一种实体的链接方法、装置和存储介质与流程
1.本发明涉及自然语言处理技术领域,尤其涉及一种实体的链接方法、装置和存储介质。
背景技术:
2.知识图谱是由节点和边构成的巨型语义网,其中节点表示物理世界中的概念和实体,边表示节点之间的拓扑链接和语义关系。近年来,知识图谱作为智能化应用的基础关键技术已经成为各界研究者关注的焦点。知识图谱能够为智能搜索、问答、推荐等系统提供知识支撑。然而,现实世界中知识是不断变化的,人们对世界的描述也在不断更新和修正。因此,为了更好地满足系统应用的需求,必须不断地对知识图谱进行知识扩充。早期的知识图谱通常依赖人工构建和扩充,这种方式不仅效率低而且成本极高。因此,知识图谱的自动扩充方法便具有极高的研究与应用价值。
3.文本中蕴含的知识是无穷无尽的,借助于实体链接的方法,将文本中带有歧义的实体提及链接到知识图谱中具有明确意义的实体上,可以实现大规模的知识图谱扩充。已有工作表明,将实体链接过程看作是序列决策的过程可以高效地完成实体链接。该类方法的核心是利用先前已决策的实体信息辅助后续的链接决策。
4.然而基于单向序列决策的实体链接方法存在全局信息利用不充分和潜在错误链接不能被纠正的问题。
技术实现要素:
5.鉴于此,本发明受人类在做完形填空时的行为启发,提出了一种带有检查与纠正功能的双向实体链接方法。该方法利用检查模块核验当前链接的实体是否正确。若正确,则作为证据参与下一个提及的决策;若不正确,则纠正该提及,还可以进一步重新进行决策。同时,重复上述检查和纠正步骤进行二次链接的策略可以有效解决信息利用不充分的问题。实验表明,本发明能够充分合理地利用全局信息,显著提升实体链接的性能。
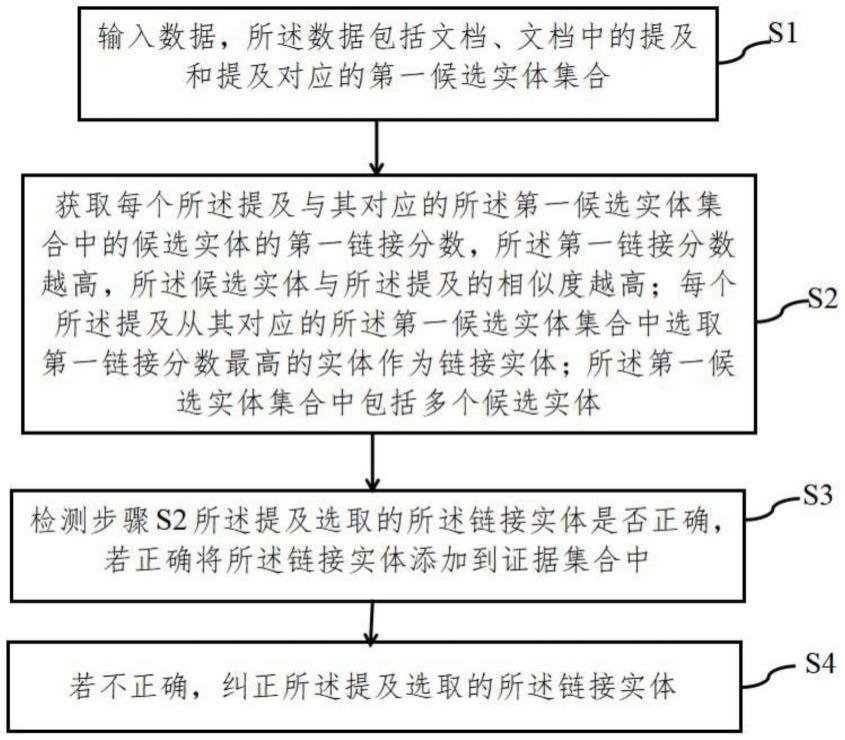
6.本发明提出一种实体的链接方法,包括以下步骤:s1、输入数据,所述数据包括文档、文档中的提及和提及对应的第一候选实体集合;s2、获取每个所述提及与其对应的所述第一候选实体集合中的候选实体的第一链接分数,所述第一链接分数越高,所述候选实体与所述提及的相似度越高;每个所述提及从其对应的所述第一候选实体集合中选取第一链接分数最高的实体作为链接实体;所述第一候选实体集合中包括多个候选实体;s3、检测步骤s2所述提及选取的所述链接实体是否正确,若正确将所述链接实体添加到证据集合中;s4、若不正确,纠正所述提及选取的所述链接实体。
7.进一步地,在步骤s2中,每个所述提及从其对应的所述第一候选实体集合中选取
最高相似度的实体作为链接实体包括:s21、获取所述候选实体的先验分布;s22、利用所述提及的上下文信息获得所述提及的表示,计算候选实体的表示与所述提及的表示的相似度;s23、计算所述提及的类型与所述候选实体的类型相似度;s24、聚合链接实体在知识图谱中的邻域实体,得到邻域实体表示,计算所述邻域实体与所述候选实体的相似度;s25、利用注意力机制聚合证据集合中的实体的信息,得到证据集合中的实体的表示,计算链接实体与候选实体的相似度;s26、聚合、、、和,得到所述候选实体最终的第一链接分数,第一链接分数最高的所述候选实体作为链接实体。
8.进一步地,在步骤s3中,所述检测步骤s2所述提及选取的所述链接实体是否正确包括:s31、确定所述链接实体的类别空间,所述类别空间包括:正确、不正确和不确定;s32、利用分类函数和证据集合中的实体判断当前链接实体的类别;s33、选择具有最大概率的类别作为链接实体的类别。
9.进一步地,在步骤s33之后还包括:步骤s34、若链接实体的类别是正确,则将该实体添加到证据集合中。
10.进一步地,在步骤s4中,所述若不正确,纠正所述提及选取的所述链接实体包括:s41、若所述连接实体的类别不正确,则按照步骤s2的方法获取所述链接实体的类别为不正确所对应的提及与第一候选实体集合中候选实体的第二链接分数;s42、聚合步骤s2的候选实体的所述第一链接分数和所述第二链接分数,得到单向决策最终的候选实体的第三链接分数,选取第三链接分数最高的实体作为链接实体。
11.进一步地,在步骤s4之后还包括:s5、根据所述第三链接分数,对每个提及的不同候选实体进行排序,计算排名第一和排名第二的候选实体的第三链接分数差值,按照该差值重新对序列中的提及进行排序,得到第二次决策的提及序列;s6、利用双向lstm网络对第一次决策得到的所述证据集合中的实体进行编码,得到历史向量;s7、将所述历史向量或者将第一次决策得到的所述证据集合中的实体作为证据集合;s8、获取所述第二次决策的提及序列的每个所述提及与其对应的所述第一候选实体集合中的候选实体的第四链接分数;s9、聚合所述第三链接分数和所述第四链接分数得到第五链接分数,选取最高的第五链接分数的实体作为链接实体。
12.进一步地,在步骤s21中,所述获取所述候选实体的先验分布包括:,其中锚
链接指的是维基百科描述页中的超链接。
13.进一步地,在步骤s21中,所述相似度的计算公式如下:其中,表示候选实体,表示对角矩阵,t表示置换,为提及的上下文表示向量。
14.此外,本发明还提出一种实体的链接装置,包括:数据模块,用于输入数据,所述数据包括文档、文档中的提及和提及对应的第一候选实体集合;实体选择模块,用于获取每个所述提及与其对应的所述第一候选实体集合中的候选实体的第一链接分数,所述第一链接分数越高,所述候选实体与所述提及的相似度越高;每个所述提及从其对应的所述第一候选实体集合中选取第一链接分数最高的实体作为链接实体;所述第一候选实体集合中包括多个候选实体;检测模块,用于检测所述提及选取的所述链接实体是否正确,若正确将所述链接实体添加到证据集合中;纠正模块,若不正确,纠正所述提及选取的所述链接实体。
15.进一步地,本发明还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述实体的链接方法的步骤。
16.本发明与现有技术对比的有益效果包括:本发明提出的实体链接方法,可以高效地利用全局实体信息,并且能够对潜在链接错误的提及进行纠正,elct-c在所有跨域数据集的f1平均得分上整体提高了0.84%。
附图说明
17.通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:图1是本发明实施例1提出的一种实体的链接方法的流程示意图。
18.图2是本发明实施例1提出的一种实体的链接装置的结构框图。
具体实施方式
19.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施的限制。
20.实施例1结合图1,本实施例提出一种实体的链接方法,包括以下步骤:s1、输入数据,所述数据包括文档、文档中的提及和提及对应的第一候选实体集合。
21.s2、获取每个所述提及与其对应的所述第一候选实体集合中的候选实体的第一链
接分数,所述第一链接分数越高,所述候选实体与所述提及的相似度越高;每个所述提及从其对应的所述第一候选实体集合中选取第一链接分数最高的实体作为链接实体;所述第一候选实体集合中包括多个候选实体;进一步地,包括:s21、获取所述候选实体的先验分布;进一步地,所述获取所述候选实体的先验分布的计算公式包括:,其中锚链接指的是维基百科描述页中的超链接。
22.s22、利用所述提及的上下文信息获得所述提及的表示,计算候选实体的表示与所述提及的表示的相似度;所述相似度的计算公式如下:其中,表示候选实体,表示对角矩阵,t表示置换,为提及的上下文表示向量。需要说明的是,提及的上下文表示向量由以下步骤得到:计算提及的每个候选实体与文档中提及的上下文单词之间向量的点乘相似度,并将点乘相似度的最大值作为该上下文单词的权重。然后根据上下文单词的权重对单词进行排序,选择排名前k1的单词,最后,根据这些单词的权重对单词的表示进行加权求和,得到提及的上下文的表示向量,其中,k1大于1。
23.s23、计算所述提及的类型与所述候选实体的类型相似度;s24、聚合链接实体在知识图谱中的邻域实体,得到邻域实体表示,计算所述邻域实体与所述候选实体的相似度;具体地,计算提及的每个候选实体与证据集合中某个已链接实体的邻域信息的相似性,若证据集合中无已链接实体,则用虚拟实体来表示已链接实体的邻域信息。将候选实体中的最大相似度作为该邻域表示的权重。然后根据权重对邻域表示进行排序,选择排名前k2的邻域表示,k2大于1。最后,根据权重对邻域表示进行加权和求和,得到邻域实体与所述候选实体的相似度;s25、利用注意力机制聚合链接实体的信息,得到链接实体的表示,计算链接实体与候选实体的相似度;具体地,计算提及的每个候选实体与证据集合中某个已链接实体的相似性,若证据集合中无已链接实体,则用虚拟实体来表示已链接实体。将候选实体中的最大相似度作为该已链接实体的权重。然后根据权重对已链接实体进行排序,选择排名前k的已链接实体。最后,根据权重对已链接实体的表示进行加权求和,得到所有已链接实体的表示向量,得到已链接实体与候选实体的相似度;s26、聚合、、、和,得到所述候选实体最终的第一链接分数,第一链接分数最高的所述候选实体作为链接实体。聚合方式如下:其中是前馈神经网络,表示向量拼接。
24.s3、检测步骤s2所述提及选取的所述链接实体是否正确,若正确将所述链接实体添加到证据集合中;进一步地,包括:
s31、确定所述链接实体的类别空间,所述类别空间包括:正确、不正确和不确定;s32、利用分类函数和证据集合中的实体判断当前链接实体的类别;s33、选择具有最大概率的类别作为链接实体的类别;利用注意力机制聚合证据集合中所有已链接实体并被判断为正确的候选实体,得到证据向量,然后将证据向量与当前链接实体拼接起来,经过维度放缩后输出维度为3的类别向量,向量的每一维度表示每一个类别的概率;选择具有最大概率的类别作为当前链接实体的预测类别;s34、若链接实体的类别是正确,则将该实体添加到证据集合中。
25.需要说明的是,证据集合是通过构造带有初始虚拟实体表示,具体方法是将随机初始化的虚拟实体表示添加到空集合中,该集合用于存储正确的链接实体,即已链接实体。
26.s4、若不正确,纠正所述提及选取的所述链接实体;进一步地,包括:s41、若所述连接实体的类别不正确,则按照步骤s2的方法获取所述链接实体的类别为不正确所对应的提及与第一候选实体集合中候选实体的第二链接分数;s42、聚合步骤s2的候选实体的第一链接分数和所述第二链接分数,得到单向决策最终的候选实体的第三链接分数,选取第三链接分数最高的实体作为链接实体。
27.重复上述实体选择、检查和纠正步骤进行二次链接,具体地,还包括以下步骤:s5、根据所述第三链接分数,对每个提及的不同候选实体进行排序,计算排名第一和排名第二的候选实体的第三链接分数差值,按照该差值重新对序列中的提及进行排序,得到第二次决策的提及序列;s6、利用双向lstm网络对第一次决策得到的所述证据集合中的实体进行编码,得到历史向量;s7、将所述历史向量或者将第一次决策得到的所述证据集合中的实体作为证据集合;s8、获取所述第二次决策的提及序列的每个所述提及与其对应的所述第一候选实体集合中的候选实体的第四链接分数;s9、聚合所述第三链接分数和所述第四链接分数得到第五链接分数,选取最高的第五链接分数的实体作为链接实体。
28.结合图2,本实施例还包括一种实体的链接装置,包括:数据模块,用于输入数据,所述数据包括文档、文档中的提及和提及对应的第一候选实体集合;实体选择模块,用于获取每个所述提及与其对应的所述第一候选实体集合中的候选实体的第一链接分数,所述第一链接分数越高,所述候选实体与所述提及的相似度越高;每个所述提及从其对应的所述第一候选实体集合中选取第一链接分数最高的实体作为链接实体;所述第一候选实体集合中包括多个候选实体;检测模块,用于检测所述提及选取的所述链接实体是否正确,若正确将所述链接实体添加到证据集合中;纠正模块,若不正确,纠正所述提及选取的所述链接实体。
29.此外,本具体实施方式还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述实体的链接方法的步骤。
30.实验结果
我们使用公开的实体链接数据集来验证我们的方法。数据集包括同领域数据集和跨领域数据集。对于同领域数据,本发明在aida-conll数据集上进行实验:aida-conll数据集中的aida-train数据用于训练,aida-a数据用于验证,aida-b数据用于测试。对于跨领域数据,本发明在aida-train数据集上进行训练,在msnbc、aquaint、ace2004、cweb以及wiki五个数据集上进行测试。数据集的规模见表1。
31.使用上述数据得到的实验结果见表2,其指标是f1值。其中elct-p和elct-c代表本发明中提出的方法,分别表示将所述历史向量作为证据集合和将第一次决策得到的所述证据集合中的实体作为证据集合。
32.表实体链接的数据集统计数据集提及数目文档数目平均提及数目候选实体召回率aida-train1844894619.5-aida-a479121622.197.2aida-b448523119.498.5msnbc6562032.898.5aquaint7275014.593.9ace2004257367.191.4cweb11154320 34.891.3wiki682132021.392.6表2实体链接结果模型aida-bmsnbcaquaintaquaintcwebwikideep-ed92.2293.7088.5088.5077.9077.50ment-norm93.0793.9088.3089.9077.5078.00dca94.6494.5787.3889.4473.4778.16fgs2ee92.6394.2688.4790.7077.4177.66elct-p95.1694.6789.1691.3475.0777.43elct-c94.9594.7889.2990.0575.2177.24明显地,在aida-b数据中,本发明提出的基于双向决策的实体链接方法要优于传统的基于实体的链接方法,其中elct-p实现了最高的实体链接性能。在跨领域数据集中,本发明提出的方法在msnbc、ace2004和aquaint数据集上实现了最先进的性能。与典型的实体链接模型dca相比,elct-c在所有跨域数据集的f1平均得分上整体提高了0.84%。
33.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1