一种面向SG-CIM模型的实体对齐方法与流程
一种面向sg-cim模型的实体对齐方法
技术领域
1.本发明涉及大数据技术领域,尤其是涉及一种面向sg-cim模型的实体对齐方法。
背景技术:
2.企业公共数据模型(sg-cim)是国家电网公司贴合实际业务需求、同时遵循国际统一标准所形成的统一信息视图,被评为行业最佳的应用实践,是面向对象构建的企业级数据模型。目前包含上百个从问题域中抽象出的信息类作为主题及子主题域,例如:安全、财务、电网、客户、人员、市场、物资、项目、资产、综合域等,域下同时涵盖了近千种相关实体和近万种属性,被用作国家电网的统一编码规范,为业务应用系统提供统一的数据模型。企业公共数据模型(sg-cim)包括:逻辑模型表、物理模型表、标准模型表等。
3.在知识图谱的实体对齐领域中,与实体对齐有关的方法主要包括以下两类:基于字符串相似性的实体对齐方法,基于表示学习的实体对齐方法。
4.(1)基于字符串相似性的实体对齐方法:
5.①
limes(long short-term memory,长短期记忆网络),limes基于三角不等距离逼近算法,推导距离的上下边界条件,使用这些边界条件来减少映射比较次数。被分割的空间内可以计算该区域中的每个实例与其他实例之间的相似度距离的精确近似。通过这些方法,可以在不牺牲精度的情况下有效地发现链接数据源之间的链接。limes在相似度距离计算上提供了多种方案,包括字符串,语义,向量,point-set等。
6.②
rdf-ai,rdf-ai实现了一个由预处理、匹配、融合、互连和后处理模块组成的对齐框架,提出一种基于属性的实体对匹配算法:基于序列对齐的模糊字符串匹配算法和词义相似度算法。计算属性匹配相似度,得到两图中所有可能对齐的属性对,通过对属性对相似度求和得到实体相似度。最终实体相似度最高者,被认为是一个实体。
7.③
holisticem,基于实体的重叠属性和相邻实体,构建了一个潜在实体对的图。然后,图中的局部和全局属性使用个性化页面排名进行传播,以计算实体对的实际相似度。该算法考虑了每个实体中,每个单词对整个实体的语义贡献程度。
8.(2)基于表示学习的实体对齐方法:
9.基于表示学习的模型旨在保留实体的结构信息,也就是说,在知识图谱中具有类似邻居结构的实体应该在表示学习空间中具有接近的表示。这种表示学习模型的进步促使研究者们去研究基于表示学习的实体对齐。
10.①
mtranse:通过对单语言实体进行空间转换来执行跨语言的实体对齐,通过空间完成单语言知识图谱的表示学习。针对不同语言,mtranse分别在独立空间中对实体和关系进行编码,并可以对任意实体或关系向量进行跨语言转换,且多语言图谱的表示学习模型保留了单语表示学习时的优良特性。
11.②
iptranse:该方案是一种利用联合知识表示学习实现的实体对齐框架。该方法根据一个小的对齐实体种子集,将不同知识图谱的实体和关系联合编码到一个统一的低维语义空间中。更具体地说,该方案提出了一种迭代和参数共享的方法来提高对齐性能。
12.该方法主要由三部分组成:(1)知识表示学习。利用基于翻译的krl(knowledge representation learning)学习实体和关系的表示学习。(2)联合表示学习。根据种子集将不同知识图谱的知识表示学习映射到联合语义空间。(3)迭代对齐。通过考虑那些在方法中越来越多地发现的高度自信的对齐实体,迭代地对齐实体及其对应实体,并更新联合知识表示学习。
13.③
jape:当面对不同自然语言的知识库时,传统的跨语言实体对齐方法依靠机器翻译来消除语言障碍。这些方法经常受到语言之间翻译质量不平衡的影响。
14.基于表示学习的技术在知识图谱中对实体和关系进行编码,并且不需要机器翻译来实现跨语言实体对齐,但是还有大量的属性尚未被研究。
技术实现要素:
15.本发明提供了一种面向sg-cim模型的实体对齐方法,以解决现有技术中跨语言实体对齐方法依靠机器翻译来消除语言障碍的缺陷,国家电网公共数据模型sg-cim中标准模型表、逻辑模型表和物理模型表之间的实体对齐匹配任务效率低的技术问题。
16.本发明的一个目的在于提供一种面向sg-cim模型的实体对齐方法,所述方法包括如下方法步骤:
17.步骤一,对sg-cim模型中不同模型表知识图谱的三元组,进行规范化处理,生成一组关系三元组和一组属性三元组;
18.步骤二,将规范化处理后的关系三元组进行结构表示学习,将规范化处理后的属性三元组进行属性表示学习,并且,
19.使用属性表示学习得到的实体向量,将结构表示学习得到的实体向量,转移到相同的向量空间中,进行联合学习;
20.步骤三,经过联合学习后,通过计算不同模型表知识图谱实体向量相似度,对不同模型表知识图谱实体进行对齐。
21.在一个较佳的实施例中,所述步骤一中,抽取sg-cim模型中的至少两个模型表知识图谱的三元组,
22.根据抽取的至少两个模型表的三元组的第二维文本数据的相似度,将所述至少两个模型表知识图谱合并成一个知识图谱,
23.抽取合并后的知识图谱的三元组,并分割成一组关系三元组和一组属性三元组。
24.在一个较佳的实施例中,将抽取的不同模型表知识图谱的三元组的第二维文本数据编辑距离,当距离大于预设阈值时,将对应的第二维文本数据统一命名,使不同模型表知识图谱合并成一个知识图谱。
25.在一个较佳的实施例中,所述步骤二中,结构表示学习的目标函数通过下式表述:
[0026][0027][0028]
其中,tr是有效关系三元组,tr是有效关系三元组的集合,t’r
是被破坏的关系三元组,t’r
是被破坏的关系三元组的集合,γ是训练后得到的数值,α是一个权重,fr()是将关
相似的实体的集合。
[0049]
本发明提供的一种面向sg-cim模型的实体对齐方法,用于跨语言实体对齐的联合属性保留表示学习模型。将两个知识图谱的结构共同嵌入到一个统一的向量空间中,并通过利用知识图谱中的属性相关性进一步细化表示学习,面对国家电网公共数据模型sg-cim,能够高效的完成标准模型表、逻辑模型表和物理模型表之间的实体对齐匹配任务。
[0050]
本发明提供的一种面向sg-cim模型的实体对齐方法,结构表示学习与属性字符表示学习相结合,用于学习模型表实体的属性字符特征和结构关联特征,使用实体结构表示学习和属性字符表示学习将来自不同知识图谱的模型表实体嵌入到同一向量的空间,具备效率高、易更新迭代、适应性强等特征。
[0051]
本发明提供的一种面向sg-cim模型的实体对齐方法,通过计算不同模型表知识图谱实体向量的相似度,丰富三元组实体的数量,以帮助识别基于属性嵌入的实体之间的相似性。
[0052]
本发明提供的一种面向sg-cim模型的实体对齐方法,针对电网公共数据模型的多种类型模型表融合对齐方面的问题,基于嵌入学习的多模块的模型表实体对齐方法,对电网公共数据模型中的物理模型表,逻辑模型表,标准模型表,进行表实体自动对齐,能很好解决国家电网sg-cim公共数据模型中标准模型表、逻辑模型表、物理模型表实体之间的错位不一致问题,有助于实现sg-cim公共数据模型的统一、一致和实用性。
附图说明
[0053]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0054]
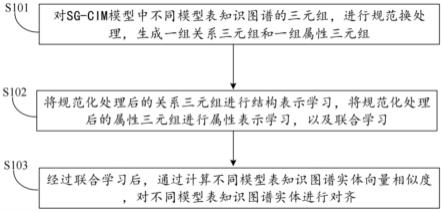
图1为本发明一种面向sg-cim模型的实体对齐方法的流程框图。
具体实施方式
[0055]
为了使本发明的上述以及其他特征和优点更加清楚,下面结合附图进一步描述本发明。应当理解,本文给出的具体实施例是出于向本领域技术人员解释的目的,仅是示例性的,而非限制性的。
[0056]
实体对齐是指,不同的知识图谱对于相同或相似的实体的描述存在差异,通过实体对齐将不同知识图谱中的实体进行互补融合,形成全面、准确、完整的实体描述。
[0057]
表示学习是指,将知识图谱的三元组表格中的文本数据通过目标函数转换成一连串数字,以产生实体向量空间,方便计算机识别。
[0058]
实体向量是指,将三元组中实体的字符串经过表示学习后,对应的向量表示。
[0059]
联合学习是指,使用属性表示学习得到的实体向量,将结构表示学习得到的实体向量,转移到相同的向量空间中。
[0060]
为了解决现有技术中跨语言实体对齐方法依靠机器翻译来消除语言障碍的缺陷,国家电网公共数据模型sg-cim中标准模型表、逻辑模型表和物理模型表之间的实体对齐匹配任务效率低的技术问题,本发明提供一种面向国家电网公司公共信息模型(sg-cim模型)
的实体对齐方法,如图1所示本发明一种面向sg-cim模型的实体对齐方法的流程框图,根据本发明的实施例一种面向sg-cim模型的实体对齐方法包括:
[0061]
对sg-cim模型中不同模型表知识图谱的三元组,进行规范化处理,生成一组关系三元组和一组属性三元组。
[0062]
将规范化处理后的关系三元组进行结构表示学习,将规范化处理后的属性三元组进行属性表示学习,并且,
[0063]
使用属性表示学习得到的实体向量,将结构表示学习得到的实体向量,转移到相同的向量空间中,进行联合学习。
[0064]
经过联合学习后,通过计算不同模型表知识图谱实体向量相似度,对不同模型表知识图谱实体进行对齐。
[0065]
下面根据本发明的实施例,对本发明一种面向sg-cim模型的实体对齐方法给出详细的说明。
[0066]
步骤s101、对sg-cim模型中不同模型表知识图谱的三元组,进行规范化处理,生成一组关系三元组和一组属性三元组。
[0067]
本发明的目标是对sg-cim模型中不同类型的模型表做实体对齐。需要件不同的知识图谱的嵌入落在同一个向量空间中,以便后续实体向量间的距离或相似度计算。例如对sg-cim模型中不同类型的模型表(物理模型表的知识图谱、逻辑模型表的知识图谱、标准模型表的知识图谱)嵌入落在同一个向量空间中,以实现后续实体向量的相似度计算。
[0068]
为了有一个统一的关系嵌入矢量空间,本发明将不同的模型表知识图谱合并。根据本发明的实施例,根据三元组中第二维文本数据的相似性合并两个知识图谱。需要说明的是,本发明三元组中第二维文本数据是指,在一个三元组表格中,位于中间行或列的文本数据。举例来说,一个三元组表格包括三列,第一列为头实体、第二列为尾实体、第三列为关系,则第二维文本数据是指位于中间的第二列尾实体的文本数据。
[0069]
根据本发明的实施例,抽取sg-cim模型中的至少两个模型表知识图谱的三元组,例如抽取物理模型表的知识图谱和逻辑模型表的知识图谱的三元组。
[0070]
根据抽取的至少两个模型表的三元组的第二维文本数据的相似度,将所述至少两个模型表知识图谱合并成一个知识图谱。
[0071]
在一些实施例中,将抽取的不同模型表知识图谱的三元组的第二维文本数据编辑距离,当距离大于预设阈值时,将对应的第二维文本数据统一命名,使不同模型表知识图谱合并成一个知识图谱。
[0072]
具体的实施例中,有部分匹配的第二维文本,例如,dbp:deadin vs.yago:deadin,and dbp:bornin vs.yago:wasbornin.yago:wasbornin。为了找到部分匹配的三元组的文本数据,计算三元组第二维文本数据的编辑距离,并设定0.95为相似度阈值,高于阈值的第二维文本数据统一命名。
[0073]
在具体的实施例中,找到三元组中部分相似的第二维文本数据,并用一个统一的命名的方式对它们进行重命名。基于第二维文本数据统一的命名,将第一模型表的知识图谱g1和第二模型表的知识图谱g2合并为知识图谱g12。本实施例中,第一模型表的知识图谱g1为物理模型表的知识图谱,第二模型表的知识图谱g2为逻辑模型表的知识图谱。本发明通过用统一的命名重新命名三元组的第二维文本数据,进而将不同模型表的知识图谱合
并,从而实现一个统一的表示学习矢量空间,实现规范化处理。
[0074]
根据本发明的实施例,抽取合并后的知识图谱的三元组,并分割成一组关系三元组和一组属性三元组。
[0075]
具体地实施例中,合并后的知识图谱g12被分割成一组关系三元组tr和一组属性三要素ta,用于后续的表示学习。
[0076]
步骤s102、将规范化处理后的关系三元组进行结构表示学习,将规范化处理后的属性三元组进行属性表示学习,并且,
[0077]
使用属性表示学习得到的实体向量,将结构表示学习得到的实体向量,转移到相同的向量空间中,进行联合学习。
[0078]
根据本发明的实施例,经过步骤s101的规范化处理,得到一个统一的向量空间,通过统一向量空间,实现结构嵌入(结构表示学习)和属性特征嵌入(属性表示学习)的联合学习,产生一个统一的实体向量空间。
[0079]
根据本发明的实施例表示学习包括结构表示学习、属性表示学习和联合学习。结构表示学习是对关系三元组tr做表示学习,而属性表示学习是对属性三元组做表示学习。
[0080]
需要说明的是,本发明的表示学习是指将知识图谱的三元组表格中的文本数据通过目标函数转换成一连串数字,以产生实体向量空间,方便计算机识别。
[0081]
结构表示学习
[0082]
根据本发明的实施例,结构表示学习的目标函数通过下式表述:
[0083][0084][0085]
其中,tr是有效关系三元组,tr是有效关系三元组的集合,t’r
是被破坏的关系三元组,t’r
是被破坏的关系三元组的集合,γ是训练后得到的数值,α是一个权重,fr()是将关系值编码为矢量的组合函数,count(r)是关系r出现的次数,|t|是合并后的知识图谱中的三元组总数。
[0086]
本发明调整transe(translating embedding)学习结构嵌入,以实现知识图谱之间的实体对齐,表示学习主要在对齐的三元组上(即具有对齐的关系(谓词)的三元组)。本发明通过增加一个权重α来控制表示学习。
[0087]
本发明训练过程中,fr()作为关系值编码为矢量的组合函数,将关系值编码为一个矢量,并将类似的关系值映射为类似的矢量表示。
[0088]
在一些实施例中,通常情况下,对齐关系的出现次数要高于非对齐关系的出现次数,由于对齐的关系同时出现在两个知识图谱中,因此从对齐的三元组中能够更多的将关系值编码为矢量,即从对齐的三元组中能够更多的将文本数据转换为一连串数字。
[0089]
属性表示学习
[0090]
属性表示学习的目标函数通过下式表述:
[0091]
[0092][0093]
其中,ta是有效属性三元组,ta是有效属性三元组的集合,t’a
是被破坏的关系三元组,t’a
是被破坏的属性三元组的集合,γ是训练后得到的数值,α是一个权重,fa()是将属性值编码为矢量的组合函数,count(a)是属性a出现的次数,|t|是合并后的知识图谱中的三元组总数。
[0094]
按照transe(translating embedding),对于属性字符表示学习,本发明将关系r视为从头部实体h到属性a的翻译。同一个属性a可能以不同的形式出现在两个知识图谱中。
[0095]
fa()是将属性值编码为矢量的组合函数,属性a的属性值是一个字符序列a={c1,c2,c3,...,ct}。组合函数fa()将属性值编码为一个矢量,并将类似的属性值映射为类似的矢量表示。根据本发明的实施例,具有三种组合函数fa()。
[0096]
在一些实施例中,将属性值编码为矢量的组合函数fa()为和合成函数(sum):
[0097]
fa(a)=c1+|c2+c3+...+c
t
,
[0098]
其中,a是属性值的一个字符序列,a={c1,c2,c3,...,ct}。
[0099]
该组合函数fa()被定义为属性值的所有字符的总和嵌入的属性值的总和,其中c1,c2,...,c
t
是属性值的字符表示学习。例如文本数据good,其对应编码的数字为1+2+3+4。
[0100]
该组合函数fa()运算简单,但是缺点是:两个包含相同字符集但顺序不同的字符串会有相同的向量表示,例如,两个坐标"50.15"和"15.05"将有相同的向量表示。
[0101]
在一些实施例中,将属性值编码为矢量的组合函数fa()为:
[0102]
fa(a)=f
lstm
(c1,c2,c3,...,c
t
),
[0103]
其中,a是属性值的一个字符序列,a={c1,c2,c3,...,ct},f
lstm
()是基于lstm的合成函数。
[0104]
基于lstm(long short-term memory,长短期记忆网络)的组合函数,使用lstm网络将一连串的字符编码为一个单一的向量。使用lstm网络的最终隐藏状态作为属性值的一个向量表示。
[0105]
在一些实施例中,将属性值编码为矢量的组合函数fa()为:
[0106][0107]
其中,a是属性值的一个字符序列,a={c1,c2,c3,...,ct},n表示在ngram组合中使用的n的最大值,t是属性值的长度。
[0108]
该组合函数是基于n-gram的合成函数。本发明提出基于n-gram的组合函数,作为解决合成函数(sum)问题的一个替代方法来解决合成函数(sum)的缺陷。
[0109]
联合学习
[0110]
根据本发明的实施例,使用属性表示学习得到的实体向量,将结构表示学习得到的实体向量,转移到相同的向量空间中,进行联合学习。根据本发明的实施例,联合学习的目标函数通过下式表述:
[0111]
j=j
se
+j
ce
+j
sim
,
[0112][0113]
其中,j
se
结构表示学习的目标函数,j
ce
属性表示学习的目标函数,j
sim
为使用属性表示学习得到的实体向量将结构表示学习得到的实体向量转移到相同的向量空间的目标函数,g1为第一模型表知识图谱,g2为第二模型表知识图谱,h为实体,h
ce
为经过属性表示学习得到的实体向量,h
se
为经过结构学习得到的实体向量。
[0114]jsim
作为使用属性表示学习得到的实体向量将结构表示学习得到的实体向量转移到相同的向量空间的目标函数,结构表示学习得到的实体向量h
se
,捕捉了两个不同模型表知识图谱之间基于实体关系的实体的相似性;属性字符表示学习得到的实体向量h
ce
是基于属性值的实体的相似性。
[0115]
在步骤s102中,最初,由于来自g1和g2的实体名称常使用不同的命名来表示,因而来自知识图谱g1和知识图谱g2的实体的结构表示学习落入不同的向量空间。对于属性表示学习,即使属性来自不同的知识图谱,它们也可以是相似的,属性三元组中学习到的属性嵌入可以落入同一个向量空间。本发明通过属性字符表示学习来将实体的结构表示学习转移到相同的向量空间,使得模型表知识图谱的实体的表示学习可以捕捉到来自两个知识图谱的实体之间的相似性。
[0116]
步骤s103、经过联合学习后,通过计算不同模型表知识图谱实体向量相似度,对不同模型表知识图谱实体进行对齐。
[0117]
本发明经过步骤s102的结构表示学习和属性表示学习的联合学习,使知识图谱g1和知识图谱g2中的相似实体向量具有相似的表示学习,在此基础上本发明计算不同模型表知识图谱实体向量相似度,从而对不同模型表知识图谱实体进行对齐。
[0118]
根据本发明的实施例,不同模型表知识图谱实体向量的相似度或距离通过如下方式计算:
[0119][0120]
其中,实体h1∈g1表示实体h1是第一模型表知识图谱g1中的实体,实体h2∈g2表示实体h2是第二模型表知识图谱g2中的实体,h
map
表示第二模型表知识图谱g2中所有与实体h1相似的实体的集合。
[0121]
设定相似度阈值β(例如0.8),在第一模型表知识图谱g1中任意给定一个实体h1,经过上述相似度(距离)计算,在第二模型表知识图谱g2中所有与实体h1相似度大于阈值β的实体组合成一个集合h
map
,筛选出第二模型表知识图谱g2最有可能与第一模型表知识图谱g1中实体h1对齐的实体,完成sg-cim模型表实体的对齐任务。
[0122]
本发明提供的一种面向sg-cim模型的实体对齐方法,用于跨语言实体对齐的联合属性保留表示学习模型。将两个知识图谱的结构共同嵌入到一个统一的向量空间中,并通过利用知识图谱中的属性相关性进一步细化表示学习,面对国家电网公共数据模型sg-cim,能够高效的完成标准模型表、逻辑模型表和物理模型表之间的实体对齐匹配任务。
[0123]
本发明提供的一种面向sg-cim模型的实体对齐方法,结构表示学习与属性字符表示学习相结合,用于学习模型表实体的属性字符特征和结构关联特征,使用实体结构表示
学习和属性字符表示学习将来自不同知识图谱的模型表实体嵌入到同一向量的空间,具备效率高、易更新迭代、适应性强等特征。
[0124]
本发明提供的一种面向sg-cim模型的实体对齐方法,通过计算不同模型表知识图谱实体向量的相似度,丰富三元组实体的数量,以帮助识别基于属性嵌入的实体之间的相似性。
[0125]
本发明提供的一种面向sg-cim模型的实体对齐方法,针对电网公共数据模型的多种类型模型表融合对齐方面的问题,基于嵌入学习的多模块的模型表实体对齐方法,对电网公共数据模型中的物理模型表,逻辑模型表,标准模型表,进行表实体自动对齐,能很好解决国家电网sg-cim公共数据模型中标准表、逻辑模型表、物理模型表实体之间的错位不一致问题,有助于实现sg-cim公共数据模型的统一、一致和实用性。
[0126]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1