一种分布式事务提交协议的运行环境监测方法
:
1.本公开涉及分布式事务处理技术领域,尤其涉及一种分布式事务提交协议的运行环境监测方法。
背景技术:
2.事务在数据库中被广泛地用于存储重要信息,它集成了用户的一系列关键操作,并保证 acid四个属性(原子性、一致性、隔离性、持久性)。在这四个属性中,原子性保证了一个事务中的操作会同时发生,但该性质的实现也为数据库,尤其是分布式数据库带来了额外的开销。在分布式数据库中,数据被拆分并分布在不同的节点上以实现水平扩展。这给保障事务的原子性带来了新的挑战:所有的参与节点需要就提交或回滚某一事务保持一致。分布式事务提交问题由此诞生,并受到了工业界以及学术界的广泛关注。然而,据我们所知,现有的分布式事务提交协议都存在一个基本缺陷,即它们对系统环境(节点表现和网络连接表现)的固定假设。该缺陷限制了分布式数据库效率的进一步提高。
技术实现要素:
3.本公开的目的是为了克服或者部分克服上述技术问题,提供一种用于分布式事务提交的环境检测方法,该方法能够使协调者全面掌握系统环境,并能够根据环境的变化及时变更分布式事务提交协议,从而提高分布式数据库效率。
4.第一方面,本公开实施例提供一种分布式事务提交协议的运行环境监测方法,包括协调者c
*
和若干个事务t的参与者c
t
,
5.c
*
分别为每一个参与者维护一个鲁棒性等级状态机rlsm;
6.rlsm包含三个状态,分别代表分布式事务提交所处环境的三个故障等级:无故障等级、崩溃故障等级和网络故障等级;
7.rlsm根据输入的不同在三个状态间转移;
8.c
*
根据c
t
中每一个参与者的rlsm状态确定环境等级l,其中l为无故障等级、崩溃故障等级或网络故障等级,所述l用于确定所述分布式事务t提交的协议π
t
。
9.第二方面,本公开实施例提供一种电子设备,包括:
10.存储器;
11.处理器;以及
12.计算机程序;
13.其中,所述计算机程序存储在所述存储器中,并被配置为由所述处理器执行以实现第一方面所述的方法。
14.第三方面,本公开实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的方法。
15.有益效果:
16.本公开提供的方法,通过使用rlsm鲁棒性等级状态机来维护每个参与者的系统环
境,该状态机维护的状态可通过输入不同参数被动态调整,以实时跟踪每个参与者的环境;协调者能够基于参与者对应rlsm的状态确定系统环境等级,打破了现有分布式事务提交时对系统环境的固定假设,使得分布式事务提交可以根据系统环境动态调整提交协议,从而提高分布式事务处理的效率。进一步的,通过设定状态机输入由当前分布式事务提交协议及其执行结果共同设置,可实现参与者rlsm状态机状态的自动调整,即参与者的状态由先前提交协议的执行结果动态确定,而其当前状态又决定了下一个分布式事务提交时应采用的提交协议。进一步的,设定状态机降低等级时的输入参数非固定,而是通过强化学习基于历史提交协议执行结果习得,更加符合分布式事务处理环境,提高分布式事务处理效率。
附图说明
17.此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
18.为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
19.图1为2pc协议流程示意图;
20.图2为3pc协议流程示意图;
21.图3为一种现有分布式系统的结构示意图;
22.图4为具有环境感知能力的分布式系统结构示意图;
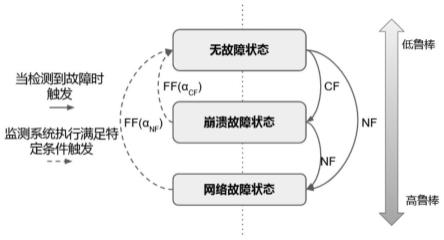
23.图5为本公开提供的鲁棒等级状态机rlsm示意图;
24.图6为本公开提供的强化学习优化器结构示意图;
25.图7为本公开实施例提供的一种电子设备的结构示意图;
26.图8为各协议在稳定环境下的表现示意图;其中,(a)为吞吐量(throughput)随客户端数目(clientnumber)增长的表现,(b)为延迟(latency)随客户端数目(clientnumber)增长的表现;
27.图9为α
cf
和α
nf
对于prac吞吐量的影响示意图,τs-cf,τs-nf分别表示周期为τ的崩溃错误和网络错误;其中,(a)为周期性崩溃错误(periodiccrashfailure)下α
cf
对于prac吞吐量的影响,(b)为周期性网络错误(periodicnetworkfailure)下α
nf
对于prac吞吐量的影响;
28.图10为α
cf
对于prac在不稳定环境下的影响示意图;其中,(a)为α
cf
对于错误路径执行所占的比例(errorrate)的影响,(b)为α
cf
对于平均鲁棒性等级(averagelevel)的影响;
29.图11为各个等级协议之间的比较示意图;
30.图12为强化学习和不同固定参数下吞吐量的比较示意图;其中,(a)为当α
cf
由强化学习(rl)调整时、固定为1时(快速鲁棒性降级转换)、固定为128(减少错误假设)时prac吞吐量的比较,(b)为当α
nf
由强化学习(rl)调整时、固定为1时(快速鲁棒性降级转换)、固定为128(减少错误假设)时prac吞吐量的比较。
具体实施方式
31.为了能够更清楚地理解本公开的上述目的、特征和优点,下面将对本公开的方案进行进一步描述。需要说明的是,在不冲突的情况下,本公开的实施例及实施例中的特征可以相互组合。
32.在下面的描述中阐述了很多具体细节以便于充分理解本公开,但本公开还可以采用其他不同于在此描述的方式来实施;显然,说明书中的实施例只是本公开的一部分实施例,而不是全部的实施例。
33.现有广为使用的分布式事务提交协议有两阶段提交协议(2pc或two-phasecommit),如图1所示,具体参见nadianouali,annedoucet,andhabibadrias.2005.atwo-phasecommitprotocolformobilewirelessenvironment.inproceedingsofthe16thaustralasiandatabaseconference-volume39.135
–
143.,和三阶段提交协议协议(3pc或three-phasecommit),如图2所示,具体参见daleskeen.1981.nonblockingcommitprotocols(sigmod’81).associationforcomputingmachinery,newyork,ny,usa,133
–
142.https://doi.org/10.1145/582318.582339。2pc无法在故障发生时保证非阻塞性,而3pc虽然通过引入一个新阶段的方式保证了非阻塞性,然而,它的额外消息传输降低了分布式事务提交效率,尤其是当系统长期处于无故障运行时。业界将分布式事务提交时的预期故障分为两种:
34.1.崩溃故障:节点暂停或终止运行。
35.2.网络故障:节点之间的消息传输花费了超出预期的时间。
36.根据这两种故障,我们将分布式事务提交协议的执行分为三种,特别的,我们只考虑参与者之间的网络故障:
37.1.无故障执行:没有崩溃故障也没有网络故障发生。
38.2.崩溃故障执行:没有网络故障发生,但崩溃故障可能发生。
39.3.网络故障执行:两种故障都可能发生。
40.能够抵抗网络故障的分布式事务提交协议必然能够抵抗崩溃故障,能够抵抗崩溃故障的分布式事务提交协议也必然在无故障环境下正确执行。由此,现有技术在选择分布式事务提交协议时,都会基于其要执行的环境所处的故障等级进行选择。如基于某应用环境要求,在网络故障发生时也必须确保同一性、有效性和非阻塞性,则大概率会选择3pc,但当3pc运行于偶尔发生网络故障、大部分时间处于无故障的环境时,会极大地降低分布式事务的提交效率,损失系统吞吐性能。同理,当选择了2pc作为提交协议时,尽管系统吞吐效能高了,但出现崩溃或网络故障时会阻塞,系统变得不可用。上述问题的原因在于,系统不能动态感知环境,基于环境的动态变换调整其当前应该使用的分布式提交协议。因此,本公开提供一种用于分布式事务提交的环境检测方法,该方法能够实时监测系统的环境状况。
41.图3是一种现有分布式系统的原型,协调者c*接收客户不时发来的事务t请求,并将该请求同步发往多个相关的参与者执行,在执行成功后向客户反馈。此处,事务t都是基于系统环境的固定假设所采用的固定提交协议执行的,不管此时整个系统无故障,还是出现了崩溃故障或网络故障。
42.因此,本公开提出在协调者c
*
处设置一环境检测器,执行下述环境检测方法,感知系统环境,并向c
*
提供需要由若干参与者c
t
执行当前事务t的分布式提交协议建议,如图4所
示。
43.图5是本公开实施例提供的一种分布式事务提交协议的运行环境监测方法,包括协调者 c
*
和若干个分布式事务t的参与者c
t
,其中
44.c
*
分别为每一个参与者维护一个鲁棒性等级状态机rlsm;
45.rlsm包含三个状态,分别代表分布式事务提交的三个故障等级:无故障等级、崩溃故障等级和网络故障等级;如图5所示;
46.rlsm根据输入的不同在三个状态间转移;
47.c
*
根据c
t
中每一个参与者的rlsm状态确定环境等级l,其中l为无故障等级、崩溃故障等级或网络故障等级,所述l用于确定所述分布式事务t提交的协议π
t
。
48.协调者c
*
通过使用rlsm来维护每个参与者的系统环境,该环境可通过输入不同参数被动态调整,以实时跟踪每个参与者的状态;协调者能够基于参与者的状态确定系统环境等级,打破了现有分布式事务提交时对系统环境的固定假设,使得分布式事务提交可以根据系统环境动态变换提交协议,从而提高分布式事务处理的效率。举例来说,当参与者为3个时, c
*
为此3个参与者分别维护一个rlsm,每个rlsm在当前时刻要么处于无故障状态,要么处于崩溃故障状态,要么处于网络故障状态,根据输入在不同状态间切换,当c
*
要提交事务时,其就可以根据这三种rlsm的状态确定系统当前的环境等级,进而根据该等级确定需要使用的提交协议。由此,c
*
即可动态实施环境监测,实时了解系统的环境状态,并能够基于系统当前的环境等级调整提交策略。
49.c
*
根据c
t
中每一个参与者的rlsm状态确定环境等级l,l的确定可以采取多种方案,如c
t
中最好状态者、c
t
中参与者的平均状态等。优选的,本公开将c
t
中系统环境最差的参与者对应的rlsm状态等级赋予l,系统环境由好至差依次为无故障等级、崩溃故障等级和网络故障等级,即把处于无故障等级状态的参与者环境作为最好环境,其次是崩溃故障等级,最差的是网络故障等级。如此,基于最差状态的参与者选定的提交协议一定能够满足好于其状态的参与者的事务提交要求。
50.具体的,设置rlsm的初始状态为无故障等级;
51.输入为cf、nf、ff(α
cf
)或ff(α
nf
),cf表示崩溃故障,nf表示网络故障,ff(α
cf
)表示从崩溃故障等级的鲁棒性降低转移,即,处于崩溃故障等级的所述rlsm,在连续α
cf
次无故障执行后,会将状态下降到无故障等级;ff(α
nf
)表示从网络故障等级的鲁棒性降低转移,即,处于网络故障等级的所述rlsm,在连续α
nf
次无故障执行后,会将状态下降到无故障等级;
52.rlsm根据输入的不同在三个状态间转移过程为:
53.当rlsm处于无故障等级时,若收到输入cf,则进行鲁棒性提高转移至崩溃故障等级,若收到输入nf,则进行鲁棒性提高转移至网络故障等级;
54.当rlsm处于崩溃故障等级时,若收到输入nf,则进行鲁棒性提高转移至网络故障等级;若收到输入ff(α
cf
),则进行鲁棒性降低转移至无故障等级;
55.当rlsm处于网络故障等级时,若收到输入ff(α
nf
),则进行鲁棒性降低转移至无故障等级。
56.rlsm的运转过程在不同的应用场景可以有不同的设置,如,初始状态设为最差等级,或随机设定等,输入以及根据输入的状态变换过程也是因应用环境而异。在本例中,将 rlsm的初始状态设为最好状态,即无故障等级,这在客观上反映了网络或设备通常是无故
障的事实。此外,将输入区分为与客观事实相符的几种不同情况的符号表示,而后根据对应情况出现时输入的对应符号进行状态转移,与客观世界真实情况相呼应。如当rlsm处于无故障等级时,若收到输入cf,即rlsm对应的参与者出现了崩溃故障,此时应该调整其为崩溃故障状态,因此本例设置此时要将其鲁棒性等级提高,转移至崩溃故障等级;若收到输入nf,即rlsm对应的参与者出现了网络故障,此时应该调整其为网络故障状态,因此本例设置此时要将其鲁棒性等级提高,直接转移至网络故障等级。同理,当rlsm处于崩溃故障等级时,若收到输入nf,则进行鲁棒性提高动作,将状态转移至网络故障等级。而在鲁棒性降低转移时,需要处于崩溃故障等级状态的rlsm,在连续α
cf
次无故障执行后,才将状态下降到无故障等级,即收到输入ff(α
cf
),则转移状态至无故障等级;处于网络故障等级状态的rlsm,在连续α
nf
次无故障执行后,才将状态下降到无故障等级,即收到输入ff(α
nf
),则转移状态至无故障等级。
57.具体的,rlsm的输入根据π
t
及t的执行结果r
t
通过如下原则确定:
58.若π
t
为无故障等级协议,检查r
t
中的结果是否能断定恶性网络故障的存在,若存在则输入nf,调整所述l为网络故障等级;否则检查r
t
中自身所代表的参与者是否存在恶性崩溃故障,若存在则输入cf,调整所述l为崩溃故障等级;
59.若π
t
为崩溃故障等级协议,检查r
t
中的结果是否能断定恶性网络故障的存在,若存在则输入nf,调整所述l为网络故障等级;否则检查连续无故障执行的数目,如果该数目达到了α
cf
则输入ff(α
cf
);
60.若π
t
为网络故障等级协议,检查连续无故障执行的数目,如果该数目达到了α
nf
则输入 ff(α
nf
)。
61.rlsm的输入可以有多种来源,如c
*
根据其网管进程或网络监视线程等计算机程序收集到的参与者状态,在此类程序中可以定期与参与者通信,获知其状态,并在其状态发生改变时,由对应的状态确定rlsm的输入,如发生了崩溃故障,则向rlsm输入cf。本例优选为由事务t的执行协议π
t
和执行结果r
t
来确定促使rlsm状态转移的输入,可以让c
*
实现不依赖其它手段的自运转循环,即当有事务需要执行时,其向环境检测器(即本公开环境检测方法)请求环境等级,环境检测器反馈其等级,即该事务的提交协议π
t
,π
t
被执行后, c
*
将执行结果r
t
再反馈给环境检测器,环境检测器根据r
t
和π
t
确定rlsm的输入,也即确定rlsm是否要进行状态转移。如此,形成了根据环境状态决定提交协议,根据协议执行结果监测环境状态并转移的正循环。
62.具体的,恶性崩溃故障的判定条件:若π
t
为无故障等级协议或崩溃故障等级协议,则检查r
t
中是否存在缺失的参与者结果,若存在,用于c
*
与参与者之间的网络连接为同步连接,结果丢失说明相应的参与者在发送结果之前遇到了崩溃故障,则判定缺失的参与者上发生了恶性崩溃故障;
63.恶性网络故障的判定条件:若π
t
为无故障等级协议,且并未检测到恶性崩溃故障,则检查r
t
中是否存在冲突的决定,若存在,则判定参与者间发生了恶性网络故障;若π
t
为崩溃故障等级协议,则若r
t
中存在冲突的决定,则判定参与者间发生了恶性网络故障。这是因为由分布式事务提交协议的性质可知,在不存在无法容忍的故障时,各个参与者的决定应保持一致,由此可知,协议执行过程中必然出现了无法容忍的故障。
64.通过所有的参与者在不同协议下的执行结果r
t
,判定参与者是否发生恶性崩溃故
障或者恶性网络故障,以便状态机转移只依赖事务t的执行结果确定,简化了系统的设计复杂性,避免了检测故障为系统带来的额外开销,并且提高了系统的独立性。
65.具体的,α
cf
和/或α
nf
基于l通过强化学习获得。可以采用现有的强化学习方法对其进行学习,如deep q-learning和policy gradient方法。
66.α
cf
、α
nf
两个参数的存在使得鲁棒性降低转移并不需要立刻进行,因为我们完全可以牺牲一些效率而非正确性来使用高鲁棒等级协议执行低鲁棒等级协议的工作。α
cf
和α
nf
调节着协议在两个因素上的取舍:更小的参数意味着更加灵敏的转移,这使得我们有更多机会用轻量级的协议来处理事务;而更大的参数意味着更加谨慎的转移,这使得我们更多地避免运行在耗时的故障路径上。用户可以手动调节这两个参数,但是,手动调节这些参数对用户来说并不容易,而仅使用预设的固定值,可能出现效率上的牺牲。因此,我们设置α
cf
和/或α
nf
可以基于l通过强化学习获得,由强化学习基于执行历史事务时的执行结果习得的参数值能够充分反映各个参与者的环境变化,实现环境的合理追踪和事务的高效处理。系统将调整后的环境等级用于强化学习,即若事务t的执行中存在故障,则该故障首先被用于调整l,其后将该l发送给强化学习优化器。之后的事务执行时将根据调整后的l确定协议。举例来说,若我们为t选取了无故障等级协议,而协议执行过程中出现了网络故障,则l将改为网络故障等级发送给强化学习优化器。
67.以α
cf
的强化学习为例,具体的,强化学习通过强化学习优化器实现,强化学习优化器包括收集器、决策器和学习器;如图6所示,其中,
68.收集器接收并缓存l,若l不同于上次缓存的环境等级,则清空缓冲区,将缓冲区缓冲期间系统的平均吞吐量μ和l一同发送给决策器,以及向学习器发送重置指令;若l与上次缓存的环境等级相同,若缓冲区已满,则清空缓冲区,将缓冲区缓冲期间系统的平均吞吐量μ和l 一同发送给决策器;
69.决策器设有计数器,并存储参数α’,α’代表需要强化学习习得的α
cf
;计数器初值为1;α’初值为k,k为实数,且不同于决策器运转过程中可能出现的取值;本例中,设置k=-1;决策器接收(l,μ)数对,判断:
70.若l为无故障等级,计数器减1,若计数器为0,则进行【决策】,否则,退出;
71.若l并非无故障等级,则进行【重置】;
72.【决策】包括以下内容:
73.若α’不为k,则触发相应的rlsm转移,设置rlsm的输入为ff(α
cf
);并进行【重置】;
74.若α’为k,则向学习器发送μ,并获得一个反馈数字h,以及一个可能会被一并发回的反馈决策α;若h为0则触发相应的rlsm转移,并将计数器设为1;否则,将计数器设为h;若成功接收到α,则设置α’为α;
75.所述【重置】包括以下内容:
76.若α’为k,则设置计数器为1;
77.若α’不为k,则设置计数器为α’;
78.学习器,若接收到收集器发来的重置指令,则将其强化学习模型调整到初始状态;若接收到决策器发来的μ,则以μ作为回报训练强化学习模型,并将模型反馈的决策数字h反馈给决策器;若强化学习模型训练完成,则将其决策方案转化为数值α一并反馈给决策器。
79.对参数α
nf
进行强化学习的过程同上,只要将其中的α
cf
替换为α
nf
即可,并且不若α
cf
的学习,是一个参与者对应的rlsm由一个强化学习优化器进行学习;对于α
nf
的学习,是所有的参与者对应的rlsm使用一个强化学习优化器进行学习,在此不再赘述学习过程。
80.可以采用现有的强化学习方法,如标准的马尔可夫决策过程(markov decision process, mdp),对参数α
cf
进行学习。优选的,本例采用q-learning模型。上述强化学习优化器,在由强化学习模型构建的学习器基础上,增加了收集器和决策器,收集器接收并缓存来自 rlsm的环境等级l,并在等级变化或缓存区满时将缓存到的结果整合发送给决策器。收集器的缓存避免了对于决策器和强化学习模型过度频繁的访问,减少这部分为系统带来的计算开销,避免影响事务的处理效率。决策器将接收到的结果进行处理,并当计数器清零时将平均吞吐量μ发送给学习器进行学习并获取决策。特别的,在学习器强化学习模型训练完成后,决策器将在本地缓存学习器学到的参数α,并依此进行接下来的决策。决策器将学习器学到的决策转化为了参数,便于系统使用,同时,其在学习完成时对参数进行了缓存,避免了对于学习器的继续访问,进一步减小了计算开销。
81.本公开针对分布式事务提交,开创性地加入了状态机rlsm来快速监测系统环境,为分布式提交协议不再使用关于系统环境固定的假设提供了一套可行的方案,给予了分布式事务提交协议感知系统环境的方法,进而抓取到了更多的优化空间。此外,本公开还加入了强化学习来提升协议的适应性和在不稳定环境下的性能,实现系统自动调参。据我们所知, rlsm是第一个利用协议现有结果,并加入强化学习的,实时的系统环境(崩溃故障,网络故障)监测器。
82.图7为本公开实施例提供的一种电子设备的结构示意图,该设备可以执行上述方法实施例提供的处理流程,如图7所示,物联网设备110包括:存储器111、处理器112、计算机程序和通讯接口113;其中,计算机程序存储在存储器111中,并被配置为由处理器112执行如上所述的方法。
83.另外,本公开实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行以实现上述实施例所述的方法。
84.本公开做了以下实验对上述环境检测方法进行验证。
85.在实验中,我们分别为无故障等级和崩溃故障等级设计了相应的协议,针对于崩溃故障等级协议,我们利用参与者之间连接同步的性质,让参与者在彼此之间交换投票而非经过协调者,减少了事务执行需要的消息延时。针对于无故障等级协议,我们在崩溃故障等级协议的基础上,引入了隐含投票的技术,进一步减少了参与者之间的消息传输。针对于网络故障等级,我们直接使用了3pc。
86.我们将这些优化后的协议利用本公开中提到的环境监测方法整合为一个分布式事务提交协议并记作prac,基于此协议,我们进行了广泛的实验以评估环境监测方法带来的性能提高。
87.在下文中,介绍了实施细节和评估两个方面:
88.1.prac与2pc(二阶段提交)和3pc(三阶段提交)等标准协议以及目前最先进的协议之一g-pac(sujaya maiyya,faisal nawab,divyakant agrawal,and amr el abbadi.2019.unifying consensus and atomic commitment for effective cloud data management.proceedings of the vldb endowment 12,5(2019), 611
–
623.)的比较。我们还测试了g-pac的一个集中式变体,名为c-pac。
89.2.强化学习对提高prac在不稳定系统环境下适应性的效果。
90.(1)实验系统实现
91.我们使用golang和python实现了基于rlsm的分布式事务提交协议prac。我们的系统以类似percolator的方式处理事务,使用preread将分布式事务提交协议的工作限制在写入操作的提交,从而避免其他部分对实验比较的影响。所有协议都建立在同一个键值存储上,共享commit、rollback、preread等api,避免无关因素的影响。我们将数据库表的行映射成键值对,并根据数据的多少修改存储大小。对于二阶段提交,我们借鉴了 tidb(2021.tidb.https://github.com/pingcap/tidb.online;accessed:2021-09-01.) 中的实现设计,在2pc二阶段提交协议中,一条消息未回复时,将被重发三次。对于3pc 三阶段提交协议,我们采用了(suyash gupta and mohammad sadoghi.2018.easycommit: a non-blocking two-phase commit protocol..in edbt.157
–
168.)中提到的设计。g
‑ꢀ
pac的实现来自其作者sujaya maiyya,faisal nawab,divyakant agrawal,and amr elabbadi.2019.unifying consensus and atomic commitment for effective cloud datamanagement.proc.vldb endow.12,5(january 2019),611
–
623。我们还实现了g
‑ꢀ
pac的集中式版本,表示为c-pac,其中协议的头节点被固定为领导者。与pac类似,c
‑ꢀ
pac需要三个阶段来执行交易:(i)它从所有节点收集初始投票,(ii)在大多数节点上达成一致,以及(iii)异步发送决策到所有节点。
92.(2)实验设置
93.我们使用部署于四个不同数据中心的谷歌e2服务器进行了实验。其中包含一名协调者和三名参与者。这些数据中心位于a市(c1)、b市(c2)、c市(c3)和d市(c
*
)。我们使用d市(c
*
) 作为协调者节点,其他节点作为参与者节点。对于所有实验,我们使用计算优化型的e2中型机器,配备有2个vcpu、4gb内存、debian gnu/linux 10(buster)系统和10gb磁盘。
94.对于小规模测试,我们使用ycsb-like数据集[(sujaya maiyya,faisal nawab, divyakant agrawal,and amr el abbadi.2019.unifying consensus and atomiccommitment for effective cloud data management.proceedings of the vldbendowment 12,5(2019),611
–
623.),(brian f cooper,adam silberstein,erwintam,raghu ramakrishnan,and russell sears.2010.benchmarking cloud servingsystems with ycsb.in proceedings of the 1st acm symposium on cloud computing. 143
–
154.),(thamir m qadah and mohammad sadoghi.2021.highly availablequeueoriented speculative transaction processing.arxiv preprint arxiv:2107.11378(2021).)]来评估所有协议的性能。在测试中,客户端不断地用闭环线程产生读写多条记录的事务,而为了模拟实际环境,我们让90%的操作集中在10%的数据对象上。在原始的测试中,所有事务都是跨节点的,这可能无法很好地反映现实世界的操作。因此,在本实验中,我们让30%的事务只涉及单节点,其余的事务跨节点。对于大数据集,我们使用tpc-c,这是oltp系统的标准测试集,包括三种类型的读写和两种类型的只读事务。我们分别在三个数据中心建立仓库。每个仓库包含10个不同的区域,每个区域维护3000个客户的信息。我们使用不断向协调器发送事务的闭环线程来模拟客户端,并通过调整线程数目的方式控制数据量的大小。
[0095]
实验涉及到以下三组参数:(i)使用两个参数α
cf
和α
nf
来控制崩溃故障和网络故障
级别中向下转移所需要的连续无故障执行的次数。(ii)在实验中,我们创建了两种不同的环境:稳定环境和不稳定环境,来模拟现实世界中故障的发生。特别的,我们在不稳定环境中按照特定频率生成故障:每2τ秒为一个周期,系统会在前τ秒出现崩溃或网络故障,然后在剩余的τ秒内恢复正常。(iii)我们使用网络缓冲参数r来调整长消息传输的延迟。我们将r 与每两个参与者之间的最长消息延迟σ相乘来计算算法中使用的消息延迟上限。
[0096]
(3)稳定环境下的测试
[0097]
首先,我们在不会注入故障的稳定环境中评估了prac、2pc、3pc、g-pac和c-pac协议的表现。如图8所示,图8展示了这些协议在稳定环境下使用ycsb-like数据集测试得到的结果,横坐标为客户端数量(client number),(a)图中纵坐标为吞吐量(throughput), (b)图中纵坐标为延迟(latency)。在这里,prac展现了延迟和吞吐量上的显著提升。当有512个客户端(用虚线表示)时,prac与g-pac、c-pac、2pc相比,吞吐量分别提高了 2.30倍、2.67倍、2.47倍和1.62倍,而其延迟则分别为其他协议的94.8%、145.3%、 10.4%和22.8%。在这里,我们解释这种结果的成因。首先,prac优于2pc,这是因为prac是非阻塞的,因此它比2pc更不容易受到高争用下滞后消息的影响。此外,prac还优于3pc、 c-pac和g-pac,这要归功于其对于系统环境的自适应能力:在稳定环境中,prac切换到比其他协议更轻量级的无故障级别来处理事务。请注意在这个实验中,g-pac在延迟方面比2pc 获得了更多的优势,但在吞吐量方面却取得了更少优势,这与文献(sujaya maiyya, faisal nawab,divyakant agrawal,and amr el abbadi.2019.unifying consensus andatomic commitment for effective cloud data management.proceedings of the vldbendowment 12,5(2019),611
–
623.)中报道的结果略有不同。这是因为在我们实现的 2pc中每个事务被重试了3次,以更高的延迟为代价增加了吞吐量。c-pac的异步决策阶段降低了它的延迟开销。而且与g-pac相比,它在执行事务时不需要重新选举领导者,实现了比 g-pac更低的延迟。
[0098]
(4)不稳定环境下的测试
[0099]
我们通过将崩溃或网络故障注入节点和网络连接来评估不稳定环境中prac的表现。此故障注入由参数τ控制:故障一旦触发,将持续τ秒,周期为2τ秒。我们在所有机器启动5+2τ秒后进行实验,以确保结果稳定。每个协议运行10次并取平均结果。
[0100]
我们通过调整参数α
cf
和α
nf
以在级别转换开销和转换速度之间取得平衡。特别的,α
cf
和α
nf
控制rlsm需要看到多少无故障执行才能重置为无故障级别。我们在每次实验运行中固定α
cf
和α
nf
的值,而在不同实验组间改变它们,以探究该参数对协议的影响。在图9中,我们研究了不同环境稳定性下,不同α
cf
和α
hf
对于prac性能的影响。
[0101]
具体来说,图9(a)显示了崩溃失败(periodic crash failure)级别中不同α
cf
值下的吞吐量,可以观察到吞吐量随着α
cf
的增加先上升然后下降。我们将这种非单调趋势归因于增加α
cf
带来的两个相反的影响:首先,当α
cf
增加时,prac在rlsm转换到无故障级别之前需要更多的无故障执行,所以鲁棒性降级转换发生的频率变低。同时因为这一点,更少的事务将进入错误路径。图10(a)显示了当α
cf
增加时,进入错误路径的事务将会减少,也就是非必要鲁棒性降级转换和事务重新运行的减少。特别的,如图9(a)中的1s-cf线所示,当环境不稳定(τ=1s)时这种开销节省尤其明显。在此情况下,每2秒系统会出现持续1秒的崩溃故障,而prac的吞吐量随着α
cf
从1增加到16,从618tps提升到了778tps。另一方面,谨慎的鲁棒性降级转换损害了prac的适应性。rlsm更倾向于保持在更严格的级别,因此错过了使用轻
量级协议处理事务的机会,如图10(b)所示。对于所有的τ,prac的平均级别都随着α
nf
的增长而增长。这表明更多的事务在更严格的级别上进行了处理。它解释了为什么在τ为1s的情况下,随着α
nf
达到128,prac的吞吐量下降到了466tps。
[0102]
图9(b)报告了prac在不同α
nf
下的吞吐量(α
nf
控制网络故障级别的鲁棒性降级转换)。我们可以观察到prac总是偏好较小的α
nf
。在τ分别取1s、4s或16s时,prac总是在α
nf
接近1时达到其性能峰值。如虚线所示,它们的吞吐量分别达到了1540,1303和1273tps。我们将α
cf
和α
nf
的不同影响归因于性能增益的差异,也就是崩溃故障级别协议prac
cf
和网络故障级别协议prac
nf
之间的吞吐量差距。特别的,我们比较了prac的三个不可切换版本,它们分别运行在一固定等级。图11比较了将协议从崩溃故障级别(prac
cf
)或网络故障级别 (prac
nf
)切换到无故障级别(prac
ff
)的吞吐量增益。可以观察到,前者实现了大约1.6倍的吞吐量提高,而后者则高达2.14倍。这种差距解释了为什么prac总是更适合使用较小的α
nf
,即快速的鲁棒性降级转换。尽管错误假设和随之而来的代价高昂的纠正在增多,prac 依旧从更宽松的级别上获得了性能增益。
[0103]
我们在上述实验中已经证实,鲁棒性降级转换参数α
cf
很难调整。具体来说,图9(a) 显示了随着系统变得不稳定,α
cf
的最优值会从2变为16。这体现了手动调整参数的难度,并促使我们使用强化学习(rl)来根据系统的性能变化反馈调整参数。
[0104]
图10当α
cf
和α
nf
为强化学习所得、设置为1、设置为128时prac分别取得的吞吐量。特别的,强化学习分别对于环境1s-cf,4s-cf,16s-cf学到了α
cf
=16,4,1。而其分别对于环境1s-nf,4s-nf和16s-nf学到了α
nf
=1,2,2。
[0105]
图12(a)报告了当α
cf
和α
nf
为强化学习所得、设置为1、设置为128时prac分别取得的吞吐量。特别的,强化学习分别对于环境1s-cf,4s-cf,16s-cf学到了α
cf
=16,4,1。而其分别对于环境1s-nf,4s-nf和16s-nf学到了α
nf
=1,2,2。当α
cf
由强化学习(rl)调整时、固定为1时(快速鲁棒性降级转换)、固定为128(减少错误假设)时prac吞吐量的比较。我们可以观察到,在所有实验设置(故障以τ=1、4和16s周期性发生)中,rl调整的α
cf
总是能产生更好的吞吐量。更具体地说,当τ=1s时,rl学习的α
cf
取得了相比α
cf
=1而言 25.7%的吞吐量提升,当与α
cf
=128比较时,该提升量甚至到达了66.7%。特别的,进一步调查中我们发现学习到的α
cf
(平均值)在此设置中接近16。相对的,当τ=4s时该性能增益降低:使用学习到的参数仅将吞吐量提升了6.4%。这是因为此时学习到的α
cf
为4,接近固定值α
cf
=1,从而只带来了很小的性能差异。尽管如此,其的吞吐量仍然比α
cf
=128高39.1%。最后,当τ=16s时,学习参数和α
cf
=1取得了相同的性能(779tps)。这是符合我们的预期,因为在此时学习到的参数为1,与固定α
cf
=1的效果完全相同。此外,它们都相比α
cf
=128 提高了21.9%的吞吐量。总体而言,该实验表明使用rl在崩溃故障级别中调整α
cf
可以产生比将α
cf
分配给固定值更好的结果。
[0106]
此外,我们还应用rl来调整了α
nf
,并将其吞吐量与α
nf
固定为1和128时做了比较。图 12(b)显示了实验结果,使用rl调整α
nf
参数时的吞吐量明显优于α
nf
=128时的吞吐量,然而相比α
nf
=1时,其吞吐量稍稍落后而接近。特别的,当τ配置为1s时,由rl调整的α
nf
和α
nf
=1产生了相似的吞吐量(1540tps)。这是因为在此设置中,学习到α
nf
的值也是1。我们在前面的图9(b)中描述了对于τ=1、4和16s的最优参数选择,其中α
nf
=1为最优值。这意味着rl仍然可以帮助我们将α
nf
调整到接近最优值:它可以产生几乎与最佳设置α
nf
=1 一样高的
吞吐量。不过,在实践中,我们建议在配置参数α
nf
时直接将其设置为1,以支持快速的鲁棒性降级转换,获得最佳性能。
[0107]
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
[0108]
最后应说明的是:以上各实施例仅用以说明本公开的技术方案,而非对其限制;尽管参照前述各实施例对本公开进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本公开各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1