基于联邦学习与深度神经网络的区域光伏发电预测方法与流程
1.本发明涉及电力系统光伏发电预测方法,属于基于联邦学习的区域分类光伏发电量协同预测方法。
背景技术:
2.为了实现碳中和目标,可再生能源的利用受到越来越多的关注。其中,太阳能被证明为最清洁,最丰富的的能源之一。利用太阳能进行光伏发电可以减少化石燃料的使用,降低碳排放。然而,太阳能的波动性为光伏电站发电计划的制定带来巨大挑战,精准预测光伏发电出力,对保证电网的稳定运行意义重大。
3.传统的光伏发电功率预测方法可分为物理法和统计法。前者需要测量有关的基础服务设施和相关设备,后者通过对历史样本进行特征提取,利用最小化误差进行光伏功率预测。但两者分别存在基础设备要求过高,预测准确度较低的问题。
4.近年来,神经网络与支持向量机等机器学习方法被广泛应用于预测场景,该方法在光伏功率预测领域同样备受关注。《利用svm-lstm-dbn的短期光伏发电预测方法》利用深度信念网络(dbn)耦合支持向量机(svm)和长短期记忆神经网络(lstm),提出一种新的光伏功率组合预测方法,其组合方法与单一模型相比,精度明显提高。《基于miv分析的ga-bp神经网络光伏短期发电预测》提出一种结合spearman相关系数显著性检验与利用欧氏距离计算变化因子改进改进miv(mean impact value)算法的ga-bp神经网络光伏短期发电预测的方法;《probabilistic forecasting of photovoltaic generation:an effificient statistical approach》提出了一种基于极值学习机和分位数回归的光伏发电量预测方法,建立了基于线性规划的光伏发电预测区间构建模型,准确量化了光伏发电系统发电量的变异性和不确定性。
5.但这些对于光伏预测的研究,其研究对象主要为一个预测点,即根据预测点的历史气象数据、发电量等预测未来一段时间的光伏发电量。然而,单点的光伏功率往往受到波动的气象因素影响较大,其结果与实际发电量存在较大差异。同时,近年来备受关注的神经网络预测方式,虽然提高了光伏预测的准确度,但是训练神经网络需要较大的运算能力,对于每个需要预测的点均搭建运算装置,成本过高。同时,存在一定的“数据孤岛”问题,不同区域的气象数据与光伏发电数据无法互通,导致数据不能被充分利用。
6.也有一些研究者提出,将各点数据合并到中央服务器进行统一的模型训练,但会导致各地数据传输过程中的数据泄露和隐私泄露问题,因此,将原始数据直接进行远程传输合并无法有效解决问题。
技术实现要素:
7.本发明要解决的技术问题是,克服现有技术中的不足,提供一种基于联邦学习与深度神经网络的区域光伏发电预测方法。
8.为解决技术问题,本发明的解决方案是:
9.提供一种基于联邦学习与深度神经网络的区域光伏发电预测方法,包括以下步骤:
10.(1)计算电力系统中各光伏预测点的气象变量与光伏发电量之间的皮尔逊相关系数,根据计算结果对各光伏预测点进行分类,分类类别的个数为n,n≤9;
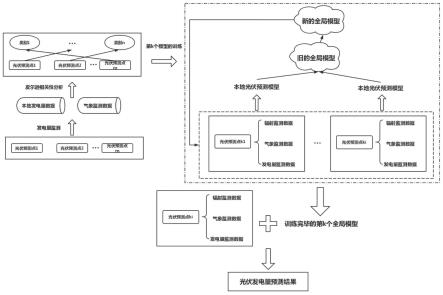
11.(2)基于联邦学习框架,在各光伏预测点的边缘计算装置上建立本地神经网络模型,在云端服务器建立全局神经网络模型,各神经网络模型均具有相同的网络结构;
12.(3)在云端服务器中对神经网络模型的模型参数进行初始化,然后下发至各光伏预测点的本地神经网络模型;
13.(4)利用下发的模型参数和本地数据,对各本地神经网络模型进行训练,并将更新后的模型参数上传至云端服务器;
14.(5)按步骤(1)中所述分类类别对来自各本地神经网络模型的参数进行分类,然后分别采用fedavg算法进行聚合计算;利用计算所得模型参数形成n个不同类别的全局神经网络模型,更新后的全局模型参数被存储起来;判断各本地神经网络模型的训练是否终止,若未终止则重复进行聚合计算,直到训练终止;
15.(6)将所存储的全局模型参数根据各光伏预测点的分类类别进行下发,并对本地神经网络模型进行参数更新,利用本地发电量数据进行区域光伏发电量的预测。
16.与现有技术相比,本发明的技术效果是:
17.(1)利用皮尔逊相关系数,依据气象变量温度、风速对光伏发电量的影响对光伏预测点进行分类,提高预测模型与预测点的匹配度,提高了预测精度。同时,在新的光伏预测点接入时,可以直接采用对应分类的网络进行预测,节省了二次训练所需时间。
18.(2)利用云边协同的思想对多居民区进行联合负荷预测模型的训练,规避了传统模型训练方法中光伏预测点边缘计算装置算力不足,数据不够等问题。
19.(3)联邦学习将光伏点数据留在本地,只传输模型参数,避免了通信过程中的大规模数据传输,显著降低了通信耗时与通信所需带宽,提高了模型训练效率与经济性。
20.(4)在模型训练之前,利用气象数据对预测点进行分类,在网络训练过程中,避免了额外气象数据的输入,降低了lstm网络的输入维度,显著降低了模型训练时间,提高模型训练效率。
附图说明
21.图1为本发明实现的流程图。
22.图2为autoencoder-lstm模型架构示意图
23.图3为示例的三种类别的光伏预测点网络训练过程示意图。
具体实施方式
24.本发明提出基于联邦学习的区域分类光伏发电量协同预测方法,首先计算系统中各光伏预测点的气象变量与光伏发电量之间的皮尔逊相关系数,对光伏预测点进行分类,并在云端进行所有分类对应的神经网络初始化。基于联邦学习框架,利用本地数据对光伏预测点的局部模型进行训练,仅传输模型参数而非训练数据,达到了保护数据隐私的目的;同时,分类算法使得光伏预测点与其预测模型更加匹配,提高发电量预测的精度。
25.本发明提供的联邦学习与深度神经网络的区域光伏发电预测方法,包括以下步骤:
26.1、计算电力系统中各光伏预测点的气象变量与光伏发电量之间的皮尔逊相关系数,根据计算结果对各光伏预测点进行分类。
27.(1)皮尔逊相关系数的计算与光伏预测点的分类;
28.虽然rnn、lstm等时序神经网络能够有效对时间序列进行预测,然而无关特征数据的输入往往会增加训练时间,降低训练精度,影响模型效果。因此,本发明在将气象数据如辐射强度作为特征量输入本地模型之前,采用皮尔逊相关系数对各种气象数据与光伏发电量的相关性进行具体分析,选择最相关的气象变量输入网络进行预测。
29.皮尔逊相关性系数r根据下面的公式(1)计算:
[0030][0031]
式中,(xi,yi)与分别为第i组样本数据以及样本数据的平均值;n为待分析样本的数据组数。
[0032]
光伏发电量受到气象因素的影响较大,不同区域由于地理位置,环境等差异,导致气象因素对光伏发电量的影响不同。为了在预测模型中进行区分从而提高预测精度,可以基于三种气象数据:总辐射、风速及温度与光伏发电量计算的皮尔逊相关系数,对光伏预测点进行分类。由于光伏发电量与太阳能总辐射的强正相关关系已经被证明,因此本发明依据温度与风速对光伏预测点进行分类,分类标准如表1所示。对系统中所有光伏预测点进行分类后,包含的类别个数为n(n≤9,n为正整数),存储在云端服务器的用于预测的初始本地神经网络模型数量也为n。
[0033]
表1依据温度、风速进行的光伏预测点分类
[0034][0035]
(2)基于联邦学习框架建立本地神经网络模型和云端全局神经网络模型;
[0036]
在本发明中,包括分设于各光伏预测点的边缘计算装置上的本地神经网络模型,以及设于云端服务器的全局神经网络模型;各神经网络模型均具有相同的网络结构,并模拟联邦学习框架进行布置。各神经网络模型均采用长短期记忆神经网络模型(long short-term memory,lstm)。lstm在循环神经网络(recurrent neural network,rnn)的基础上,引入了记忆单元,克服了rnn中存在的“遗忘”缺陷,同时具有强大的时序预测能力。光伏发电
量为时序变量,同时具有波动性和随机性,采用lstm可以进行较为精确的预测。例如,神经网络可以用以前三个时间点的光伏发电量与当前光照辐射量为输入变量,预测后三个时间点的光伏发电量。
[0037]
神经网络模型主要由autoencoder层、lstm以及输出层组成。autoencoder层提取原始数据的隐含特征作为lstm层的输入,lstm对输入数据进行分析后得到预测结果,最终由输出层输出最后的结果。autoencoder-lstm结构示意图如图2所示。
[0038]
(3)对本地神经网络模型的模型参数进行初始化与下发
[0039]
在云端服务器中,对神经网络模型的模型参数进行初始化,经过同态加密算法进行数据加密后,再下发至各光伏预测点的本地神经网络模型;由于各模型具有相同的网络结构,因此模型参数可以直接迁移。
[0040]
同态加密的过程主要由四个部分组成:密钥的生成、同态加密、同态赋值以及同态解密。
[0041]
(4)本地模型的训练和模型参数的上传;
[0042]
利用本地数据和云端服务器下发的模型参数,对各光伏预测点的本地神经网络模型进行训练,并将更新后的模型参数上传至云端服务器;
[0043]
(5)模型参数的聚合计算
[0044]
云端服务器收到各光伏预测点上传的本地模型参数后,先按步骤(1)中所述分类类别对来自各本地神经网络模型的参数进行分类,然后分别采用fedavg算法进行聚合计算。利用计算所得模型参数形成n个不同类别的全局神经网络模型,更新后的全局模型参数被存储起来;判断各光伏预测点的本地神经网络模型的训练是否终止,若未终止则重复进行聚合计算,直到训练终止。
[0045]
febavg算法通过使用下面的公式来更新全局模型:
[0046][0047]
其中,g
t
表示第t轮聚合之后的全局神经网络模型,l
t+1i
表示第i个用户端在第t+1轮本地训练更新后的模型,g
t+1
表示第t+1轮聚合之后的全局神经网络模型;λ表示设置的更新系数;m表示参与训练的客户端总数。
[0048]
(5)模型参数的下发和发电量预测
[0049]
待各光伏预测点的模型训练完毕之后,将云端服务器上经聚合计算、最终更新后的n个全局神经网络模型所生成的新模型参数进行存储;然后根据各光伏预测点的分类类别,向各光伏预测点的边缘计算装置进行下发。各本地神经网络模型在更新参数后,将利用本地发电量数据进行区域光伏发电量的预测。
[0050]
在下发模型参数时,归属不同分类类别的光伏预测点会收到对应的模型参数;如果某区域不存在某些分类类别的光伏预测点,则云端服务器在收到相应反馈后,在下轮训练后不再将该分类类别的模型参数下发给该光伏预测点;如果某区域存在增加光伏预测点的情况,则首先对增加的光伏预测点进行皮尔逊相关系数的计算和分类,全局神经网络模型在收到反馈后对分类类别的个数进行更新,并在下轮训练后由云端服务器下发更新后的模型参数。
[0051]
具体应用示例:
[0052]
本实例中,利用python中的pytorch建立本地神经网络模型,同时模拟联邦学习的环境,在各光伏预测点的边缘计算装置上分别建立边缘客户端,在云端服务器上建立中心客户端,以实现云边协同场景下基于联邦学习的区域分类光伏发电量协同预测系统。
[0053]
下面,利用某地区20个光伏预测点的光伏数据与气象数据,对预测点进行光伏电量的预测。其中,光伏数据10min采集一次,气象数据为:太阳辐照度(w/m2),环境温度与环境风速,每10min采集一次。
[0054]
首先计算这20个光伏预测点的温度、风速与光伏发电量之间的皮尔逊相关系数,结果如表2所示。
[0055]
表2光伏预测点分类结果表格
[0056][0057]
根据表2中的分类结果,其中,属于类别2的光伏预测点的个数为14个,属于类别5的光伏预测点的个数为4个,属于类别1的光伏预测点的个数为2个,表3展示了三个类别的光伏预测点及其对应的预测点序号。
[0058]
表3三种光伏预测点对应序号
[0059][0060]
因此,在云端服务器中建立3个初始状态的全局神经网络模型(autoencoder-lstm),分别标识为模型a、b、c,依据本发明提出的学习与训练方法,将三个全局模型的模型参数分别下发至3个类别对应的边缘计算装置。在各光伏预测点分别使用本地数据,以前三个时间点的光伏发电量及当前辐射强度为输入变量,以后三个时间点的光伏发电量对a、b、
c三个模型进行训练。将训练完的新的局部模型参数传至云端,云端分别进行三个模型参数的聚合,生成新的全局模型a、b、c。重复上述训练步骤,最终得到适用于3个类别的全局预测模型。将各种模型参数下发至对应的各预测点,分别用于预测任务。
[0061]
在模型运用过程中,首先将前三个时间点的光伏发电量和当前辐射强度输入,得到后三个时间点的预测光伏发电量。同时,若模型训练完毕之后,新加入了属于类别1,2,5的光伏预测点,可直接使用对应的原有的预测模型进行预测,因为经过前期的预测点分类,模型a、b、c具有较强的针对性。
[0062]
图3展示了三种类别光伏预测点网络训练过程,类别2的训练精度下降较快,因为类别2包含更多的预测点,数据量更充足。
[0063]
表4类别5光伏预测点验证集结果
[0064]
光伏预测点序号10131921验证集mse0.00430.00280.00330.0059
[0065]
考虑新接入光伏预测点,序号为21,属于类别5,表4展示了序号10、13、14、19、21对应的验证集预测结果,可以看出,即使21预测点没有参与模型训练,由于前期的预测点分类,21预测点同样表现出较高的预测精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1