一种附加时间信息的电磁空间领域实体关系联合抽取方法
本发明属于电磁空间、深度学习,涉及一种附加时间信息的电磁空间领域实体关系联合抽取方法,涉及自然语言处理有关的研究和分析,具体涉及短文本的命名实体识别和关系识别。
背景技术:
1、面向电磁空间领域的实体及关系抽取任务是电子情报分析、构建电磁空间领域知识图谱的基础工作之一,是建立电磁画像的核心工作。雷达是电磁空间中重要的军事实体,其往往装载在飞机、舰艇等电子目标上。结合战场环境下捕获的敌方雷达波信息,分析电子情报中雷达装备平台的态势分布,能够有效地估计敌方作战行动及意图,有助于军事决策制定,具有重要的国防军事意义。微博等社交平台上存在着大量军事相关的信息,这些信息包含多作战空间,数据量大、实时性高,能够作为辅助信息源,扩充电子情报数据,对军事研判和战场态势分析有着重要的意义。
2、面向互联网开源数据的电磁空间领域实体关系抽取存在着军事实体别称多、表达不一致等问题。同时,还存在着实体嵌套和关系重叠现象。以往的实体关系抽取任务通过流水线模型或二阶段联合抽取模型来完成,前者存在误差累积问题,后者存在曝光偏差问题。针对移动电子目标,电磁空间领域的信息抽取还面临着传统信息抽取难以表示实体关系动态变化的问题。
技术实现思路
1、为了解决现有技术存在的不足,本发明的目的是提供一种附加时间信息的电磁空间领域实体关系联合抽取方法,包括以下步骤:
2、步骤a:利用python爬虫技术获取社交平台开源文本数据;
3、步骤b:对步骤a中获得的开源文本进行文本清洗、预处理,形成数据集c;
4、步骤c:确定实体和关系分类,制定实体关系序列联合标注策略,将句子中包含的各类关系及其所包含的实体进行标注;
5、步骤d:为步骤b中的所述数据集c打上三元组标签;所述三元组标签为(主实体subject,关系predicate,客实体object);
6、步骤e:构建基于片段排序的实体关系联合抽取模型sterm,并训练得到实体关系三元组预测模型;
7、所述片段排序是指按照输入句子的语序排序的字符对标签序列:所述字符对标签序列包括eh-et(实体头-实体尾),以及输入文本中所含的每个关系所对应的sh-oh(主体头-客体头)、st-ot(主体尾-客体尾)序列。
8、步骤f:通过时间实体距客实体顺序优先的就近匹配算法得到预测的时间、主实体、关系、客实体四元组列表。
9、本发明步骤b进一步包括如下步骤:
10、步骤b1:通过正则匹配对原文本中存在的tag标签、html链接、视频链接、@其他博主、emoji表情等不规范表达进行去除;
11、步骤b2:将文本中存在的希腊拉丁字符转换为英文字母;
12、步骤b3:使用python的re模块,以句末标点“。?!”为边界对语料集进行分句;
13、步骤b4:对分句后的语料集进行筛选,通过包含“飞机”,“舰船”,“舰”,“艇”,“船”,“航母”,“机”,“车”,“导弹”,“起飞”,“到达”,“无人机”,“战斗机”,“部队”,“海”,“上空”,“港口”,“机场”,“基地”的关键词列表去除与电子目标无关的语料;
14、步骤b5:统计分析分句后的语料集中各语料的长度,由于部分微博长度较少,句子中包含完整三元组的可能较低,为了减少数据集标注的工作量,删去文本长度小于10的语料,形成数据集c。
15、本发明步骤c中为电磁空间领域实体关系联合标注策略制定阶段,步骤c中涉及的标注策略包括:
16、步骤c1:定义了实体类别,实体类别包括:“人员名称”、“军事地名”、“时间”、“军衔或军职”、“军事组织或机构”、“港口”、“机场”、“军事基地”、“军事事件”、“武器装备”、“飞机”、“舰艇”、“型号”、“编队”、“舰级”;
17、步骤c2:定义了关系类别,分为静态关系和动态关系两类。静态关系包括:“共指”、“层级”、“位于”、“隶属于”、“属于……编队”、“母港/基地”、“搭载”、“发生地”,动态关系包括:“指挥”、“执行”、“结束执行”、“出发”、“出现在”、“将要去”、“曾经在”、“到达”。
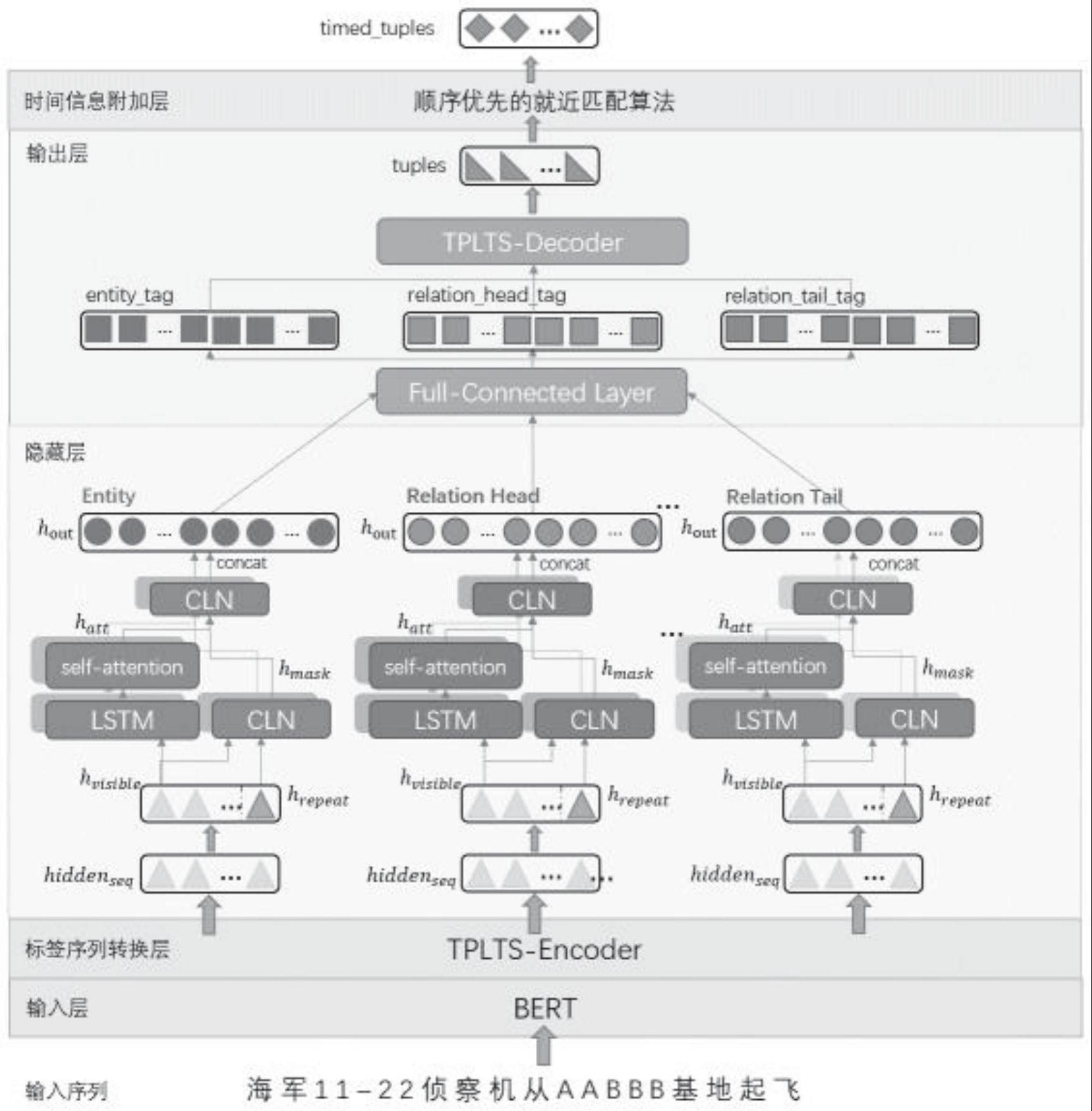
18、本发明步骤e中为构建基于片段排序的实体关系联合抽取模型sterm阶段,模型结构图如图1所示,步骤e包括:
19、步骤e1:sterm联合抽取模型的输入部分将步骤b预处理得到的数据集c作为sterm的输入,由于bert原分词函数不能将英文或数字表述按照字符切分,如“p-8a”被切分为“p”、“-”、“sa”,为了保证其形式与标注语料一致,sterm联合抽取模型重写了bert的分词函数,使其严格按照字符来对输入序列进行分字,输入序列经过bert中n层transformer机制,学习每个字符的上下文特征,构建输入序列的字符向量表示为集合b;
20、步骤e2:构建sterm模型的序列标签转换层,用于将输入的实体关系三元组的中的实体起始及结束位置标签序列转换为片段排序的eh-et(实体头-实体尾)、sh-oh(主体头-客体头)、st-ot(主体尾-客体尾)序列,所描述的eh-et序列表示实体起止位置序列,sh-oh序列表示关系对应的实体起始位置序列,st-ot序列表示关系对应的实体结束位置序列,标签序列转换示意图如图2所示,根据输入语句的语序,将句子中的每个字符分别匹配形成字符对,将各实体的eh-ht标记为1,将各关系类别的sh-oh、st-ot标记为1,从输入标签序列转换为片段排序的下标转换公式为:
21、其中,x指的是枚举实体标签过程中累加的子序列,i表示实体开始位置在原始输入文本中的下标,j表示实体结束位置在原始输入文本中的下标,n表示原序列的长度。对于实体标签来说,将index位置标记为1;对于关系标签来说,当i≤j时,index位置标记为1,当i>j时,index位置标记为2。输出转换后的序列标签t′=[eh-et,sh-oh,st-ot];
22、步骤e3:构建sterm模型的隐藏层,用于学习原始输入文本序列的上下文信息,将原始文本输入经过bert编码得到字向量hiddenseq,为了预测标签序列,需要将子向量序列hiddenseq与片段排序后的标签序列对齐,即如附图3(b)所示对字向量进行拼接得到[hvisible,hrepeat],其中可见向量hvisible对应图中右上三角的字向量,hrepeat对应图中左下角的字向量;对于每个输入序列hiddenseq和对应的2n+1个标签序列t′,即1个[eh-et]序列,以及n种关系,每种关系对应的一组[sh-oh,st-ot]序列,模型构造独立的2n+1个隐藏层结构。每个隐藏层结构相同,通过条件层归一化(conditional layer normalization,cln)将hvisible与hrepeat正交相乘得到遮罩后的序列hmask,防止后续lstm网络发生梯度消失或是梯度爆炸;通过带自注意力机制的双向长短期记忆lstm网络将hvisible进一步编码为hatt;对lstm输出的特征进行dropout操作,随机删去部分节点(约30%)特征减少负样本对模型训练的影响;将hmask与hatt通过cln正交相乘得到隐藏层的输出hout;最终拼接2n+1个隐藏层的输出得到
23、步骤e4:构建sterm模型的输出层,输出预测标签序列p=[peh-et,psh-oh,pst-ot],其中实体序列peh-et每一位置的取值为[0,1],关系序列psh-oh,pst-ot每一位置的取值为[0,1,2];通过解码算法将片段排序下标转换为输入序列下标,得到预测三元组列表triples;
24、步骤e4中的解码算法进一步包括:
25、步骤e4_1:解码peh-et,得到句子中所有实体,用实体头部字符作为key,实体作为value存入字典d中;
26、步骤e4_2:遍历关系集合r,解码各关系的pst-ot序列,得到实体尾字符对并存入该关系对应的集合e中;解码各关系的psh-oh序列,得到实体头字符对,将该字符对与字典d关联,得到该关系对应的实体对集合s;
27、步骤e4_3:遍历各关系的实体对集合s并查询实体尾字符对e即可解码得到可能的三元组。
28、步骤e2所构建的标签序列转换层将输入序列下标转换为三种标注序列类型并转换为片段排序下标,具体步骤包括:
29、步骤e2_1:定义了三种标注序列类型eh-et、sh-oh、st-ot:采用片段排序的方式对输入序列进行转化,分别表示实体起止位置序列(eh-et)、关系的主体起始下标到客体起始下标序列(sh-oh)、关系的主体结束下标到客体结束下标序列(st-ot);
30、步骤e2_2:设计了词语对链接标注策略tplts:对于一条长度为p的句子s=[w1,w2,...,wp],该句子对应的片段排序s′=[s1,1,s1,2,...,s1,p,s2,1,...sp,p],片段排序的长度为p×p,其中si,j表示从wi到wj的片段序列。对于给定的m种实体类别和n种关系类别可以对应生成2n+1条序列;对于序列中所有实体e=[e1,e2,...,en],每个实体e=span(wi,wj)对应eh-et序列中的si,j位置,标记为“1”;对于序列中的所有关系,每个关系表示为一个三元组triple=<subj,pre,obj>,其中subj表示关系主体,pre表示关系类别,obj表示关系客体,给定一个三元组subj=span(wsh,wst),obj=span(woh,wot),对应的关系为predicate,即在predicate关系的sh-st序列ssh,st位置,oh-ot序列的soh,ot位置标记为“1”;
31、步骤e2_3:设计优化后的标注策略:原始标注策略需要枚举每个字符对应的标签序列,枚举后得到的标签为p×p的矩阵,该矩阵的左下三角包含的“1”标签只可能是客实体出现在主实体前的情况,这种情况可以使用对角线翻转来进一步优化内存,本方法将主体在客体后面出现的关系按照对角线翻转到p×p矩阵的右上部分,并将标记置为“2”,将p×p矩阵优化为长度为p×(p-1)/2的序列,优化后的序列示意图如图3所示。
32、步骤f中为顺序优先的就近匹配算法,包括:
33、步骤f1:构建顺序优先的就近匹配算法,在步骤e4中的sterm模型预测阶段,算法的输入为原始文本序列seq,预测三元组triples,原始文本对应的时间实体列表timelist,原始文本对应的在社交平台的发表时间time;
34、步骤f2:判断当前关系是否为动态关系,若为静态关系则直接返回;若为动态关系则执行步骤f3;
35、步骤f3:判断当前timelist列表是否为空,若为空则将社交平台的发表时间time转换为标准时间格式并赋值给triple;若不为空则记录当前三元组triple客体的开始位置objstartindex和结束位置objendindex;
36、步骤f4:从后往前遍历timelist找到第一个在客实体前面的时间实体;如果找不到再从前往后遍历timelist找到第一个在客实体后面的时间实体;将找到的时间实体赋值给三元组triple得到时间三元组timedtriple。
37、本发明还公开了上述方法在从各类情报源中获取雷达型号及装备平台等实时动向,从而进行电磁目标的情报生成、更新雷达态势情报、雷达态势智能分析可视化等中的应用。
38、本发明还提出了一种设备,包括:存储器和处理器;所述存储器上存储有计算机程序,当所述计算机程序被所述处理器执行时,实现上述方法。
39、本发明还提出了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述方法。
40、本发明的有益效果为:现有方法使用序列标注的形式来完成实体、关系的三元组抽取,但是序列标注在处理嵌套实体时表现不佳,如对于实体——aabbb空军基地,序列标注只能将整个标注为基地,无法同时对aa这个地名进行标注;关系重叠问题指不同的关系三元组都含有同一实体,如空军132中队的11-22飞机从aabbb基地起飞,该句中包含三元组(11-22,隶属于,空军132中队)、(11-22,从...出发,aabbb基地),序列标注方法无法同时为11-22预测两个标签。相比于现有方法,本发明构建的sterm模型不再使用传统的序列标注方法,而是将其转换为实体的起始-结束下标预测任务,有效解决关系重叠和实体嵌套问题。相较于现有模型,sterm模型构建了单阶段端到端的模型结构,解决了现有流水线模型和二阶段联合抽取模型带来的误差累积和曝光偏差问题。
- 还没有人留言评论。精彩留言会获得点赞!