一种基于计算机系统的大数据分析存储系统及方法与流程
1.本发明涉及大数据存储技术领域,具体为一种基于计算机系统的大数据分析存储系统及方法。
背景技术:
2.随着信息技术的快速发展,人们的日常活动会产生大量的数据信息,为更好地搜集、处理及应用这些数据,需要将大数据存储到计算机系统中,随着需要存储的数据量越来越大,传统的将数据集中存储技术已经无法满足井喷式的数据量增长,将数据进行分散存储,有效减轻了存储设备的压力;
3.然而,现有的分散存储数据方式仍然存在一定的弊端和挑战:首先,为满足的数据存储性能,通常会增加存储节点,但是,存储节点的增加导致了数据服务间的链路变多、变长,在存储节点发生故障时的排查难度急剧增长,在无形中提高了故障率;其次,在数据存储时只考虑到数据的重要性,忽略了存储节点的故障情况,导致数据出现丢失的可能性加剧;最后,由于数据过度分散存储,在调取多方数据时需要从不同的存储节点调取,延长了数据调取时间。
4.所以,人们需要一种基于计算机系统的大数据分析存储系统及方法来解决上述问题。
技术实现要素:
5.本发明的目的在于提供一种基于计算机系统的大数据分析存储系统及方法,以解决上述背景技术中提出的问题。
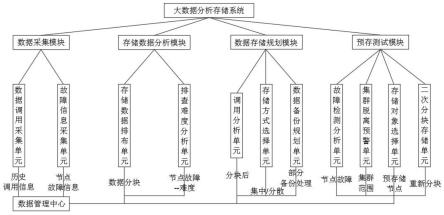
6.为了解决上述技术问题,本发明提供如下技术方案:一种基于计算机系统的大数据分析存储系统,其特征在于:所述系统包括:数据采集模块、数据管理中心、存储数据分析模块、数据存储规划模块和预存测试模块;
7.所述数据采集模块用于采集待存储数据的历史调用信息和存储节点的故障信息;
8.所述数据管理中心用于存储并管理所述数据采集模块采集到的所有信息;
9.所述存储数据分析模块用于分析调用信息和故障信息并将数据进行分块;
10.所述数据存储规划模块用于选择存储方式并对部分数据进行备份处理;
11.所述预存测试模块用于测试数据存储情况,规划数据存储位置。
12.进一步的,所述数据采集模块包括数据调用采集单元和故障信息采集单元,所述数据调用采集单元用于采集待存储数据的历史调用次数和调用所需时间信息;所述故障信息采集单元用于采集当前已有的存储节点的历史发生故障的次数以及故障影响范围信息,将采集到的所有数据传输到所述数据管理中心中。
13.进一步的,所述存储数据分析模块包括存储数据排布单元和排查难度分析单元,所述存储数据排布单元用于调取并分析待存储数据的历史调用信息,将待存储数据进行分块;所述排查难度分析单元用于若分块后的数据存储到对应节点中,分析在不同存储节点
发生故障时排查故障原因的困难程度。
14.进一步的,所述数据存储规划模块包括调用分析单元、存储方式选择单元和数据备份规划单元,所述调用分析单元用于分析分块后待存储数据的调用频繁程度和历史调用时的信息丢失情况,得到分析结果;所述存储方式选择单元用于依据分析结果为待存储数据选择不同的存储方式;所述数据备份规划单元用于依据分析结果将部分数据进行备份处理。
15.进一步的,所述预存测试模块包括故障检测分析单元、集群脱离预警单元、存储对象选择单元和二次分块存储单元,所述故障检测分析单元用于测试数据存储情况,在数据预存储过程中对存储节点进行实时故障检测;所述集群脱离预警单元用于在存储节点脱离集群时进行预警;所述存储对象选择单元用于统计存储节点在测试过程中脱离集群的次数、以及历史故障次数,并依据在测试过程中的调用信息分析待存储数据的重要程度;所述二次分块存储单元用于对待存储数据进行重新分块并存储到对应节点中。
16.一种基于计算机系统的大数据分析存储方法,其特征在于:包括以下步骤:
17.s1:采集数据调用信息和存储节点故障信息;
18.s2:分析数据调用信息和故障信息,将待存储数据进行分块处理;
19.s3:分析分块后数据的调用信息,选择不同的存储方式;
20.s4:对部分待存储数据进行备份处理;
21.s5:测试分块后数据存储情况,规划数据存储对象,将数据重新分块后进行存储。
22.进一步的,在步骤s1-s2中:采集到不同待存储数据历史被调用的次数集合为m={m1,m2,...,mn},其中,依据调用次数的不同共分为n种待存储数据,在对应数据被调用过程中出现信息丢失的次数集合为n={n1,n2,...,nn},在出现信息丢失后对应数据被调用的次数集合为n’={n1’,n2’,...,nn’},信息丢失前后被调用数据的关联系数集合为sim={sim1,sim2,...,simn},采集到当前已有的存储节点历史发生故障次数集合为m={m1,m2,...,mp},对应存储节点发生故障时修复需要的平均时间集合为t={t1,t2,...,tp},其中,p表示除存储元数据的主节点外的存储节点数量,根据下列公式计算随机一种待存储数据的重要系数wi:
[0023][0024]
其中,mi表示随机一种待存储数据历史被调用的次数,ni表示随机一种待存储数据在被调用过程中信息丢失的次数,ni’表示对应信息丢失后对应数据被调用的次数,simi表示在信息丢失前后随机一种待存储数据中被调用的数据的关联系数,得到待存储数据的重要系数集合为w={w1,w2,...,wn},将待存储数据进行分块处理:分为k块,随机选取k种数据,k种数据的重要系数集合为w={w1,w2,...,wj,...,wk},其中,根据下列公式判断随机一种待存储数据的所属块:
[0025][0026]
其中,ai表示k个分块中数据重要系数与随机一种待存储数据的重要系数差值最小的块,ai的值是w中的一个,将ai的值与w中的元素进行匹配,得到与ai的值相等的重要系
数为wj,将对应待存储数据归为第j块,在存储空间充足的前提下,按照待存储数据的重要系数将数据进行分块存储,在调用次数的基础上考虑到历史数据被调用时存在一定的数据丢失的问题,若丢失的是关键数据,会再次对同样的数据进行调用,在一定程度上反映出数据的重要程度,计算重要系数的目的在于将其作为分块依据,同时,考虑到数据可能存在过度分散的问题,将重要数据进行聚类存储,有利于减少数据服务间的链路,进一步减轻了故障时的排查难度。
[0027]
进一步的,在步骤s3-s4中:分析分块后数据的调用信息:获取到将数据分为k块进行存储后,随机一块数据被单独调用的次数为ei,被同时调用的次数为fi,根据公式选择k块待存储数据的存储方式:若pi》1,将对应块数据进行单独存储;若pi≤1,将对应块数据与和对应数据被同时调用的数据进行集中存储,对部分待存储数据进行备份处理:比较n种待存储数据的重要系数,将重要系数大于的数据进行备份处理。
[0028]
进一步的,在步骤s5中:测试数据存储情况:在数据预存储过程中对存储节点进行实时故障检测,在检测到存储节点无响应时,判断对应存储节点脱离集群,发送预警信号,同时统计到存储节点在测试过程中脱离集群的次数集合为l={l1,l2,...,lp},记录到在测试过程中存储节点的被访问次数集合为q={q1,q2,...,qp},根据下列公式计算当前已有的随机一个存储节点的存储可靠系数ki:
[0029][0030]
其中,mi表示对应存储节点历史发生故障的次数,li表示对应存储节点在测试过程中脱离集群的次数,ti表示对应存储节点发生故障时修复需要的平均时间,qi表示在测试过程中对应存储节点被访问的次数,得到可靠系数集合为k={k1,k2,...,kp},在数据分块后,对数据存储过程进行测试,有利于为对应数据选择合适的存储对象,在计算存储节点可靠系数的同时,考虑到可靠系数不仅受到测试过程中故障情况影响,同时也与历史存储节点存储数据的故障情况影响,提高了计算结果的准确性。
[0031]
进一步的,规划数据存储对象:将数据重新分块:获取到进行单独存储的数据的重要系数集合为w’={w1’,w2’,...,we’},其中,集中存储到同一位置的数据的平均重要系数集合为w
集
={w
集1
,w
集2
,...,w
集q
},其中,e表示单独存储的数据块数,q表示集中存储的数据块数,比较数据的重要系数:将最大系数对应的数据存储到最可靠的存储节点中,最大系数为w
max
,最大可靠系数为k
max
,将存储节点按可靠系数从大到小排列,剩余数据依据重要系数从大到小依次存储到存储节点中,数据分块后调用数据出现了变化,分析分块后数据的被调用情况,为数据选择集中和分散存储两种存储方式,为数据分块后调用提供了便利,将数据的重要系数和存储节点的可靠系数进行匹配,将重要的数据存储到可靠的存储节点中,降低了数据丢失的概率。
[0032]
与现有技术相比,本发明所达到的有益效果是:
[0033]
本发明通过采集分析历史数据,按照待存储数据的重要系数将数据进行分块存储,在调用次数的基础上考虑到历史数据被调用时存在一定的数据丢失的问题,结合数据丢失再调用数据和初次调用数据计算待存储数据的重要系数,将数据进行分类,将部分重要数据进行聚类存储,解决了现有技术中数据存储地过于分散导致数据服务间链路增长、加剧故障排查难度的问题;在数据分块后,对数据存储过程进行测试,有利于为对应数据选择合适的存储对象,在考虑到数据重要性的同时分析了存储节点故障情况,将重要的数据存储到可靠的存储节点中,降低了数据丢失的概率。
附图说明
[0034]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0035]
图1是本发明一种基于计算机系统的大数据分析存储系统的结构图;
[0036]
图2是本发明一种基于计算机系统的大数据分析存储方法的流程图。
具体实施方式
[0037]
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
[0038]
请参阅图1-图2,本发明提供技术方案:一种基于计算机系统的大数据分析存储系统,其特征在于:系统包括:数据采集模块、数据管理中心、存储数据分析模块、数据存储规划模块和预存测试模块;
[0039]
数据采集模块用于采集待存储数据的历史调用信息和存储节点的故障信息;
[0040]
数据管理中心用于存储并管理数据采集模块采集到的所有信息;
[0041]
存储数据分析模块用于分析调用信息和故障信息并将数据进行分块;
[0042]
数据存储规划模块用于选择存储方式并对部分数据进行备份处理;
[0043]
预存测试模块用于测试数据存储情况,规划数据存储位置。
[0044]
数据采集模块包括数据调用采集单元和故障信息采集单元,数据调用采集单元用于采集待存储数据的历史调用次数和调用所需时间信息;故障信息采集单元用于采集当前已有的存储节点的历史发生故障的次数以及故障影响范围信息,将采集到的所有数据传输到数据管理中心中。
[0045]
存储数据分析模块包括存储数据排布单元和排查难度分析单元,存储数据排布单元用于调取并分析待存储数据的历史调用信息,将待存储数据进行分块;排查难度分析单元用于若分块后的数据存储到对应节点中,分析在不同存储节点发生故障时排查故障原因的困难程度。
[0046]
数据存储规划模块包括调用分析单元、存储方式选择单元和数据备份规划单元,调用分析单元用于分析分块后待存储数据的调用频繁程度和历史调用时的信息丢失情况,得到分析结果;存储方式选择单元用于依据分析结果为待存储数据选择不同的存储方式;数据备份规划单元用于依据分析结果将部分数据进行备份处理。
[0047]
预存测试模块包括故障检测分析单元、集群脱离预警单元、存储对象选择单元和二次分块存储单元,故障检测分析单元用于测试数据存储情况,在数据预存储过程中对存
储节点进行实时故障检测;集群脱离预警单元用于在存储节点脱离集群时进行预警;存储对象选择单元用于统计存储节点在测试过程中脱离集群的次数、以及历史故障次数,并依据在测试过程中的调用信息分析待存储数据的重要程度;二次分块存储单元用于对待存储数据进行重新分块并存储到对应节点中。
[0048]
一种基于计算机系统的大数据分析存储方法,其特征在于:包括以下步骤
[0049]
s1:采集数据调用信息和存储节点故障信息;
[0050]
s2:分析数据调用信息和故障信息,将待存储数据进行分块处理;
[0051]
s3:分析分块后数据的调用信息,选择不同的存储方式;
[0052]
s4:对部分待存储数据进行备份处理;
[0053]
s5:测试分块后数据存储情况,规划数据存储对象,将数据重新分块后进行存储。
[0054]
在步骤s1-s2中:采集到不同待存储数据历史被调用的次数集合为m={m1,m2,...,mn},其中,依据调用次数的不同共分为n种待存储数据,在对应数据被调用过程中出现信息丢失的次数集合为n={n1,n2,...,nn},在出现信息丢失后对应数据被调用的次数集合为n’={n1’,n2’,...,nn’},信息丢失前后被调用数据的关联系数集合为sim={sim1,sim2,...,simn},采集到当前已有的存储节点历史发生故障次数集合为m={m1,m2,...,mp},对应存储节点发生故障时修复需要的平均时间集合为t={t1,t2,...,tp},其中,p表示除存储元数据的主节点外的存储节点数量,根据下列公式计算随机一种待存储数据的重要系数wi:
[0055][0056]
其中,mi表示随机一种待存储数据历史被调用的次数,ni表示随机一种待存储数据在被调用过程中信息丢失的次数,ni’表示对应信息丢失后对应数据被调用的次数,simi表示在信息丢失前后随机一种待存储数据中被调用的数据的关联系数,得到待存储数据的重要系数集合为w={w1,w2,...,wn},将待存储数据进行分块处理:分为k块,随机选取k种数据,k种数据的重要系数集合为w={w1,w2,...,wj,...,wk},其中,根据下列公式判断随机一种待存储数据的所属块:
[0057][0058]
其中,ai表示k个分块中数据重要系数与随机一种待存储数据的重要系数差值最小的块,ai的值是w中的一个,将ai的值与w中的元素进行匹配,得到与ai的值相等的重要系数为wj,将对应待存储数据归为第j块,减少了数据服务间的链路,在实现数据分散存储、减轻空间存储压力的同时,有效减轻了故障时的排查难度。
[0059]
在步骤s3-s4中:分析分块后数据的调用信息:获取到将数据分为k块进行存储后,随机一块数据被单独调用的次数为ei,被同时调用的次数为fi,根据公式选择k块待存储数据的存储方式:若pi》1,将对应块数据进行单独存储;若pi≤1,将对应块数据与和对应数据被同时调用的数据进行集中存储,对部分待存储数据进行备份处理:比较n种待存
储数据的重要系数,将重要系数大于的数据进行备份处理。
[0060]
在步骤s5中:测试数据存储情况:在数据预存储过程中对存储节点进行实时故障检测,在检测到存储节点无响应时,判断对应存储节点脱离集群,发送预警信号,同时统计到存储节点在测试过程中脱离集群的次数集合为l={l1,l2,...,lp},记录到在测试过程中存储节点的被访问次数集合为q={q1,q2,...,qp},根据下列公式计算当前已有的随机一个存储节点的存储可靠系数ki:
[0061][0062]
其中,mi表示对应存储节点历史发生故障的次数,li表示对应存储节点在测试过程中脱离集群的次数,ti表示对应存储节点发生故障时修复需要的平均时间,qi表示在测试过程中对应存储节点被访问的次数,得到可靠系数集合为k={k1,k2,...,kp},为对应数据选择了合适的存储对象,提高数据存储的可靠性,为数据分块后的调用提供了便利。
[0063]
规划数据存储对象:将数据重新分块:获取到进行单独存储的数据的重要系数集合为w’={w1’,w2’,...,we’},其中,集中存储到同一位置的数据的平均重要系数集合为w
集
={w
集1
,w
集2
,...,w
集q
},其中,e表示单独存储的数据块数,q表示集中存储的数据块数,比较数据的重要系数:将最大系数对应的数据存储到最可靠的存储节点中,最大系数为w
max
,最大可靠系数为k
max
,将存储节点按可靠系数从大到小排列,剩余数据依据重要系数从大到小依次存储到存储节点中,将数据的重要系数和存储节点的可靠系数进行匹配,将重要的数据存储到可靠的存储节点中,降低了数据丢失的概率。
[0064]
实施例一:采集到不同待存储数据历史被调用的次数集合为m={m1,m2,m3,m4,m5}={20,10,15,2,6},在对应数据被调用过程中出现信息丢失的次数集合为n={n1,n2,n3,n4,n5}={1,5,2,1,3},在出现信息丢失后对应数据被调用的次数集合为n’={n1’,n2’,n3’,n4’,n5’}={2,3,1,0,1},信息丢失前后被调用数据的关联系数集合为sim={sim1,sim2,sim3,sim4,sim5}={0.9,0.8,0.5,0.6,0.1},根据公式得到待存储数据的重要系数集合为w={w1,w2,w3,w4,w5}={2.18,0.67,0.53,0.04,0.15},将待存储数据进行分块处理:分为3块,随机选取3种数据,3种数据的重要系数集合为w={w1,w2,w3}={0.67,0.53,0.15},根据公式判断随机一种待存储数据的所属块:得到a1的值为:0.67=w1,将w1对应的数据归为第1块中,a4的值为:0.15=w3,将w4对应的数据归为第3块中;
[0065]
实施例二:获取到将数据分为3块进行存储后,数据被单独调用的次数分别为e={1,0,2},被同时调用的次数为f={2,3,1},根据公式待存储数据的存储方式:p1《
1,p2《1,p3》1,将第3块数据进行单独存储,将第1、第2块数据进行集中存储,测试数据存储情况:采集到当前已有的存储节点历史发生故障次数集合为m={m1,m2,m3}={10,5,6},对应存储节点发生故障时修复需要的平均时间集合为t={t1,t2,t3}={20,15,30},单位为:分钟,统计到存储节点在测试过程中脱离集群的次数集合为l={l1,l2,l3}={2,3,1},记录到在测试过程中存储节点的被访问次数集合为q={q1,q2,q3}={10,6,1},根据公式得到当前已有存储节点的可靠系数集合为k={k1,k2,k3}={1.6,1.7,1.3},将数据重新分块:获取到进行单独存储的数据的重要系数为0.15,集中存储到同一位置的数据的平均重要系数为:0.6,比较数据的重要系数:将0.6对应的数据存储到第2个存储节点中,将0.15对应的数据存储到第1个存储节点中。
[0066]
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1