一种新型的胎儿体重预测模型构建方法
1.本发明涉及医疗技术领域,具体而言,涉及一种新型的胎儿体重预测模型构建方法。
背景技术:
2.胎儿体重预测(efw,estimated fetal weight)是产前管理的重要内容,准确的胎儿体重预测,可以减少围产儿的患病率、死产率、死亡率及孕产妇并发症。在临床工作中,准确的胎儿体重预测显得尤为重要。
3.在过去的三十年中,对胎儿体重预测模型的研究有几十种之多。目前准确性最高、临床最常用仍然是1985年hodlock等报道的基于超声测量数据所建立的回归模型,据报道该模型对胎儿体重预测成功率(出生体重
±
10%)只有67%-86%不等。当然也有基于临床数据(孕妇宫高及腹围)的胎儿体重预测模型,其预测的准确性更低,据报道只有55%-74.3%不等。综上所述,胎儿体重预测的准确性有待提高。
4.近年来,为了提高胎儿体重预测的准确率,研究目光转移到三维超声以及磁共振检查上。虽然三维超声和磁共振(mri)检查从一定程度上提高了预测的准确率,然仍不理想。考虑三维超声并非常规测量,且费用较贵,费时长,不容易掌握等,不易在临床推广。mri检查也存在耗时较长,费用高等问题,目前难以普遍推广应用。
5.因此如何使用更为全面的孕妇生理参数和超声参数,建立了一种比较简便但同时又较传统方法更加准确和个性化的胎儿体重预测方法,将估计胎儿体重的误差减小至产科临床可接受范围内仍是亟待解决的重大挑战。随着机器学习的出现,为这一想法的实现提供了可能。
6.基于此,发明人提出一种新型的基于svr的胎儿体重预测模型构建方法。
技术实现要素:
7.本发明解决的问题是现有的胎儿体重估算模型并不准确,需要多次对孕妇采用超声波进行检测,且现有的胎儿体重估算模型其噪音值较多,胎儿体重估算模型准确性较低。
8.为解决上述问题,本发明提供一种新型的胎儿体重预测模型构建方法,包括如下步骤:s100:获取欲分娩孕妇以及相对应胎儿的多个参数数据;s200:采用不同算法对多个参数数据进行预实验,并通过多个预实验结果对比选出最优算法;s300:采用最优算法构建新模型,并根据构建的新模型与经典胎儿体重预测模型进行对比以及计算新模型的预测成功率,评估新模型的准确性。
9.与现有技术相比,采用本方案所能达到的技术效果:通过采集分娩孕妇分娩之前孕妇和孕妇内胎儿的参数数据,以及孕妇分娩后的参数数据,来建立后续的新的胎儿预测模型;采用至少3种不同的算法对上述的参数数据进行预实验,然后通过比较各个算法的预实验结果来确定最优算法,而后通过最优算法构建新的胎儿预测模型,并与经典的胎儿预测模型进行对比以及与孕妇分娩后实际胎儿的体重进行误差分析,评估了新模型的准确
性。
10.在本实施例中,所述s100步骤和s200步骤中还包括s150:将多个参数数据进行预处理,所述预处理步骤包括:s151:通过计算机软件将离散的参数数据数值化;s152:通过计算机软件将异常的参数数据剔除,从而形成有效的参数数据。
11.采用该技术方案后的技术效果为,上述预处理的目的是为了将收集到的参数数据数值化或者将明显异常的参数数据剔除,举例说明,如在有关孕妇的参数数据中,有一项关于是否妊娠糖尿病,将其数值化,计有妊娠糖尿病的标记为0,相对应的,无妊娠糖尿病的标记为1。举例说明,如在有关孕妇的参数数据中,有一项关于宫高,而标准的取值均为32cm~36cm,而此时有一个参数数据出现了50cm的宫高,则记为异常值将其剔除,其原因可能是人为输入参数错误等原因。完成上述预处理后的参数数据能够更好的提高新的预测模型的准确性。
12.在本实施例中,所述采用最优算法构建新模型,包括如下步骤:s310:从所述多个参数数据中选出构建新模型所需的多个建模参数;s320:根据建模参数建立所述新模型。
13.采用该技术方案后的技术效果为,由于采集的多个参数数据中有一些参数数据没有参考价值或参考意义,为减少新的模型的计算复杂程度,故在构建新模型时仅选取有参考价值或参考意义的参数数据,可减少新的模型的计算量,比如孕妇的年龄、分娩方式等参数数据对胎儿体重的相关性很小,无参考价值,可剔除上述参数数据。
14.在本实施例中,所述从所述多个参数数据中选出构建新模型所需的多个建模参数,包括如下步骤:s311:将所述参数数据与相对应胎儿体重计算皮尔逊相关系数,所述皮尔逊相关系数包括参数r,p的值;并根据r,p的值以及r,p的相关程度以及其他因素将部分参数数据选入构建新模型所需的建模参数中。
15.采用该技术方案后的技术效果为,皮尔逊相关系数,是一种度量两个变量间相关程度的方法,皮尔逊相关系数p的变化范围-1到1,p值是检验值,是检验两变量(参数数据和胎儿体重)在样本来自的总体中是否存在和样本一样的相关性,r表示在样本中变量间的相关系数,表示相关性的大小。在有相关性的情况下,再看是否正负相关。
16.在本实施例中,其中,p>0.05时,相对应的参数数据不选入构建新模型所需的建模参数中;其中,p<0.05时;r越大时,表明r,p的线性相关越大,相对应的参数数据按相关程度排序以及临床应用因素,并将相对应的参数数据选入构建新模型所需的建模参数中。
17.采用该技术方案后的技术效果为,p>0.05时表明相对应的参数数据与胎儿体重之间没有相关性,故不选入构建新模型所需的建模参数中;而当p<0.05时,表明相对应的参数数据与胎儿体重之间有相关性,此时,r的值越大表明参数数据与胎儿体重线性正相关性越大,而r越小表明参数数据与胎儿体重线性负相关性越大。
18.在本实施例中,所述采用不同算法对多个参数数据进行预实验,并通过多个预实验结果对比选出最优算法;包括如下步骤:s210:将多个参数数据分为训练数据和测试数据,并采用不同的算法计算平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预测成功率;s220:根据各个算法计算得出的平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预测成功率的结果,选取最佳的算法。
19.采用该技术方案后的技术效果为,为了得出哪个算法所形成的新预测模型更准确,采用多个不同算法对多个参数数据分别进行预实验,预实验主要包括采用训练数据用
于模型的构建以及测试数据用于检测模型构建,用于评估模型的准确率。并采用不同的算法计算平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预测成功率;平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预测成功率可用来判断模型的准确率,一般上述平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预测成功率会有权重比,通过计算权重比可得出哪一个是最准确的算法,将此算法成为最优算法并用于构建后续的新的胎儿预测模型。
20.在本实施例中,所述训练数据和所述测试数据的划分比例为9:1。
21.采用该技术方案后的技术效果为,为了提高模型构建的准确性,将大部分的数据参数设置为训练数据用于模型的构建,而将小部分的数据参数设置为测试数据用于测试构建的模型,以使模型的构建更为准确。
22.在本实施例中,所述最优算法为支持向量回归算法,所述支持向量回归算法包括如下计算步骤:所述最优算法为支持向量回归算法,所述支持向量回归算法包括如下计算步骤:
23.将有效的参数数据遵循给定数据集d={(x1,y1),(x2,y2),...,(xm,ym)|m∈r},学习目标回归函数f(x),
[0024][0025]
其中为非线性映射函数;以学习到的函数f(x)为回归中心,构建一个宽度为2ε的间隔带,当实际胎儿体重落入所述间隔带时,则认为是所述支持向量回归算法预测准确。
[0026]
采用该技术方案后的技术效果为,svr算法是在svm基础上发展起来的一种自回归算法。svm算法是利用核函数的方法,将在低维特征空间线性不可分的样本映射到更高维特征空间使得线性可分。而svr算法是建立在svm理论基础上的一种回归算法。
[0027]
在本实施例中,所述参数数据包括高维数据和低维数据,所述高维数据通过最优核函数映射为低维数据。
[0028]
采用该技术方案后的技术效果为,参数数据内包括高维数据和低维数据,采用上述svr算法时,要将高维数据映射为低维数据,此时需要采用核函数的方式将高维数据映射为低维数据,而核函数的种类有好多种,需要通过实验选出最优核函数,以使高维数据映射为低维数据时的参数数控更为准确。
[0029]
在本实施例中,所述最优核函数的选取步骤包括:将不同类型的核函数进行实验对比,并根据实验对比选出最优能拟合参数数据的核函数。
[0030]
采用该技术方案后的技术效果为,通过实验的对比,可选出最优能拟合参数数据的核函数,常见的核函数有“rbf”、“linear”、“poly”,通过实验的对比选择“linear”作为最优核函数,使用该核函数可在训练数据上更好的拟合参数数据,能够更好的将高维参数数据映射至低维参数数据上。
附图说明
[0031]
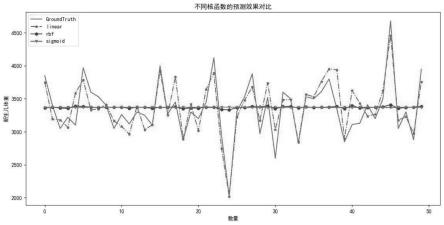
图1是不同核函数的预测效果对比图。
具体实施方式
[0032]
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
[0033]
近年来,随着人工智能技术的不断发展,使得进一步提高胎儿体重预测的准确性成为了可能。支持向量回归(support vector regression,svr)是机器学习的一种,是对人脑若干基本特性通过数学方法进行的抽象和模拟,是对人类大脑系统特征的一种描述,是一种模仿人脑结构及其功能的非线性信息处理系统。因此,发明人尝试联合使用临床数据及超声数据,拟构建一种方便、经济且预测性能良好的基于svr的新型胎儿体重预测模型。胎儿体重预测是产前监护的一项重要内容,胎儿体重与胎儿成熟度之间有着十分密切的关系,应用超声波检查得到关于胎儿的计量生物学参数,并采用经验公式模型对胎儿体重进行估算,对胎儿体重的估算已经成为判断胎儿生长异常及其类型的有效手段。
[0034]
本发明联合使用孕妇生理参数和超声参数,使用svr的方法建立了一种比较简便但同时又较传统方法更加准确和个性化的胎儿体重预测方法,将估计胎儿体重的误差减小至产科临床可接受范围内。
[0035]
【第一实施例】本发明提供一种新型的胎儿体重预测模型构建方法,包括如下步骤:s100:获取欲分娩孕妇以及相对应胎儿的多个参数数据;s200:采用不同算法对多个参数数据进行预实验,并通过多个预实验结果对比选出最优算法;s300:采用最优算法构建新模型,并根据构建的新模型与经典胎儿体重预测模型进行对比以及计算新模型的预测成功率,评估新模型的准确性。
[0036]
在本实施例中,欲分娩孕妇研究对象的有一定的入选标准,包括如下的入选标准:单胎、头位、妊娠周数为31~42周,有明确的末次月经或者可以依据早孕期超声波测量头臀长度确定孕周,且中孕期大畸形筛查中未见胎儿结构的畸形,上述欲分娩孕妇的研究对象均签署知情同意书。
[0037]
其中欲分娩孕妇以及相对应胎儿的参数数据包括多个数据,回顾性数据:采用b超(b超的测量为同一标准测量),临床数据(临床数据的测量为同一标准测量),收集近6个月在某医院分娩的孕妇(仅限于单胎、头位、孕晚期的孕妇),所有采集的数据均是孕妇分娩前1周内,可以最大可能的减少误差,收集的数据共计18个维度,具体包括三个方面:
[0038]
1):孕妇数据包括:孕妇的年龄、孕周、胎产次、升高、体重、宫高、腹围、孕期体重增长,是否妊娠期有糖尿病(简称gdm)、分娩方式(具体包括有顺产/产钳/剖宫产)。
[0039]
2):孕妇还未分娩时通过超声波测量的胎儿数据包括:双顶径(简称bpd)、头围(简称hc)、股骨长(简称fl)、腹围(简称ac)、羊水指数(简称afi)。
[0040]
3):孕妇分娩后出生胎儿情况数据包括:胎头是否入盆(具体包括未入盆/浅入盆/入盆)、性别、出生体重(简称bw)。
[0041]
s200步骤中采用不同的多种算法对上述多个参数数据进行预实验,常见的多种算法包括
[0042]
基于多层感知机的反向传播算法(back propagation):通过随机变量的多元线性组合和非线性函数激活,从而拟合目标函数,并通过误差反传,迭代调整多层感知机的参数权重,自动学习最佳的映射函数。
[0043]
决策树回归(regression tree):通过寻找样本中最佳的特征以及特征值作为最
佳分割点,构建一棵二叉树,在预测阶段,根据提供的样本的特征,以叶子节点的值作为预测值。
[0044]
多元线性回归(multivariable linear regression):通过两个或两个以上的影响因素作为自变量来解释因变量的变化。
[0045]
轻量梯度提升机(light gradient boosting machine):简称lightgbm,一种集成学习方法,通过合并多个决策树来构建一个更为强大的模型,采用连续的方式构造树,每棵树都试图纠正前一棵树的错误。
[0046]
支持向量回归(support vector regression,svr):在支持向量机(support vector machine)的基础上,将最大化分类间隔的分类任务替换为最大化回归范围的回归任务的变种。
[0047]
上述的五个算法各有利弊,为了选取哪个算法能够最适合构建新模型,将上述五个算法均通过预实验进行验证,通过预实验的结果选出最优的算法。
[0048]
通过预实验的实验结果,得出了最优算法是支持向量回归(svr)的算法。
[0049]
s300步骤中采用上述最优算法的支持向量回归(svr)的算法构建新的模型,并根据通过该算法构建的新模型与现有技术中的经典胎儿体重预测模型进行对比,并计算新模型预测成功率,以评估新模型的准确性。
[0050]
【第二实施例】所述s100步骤和s200步骤中还包括s150:将多个参数数据进行预处理,所述预处理步骤包括:s151:通过计算机软件将离散的参数数据数值化;s152:通过计算机软件将异常的参数数据剔除,从而形成有效的参数数据。
[0051]
数据预处理是数据挖掘分析的基础,主要是分析数据来源,对数据进行相应的采集、清洗、规整,实现对数据的规则化,为之后的数据分析打下良好数据基础。正对采集的数据,进行进一步的预处理包括如下步骤:
[0052]
1)对离散的参数数据的数值化,对参数数据中的孕妇数据中是否妊娠糖尿病进行数值化,使用计算机软件python进行处理,将有妊娠糖尿病的参数数据标记为0,相对应的,将没有妊娠糖尿病的参数数据标记为1。对参数数据中孕妇数据中分娩方式(包括顺产/产钳/剖宫产)进行数值化,使用计算机软件python进行处理,将产钳和剖宫产的参数数据标记为0,将顺产的参数数据标记为1。对参数数据中孕妇分娩后出生胎儿情况数据中胎头是否入盆(具体包括未入盆/浅入盆/入盆)进行数值化,使用计算机软件python进行处理,将未入盆和浅入盆的参数数据标记为0,将入盆的参数数据标记为1。对参数数据中的孕妇分娩后出生胎儿情况数据进行数值化,使用计算机软件python进行处理,将男性胎儿的参数数据标记为0,相对应的,女性胎儿的参数数据标记为1。以便于后续对参数数据的处理。
[0053]
2)对异常的参数数据的剔除处理:如参数数据中的孕妇数据中宫高的参数数据,孕妇的标准取值为32cm~36cm,而此时有一个参数数据出现了50cm的宫高,则记为异常值将其剔除,踢除该参数数据。其原因可能是人为输入参数错误等原因。完成上述预处理后的参数数据能够更好的提高新的预测模型的准确性。
[0054]
3)对未采集到的参数数据进行清洗:在采集到的参数数据中,难免会出现参数数据缺失等情况。对于缺失的参数数据,首先引入python语言的一个扩展程序库pandas,pandas是一个强大的分析结构化数据的工具集。我们使用pandas中的read excel方法来读取数据文件,并使用numpy进行数据清洗,踢除含有空值的数据。
[0055]
综上,采用上述的对离散的参数数据的数值化、对异常的参数数据的剔除处理、对未采集到的参数数据进行清洗可形成有效的参数数据。
[0056]
【第三实施例】所述采用最优算法构建新模型,包括如下步骤:s310:从所述多个参数数据中选出构建新模型所需的多个建模参数;s320:根据建模参数建立所述新模型。
[0057]
由于参数数据的维度为18维度,若将18维度的参数数据均作为有效的参数数据(即建模参数)会导致构建新模型所需的计算量太过庞大,且上述18维度的参数数据中有些参数数据与胎儿体重并无关系,如果将这些参数数据也作为构建新模型的参数数据无实际意义,更有甚者会影响新模型的准确性。
[0058]
根据参数数据特征与胎儿体重之间的皮尔逊相关系数来判断该参数数据特征与胎儿体重的相关性。
[0059]
【第四实施例】所述从所述多个参数数据中选出构建新模型所需的多个建模参数,包括如下步骤:s311:将所述参数数据与相对应胎儿体重计算皮尔逊相关系数,所述皮尔逊相关系数包括参数r,p的值;并根据r,p的值以及r,p的相关程度以及其他因素将部分参数数据选入构建新模型所需的建模参数中。
[0060]
本实施例中,将多个参数数据中选出构建新模型所需的多个建模参数,将上述18个参数数据分别计算与胎儿体重的皮尔逊相关系数,皮尔逊相关系数是采用参数r,p来表达参数数据与胎儿体重之间的相关(线性相关),其值介于-1与1之间,用来表示参数数据与胎儿体重之间的相关程度。18个参数数据相对应的参数r,p如表1所示:
[0061][0062][0063]
表1参数r,p与参数数据之间的关系
[0064]
其中,头围参数数据中p值为3.78e-144代表3.78e*-144,其中e为自然数。股骨长参数数据中p值为1.46e-140代表1.46e*-140,其中e为自然数。以此类推,表1中p的值为科学计数法进行计数的。
[0065]
【第五实施例】其中,p>0.05时,相对应的参数数据不选入构建新模型所需的建模参数中;其中,p<0.05时;r越大时,表明r,p的线性相关越大,相对应的参数数据按相关程
度排序以及临床应用因素,并将相对应的参数数据选入构建新模型所需的建模参数中。
[0066]
由于r,p的不同的取值大小决定了是否将该参数数据选入构建新模型所需的建模参数中。故当p>0.05时,表明该参数数据与胎儿体重的相关性关联度较小,此时将该参数数据部选入构建新模型所需的建模参数中。而当p<0.05时,r越大时,表明r,p的线性相关越大,此时可根据线性相关度程序排序以及临床应用的经验值等因素,将相对应的参数数据选入构建新模型所需的建模参数中。
[0067]
根据表1中所示,得出如下结论,首先腹围参数数据的p值接近于0,<0.05,且此时r值为0.818335,在18维参数数据中最大,说明该腹围参数数据与胎儿体重之间显著相关。
[0068]
其次,胎儿的性别的参数数据的p值<0.05,且此时r值为-0.12318,在18维参数数据中最小,说明该胎儿性别参数数据与胎儿体重之间呈负相关,即胎儿性别参数数据与胎儿体重之间的相关性较小,故可将胎儿性别这一参数数据特征不选入构建新模型所需的建模参数中。
[0069]
另外,参数数据孕妇是否妊娠糖尿病(gdm)的p<0.05,且此时r值为-0.05286,r值较小,说明孕妇是否妊娠糖尿病(gdm)与胎儿体重之间呈负相关,即孕妇是否妊娠糖尿病(gdm)与胎儿体重之间的相关较小,故孕妇是否妊娠糖尿病(gdm)这一参数数据特征不选入构建新模型所需的建模参数中。
[0070]
而参数数据孕妇年龄的p>0.05,此时,相对应的参数数据不选入构建新模型所需的建模参数中。
[0071]
另外,考虑到临床应用的推广等情况,将参数数据分娩孕周、分娩方式、产次、孕次与胎儿体重的相关性较小,故相对应的参数数据不选入构建新模型所需的建模参数中。
[0072]
而参数数据采集时间,其p>0.05,此时根据皮尔逊相关系数表明,参数数据采集时间不选入构建新模型所需的建模参数中,但是,由于参数数据采集时间具有一定的特殊性,本发明中一开始就将采集时间进行了限定,限定采集分娩前一周内孕妇的参数数据,且根据临床应用以及其他文献均表明采集时间的延长会对预测胎儿体重的结果产生影响,故有基于上述的科学性,将参数数据采集时间选入构建新模型所需的建模参数中。
[0073]
综上,原本18维的参数数据经过根据皮尔逊相关系数以及临床应用等因素的作用下剔除了7维相关性较小的参数数据,只剩下11维参数数据,如表2所述,使用最优算法对11维参数权重对比,数值越大表示参数影响越大。
[0074]
从表2可得,参数数据宫高的数值为1,其影响最大,而参数数据腹围的数值为0.123198,其影响最小。
[0075][0076]
表2使用svr算法对11维参数权重对比。
[0077]
其中归一化处理是指归一化就是要把需要处理的数据经过处理后(通过某种算法)上述为svr算法,限制在需要的一定范围内。
[0078]
【第六实施例】所述采用不同算法对多个参数数据进行预实验,并通过多个预实验结果对比选出最优算法;包括如下步骤:s210:将多个参数数据分为训练数据和测试数据,并采用不同的算法计算平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预
测成功率;s220:根据各个算法计算得出的平均绝对百分比误差、平均绝对误差、均方根误差以及胎儿体重预测成功率的结果,选取最佳的算法。
[0079]
为了通过预实验选出最优算法,参数数据还是采用18维数据进行验证,本发明选取了2020年1月到6月半年间分娩的符合准入标准的孕产妇共计1442例,本发明总共纳入18维参数:其中gdm孕产妇242例,其他孕产妇1 200例;经阴道分娩者有824例,剖宫产分娩者618例;孕次为1~8次,平均(1.95
±
1.16)次,初产妇948例,二胎分娩475例,三胎分娩19例;男婴747例,女婴695例。其余14维数据纳入的参数及总体样本的平均值、标准差见表3。
[0080]
本研究选取了半年间符合准入标准的孕产妇共计1 442例,总共纳入18维参数,
[0081][0082]
表3其余14维参数数据以及总体样本的平均值、标准差
[0083]
然后采用基于多层感知机的神经网络(bp),决策树回归(decisiontree-regressor),多元线性回归(linear-regression),lightgbm,svr(包括svr、linearsvr、nusvr)算法对现有数据进行预实验,共计18维。其中有效数据1442条(符合准入标准的孕产妇共计1442例),其中将1297条作为训练数据,145条作为测试数据,来计算平均绝对百分比误差(mape)、平均绝对误差(mae)、均方根误差(rmse)以及胎儿体重预测成功率。具体的结果见表4所示:
[0084][0085]
表4各个算法下的mape,mae,rmse及胎儿体重预测的成功率
[0086]
从表4中可得,lightgbm算法的10%误差预测成功率最高,linearregression算法的250g误差预测成功率最高,svr算法的5%误差预测成功率最高,且svr算法有最小的mae、mape以及rmse。
[0087]
其中250g是指预测胎儿体重和实际胎儿体重的误差在250g内,则视为预测成功。10%是指,预测胎儿体重和实际胎儿体重的误差率在10%内,则视为预测成功;而5%是指,预测胎儿体重和实际胎儿体重的误差率在5%内,则视为预测成功,且预测成功率(%)为成功预测的数量/总预测数量*100%。而平均绝对百分比误差(mape)、平均绝对误差(mae)、均方根误差(rmse)采用相对应的公式进行计算。
[0088]
lightgbm算法在寻找最优解时,依据的是最优切分变量,没有将最优解是全部特征的综合这一理念考虑进去,多元线性回归算法对于数据特征间具有相关性多项式回归难以建模,bp算法预测精度不高。而对于特征维度少的数据,svr不容易造成过拟合,添加的松弛变量可以提高模型的泛化性。linearsvr使用线性核函数,在实验过程中难以收敛;nusvr预测平均绝对误差较svr低。
[0089]
综上所述,我们选择svr作为最优算法。
[0090]
【第七实施例】所述训练数据和所述测试数据的划分比例为9:1。
[0091]
为了提高模型构建的准确性,将大部分的数据参数设置为训练数据用于模型的构建,而将小部分的数据参数设置为测试数据用于测试构建的模型,以使模型的构建更为准确。
[0092]
【第八实施例】所述最优算法为支持向量回归算法,所述支持向量回归算法包括如下计算步骤:所述最优算法为支持向量回归算法,所述支持向量回归算法包括如下计算步骤:
[0093]
将有效的参数数据遵循给定数据集d={(x1,y1),(x2,y2),...,(xm,ym)|m∈r},学习目标回归函数f(x),
[0094][0095]
其中为非线性映射函数;以学习到的函数f(x)为回归中心,构建一个宽度为2ε的间隔带,当实际胎儿体重落入所述间隔带时,则认为是所述支持向量回归算法预测准确。
[0096]
由于通过预实验选出了最优算法为svr算法,而通过皮尔逊相关系数以及临床应用等因素的作用下剔除了7维相关性较小的参数数据,只剩下11维参数数据,为了确保剩下11维参数数据构建新模型的准确性。
[0097]
使用svr对筛选后的11维参数与18维参数的分别进行建模,并对其建模结果进行对比,结果如表5所示。使用11维参数建立的胎儿体重预测模型与18维数据构建的体重预测模型在预测成功率等方面相差无几。因此考虑到临床应用的方便,不便选择过多的数据,且从表5可以看出,去除7维数据后,不影响预测成功率,因此我们最终决定使用11维参数构建的胎儿体重预测模型,即新的胎儿体重预测模型。
[0098][0099]
表5 18维胎儿体重预测模型和11维胎儿体重预测模型的成功率比较表
[0100]
而后为了验证新的胎儿体重预测模型的准确性,与现有技术中的hodlock模型及intergrowth-21st模型进行性能比较,来计算平均绝对百分比误差(mape)、平均绝对误差(mae)、均方根误差(rmse)以及胎儿体重预测成功率,结果见表6所示:
[0101][0102][0103]
表6新的胎儿预测模型、hodlock模型及intergrowth-21st模型的成功率比较表
[0104]
与hadlock1及intergrowth-21模型相比,新模型具有最高的胎儿体重预测成功率,无论是5%,10%还是250g。此外,新型胎儿体重预测模型还具有最低的mape、mae及rmse。
[0105]
【第九实施例】所述参数数据包括高维数据和低维数据,所述高维数据通过最优核函数映射为低维数据。
[0106]
参数数据内包括高维数据和低维数据,采用上述svr算法时,要将高维数据映射为低维数据,此时需要采用核函数的方式将高维数据映射为低维数据,而核函数的种类有好多种,需要通过实验选出最优核函数,以使高维数据映射为低维数据时的参数数控更为准确。常见的核函数为“rbf”,“linear”、“poly”。
[0107]
【第十实施例】所述最优核函数的选取步骤包括:将不同类型的核函数进行实验对比,并根据实验对比选出最优能拟合参数数据的核函数。
[0108]
实验对比后选择使用linear核函数,如图1所示,使用该核函数在训练集上可以更好的拟合数据。同理,惩罚因子c在超参数调优后设为1.35。将收集到的数据以90%用于训练,而10%用于验证。损失函数选用平均绝对误差(mean absolute error,mae)。
[0109]
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1