一种考虑减碳的土石方机械配置方法
1.本发明涉及公路或铁路土石方工程中的机械配置管理领域,同时也属于计算机领域和运筹学领域,涉及土石方工程中挖掘机和运输卡车的智能调度,特别是一种考虑减碳的土石方机械配置方法。
背景技术:
2.合理的土方设备组合将有助于减少土石方工程的工期和成本。然而,减少土方作业中的碳排放是非常可取的,因为土方作业涉及到大量产生高碳排放的重型设备。然而至今为止,多数学者在研究土石方机械配置优化问题时都只考虑到了降低成本和工期。如文献[parente m,cortez p,correia a g.an evolutionary multi-objective optimization system for earthworks[m]//expert systems withapplications 42(2015):6674
–
6685]。然而随着大众对绿色建筑的关注度不断增长,多数建筑不仅需要考虑安全实用性,还需要考虑绿色环保问题。而在土石方作业的环境影响(例如,废物产生、能源消耗、资源消耗等)中,其排放占总影响的最大份额(超过50%)。因此,在满足计划工期和预算的前提下,使得机械配置能尽可能减少碳排放和提高机械的生产效率具有重要的价值和研究意义。
技术实现要素:
[0003]
本发明构建了一种考虑减碳的自动生成土石方机械配置模型,在土石方机械配置自动设计时考虑了碳排放,目的在于达到节能减排和绿色低碳的要求,并实现费用和工期的最小化,同时能自动确定土石方机械配置数量。
[0004]
一种考虑减碳的土石方机械配置自动生成模型,首先根据土石方系统中机械的实际运作特征和排队理论建立土石方工程中机械的排队模型,然后建立目标函数,并将土石方机械配置模型引入该目标函数,再依据设置的约束条件,利用多目标粒子群优化算法对建立的土石方机械配置模型进行求解,获得以减少碳排放、工期和成本为目标的最优机械配置解集。
[0005]
步骤1,根据土石方系统中机械的实际运作特征和排队理论,建立以减少总成本、缩短工期和减少碳排放为目标的土石方工程中机械配置模型,碳排放目标函数如下所示:
[0006][0007]
其中,f
idl_t
表示运输卡车在空闲时间内的单位秒燃油消耗,ws表示运输卡车在排队系统中所花费的时间,t表示一台班的时间,ts表示运输卡车往返一趟的时间,f
idl_e
表示挖掘机在空闲时间内的单位秒燃油消耗,n表示挖掘机数量,m表示运输卡车数量,pi表示状态si出现的概率,si表示i个(i=0,1,...,m-1)卡车在排队系统中的状态,表示单位秒内卡车被装载的数量,f
tm
表示由于卡车会车每次所增加的碳排放量,td表示土石方工程的工
期,f表示燃油消耗与碳排放的转换系数。
[0008]
工期目标函数如下:
[0009][0010]
其中,v表示总土石方量,p
t
表示理论生产率,t
tm
表示由于卡车会车每次所增加的时间。
[0011]
成本目标函数如下:
[0012]
c=c1×n×
td+c2×m×
td[0013]
其中,c1表示每台挖掘机的日租费用,c2表示每台运输卡车的日租费用。
[0014]
土石方机械配置模型的约束条件如下:
[0015][0016]
其中,th表示计划工期,n
max
表示最大挖掘机数量,m
max
表示最大运输卡车数量。
[0017]
步骤2,对基本多目标粒子群优化算法进行改进,得到新的多目标粒子群优化算法,所述对基本多目标粒子群优化算法进行改进是采用双档案集策略更新种群,双档案集分为收敛性档案集和多样性档案集,其中采用r2指标来更新收敛性档案集,采用帕累托支配来更新多样性档案集。
[0018]
其中,收敛性档案集更新流程:
[0019]
step1:在t代计算种群中所有粒子的r2指标贡献值;
[0020]
step2:进行降序排列,取前n个粒子,加入收敛性档案集中;
[0021]
step3:在t+1代计算种群所有粒子的r2指标贡献值;
[0022]
step4:进行降序排列,取前n个粒子,加入收敛性档案集中;
[0023]
step5:计算收敛性档案集中2n个粒子的r2指标贡献值;
[0024]
step6:进行降序排列,取前n个粒子,删除档案集中多余粒子;
[0025]
step7:重复步骤1到6,直到迭代结束。
[0026]
多样性档案集更新流程:
[0027]
step1:根据pareto支配关系,把t代种群中的非支配解存储到多样性档案集中;
[0028]
step2:找到t+1代种群的非支配解,分别和多样性档案集中的粒子进行支配关系比较,把非支配解加入档案集中,支配解则删除;
[0029]
step3:当多样性档案集中的解的数目没有超过档案集容量就直接更新;否则依次计算档案集中每个粒子到档案集中其他粒子的距离。
[0030]
step4:对距离值从小到大排列,找到每个粒子到其它粒子距离中的最小距离为d
min
。
[0031]
step5:对所有粒子的d
min
进行升序排列,从小到大把粒子从多样性档案集中删除,直到满足档案集的容量;
[0032]
step6:重复step1到step5,直到迭代结束。
[0033]
步骤3,采用所述新的多目标粒子群优化算法对机械配置模型进行求解,模型求解过程为:
[0034]
step1:初始化参数,确定种群规模n,最大迭代次数gmax,档案集容量t
num
;
[0035]
step2:根据模型的目标和约束条件,初始化粒子的位置、速度和个体最优;
[0036]
step3:根据pareto支配关系将非支配解存入多样性档案集(da)中,并根据r2指标贡献值将解存入收敛性档案集(ca)中;
[0037]
step4:把收敛性档案集并入多样性档案集,更新多样性档案集,保持收敛性档案集不变,从更新后的多样性档案集中选取全局最优;
[0038]
step5:更新粒子群的位置、速度和个体最优;
[0039]
step6:基于pareto支配关系更新da,并基于r2指标贡献值更新ca;
[0040]
step7:迭代次数加1,判断是否满足终止条件;
[0041]
step8:当达到最大迭代次数gmax的时候,输出最终得到的da。
[0042]
本发明的有益效果是:
[0043]
与现有技术相比,本发明不必将多个目标线性加权转换为单目标问题,而是直接对多目标问题进行求解。在现有土石方机械配置模型的基础上,考虑碳排放对机械配置的影响,建立了以总成本、工期和碳排放为目标的土石方机械配置优化模型,模型在原有基本土石方机械配置模型的基础上增加了减少碳排放的目标以及运输卡车会车的影响。然后采用一种改进多目标粒子群优化算法对模型进行求解。多目标粒子群优化算法已被证明适用于带约束的多目标优化问题,在处理土石方机械配置优化模型的过程中,能够快速的得到符合实际生产需求的机械配置数量。另外,本发明提供的是一组解,同时可以满足不同偏好决策者的需求,对于指导土石方机械配置管理、降低土石方工程成本、工期和碳排放有着重要的现实意义。
附图说明
[0044]
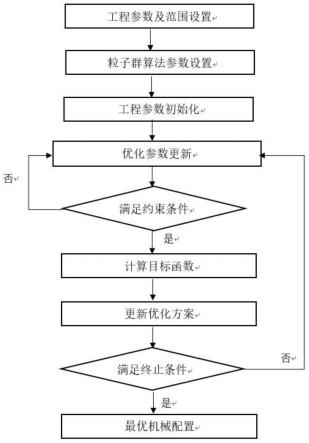
图1为土石方机械配置模型优化流程图。
[0045]
图2为本发明采用的多目标粒子群优化算法的流程图。
具体实施方式
[0046]
为使本发明的目的、技术方案和特点更加清楚明白,下面结合实施例和附图,对本发明作进一步地说明,本发明的示意性实施例和说明用于解释本发明,不作为对本发明的限定。
[0047]
实施例:
[0048]
湖南省某大型铁路工程项目,该工程需要开挖土方量为12300m3,挖掘机斗容量为1.1m3,挖方到弃土和填方的平均运距为2.5km,运输卡车自重12t,载重后重量为45.2t,运输土为粘土和砾石,密度为1660kg/m3,运输卡车容积为20m3,长度为9.6m,空载速度为40km/h,载重速度为30km/h。
[0049]
s1、根据现有土石方调配实际的工作过程,建立以减少总成本、缩短工期和减少碳排放为目标的土石方机械配置模型。
[0050]
(1)减少碳排放量。
[0051]
本发明中所考虑的碳排放量主要分为三部分。第一部分为运输卡车在空闲时间内所产生的碳排放量,由卡车的数量决定。第二部分为挖掘机在空闲时间内所产生的碳排放
量,由挖掘机的数量决定。第三部分为运输卡车在运输过程中会车时所增加的碳排放量,由卡车的会车次数决定。
[0052]
具体而言,碳排放量目标函数如下所示:
[0053][0054]
(2)缩短工期。
[0055]
工期包括两部分。第一部分为完成总挖方量所需时间。第二部分为运输卡车在运输过程中会车时所增加的时间。
[0056][0057]
(3)减少成本。
[0058]
成本包括两部分。第一部分为卡车的租用费用。第二部分为挖掘机的租用费用。
[0059]
c=c1×n×
td+c2×m×
td[0060]
(4)约束条件。
[0061]
土石方实际工程中还应满足最小计划工期、最大挖掘机数量以及最大运输卡车数量等一系列约束条件。
[0062][0063]
s2、对基本多目标粒子群优化算法进行改进,得到新的多目标粒子群优化算法。
[0064]
对基本多目标粒子群优化算法进行改进是采用双档案集策略来更新种群,其中采用r2指标来更新收敛性档案集,采用帕累托支配来更新多样性档案集。
[0065]
s3、初始化参数,确定种群规模n,最大迭代次数gmax,档案集容量t
num
;根据模型的目标和约束条件,初始化粒子的位置、速度和个体最优。
[0066]
s4、根据pareto支配关系将非支配解存入多样性档案集(da)中,并根据r2指标贡献值将解存入收敛性档案集(ca)中;把收敛性档案集并入多样性档案集,更新多样性档案集,保持收敛性档案集不变,从更新后的多样性档案集中选取全局最优;
[0067]
s5、更新粒子群的位置、速度和个体最优;基于pareto支配关系更新da,并基于r2指标贡献值更新ca;
[0068]
s6、迭代次数加1,判断是否满足终止条件;
[0069]
s7、如果目标函数评价次数达到最大评价次数,则从外部档案集的da获得最后的包含所有变量维度的完整的非支配解集,输出当前最优解集,结束。
[0070]
经过上述步骤,可以得到该实例的机械配置解集,表1展示了该实例中所得到的27
种配置方案。
[0071]
表1机械配置组合
[0072][0073]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1