基于深度Q学习的移动边缘计算中卸载决策方法及系统与流程
基于深度q学习的移动边缘计算中卸载决策方法及系统
技术领域
1.本发明属于移动边缘计算系统中移动设备的卸载决策技术领域,具体涉及一种基于深度q学习的移动边缘计算中卸载决策方法及系统。
背景技术:
2.随着5g和物联网技术的飞速发展,人们已经步入了一个万物互联的新世界。近年来,具有联网功能的移动设备,如智能手机,智能家电,智能穿戴设备等数目呈井喷式增长,与此同时,诸如虚拟现实,实时路径规划,在线视频处理等新功能的出现也对数据传输和数据计算的能力提出了更为严格的要求。如何找到一种有效的方式解决物联网设备对于数据传输和数据计算的需要是一个急需解决的难题,移动边缘计算成为了一种有效的解决方案。
3.虽然现有的移动边缘计算方法已经取得了一定的成就,但是现有的移动边缘计算系统中卸载决策过程产生的时延仍然较大,产生的能耗仍然较高,因此,为移动边缘计算系统提出一种卸载决策的方法以降低卸载决策过程产生的时延与能耗是十分必要的。
技术实现要素:
4.本发明的目的是为解决现有移动边缘计算系统中卸载决策过程产生的时延大、能耗高的问题,而提出的一种基于深度q学习的移动边缘计算中卸载决策方法及系统。
5.本发明为解决上述技术问题所采取的技术方案是:
6.基于本发明的一个方面,基于深度q学习的移动边缘计算中卸载决策方法,所述方法具体包括以下步骤:
7.步骤一、强化学习模型构建
8.根据任务特性构建马尔可夫决策过程中的系统状态、系统动作和奖励函数;
9.步骤二、神经网络构建
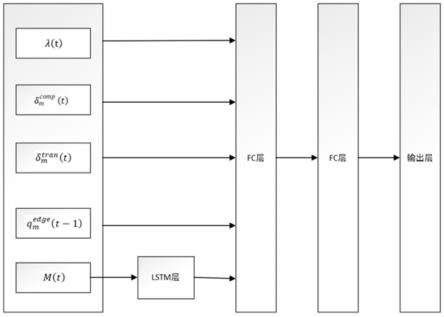
10.构建包括输入层、lstm层、第一fc层、第二fc层和输出层的神经网络,输入层用于将系统状态信息传递给lstm层和第一fc层,并将lstm层的输出作为第一fc层的输入;
11.再将第一fc层的输出作为第二fc层的输入,将第二fc层的输出作为输出层的输入。
12.进一步地,所述系统状态的构建方式为:
13.将当前时隙开始时移动设备m的自身任务大小表示为λm(t),若当前时隙开始时移动设备m存在新的任务k(t),则λm(t)=k(t),否则λm(t)=0;
14.构建本地计算队列、任务传输队列和边缘节点计算队列,将当前时隙开始时移动设备m的自身任务在本地计算队列中需要等待的时隙数表示为将当前时隙开始时移动设备m的自身任务在任务传输队列中需要等待的时隙数表示为将移动设备m在边缘节点n处的队列长度表示为
15.构建表示当前时隙之前的t个时隙内每个边缘服务器负载水平的矩阵m(t),m(t)的维度为t
×
n,n是边缘服务器的个数;
16.则移动设备m在当前时隙处观察到的系统状态sm(t)为:
[0017][0018]
进一步地,所述系统动作表示为a(t)={0,1,2,
…
,n},其中,0表示本地计算,k=1,2,
…
,n,k表示卸载的边缘服务器的序号。
[0019]
进一步地,所述奖励函数的构建方式为:
[0020]
若任务被决策为本地计算,则任务等待的时隙数为:
[0021][0022]
其中,表示在时隙t
′
产生的任务在本地执行完成后的时刻;
[0023]
任务本地计算中所需要的能量为:
[0024][0025]
其中,εm代表移动设备m本地计算时cpu的能耗系数,即本地cpu计算一个周期所消耗的能量,dm代表移动设备m当前产生的任务的计算量大小,即执行当前产生的任务需要的cpu计算周期数;
[0026]
设置移动用户m对于时延和能耗的偏好系数分别为和那么移动用户m在卸载决策过程中的奖励函数为:
[0027][0028]
其中,r为奖励函数值,t为移动用户m在本地计算时产生的总时延,即t等于任务排队等待的时隙数目与任务在本地执行过程中产生的时延之和,e为移动用户m产生的总能耗,即
[0029]
进一步地,所述奖励函数的构建方式为:
[0030]
若任务被决策为边缘计算,则任务等待的时隙数通过在边缘服务器n执行完成后的时刻来计算,即任务等待的时隙数为
[0031]
任务边缘计算中所需要的能量包括任务上传和任务执行两个部分,将任务上传时移动设备的功率表示为p
up
,将任务执行时移动设备的功率表示为pe,则对于移动设备m,所需要的能量为:
[0032][0033]
其中,t
n,up
代表移动设备m将任务上传到边缘服务器n中消耗的时间,t
n,e
代表移动设备m在边缘服务器n中执行任务所消耗的时间。
[0034]
此时,用户在卸载决策过程中的奖励函数为:
[0035]
[0036]
其中,r为奖励函数值,t是任务排队产生的总时延任务上传到边缘服务器n产生的时延t
n,up
以及任务在边缘服务器n执行产生的时延t
n,e
的和,e是边缘计算产生的总能耗,即
[0037]
进一步地,所述奖励函数的构建方式为:
[0038]
若在任务执行完成前已经达到了任务所允许的最大延迟时间,则任务被丢弃,将此时的奖励函数值r设定为一个固定的惩罚值p。
[0039]
进一步地,所述lstm层用于根据矩阵m(t)预测边缘服务器负载水平的时间相关性。
[0040]
进一步地,所述第一fc层和第二fc层用于学习系统状态到系统动作奖励函数值的映射,第一fc层和第二fc层均包含一组具有整流线性单元的神经元。
[0041]
更进一步地,所述输出层用于输出当前系统状态采用当前选择的动作对应的奖励函数值。
[0042]
基于本发明的另一个方面,基于深度q学习的移动边缘计算中卸载决策系统,所述系统用于执行基于深度q学习的移动边缘计算中卸载决策方法。
[0043]
本发明的有益效果是:
[0044]
本发明将深度强化学习算法应用到移动边缘计算中的卸载决策问题,根据系统中建立的本地计算队列,任务传输队列,边缘服务器队列等任务调度模型,设计对应的系统状态,动作和奖励方程。通过对比本发明方法与其他算法的平均时延和能耗,可以得出,本发明的卸载决策方法极大的降低了移动边缘计算系统中卸载决策过程产生的时延与能耗。
附图说明
[0045]
图1为本发明构建的神经网络结构图;
[0046]
图2为本发明方法的奖励函数值随迭代次数收敛曲线图;
[0047]
图3为本发明方法与其他三种基线算法的平均奖励值随用户数目变化曲线图;
[0048]
图4为本发明方法与其他三种基线算法的平均时延随用户数目变化曲线图。
具体实施方式
[0049]
具体实施方式一、本实施方式针对mec系统中多移动设备多服务器的网络场景,提出一种基于深度强化学习的计算卸载策略。将每个移动用户看作一个智能体,任务在卸载的过程中由于有到达的先后之分,需要进行任务排队,本发明构建了包括本地计算队列,任务传输队列,边缘节点计算队列三个队列的任务调度模型。然后分别建立两类任务执行方式下时延和能耗成本计算模型,以最小化系统成本为目标设计方法,使其在连续若干个时隙内产生最小的系统时延与能耗。
[0050]
步骤1、强化学习模型构建:
[0051]
本步骤对于本发明使用dqn进行任务卸载决策的具体实现做了详细说明。主要包括马尔可夫决策过程中系统状态,动作,奖励方程的定义等。
[0052]
1.马尔可夫决策过程构造
[0053]
在每个时隙开始时,每个移动设备都会观察其状态(例如任务大小,队列长度等信
息)。如果有新任务要处理,移动设备会为该任务选择合适的卸载决策,使其任务计算的长期成本降到最低。将深度强化学习应用于任务卸载决策问题需要构建一个马尔可夫决策过程,构造过程中需要具体定义系统状态,动作和奖励方程。
[0054]
2.系统状态设置
[0055]
与卸载决策有关的第一个信息是任务本身的特性。首先考虑任务自身大小λ(t)。在每个时隙开始时,移动设备m需要首先观察自身任务的大小,使用λ(t)表示。其中若当前时隙开始时存在新的任务k(t),那么λ(t)=k(t),否则λ(t)=0。注意因为设置新任务的产生也是在时隙开始时产生,所以不存在时隙中产生任务无法计算λ(t)的问题。
[0056]
同样需要考虑的一个任务特性是任务的最大可接受延迟,这个特性对于卸载决策也是有关的。因此也考虑将其加入到系统状态当中。
[0057]
任务在三种排队队列中的执行时间等也与卸载决策有关。因此也应将其添加到系统状态当中。具体包括:
[0058]
表示任务在本地计算队列中需要等待的时隙数;
[0059]
表示任务在传输队列中需要等待的时隙数;
[0060]
表示移动设备m在边缘节点n处的队列长度。
[0061]
由于每个边缘节点的负载水平,即节点处活动队列的数量,是不断变化的。而当前时刻的负载水平又与上一个时刻有强关联性。因此考虑构建边缘节点负载水平矩阵m(t)来体现一段时间内边缘节点的负载水平。
[0062]
具体来说,使用矩阵m(t)表示前t个时隙(从时隙t-t到时隙t-1)内每个边缘节点的负载水平(即该边缘节点的活动队列的数量,最大为移动设备数m)的历史情况。其为一个t
×
n维的矩阵,其中,t是总的时隙数目,n是边缘节点个数。举例来说,{m(t)}
(i,j)
表示第t-t+i-1个时隙时边缘节点j的活动队列的数量。
[0063]
综合以上叙述,可以把移动设备m在当前时隙处观察到的系统状态定义为一个若干维度的向量,用sm(t)表示,即
[0064][0065]
3.系统动作
[0066]
每个移动设备需要做出的决策首先要确定卸载到边缘服务器还是本地执行,然后需要考虑卸载到哪个边缘服务器。使用0表示本地计算,使用k表示卸载的边缘服务器的序号。假设一共有m个边缘服务器,那么系统动作可以表示为a(t)={0,1,2,
…
,m}。
[0067]
4.奖励函数
[0068]
最影响移动设备应用体验的是卸载产生的时延与能耗。因此本发明奖励函数的设置也围绕任务卸载过程中产生的时延与能耗来构建。
[0069]
任务产生的时延从本地计算和边缘计算两种情况进行考虑。
[0070]
如果任务被决策为本地计算,那么任务等待的时隙数可以如下计算。
[0071][0072]
如果任务被决策为边缘计算,那么任务等待的时隙数通过在边缘节点执行完成后
的时刻来计算,即为
[0073]
任务产生的能耗同样从本地计算和边缘计算两种情况进行考虑。
[0074]
任务本地计算所需要的能量为
[0075]
任务边缘计算中耗能主要在任务上传和任务执行两个部分,假设任务上传时移动设备的功率为p
up
,任务执行时移动设备的功率为pe,则对于设备i;
[0076][0077]
设置移动用户i对于时延和能耗的偏好系数分别为和那么设置用户在卸载决策过程中的奖励函数为
[0078][0079]
另一方面,如果任务由于已经达到了它可以接受的最大延迟时间,那么任务被丢弃,那么定义此时的奖励函数为一个固定的惩罚值p,即
[0080]
r=p
ꢀꢀ
(5)
[0081]
步骤2、神经网络构建,如图1所示:
[0082]
1.输入层:该层负责将状态作为输入并将其传递给以下层。对于移动设备m,状态信息λ(t),m(t)将被传递给fc层进行预测。
[0083]
2.lstm层:矩阵m(t)表示前t个时隙内每个边缘节点的负载水平,而边缘节点的负载水平是时间相关的,也就是说边缘节点的负载水平具有时间依赖性。因此考虑使用lstm层预测负载水平的时间相关性。
[0084]
3.fc层:两个fc层负责学习状态到动作q值的映射。每个fc层包含一组具有整流线性单元的神经元。
[0085]
4.输出层:输出层的值对应于当前状态采用当前选择的动作对应的q值。用来体现当前决策所带来的综合成本,即时延与能耗的均衡值。
[0086]
实施例
[0087]
本实施例从网络模型,任务模型,任务调度模型三个方面对本发明应用的系统架构进行介绍。
[0088]
步骤1、网络模型的建立:本发明针对的场景由以下两个部分组成,若干台配备有边缘服务器的基站,若干个需要执行密集型计算任务的移动设备。每个基站配备有一台具有较高计算能力的边缘服务器。假设在每个时隙开始时,每台移动设备以一定的概率产生一个需要执行的密集型任务,任务要么在本地执行,要么全部卸载到边缘服务器端执行,任务不可分割。
[0089]
考虑一个包含t个时隙的时间段t={1,2,3,
…
,t},本发明在仿真中设置t=100,其中设置每个时隙的时间长度为δ。对于该小区内的n个移动设备,在每个时隙开始时,使用卸载决策变量αi表示是否将计算任务卸载到边缘服务器中执行以及卸载到哪个服务器当中,如果选择将其卸载到第k个边缘服务器中,决策变量ai=k,如果选择将任务本地执行,决策变量ai=0。
[0090]
假设移动设备的任务具有相同的优先级。每个边缘节点都有一个cpu,用于处理队
列中的任务。在每个时隙开始时,边缘节点处的若干个移动设备对应的任务队列平均共享边缘节点n处cpu的处理能力。
[0091]
步骤2、任务模型的建立:移动设备产生的任务表示有两个维度,一个是任务的存储空间大小,这里设置任务大小λm(t)为3mbit到5mbit之间的随机值,步长为0.1mbit。另一个是任务可以接受的最大等待时隙数,使用τm表示。当任务等待的时长超过了τm,此任务在系统中会被丢弃。
[0092]
步骤3、任务调度模型的建立:以边缘服务器一侧为例,由于任务到来有先后之分,在下一个时隙开始阶段边缘服务器可能还没有处理完上个时隙的任务,因此任务会进行排队。本部分构建了本地计算队列,任务传输队列,边缘节点计算队列三个队列模型,作为任务的调度模型。
[0093]
步骤4、算法性能评价与分析:
[0094]
选择一个场景对算法收敛性进行研究,设置用户数量为120,边缘服务器数目为5,算法迭代1200次,绘制出算法的奖励函数在连续100次决策后的平均奖励值。从图2可以看到平均奖励值在迭代次数达到500次左右时开始收敛,平均奖励值在之后的迭代中逐渐趋于稳定。这说明在多次训练中智能算法已经学习到了比较稳定的卸载策略。
[0095]
选择其他三种基线算法与本发明设计的基于dqn的算法进行比较,设置移动用户数量从50变化到120,固定边缘服务器数量为5,如图3所示,分别绘制四种算法的平均奖励值曲线,其中三种基线算法使用的奖励值均为100次平均得到。
[0096]
从仿真曲线可以看到,随用户数目增加除全部本地计算算法之外,其余三种算法得到的平均奖励值均呈现下降趋势。这是因为本次仿真设置的边缘服务器数目始终为5,而用户数目却逐渐增加,因此用户所能分得的服务器资源也就逐渐紧张。对于全部本地卸载算法,其平均奖励值随用户数变化基本不变,当用户数小于90时,全部卸载算法的性能要优于全部本地计算算法,这是由于此时服务器计算资源较为充足,而随着用户数量继续增加,全卸载算法的性能则差于全部本地计算算法。
[0097]
从图4的仿真曲线可以看到,对比其他三种基线算法,dqn算法始终可以获得更低的任务处理时延。和奖励值曲线的变化趋势类似,当用户数目超过90时,由于边缘服务器的计算资源过于紧张,全卸载算法的时延开始超过全部本地计算算法的时延。
[0098]
本发明的上述算例仅为详细地说明本发明的计算模型和计算流程,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1