一种基于双交叉注意力机制的高精度立体匹配方法
1.本发明属于图像处理技术领域,具体涉及一种自适应视差范围的深度信息获取方法和优 化策略,可用于双目输入下的高效深度信息获取。
背景技术:
2.在立体视觉领域,给定一个像素的视差,其深度z可以通过z=bf/d求解得到。其中,b 是双目相机系统的基线长度,f是相机系统的焦距,d是该像素对应的视差。因此,深度信息 估计任务可以转化为对应像素的视差估计任务。给定一对校正后的双目图像,在没有遮挡的 情况下,真实场景中的一个点会同时被投射到左右两个视点的图像中,而这两个位于不同视 点下的对应像素对之间的横坐标差,就被称为“视差”。通常,这种视差估计任务会被分解成 四个步骤:1)特征提取;2)代价计算;3)代价聚合;和4)视差估计。对于传统算法而言, 这四个步骤是依次进行的,而每个步骤的技术通常可以单独应用。
3.近年来,随着深度学习技术的发展,视差估计每个步骤的完成正逐渐被神经网络所替代, 步骤之间的独立性也日渐减弱,视差估计任务也更多地由一个端到端的网络计算完成。在这 些网络中,代价计算通常由两种手段完成:特征级联和卷积计算。对于前者而言,左右视点 下的输入经过共享参数的相同特征提取结构,随后,得到的特征被直接按照通道级联并直接 作为后续代价聚合和视差估计网络的输入。这种方法在代价聚合部分通常依赖3d卷积,因 此需要付出较大的计算量代价。而且,这种直接级联的代价计算方法在效果上也不如卷积计 算得到的代价矩阵。这种基于卷积计算的代价计算方法将左右视点下的特征,在某一给定的 视差范围内通过点积计算其相似度,并将不同点对的计算结果放在不同通道上。通常,这种 方法下的代价矩阵的通道数,就等于人为设定的视差范围。对于大部分数据库,这个视差范 围被指定为192像素。
4.尽管这种基于相关计算的方法可以得到比直接级联效果更好的代价矩阵,但是其必须应 用于一个固定的视差范围。而当这种视差范围变化时,网络结构需要重新训练,而且训练的 时长会随着视差范围的增大而显著拉长。除此之外,在某些视差范围变化比较大的应用场景 下,如果网络没有针对性地被重新训练,其效果会大打折扣,甚至失效。比如在自动驾驶领 域,算法需要准确识别远处的目标和近处的目标,而这两者之间的视差差距巨大,传统固定 视差范围的算法计算难度很大,且随着视差范围的增加,算法表现会明显下降。
5.除了这两种基于卷积神经网络的视差估计结构,还有一种基于注意力机制的网络结构。 这种方法将双目立体匹配任务视作与自然语言处理相似的序列计算任务,通过交叉注意力机 制和自注意力机制的穿插运用,同步完成代价计算任务和代价聚合任务。尽管这种方法也可 以实现视差范围的自适应,但是其计算代价巨大且效果不及主流基于卷积神经网络的立体匹 配算法。
技术实现要素:
6.本发明的目的在于解决以上可变视差范围应用对于算法应用和表现的限制问题,设计一 种基于双交叉注意力机制的高效立体匹配方法,用于可变视差范围下的高精度视差估计问题。
7.为实现上述目的,本发明采用的技术方案为:
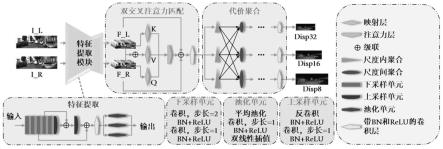
8.一种基于双交叉注意力机制的高效立体匹配方法,其特征在于不受应用场景的视差范围 约束,可以无需二次训练地自适应应用场景下的视差要求,实现高精度视差估计。方法的整 体网络结构如图1所示,左右视点图片经过特征提取模块学习得到特征,之后两个视点下的 特征通过双交叉注意力匹配模块得到匹配代价,通过代价聚合模块最终得到视差图估计。方 法包括如下步骤:
9.步骤1:处理输入数据,将数据根据需要分成训练集和测试集两个部分。其中,训练集 可以进一步分成训练集和验证集,其中验证集有视差真值但是真值仅用于评估而不参与训练 过程的损失计算。撰写相关数据读取函数,表明输入双目图像和视差真值图像的路径,用于 在训练过程中根据该路径读取相应输入。对输入图像进行数据扩张操作,包括竖直方向的位 移和旋转、rgb亮度变换、高斯噪声或者亮度对比度变换。
10.步骤2:采用漏斗形特征提取网络计算特征,具体步骤为:
11.步骤2a:利用5个下采样单元对输入提取特征并压缩空间尺寸,分别编号l={1,2,3,4,5}。 每一个下采样单元由:a)步长为2、核尺寸为3x3、padding为1的卷积层;b)batch normalization; c)斜率为0.1的leaky relu;d)步长为1、核尺寸为3x3、padding为1的卷积层;e)batchnormalization;f)斜率为0.1的leaky relu;依次组成。
12.步骤2b:利用2个上采样单元提取特征并恢复空间尺寸,分别编号l={6,7}。每一个上 采样单元由:a)步长为2、核尺寸为3x3、padding为0的反卷积层;b)batch normalization; c)斜率为0.1的leaky relu;d)步长为1、核尺寸为3x3、padding为1的卷积层;e)batchnormalization;和f)斜率为0.1的leaky relu;依次组成。下采样单元4和上采样单元6的 输出级联作为上采样单元7的输入。
13.步骤2c:下采样单元3和上采样单元7的输出级联作为特征金字塔的输入。特征金字塔 包括:a)一层步长为1、核尺寸为3x3、padding为1的卷积层;b)三层并列的平均池化层, 核尺寸和步长分别为(2,2)、(4,4)、(8,8);c)三层并列的核尺寸为1x1、padding为0的卷积 层,依次跟在前面的池化层之后;d)三层并列的batch normalization,依次跟在前面的卷积 层之后;e)三层并列的leaky relu层,分别跟在前面的归一化层之后;和f)三层并列的插 值层,分别跟在激活函数层之后,用于将空间分辨率恢复到原始尺寸的1/8。
14.步骤3:特征金字塔的第一层输出与最后三层的输出级联,作为双注意力机制代价计算 模块的输入。代价计算模块,由双注意力机制构成。考虑到匹配的点在左右视点下只会出现 在同一条核线上,代价计算只需要进行一维匹配即可。因此,给定一个视点下的位置,我们 只需要沿相同核线进行匹配计算。双交叉注意力具体计算方法如图2所示,具体包括以下步 骤:
15.步骤3a:以左视点特征为输入,通过1个全连接层习得key;以右视点特征为输入,通 过1个全连接层习得query;以左右视点特征的级联为输入,通过一个全连接层习得value。 如果是应用多头注意力机制,以上的全连接层神经元会被分成份,分别应用到
个通道 上,实现-头注意力机制。
16.步骤3b:对计算得到的key和query,计算注意力权重αh,公式为:,公式为:其中,q代表query,k代表key;t表示转置运算;代表单个头的特征 通道数,cf是总特征通道数;为所属头的编号。
17.步骤3c:考虑到注意力机制具有位移不变性,需要在上述方法的基础上添加位置编码信 息辅助不同匹配位置的区分。这里采用相对位置编码形式,因为绝对位置编码可以从相对位 置编码进行恢复,具体编码样式如图2所示,其中横纵坐标均为图像宽度。因此,上述注意 力权重可以表示为:其中f
l
和fr分别代表左 右图的特征,wq、w
k,f
、w
k,r
分别代表query、key-feature和key-position之间的权重,r
δ
代 表相对位置编码,其中δ表示key和query的横坐标差值,uh是每个头下单独学习得到的向量。
18.步骤3d:由于同一目标在右图中的位置一定出现在左图该目标位置的左侧,即横坐标 xr<x
l
。因此,注意力机制计算的时候只需要考虑x
l
以左的位置即可。这个遮罩会应用于注 意力机制权重,将不满足约束条件的权重置为none,不参与后续的计算。
19.步骤3e:将带有位置编码的注意力权重乘以对应的value,并将所有头的结果级联,输入 线性映射层,得到最终的输出。具体公式为:o=wo级联(αh×vh
)+bo,这里的乘法是矩 阵乘法。其中,o为匹配输出;wo和bo为输出层可学习参数;vh为第h头所对应的value。
20.步骤3f:级联左图特征、右图特征和双交叉注意力机制代价计算的输出,经过一层卷积 层后,将其作为代价聚合的输入,以参数c表示。
21.步骤4:代价聚合部分采用的是基于2d卷积的多尺度代价聚合结构,主要包括尺度内和 尺度间两种聚合模式。在代价聚合的过程中,两种模式交替使用,并且共享聚合结果。具体 步骤为:
22.步骤4a:对输入进行多尺度的尺度内聚合。聚合主要采用两种邻域位置:固定邻域和自 适应邻域。其中,固定邻域服从以中心位置为起始点的位移为1的8邻域点,共采样9个点; 自适应邻域的位移不固定,由神经网络计算得到,沿核线采样9个点。采样点之间的代价聚 合由共享参数w1和特定参数m1共同决定,其中下标l表示了不同的采样点编号。代价聚合的 公式为:其中m2代表总采样点数,代表输出代价矩 阵,p为位置,i为通道编号,p
l
为固定坐标偏移量,δp为自适应坐标偏移量。
23.步骤4b:随后对上一步的代价输出进行尺度间聚合。以3尺度为例,当目标尺度小于当 前尺度时,会对当前尺度的代价矩阵通过步长为2的卷积层下采样,直到空间尺寸与目标尺 度的空间尺寸一致;若目标尺度大于当前尺度,则通过差值上采样,直到空间尺寸与目标尺 度的空间尺寸一致;若目标尺度等于当前尺度,则无需变换。
24.步骤4c:交替上述步骤4b和4c若干次,最后经过一层卷积层完成代价聚合。最后一层 聚合的输出特征通道数为1,得到估计的视差图。
25.步骤5:分辨率恢复和细节重塑模块以步骤3所估计的视差图为输入,依次经过3次分 辨率恢复模块逐步恢复分辨率,结构图如图3所示。该部分以左视点图片、右视点图片、左 视点视差估计、左视点图片依照左视点视差估计变换到右视点下的图片、以及右视点图
片与 变换得到的右视点图片之间的差值,这5个变量按照通道级联作为结构的输入。每个分辨率 恢复模块由4个resnet模块和1个步长为2的反卷积构成,每个模块的输出在经过1层核尺 寸为1x1的卷积层之后,可以恢复为该分辨率下的视差图残差,最终将残差与上采样至同样 分辨率的视差图估计相加,得到该空间分辨率下的视差图。
26.步骤6:将视差图与真值视差图根据损失函数求得损失,通过反向传播指导网络模型参 数更新。最终得到固定的网络模型参数即可用于视差图推理。
27.本发明与现有的双目立体匹配方法相比,具有以下优势:
28.1、本发明设计了一种双交叉注意力代价计算结构,配合特殊设计的位置编码和注意力遮 罩,沿核线寻找匹配点。本方法将左视点习得的key与右视点习得的query经过计算得到权 重,应用于左右视点特征矩阵中,进而得到匹配代价,克服了传统基于卷积的代价计算方式 受限于人为设定的视差范围的影响,使得方法可以更方便地应用于不同视差估计场景。
29.2、本发明采用卷积神经网络作为特征提取、代价聚合及视差估计的基本组成结构。在特 征提取阶段,通过不同层级特征及不同尺度之间的级联,得到可以同时具有长短程视野的特 征信息,有助于处理不同尺度下的特征提取问题。在代价聚合及视差估计阶段,通过固定和 自适应两种邻域采样策略聚合匹配代价,在空间层面上进一步提升了匹配的精度和视差的可 靠性。
30.3、本发明采用了基于左右一致性校验理论所设计的残差校正和分辨率恢复模块。该模块 以左图、右图、视差图估计等为输入,通过反卷积结构逐步恢复视差图的分辨率至输入空间 分辨率,并与此同时逐步完善视差图的细节,进一步提高视差估计的精度。
附图说明
31.图1为本发明所提出的视差估计网络结构示意图。
32.图2为本发明所提出的双交叉注意力机制匹配结构图和注意力遮罩示意图。
33.图3为本发明所提出的残差校正网络结构示意图。
34.图4(a)-(f)为本发明结果与现有视差估计算法在kitti数据库下的效果对比。
35.图5(a)-(g)为本发明结果与现有视差估计算法在middlebury数据库下的效果对比。
具体实施方式
36.下面将结合附图和实施例对本发明作进一步的详细说明。
37.在以已校正的数据库图像为输入的条件下,本发明包括如下步骤:
38.步骤1:针对目标数据库数据形式撰写数据处理函数,指定双目图片路径和训练集真值 路径,用于网络训练。以sceneflow数据库为例,其中训练集和测试集共包括3万9千张图 片。在本方法中,80%的训练集用于网络训练,剩余的20%用于训练中的交叉验证,测试集 全部仅留作测试使用,不以任何形式参与网络的训练或者精调。训练集数据会经过数据扩张 操作,具体包括:
39.步骤1a:对左右图同时进行竖直方向的位移和旋转变换。其中,位移在
±
1.5像素范围内 进行,具体位移量随机确定。旋转发生在
±
0.5度之间,具体旋转量随机确定。上述
位移和角 度的随机数取值服从[0,1)范围内的均匀分布。
[0040]
步骤1b:按照50%概率对rgb三通道独立进行亮度变换,所有通道变化均服从范围在 (-20,20)区间内的均匀分布,变换是对每个像素上的数值发生的。左右图有20%的概率应用不 同的变换数值。
[0041]
步骤1c:随后,算法有50%的概率选择对输入进行高斯白噪声或者亮度对比度变换。其 中,高斯噪声服从均值为0、方差在(10,50)范围内的高斯分布,其中方差的选择服从[0,1)范 围内的均匀分布。亮度对比度变换是对图像亮度进行(-0.2,0.2)范围内的亮度和对比度变换。 同样,左右图有20%的概率应用不同的变换数值。
[0042]
步骤2:撰写特征提取部分的网络结构代码。特征提取模块的代码可以主要拆分为下采 样单元、上采样单元和金字塔单元的定义。注意每个单元中的层在多次应用的时候不可以共 用,需要多次定义具体的层。左图和右图共享特征提取部分的参数,最终输出的是提取好的 左图和右图特征。特征提取具体包括如下步骤:
[0043]
步骤2a:定义5个下采样单元,分别编号l={1,2,3,4,5}。每一个下采样单元由:a)步 长为2、核尺寸为3x3、padding为1的卷积层;b)按通道的batch normalization;c)斜率为 0.1的leaky relu;d)步长为1、核尺寸为3x3、padding为1的卷积层;e)按通道的batchnormalization;f)斜率为0.1的leaky relu;依次组成。下采样单元的输入输出通道数,从 单元1到单元5,依次为:(3,32)、(32,64)、(64,128)、(128,256)、(256,512)。
[0044]
步骤2b:定义2个上采样单元,分别编号l={6,7}。每一个上采样单元由:a)步长为2、 核尺寸为3x3、padding为0的反卷积层;b)按通道的batch normalization;c)斜率为0.1的 leaky relu;d)步长为1、核尺寸为3x3、padding为1的卷积层;e)按通道的batchnormalization;和f)斜率为0.1的leaky relu;依次组成。上采样单元6以下采样单元5的 输出为输入,上采样单元7以下采样单元4和上采样单元6的输出级联为输入,因此,上采 样单元的输入输出通道数,从单元6到单元7,依次为:(512,256)、(256+256,256)。
[0045]
步骤2c:定义特征金字塔,包括:a)一层步长为1、核尺寸为3x3、padding为1的卷积 层;b)三层并列的平均池化层,核尺寸和步长分别为(1,1)、(2,2)、(4,4);c)三层并列的核 尺寸为1x1、padding为0的卷积层,依次跟在前面的池化层之后;d)三层并列的按通道的 batch normalization,依次跟在前面的卷积层之后;e)三层并列的斜率为0.1的leaky relu 层,分别跟在前面的归一化层之后;和f)三层并列的插值层,分别跟在激活函数层之后,用 于将空间分辨率恢复到原始尺寸的1/8。下采样单元3和上采样单元7的输出级联作为特征金 字塔的输入,因此,特征金字塔各部分输入输出通道依次为:第一个总卷积层(256+128,128), 其余三个尺度均为(128,128)。
[0046]
步骤3:代价计算部分以特征金字塔三个尺度下的输出分别作为输入。这里为了表述简 介,统一用h和w表示特征的空间尺寸下的高和宽,对于不同尺度,h和w为相应的下采 样结果(原始输入图像的1/8或1/16或1/32)。以如前文所述,对于校正后的图像,匹配的位 置只会出现在相同极线上,因此在代价计算之前先将左右视点特征从nxcxhxw格式转换成 wxnhxc格式,其中n是每个batch所采用的图像数量。对于sceneflow数据集,其输入图 片尺寸为960x540,训练过程采用batch size=1,以1/8尺度为例,此时对应的特征尺寸为1x128x64x120,变换后的尺寸为120x64x128。在此基础上,再进行代价计算。下面尺寸计算 均以1/8尺度为例,其他尺度下类似。具体步骤如下:
[0047]
步骤3a:分别以左视点特征、右视点特征和左右视点级联后的特征为输入,通过3个全 连接层习得对应的key,query和value。这里的全连接层使用的是pytorch中的nn模块里面的 linear函数。随后,根据多头注意力机制的思路,将key、query和value从wxnhxc变换成 其中w是特征宽度,取值120;nh为batch size乘以高度,等于1x64=64; 为头数,取值8;c1是每个头下的通道数,为128/8=16。因此,key、query和value的维 度均为120x64x8x16。
[0048]
步骤3b:根据计算得到的key(k)和query(q),根据公式求得注意力权重步骤3b:根据计算得到的key(k)和query(q),根据公式求得注意力权重其中t为转置运算,代表单个头的特征通道数,cf是总特 征通道数;为所属头的编号。计算得到的注意力权重尺寸为其中nh是batch size乘以高度,值为1x64=64;为头数,取值8;w是特征宽度,取值120。 因此,注意力权重维度为64x8x120x120。
[0049]
步骤3c:对上述注意力权重添加相对位置编码信息。首先根据宽度w移位生成相对位置 编码,编码尺寸为(2w-1)xc。其中w为宽度,等于120;c是特征通道数,等于128。其生 成方式是在区间(-w+1,w-1)内,生成均匀2w-1个值,即每个单位位置上有一个值。而后穿 插sin和cos的求解结果,放置在对应位置上。最后将注意力编码矩阵转换成尺寸为wxwxc 的形式,即120x120x128。以此为输入,用跟步骤3a中相似的方法,以位置编码为输入,求 得qr和kr,分别与key和query计算得到带有位置编码的注意力权重。最后将三个注意力权 重相加,得到带有全部编码信息的注意力权重αh,维度为64x8x120x120。
[0050]
步骤3d:由于同一目标在右图中的位置一定出现在左图该目标位置的左侧,即横坐标 xr<x
l
。因此,注意力机制计算的时候只需要考虑x
l
以左的位置即可。根据这个原则,将注 意力权重αh中不满足条件的位置置为none。具体实现方法是,生成一个上三角阵,将其中值 为1的位置所对应的αh中的所有通道的值设为none,不参与后续计算。所生成的mask尺寸 为wxw,即120x120。
[0051]
步骤3e:最后将带有位置编码的注意力权重乘以对应的value,得到匹配结果。首先,将 value的维度从变成将αh的维度从变成 随后将二者进行矩阵乘法,将得到输出从维度变换到维度 wxnhxc。再通过全连接层习得多头下的value,最终输出尺寸为wxnhxc,即120x64x128。
[0052]
步骤3f:将匹配结果尺寸转换为nxcxhxw后与左右视点下的特征级联,得到nx3cxhxw 的矩阵,将其送入一层核尺寸为1x1,步长为1的卷积层中,将矩阵按照通道整合信息,最 终得到尺寸为nxcxhxw的输出,作为匹配代价。具体而言,输出尺寸是1x128x64x120。
[0053]
步骤4:将步骤3得到的输出作为代价聚合部分的输入,通过尺度内和尺度间两种聚合 计算的交替进行,得到最终的视差图估计。具体步骤为:
[0054]
步骤4a:首先对输入进行尺度内聚合,聚合公式为其中,p
l
和δp分别为固定位移和可学习位移,其他参数定义与前文所述相同。这里,采用3 层卷积层实现,核尺寸分别为1x1、3x3和1x1。其中,第二层为可变形卷积。卷积计算前后, 矩阵的空间尺寸不变,分别为1/8、1/16和1/32。通道
数除第一组外,每聚合一组下降一倍, 即输入输出通道数再三个尺度下均为(128,128)、(128,64)、(64,32)、(32,16)、(16,8)、(8,4)。
[0055]
步骤4b:对步骤4a的输出结果进行尺度间聚合。根据输入输出尺度关系,可以分为以 下几种情况:尺度1(1/8)到尺度2(1/16)、尺度2到尺度3(1/32),采用一个核尺寸为3x3、 步长为2的卷积层过渡;尺度1到尺度3,采用两个核尺寸为3x3、步长为2的卷积层过渡; 尺度2到尺度1、尺度3到尺度1、尺度3到尺度2,首先双线性插值进行上采样,之后用一 个核尺寸为1x1、步长为1的卷积层过渡;尺度1到尺度1、尺度2到尺度2、尺度3到尺度 3,不做变化。之后,将该尺度下的三个映射结果按通道相加后再做归一化。
[0056]
步骤4c:交替上述步骤4b和4c共计6次,再将结果送入1层核尺寸为1x1、步长为1 的卷积层完成代价聚合。最后一层聚合的输入特征通道为4,输出特征通道数为1,输出结果 即为该尺度下的视差图估计。
[0057]
步骤5:残差校正模块输入为:左图、右图、左图根据左视点视差图warp到右视点下的 结果、两张右图之间的像素差、估计得到的左视点视差图。其中warp的含义是根据视差,将 相应rgb数值移动到根据视差偏移后的位置上,纵坐标不变。遮挡区域值为0。将5个输入 按照通道级联,以rgb图为例,通道数总数为3+3+3+3+1=13。将其送入一层核尺寸为3x3、 步长为1、padding为1的卷积层中,输出通道数为64。之后,送入残差校正单元恢复分辨率。 每个残差校正单元由4个resnet模块和1个步长为2的反卷积构成,其中resnet模块采用 默认参数,反卷积核尺寸为3x3。所有卷积层输出通道数均为64。将单元的输出送入一个核 尺寸为1x1、步长为1的卷积层之后,即可得到该分辨率下的视差图估计残差。分辨率分别 为1/4、1/2和1。将不同分辨率下的视差图估计残差与双线性插值上采样至相同分辨率下的 视差图相加,即可得到残差校正后的视差图估计。
[0058]
步骤6:撰写损失函数。本发明中采用了平滑l1损失,该损失应用于所有尺度下的视差 图。在计算损失时,视差图真值会被下采样到与估计视差图相同的空间尺寸。考虑到不同空 间尺寸下的重要性和像素个数,本发明中对各尺度的损失采用了加权求和的方式。具体权重 为:1(视差估计网络,1/8尺寸),0.2(视差估计网络,1/16尺寸),0.2(视差估计网络,1/32 尺寸),1(残差校正网络,1尺寸),0.5(残差校正网络,1/2尺寸),0.5(残差校正网络, 1/4尺寸)。设定训练epoch数为40,用4个nvidiap100 gpu训练,参数优化采用带权重 的adam方法,监测每当损失收敛即减半学习率。每个epoch训练结束后,测试得到的网络 参数,作为交叉验证。得到最终网络参数即可作为固定模型。
[0059]
下面结合实验仿真,对本发明的技术效果做进一步说明:
[0060]
1.仿真条件
[0061]
采用pytorch框架,硬件条件为4块英伟达p100显卡。预训练数据库为sceneflow,训 练集数据中的80%留作训练集,剩下的20%作为验证集。网络以0.0001学习率开始训练,采 用adamw参数更新策略,batch size为2。共训练40个epoch,在20和30个epoch时,学 习率减半。fine-tune在kitti数据库下进行,85%的训练集数据用于训练,余下的15%作为 验证集。训练首先在kitti混合数据集下进行,共训练200个epoch。之后对kitti2012和 kitti2015数据库分别精调,每个数据库下训练100个epoch。学习率从0.0001开始,每个 epoch采用指数更新策略更新。
[0062]
2.仿真内容及结果分析
[0063]
仿真1在kitti2015数据库的测试集下测试了本发明,并且与其他相关研究做了对比。 实验结果如图4所示。其中列(a)表示左视点图像输入,列(b)-(e)为4个用于对比的方法,列 (f)为本方法结果。第一行和第三行为输入图片或视差图估计,第2行和第4行为误差图,颜 色越深的区域越准确,颜色越浅表示误差越大。纯黑区域没有真值。可以看到,在白色矩形 所框出的区域,本方法具有明显更准确的估计结果。
[0064]
仿真2在middlebury2014数据库的测试集下测试了本发明,并且与其他相关研究做了对 比。注意这里所用的模型是在sceneflow数据集下训练的,没有在middlebury数据集下进行 任何形式的训练或优化,因此可以说明本方法的适应性。实验结果如图5所示。其中,列(a) 为左视点图像输入,列(b)-(f)为用于对比的方法,列(g)为本方法结果。第一行和第二行为两 个输入场景。可以看到,由白色或者黑色矩形框出的区域内,本方法具有明显更准确的结果。
[0065]
仿真3在sceneflow数据集下对本发明在不同视差范围下的表现做了测试,并与相关研 究成果做了对比。其中,除本发明和sttr方法外,其他方法(如果可以的话),都在最大视 差为480的条件下重新训练以保证对比的公平性。可以看出,本发明有效提升了精度,且在 大视差范围下,精度提升更为明显。其中,3像素误差表示误差大于3像素的像素数量所占 百分比。本方法为1.53%,相比较其他算法提升了近一倍。epe表示end-point error,为平均 像素误差。本方法为0.66,也明显高于其他算法。实验结果如表1所示。表1为本发明结果 与现有视差估计算法在sceneflow数据库下的不同视差范围下的表现结果对比。
[0066]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1