一种基于改进的YoloX的戏曲角色妆容脸部检测方法
一种基于改进的yolox的戏曲角色妆容脸部检测方法
技术领域
1.本发明涉及计算机图形学处理,具体涉及一种基于改进的yolox的戏曲角色妆容脸部检测方法。
背景技术:
2.戏曲艺术作为中华非物质文化遗产,是中华文明传承的重要载体。传播、传承、推广戏曲艺术,对增强民族自信和自豪,弘扬民族文化,意义重大。戏曲表演绘声绘色、眉目传情,妆容精致,蕴含着丰富的文化信息。戏曲中妆容丰富,代表着对人物的形象创造,使得观众对戏剧中人物的角色、性格,在登场的一刹那,不需道出身份,即有鲜明的基本认识。戏曲化妆从一勾一抹的化妆中彰显人物的性格化,朝着“写意”方向发展,具有虚拟性、象征性、夸张性的特点,如戏曲中的生、旦角色为了将人物烘托得更鲜明,将眼睛和眉毛故意吊高;净、丑角色常将眉、鼻窝、嘴唇等夸张地拉大、变形,以便能吸引观众的注意及突显人物角色的性格化。目前,计算机在图像、视频领域都有一定的研究进展,但对具有脸谱妆容的戏曲角色方面研究还很少。人脸检测是人脸识别、人脸老化、人脸表情识别等任务的前提条件,同样,戏曲角色妆容脸部检测也是戏曲角色识别、身份识别、情感识别等任务的首要工作,因为只有将具有戏曲特定妆容的脸部检测出来,才能更好地研究这些独特特点背后的含义。
3.由于戏曲有自己的特点,有特定的脸谱妆容,与人们平时化妆或演出的妆容存在较大差异。目前,不论是采用现有的探索人脸独特特征的人脸检测器,还是采用通用目标检测器都无法准确检测出戏曲角色化妆后的脸部。因此,迫切需要研究实现能够检测出戏曲特定妆容的脸部检测器,以支撑对戏曲文化传承保护和对戏曲文化艺术风格的研究。
技术实现要素:
4.针对现有技术的不足,本发明的目的在于提供一种基于改进的yolox的戏曲角色妆容脸部检测方法,以解决现有技术无法准确检测戏曲角色带妆脸部的问题。
5.为了实现上述目的,本发明采用以下技术方案予以实现:
6.一种基于改进的yolox的戏曲角色妆容脸部检测方法,包括如下步骤:
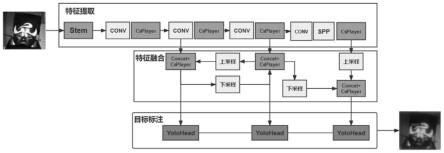
7.步骤1、对通用目标检测算法yolox进行改进:将主干网络cspdarknet中的focus模块替换为stem模块,调整加强特征提取网络fpn中的spp模块池化核为更小的核,在分类器与回归器yolo head中引入5个人脸关键点进行回归;
8.步骤2、数据预处理:收集秦腔戏曲妆容人脸数据,对其进行标注,并添加到公共人脸数据集中,然后使用mosaic方法通过随机缩放、随机裁剪和随机排布的方式对数据集进行增强,并将增强后的数据传入改进后的yolox的输入端进行特征层堆叠,扩充通道;
9.步骤3、特征提取:将经输入端处理过的数据传入主干网络cspdarknet中进行特征提取,获取到三个特征层;
10.步骤4、特征融合:将步骤3获得的三个特征层传入加强特征提取网络fpn,分别使
用上采样和下采样的方式实现特征融合,得到三个加强过的有效特征层;
11.步骤5、目标标注:将三个加强过的有效特征层传入yolox的分类器与回归器yolo head中得到特征图,并将其转化为特征点的集合,判断特征点是否有物体与其对应,获得最终的预测结果;
12.步骤6、对预测结果进行解码:预测结果分为reg预测结果、obj预测结果和cls预测结果三个部分,将三者结合绘制出相应的预测框;
13.步骤7、对得到的预测框进行得分排序与非极大值抑制,找出得分满足置信度的预测框并筛选出一定区域内属于同一种类且得分最大的预测框,即为最终的检测结果。
14.进一步地,所述步骤5在分类器与回归器yolo head中,采用更适用于人脸检测的loss函数,损失函数为:
[0015][0016]
该损失函数的作用是对于小误差,表现为具有偏移量的对数函数,而对于大误差,则表现为l1损失函数:l1(x)=|x|;其中,正数ω将非线性部分的范围限制在[-ω,ω]区间内,e代表约束非线性区域的曲率,并且为一个常数,平滑地连接了分段定义的线性和非线性部分。
[0017]
本发明与现有技术相比,具有如下技术效果:
[0018]
本发明首先对通用目标检测算法yolox进行改进:将主干网络cspdarknet中的focus模块替换为stem模块,调整加强特征提取网络fpn中的spp模块池化核为更小的核,在分类器与回归器yolo head中引入5个人脸关键点进行回归。然后收集含戏曲妆容的人脸数据,对其进行标注,添加到公共人脸数据集中,使用mosaic方法通过随机缩放、随机裁剪、随机排布的方式进行数据增强,并将增强后的数据传入输入端进行特征层堆叠,通道扩充。经过输入端处理过的数据传入主干网络cspdarknet中进行特征提取,获取到三个特征层。在主干部分获得的三个特征层传入加强特征提取网络fpn,分别使用上采样和下采样的方式实现特征融合,得到三个加强过的有效特征层。将三个加强过的有效特征层传入yolox的分类器与回归器yolo head中得到特征图,并将其转化为特征点的集合,判断特征点是否有物体与其对应,获得最终的预测结果。最后对得到的预测结果进行解码,绘制出相应的预测框,并利用置信度与非极大值抑制筛选出最终的检测结果。
[0019]
本发明将主干网络中的focus模块替换为stem模块后进行特征提取,提高了网络的泛化能力,在不降低性能的同时降低了计算复杂度,提升了检测速率;调整加强特征提取网络fpn中的spp模块池化核为更小的核使得yolox更适用于人脸检测,提高了检测精度;引入人脸关键点进行回归,提高了检测精度。本方法实现了基于改进的yolox的戏曲角色妆容脸部检测,操作简便,使得训练出的人脸检测器可以准确检测出戏曲角色具有特定妆容的脸部,并提高了一般人脸检测的速率和精度。
附图说明
[0020]
图1为本发明实施例经步骤2预处理后的数据图像示意图;
[0021]
图2为本发明实施例中改进后的通用目标检测算法yolox的结构示意图;
[0022]
图3为本发明实施例改进后的spp结构示意图;
[0023]
图4为本发明实施例所涉及的改进后的yolox的分类器与回归器yolo head的工作流程图;
[0024]
图5为采用通用目标检测器yolox对戏曲人物检测的效果图;
[0025]
图6为采用本发明实施例所述方法对戏曲人物检测的效果图。
具体实施方式
[0026]
以下结合实施例对本发明的具体内容做进一步详细解释说明。
[0027]
参照图1-6,本实施例提供一种基于改进的yolox的戏曲角色妆容脸部检测方法,包括如下步骤:
[0028]
步骤1、对通用目标检测算法yolox进行改进:将主干网络cspdarknet中的focus模块替换为stem模块;调整加强特征提取网络fpn中的spp模块池化核为更小的核;在分类器与回归器yolo head中引入5个人脸关键点进行回归;
[0029]
步骤2、数据预处理:收集秦腔戏曲妆容人脸数据,对其进行标注,并添加到公共人脸数据集中,然后使用mosaic方法通过随机缩放、随机裁剪和随机排布的方式对数据集进行增强,增强前后的数据图像示例见图1所示;然后将增强后的数据传入改进后的yolox的输入端进行特征层堆叠,扩充通道;
[0030]
步骤3、特征提取:将经yolox输入端处理过的数据传入主干网络cspdarknet中进行特征提取,获取到三个特征层;
[0031]
其中,主干网络cspdarknet主要包括残差网络residual、cspnet、stem、spp网络结构和silu激活函数,利用残差网络和残差块,使用跳跃连接缓解深度神经网络中增加深度带来的梯度消失问题,并通过spp模块不同池化核大小的最大池化进行特征提取,得到输入图片的特征集合,改进后的spp结构如图3所示;
[0032]
步骤4、将在主干网络cspdarknet部分获得的三个特征层传入加强特征提取网络fpn,分别使用上采样和下采样的方式实现特征融合,得到三个加强过的有效特征层;
[0033]
其中,在主干网络中提取出的三个特征层分别位于主干网络的中间层、中下层、底层;当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024);将三个特征层传入fpn后,feat3=(20,20,1024)的特征层进行1次1x1卷积调整通道后获得p5,p5进行上采样umsampling2d后与feat2=(40,40,512)特征层进行结合,然后使用csplayer进行特征提取获得p5_upsample,此时获得的特征层为(40,40,512);p5_upsample=(40,40,512)的特征层进行1次1x1卷积调整通道后获得p4,p4进行上采样umsampling2d后与feat1=(80,80,256)特征层进行结合,然后使用csplayer进行特征提取p3_out,此时获得的特征层为(80,80,256);p3_out=(80,80,256)的特征层进行一次3x3卷积,并下采样后与p4堆叠,然后使用csplayer进行特征提取p4_out,此时获得的特征层为(40,40,512);p4_out=(40,40,512)的特征层进行一次3x3卷积,并下采样后与p5堆叠,然后使用csplayer进行特征提取p5_out,此时获得的特征层为(20,20,1024);最终获得三个加强过的有效特征层,如图2所示。
[0034]
步骤5、将三个加强过的有效特征层传入yolox的分类器与回归器yolo head中得
到特征图,并将其转化为特征点的集合,判断特征点是否有物体与其对应,获得最终的预测结果;
[0035]
其中,经过fpn特征金字塔后,获得的三个加强过的有效特征层维度分别为(20,20,1024)、(40,40,512)、(80,80,256),将这三个加强过的有效特征层传入yolo head中获取预测结果;
[0036]
对于每一个特征层,获得三个预测结果,分别是1、reg(h,w,4)用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;2、obj(h,w,1)用于判断每一个特征点是否包含物体;3、cls(h,w,num_classes)用于判断每一个特征点所包含的物体种类;将三个预测结果进行堆叠,每个特征层获得的结果为:out(h,w,4+1+num_classses)前四个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;第五个参数用于判断每一个特征点是否包含物体;最后num_classes个参数用于判断每一个特征点所包含的物体种类。
[0037]
本发明通过在分类器与回归器yolo head中引入5个人脸关键点进行回归,引用更适用于人脸检测的wing-loss函数,来提升人脸检测的精度,该损失函数为:
[0038][0039]
该损失函数的作用是对于小误差,表现为具有偏移量的对数函数,而对于大误差,则表现为l1损失函数:l1(x)=|x|;其中,正数ω将非线性部分的范围限制在[-ω,ω]区间内,e代表约束非线性区域的曲率,并且为一个常数,平滑地连接了分段定义的线性和非线性部分。
[0040]
步骤6、对预测结果进行解码:预测结果分为三个部分,reg预测结果、obj预测结果和cls预测结果;reg代表预测框的中心点相较于该特征点的偏移情况和预测框的宽高相较于对数指数的参数,obj代表每一个特征点预测框内部包含物体的概率,cls代表每一个特征点对应某类物体的概率,将reg、obj、cls三者结合绘制出相应的预测框,详情见图4所示。
[0041]
步骤7:对得到的最终预测框进行得分排序与非极大值抑制,找出得分满足置信度的预测框并筛选出一定区域内属于同一种类且得分最大的预测框,即为最终的检测结果。
[0042]
图5为采用原始通用目标检测器yolox对戏曲人物检测的效果图,可以看到,带有净角大花脸妆容的戏曲角色无法检测出。
[0043]
图6为采用本发明所述方法对戏曲人物检测的效果图,由图可以看出,本发明所述方法可以成功检测出戏曲净角带有特定妆容的脸部。
[0044]
综上所述,本发明在通用目标检测器yolox上进行了模块替换、调整池化核大小并引入关键点检测的改进,在提高了人脸检测精度和速率的同时有效地解决了带有戏曲特定妆容的人脸因具有虚拟性、夸张性等特点无法准确检测的问题,为实现戏曲面部情感识别、戏曲角色身份识别等后续方向奠定了基础,对发扬戏曲传统文化具有重要意义。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1