一种复合信息分层卷积神经网络的钻机健康状况评估方法
1.本发明涉及煤矿大型机电装备的健康管理技术领域,尤其涉及一种复合信息分层卷积神经网络的钻机健康状况评估方法。
背景技术:
2.煤层开采主要有地面钻采和井下抽采两种模式,井下抽采主要依靠钻机,因此钻机是煤炭安全高效开采中不可或缺的装备。由于钻机的智能化程度低,只能凭借作业人员经验对钻机的健康状态判断,存在安全隐患,严重限制了传统煤矿向“智慧矿山”的发展。
3.目前,常见的设备健康状态评估方法主要有基于模型的评估方法、基于经验的评估方法和基于数据的评估方法。基于模型的评估方法虽然精度准确,但难以建立精准的数学模型;基于经验的评估方法主要根据专家经验进行评估,评估结果直观,但是受主观因素影响,很难满足智能化需求;基于数据的评估方法分为人工提取特征的数据评估方法和自动提取特征的数据评估方法,主要根据设备状态信息建立模型进行故障诊断和健康评估。
4.基于人工提取特征的数据评估方法主要包含以下三个步骤:1)信号分析,2)特征提取,3)智能诊断。特征提取的质量对于最后的评估结果起到决定性作用,然而这种方法需要人为提取特征,只能提供有限的健康评估能力,存在一定的局限性。
5.因此,提出一种复合信息分层卷积神经网络的钻机健康状况评估方法,来解决现有技术存在的困难,是本领域技术人员亟需解决的问题。
技术实现要素:
6.鉴于此,本发明提供了一种复合信息分层卷积神经网络的钻机健康状况评估方法,基于钻机电控系统与液压系统所获取的各类传感器信息,建立用于钻机健康评估的复合信息分层卷积神经网络模型,对钻机的运行状态进行准确分类与健康状态实现有效评估。
7.为了实现上述目的,本发明采用如下技术方案:
8.一种复合信息分层卷积神经网络的钻机健康状况评估方法,包括以下步骤:
9.获取数据步骤:获取钻机不同工况和不同健康状态下的钻车电流数据、泵车电流数据作为第一数据集,以及钻机多个工作状态数据作为第二数据集;
10.二维矩阵构建步骤:截取第一数据集中一定长度的数据段,作为一个时域样本,相邻两个样本以一定的重合率首尾重合,得到第一数据集的两个二维矩阵,将第二数据集进行复制并补零构成一个与第一数据集的二维矩阵同尺寸的二维矩阵;
11.三维矩阵构建步骤:将第一数据集的二维矩阵和第二数据集的二维矩阵沿着厚度方向分别叠放在不同的层,排列融合重塑为一个具有多层的三维矩阵复合信息样本,钻机不同工况和不同健康状态下的所有样本构成一个数据集;
12.数据划分步骤:将数据集及对应的样本输出标签矩阵构成样本对,将样本对打乱顺序,并按照一定的比例划分为训练集和测试集;
13.构建神经网络模型步骤:依据样本厚度进行平均分组,一层即为一个独立卷积通道,卷积通道的个数为样本的厚度;复合信息分层卷积神经网络模型由多个独立的卷积通道组成;
14.神经网络模型训练步骤:将训练集输入至复合信息分层卷积神经网络模型,输出各样本对应的预测值,根据输出的预测值与目标值通过损失函数进行误差分析,更改模型各个权重值;
15.训练结束判定步骤:判断是否达到最大迭代次数,若为否,则返回神经网络模型训练步骤继续训练;若为是,则结束模型训练步骤,输出基于复合信息分层卷积神经网络模型;
16.钻机健康状况预测步骤:将测试集输入基于复合信息分层卷积神经网络模型,输出待评估钻机健康状况的预测值。
17.可选的,获取数据步骤中钻机多个工作状态数据包括:流量、压力、温度、油位、电压、电阻率、方位角低阈值信号。
18.可选的,三维矩阵构建步骤中的数据集表示为:x∈rh×w×d×n,其中,x表示一个样本,h表示样本的行,w表示样本的列,d表示通道数,即原始信号的种类数,n表示样本个数。
19.可选的,数据划分步骤中的样本输出标签矩阵具体为:对于钻机的每一种状态分别定义一个标签,每个样本的输出标签为小于等于m的一个整数,其中m为状态的分类数,相应地样本输出矩阵为一个n
×
1的样本输出标签矩阵,其中n表示样本个数。
20.可选的,构建神经网络模型步骤中,每个通道的参数保持一致,每个通道的特征提取独立并行。
21.可选的,构建神经网络模型步骤中复合信息分层卷积神经网络模型的结构为:每一组通道包括一个输入层、4个卷积层、4个池化层,多组通道共用一个全连接层,一个softmax输出层,输出层包括m个神经元,其中m为状态的分类数;网络中的卷积核采用多个不同尺寸的小卷积核级联,卷积层采用relu函数作为非线性激活函数;池化采用最大池化法。
22.可选的,卷积过程为:si=f(con(mi,ci)+bi)
ꢀꢀꢀ
(1)
23.其中式中si为输出特征图,f为激活函数,con为卷积运算,mi是输入特征图,ci是卷积核,bi为偏置。
24.可选的,最大池化的定义如下:
25.式中,为l+1层第i个输入特征矢量中第h个值,d为池化域;为l+1层第i个输出特征矢量中第g个值。
26.可选的,在softmax输出层中,计算每个类别发生的概率,表达式为
[0027][0028]
式中oj为输出层第j个神经元输出概率值,aj为输出层第j个神经元的输出值;n为输出层神经元个数。
[0029]
可选的,神经网络模型训练步骤中采用交叉熵误差作为目标损失函数,
[0030]
交叉熵误差为:
[0031]
式中n为样本数,k为输出神经元个数,y
nk
为第n个样本第k个输出的目标值,为第n个样本第k个输出的预测值。
[0032]
经由上述的技术方案可知,与现有技术相比,本发明提供了一种复合信息分层卷积神经网络的钻机健康状况评估方法:提取多传感器信息的特征,采取自适应提取特征的方法,构建一种多信息融合的复合信息样本,依据厚度分层,以分层独立卷积神经网络的深度学习,建立用于钻机健康评估的复合信息分层卷积神经网络模型,对钻机的运行状态进行准确分类与健康状态实现有效评估,对钻机的维护工作起到一定的指导意义,同时也保证了安全生产和作业人员的人身安全。
附图说明
[0033]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0034]
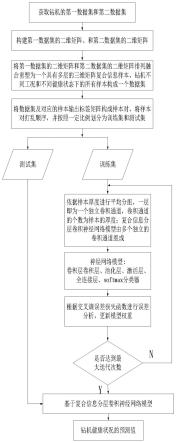
图1为本发明提供的一种复合信息分层卷积神经网络的钻机健康状况评估方法流程图;
[0035]
图2为本发明提供的复合信息分层卷积神经网络模型结构示意图;
[0036]
图3为本发明提供的一种复合信息分层卷积神经网络的钻机健康状况评估系统结构框图。
具体实施方式
[0037]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0038]
参照图1所示,本发明公开了一种复合信息分层卷积神经网络的钻机健康状况评估方法,包括以下步骤:
[0039]
获取数据步骤:获取钻机不同工况和不同健康状态下的钻车电流数据、泵车电流数据作为第一数据集,以及钻机多个工作状态数据作为第二数据集;
[0040]
二维矩阵构建步骤:截取第一数据集中一定长度的数据段,作为一个时域样本,相邻两个样本以30%首尾重合,得到第一数据集的两个二维矩阵,将第二数据集进行复制并补零构成一个与第一数据集的二维矩阵同尺寸的二维矩阵;
[0041]
三维矩阵构建步骤:将第一数据集的二维矩阵和第二数据集的二维矩阵沿着厚度方向分别叠放在不同的层,排列融合重塑为一个具有多层的三维矩阵复合信息样本,钻机不同工况和不同健康状态下的所有样本构成一个数据集;
[0042]
数据划分步骤:将数据集及对应的样本输出标签矩阵构成样本对,将样本对打乱
顺序,并按照一定比例划分为训练集和测试集;
[0043]
构建神经网络模型步骤:依据样本厚度进行平均分组,一层即为一个独立卷积通道,卷积通道的个数为样本的厚度;复合信息分层卷积神经网络模型由多个独立的卷积通道组成;
[0044]
神经网络模型训练步骤:将训练集输入至复合信息分层卷积神经网络模型,输出各样本对应的预测值,根据输出的预测值与目标值通过损失函数进行误差分析,更改模型各个权重值;
[0045]
训练结束判定步骤:判断是否达到最大迭代次数,若为否,则返回神经网络模型训练步骤继续训练;若为是,则结束模型训练步骤,输出基于复合信息分层卷积神经网络模型;
[0046]
钻机健康状况预测步骤:将测试集输入基于复合信息分层卷积神经网络模型,输出待评估钻机健康状况的预测值。
[0047]
进一步的,获取数据步骤中钻机多个工作状态数据包括:流量、压力、温度、油位、电压、电阻率、方位角低阈值信号。
[0048]
进一步的,二维矩阵构建步骤中,相邻两个样本以一定的重合率首尾重合,该重合率可以选择30%;所得到的第一数据集的两个二维矩阵分别是钻车电流对应的一个二维矩阵,泵车电流对应的另一个二维矩阵。
[0049]
进一步的,三维矩阵构建步骤中的数据集表示为:x∈rh×w×d×n,其中,x表示一个样本,h表示样本的行,w表示样本的列,d表示通道数,即原始信号的种类数,n表示样本个数。
[0050]
进一步的,数据划分步骤中的样本输出标签矩阵具体为:对于钻机的每一种状态分别定义一个标签,每个样本的输出标签为小于等于m的一个整数,其中m为状态的分类数,相应地样本输出矩阵为一个n
×
1的样本输出标签矩阵,其中n表示样本个数。
[0051]
进一步的,将样本对的前70%为测试集,后30%为训练集。
[0052]
进一步的,构建神经网络模型步骤中,每个通道的参数保持一致,每个通道的特征提取独立并行。
[0053]
进一步的,参照图2所示,构建神经网络模型步骤中复合信息分层卷积神经网络模型的结构为:每一组通道包括一个输入层、4个卷积层、4个池化层,多组通道共用一个全连接层,一个softmax输出层,输出层包括m个神经元,其中m为状态的分类数;网络中的卷积核采用多个不同尺寸的小卷积核级联,卷积层采用relu函数作为非线性激活函数;池化采用最大池化法。
[0054]
更进一步的,卷积过程为:si=f(con(mi,ci)+bi)
ꢀꢀꢀ
(1)
[0055]
其中式中si为输出特征图,f为激活函数,con为卷积运算,mi是输入特征图,ci是卷积核,bi为偏置。
[0056]
更进一步的,最大池化的定义如下:
[0057]
式中,为l+1层第i个输入特征矢量中第h个值,d为池化域;为l+1层第i个输出特征矢量中第g个值。
[0058]
更进一步的,在softmax输出层中,计算每个类别发生的概率,表达式为
[0059]
式中oj为输出层第j个神经元输出概率值,aj为输出层第j个神经元的输出值;n为输出层神经元个数。
[0060]
更进一步的,神经网络模型训练步骤中采用交叉熵误差作为目标损失函数,交叉熵误差为:
[0061]
式中n为样本数,k为输出神经元个数,y
nk
为第n个样本第k个输出的目标值,为第n个样本第k个输出的预测值。
[0062]
参照图3所示,本发明还公开了一种复合信息分层卷积神经网络的钻机健康状况评估方法,包括:数据获取模块、二维矩阵构建模块、三维矩阵构建模块、数据划分模块、神经网络构建模块、神经网络训练模块、基于复合信息分层卷积神经网络模型和钻机健康状况预测值输出模块;
[0063]
数据获取模块,与二维矩阵构建模块连接,用于获取钻机不同工况和不同健康状态下的钻车电流数据、泵车电流数据作为第一数据集,以及钻机多个工作状态数据作为第二数据集;
[0064]
二维矩阵构建模块,与三维矩阵模块连接,用于截取第一数据集中一定长度的数据段,作为一个时域样本,相邻两个样本以一定的重合率首尾重合,得到第一数据集的两个二维矩阵,将第二数据集进行复制并补零构成一个与第一数据集的二维矩阵同尺寸的二维矩阵;
[0065]
三维矩阵构建模块:将第一数据集的二维矩阵和第二数据集的二维矩阵沿着厚度方向分别叠放在不同的层,排列融合重塑为一个具有多层的三维矩阵复合信息样本,钻机不同工况和不同健康状态下的所有样本构成一个数据集;
[0066]
数据划分模块,用于将数据集及对应的样本输出标签矩阵构成样本对,将样本对打乱顺序,并按照一定的比例划分为训练集和测试集;
[0067]
构建神经网络模型模块,与数据划分模块训练集输出端口连接,用于依据样本厚度进行平均分组,一层即为一个独立卷积通道,卷积通道的个数为样本的厚度;复合信息分层卷积神经网络模型由多个独立的卷积通道组成;
[0068]
神经网络模型训练模块,与构建神经网络模块连接,用于将训练集输入至复合信息分层卷积神经网络模型,输出各样本对应的预测值,根据输出的预测值与目标值通过损失函数进行误差分析,更改模型各个权重值,直到达到最大迭代次数,输出基于复合信息分层卷积神经网络模型;
[0069]
基于复合信息分层卷积神经网络模型,分别与神经网络模型训练模块的输出端和数据划分模块的测试集输出端口连接,用于预测待评估钻机健康状况;
[0070]
钻机健康状况预测值输出模块,与基于复合信息分层卷积神经网络模型连接,用于输出待评估钻机健康状况的预测值。
[0071]
进一步的,二维矩阵构建模块中,相邻两个样本以一定的重合率首尾重合,该重合率可以选择30%;所得到的第一数据集的两个二维矩阵分别是钻车电流对应的一个二维矩
阵,泵车电流对应的另一个二维矩阵。
[0072]
进一步的,数据划分模块中训练集和测试集的划分比例可为7:3。
[0073]
在一个具体实施例中,通过提取多传感器信息的特征,采取自适应提取特征的方法,构建了一种多信息融合的复合信息样本,依据厚度分层,以分层独立卷积神经网络的深度学习,建立用于钻机健康评估的复合信息分层卷积神经网络模型,对钻机的运行状态进行准确分类与健康状态实现有效评估。
[0074]
采集钻机在不同工况和不同健康状态下的钻车电流、泵车电流信号,各截取两个电流信号的4096个数据点作为一个时域样本,相邻两个样本的首尾重合率为30%,将每种时域信号样本分别重新塑形构建二维矩阵,其尺寸为64
×
64,一种时域信号样本为一个二维矩阵;在此基础上将钻机的状态信号即低频阈值信号包括液压系统的钻车主泵压力、钻车主泵流量、钻车主泵温度、钻车辅助泵压力、钻车辅助泵流量、钻车辅助泵温度、钻车夹持器前压力、钻车夹持器后压力、钻车旋转马达压力1、钻车旋转马达压力2、钻车推进油缸压力1、钻车推进油缸压力2、钻车制动闸压力、钻车行走马达压力、钻车支撑油缸压力、泵车液压泵压力、泵车液压泵流量、泵车液压泵温度、泵车水泵压力、泵车水泵流量、泵车水泵温度、泵车水泵马达压力;电控系统的钻车行走压力、钻车油箱油位、钻车油箱温度、泵车行走压力、泵车油箱油位、泵车油箱温度、系统电压、系统瓦斯;孔内系统的煤粉电阻率、土壤电阻率;导向系统的倾角、方位角、工具面向角、水压(mpa)、水流流速(升/分钟)共37个,将37个低频阈值信号进行110倍复制并补零构成一个与时域信号同尺寸的二维矩阵,其尺寸为64
×
64;所有的二维矩阵排列成一个具有三层的三维矩阵,即具有复合信息的三维矩阵样本;由于钻机的运行状态共分为23种,即钻机正常、液压系统钻车主泵压力异常、液压系统钻车主泵流量异常、液压系统钻车主泵温度超限、液压系统钻车辅助泵压力异常、液压系统钻车辅助泵流量异常、液压系统钻车辅助泵温度超限、液压系统钻车夹持器压力异常、液压系统钻车旋转马达压力异常、液压系统钻车推进油缸压力异常、液压系统泵车液压泵异常、液压系统泵车水泵异常、电控系统钻车行走压力异常、电控系统钻车油箱油位异常、电控系统钻车油箱温度超限、电控系统泵车电流过载、电控系统泵车行走压力异常、电控系统泵车油箱油位偏低、电控系统泵车油箱温度超限、电控系统电压异常、电控系统瓦斯超限、孔内形状异常、导向系统工作异常,取不同工况和不同健康状态下的每种样本100个,因此所有样本形成一个样本集x,表示为:x∈r
64
×
64
×3×
2300
,即x为64
×
64
×3×
2300的4维样本集;即样本集中的样本个数为2300,每个样本为一个3维矩阵,行为64,列为64,厚度为3;
[0075]
对于钻机的每一种状态分别定义一个标签,具体的对应如表1,每个样本的输出标签为小于等于23的一个整数,相应地样本输出矩阵为一个包括1-23的2300
×
1的样本输出标签矩阵;
[0076]
表1钻机运行状态与样本输出标签对照表
[0077]
[0078][0079]
将数据集及对应的样本输出标签矩阵构成样本对,将样本对打乱顺序,并按照7:3的比例分成训练集和测试集,即训练集数量为1610个,测试集数量690个;
[0080]
构建复合信息分层卷积神经网络,由于样本集的厚度为3,一层即作为一个独立通道,因此网络结构是由3个独立的卷积通道组成,每个通道所使用的参数保持一致,每个通道的特征提取独立并行,互不干扰。网络的每一组包含输入层、4个卷积层,4个池化层,3组通道共用的全连接层,一个softmax输出层;输出层包括23个神经元,组成23种
‘
one hot’编码组合对应于钻机的23种运行状态标签,在卷积层采用relu函数作为非线性激活函数,卷积核采用多个不同尺寸的小卷积核级联,池化采用最大池化方式,复合信息分层卷积神经网络每一通道参数如表2所示;
[0081]
表2每一通道卷积神经网络参数
[0082][0083]
将经过预处理后形成的训练样本矩阵与对应的训练样本输出标签矩阵输入到复合信息分层卷积神经网络中进行训练,其中训练样本数为1610,采用小批量样本训练,批量数
‘
minibatchsize’为161,使用
‘
adam’算法,最大迭代次数
‘
maxepochs’设置50,以交叉熵误差为损失函数,这里n为161,k为23,y
nk
为第n个样本第k个输出的目标值,为第n个样本第k个输出的预测值,初始学习率为0.001,通过前向传播和反向传播算法,逐次迭代,不断实现网络各参数的更新,直到达到最大迭代次数;
[0084]
对于训练好的网络,将690个测试样本对输入训练好的网络并对其进行测试,对于预测输出标签矩阵与目标输出标签矩阵进行比较,获得复合信息分层卷积神经网络对钻车运行状态分类的准确率。
[0085]
对所公开的实施例的上述说明,按照递进的方式进行,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1