基于过滤规则多级组合优化的工业数据流清洗模型和方法
1.本发明涉及一种数据流清洗模型、方法、存储介质和电子设备,能够实现对脏数据流的自学习、自匹配式的检测和修复,从而提高数据的准确性和可信性。
背景技术:
2.先进传感技术、物联技术、人工智能技术在驱动工业领域向“多维度、透明化、泛在感知”全新模式转变的同时,对智能决策所输入数据的质量与效率提出了更高的需求。但随机外部扰动等问题常导致所采集的数据存在缺失、噪声、重复等质量问题,大量研究表明数据质量异常将严重影响决策与分析的可靠性及正确性。因此数据清洗已成为数据仓库领域、数据挖掘领域以及数据质量管理领域一项关键研究内容。
3.近年来,在数据清洗方面的研究主要有:
4.江苏满运软件科技有限公司公开的发明专利《数据清洗方法、系统、存储介质及电子设备》(201811627786.4),通过选择数据源的目标源表,确定数据来源并进行数据清洗,降低数据同步的出错率。
5.武汉理工光科股份有限公司公开的发明专利《一种多级平台间数据清洗与同步方法及系统》(202010784073.x),通过多级平台对数据进行多层次性的清洗,确保数据的可靠性和有效性。
6.蔚来汽车有限公司公开的发明专利《脏数据识别方法及装置、数据清洗方法及装置、控制器》(201810737680.3),提出了一种脏数据识别和清理方法,首先提取领域规则库,然后通过多重判别规则对脏数据进行识别和清洗。
7.大连海事大学公开的发明专利《一种面向海洋数据流的数据清洗方法和系统》(201910432271.7),对实时数据流进行有限的一体式异常点检测、异常点修复和缺失值填补。
8.东北电力大学公开的发明专利《一种基于关联规则的电网设备数据流清洗方法》(201910475890.4),基于关联规则对电网设备数据流进行清洗,将多种小波基函数的神经网络应用到数据清洗中,完成组合预测。
9.上述研究和发明创造在数据流清洗的自动化与实时性等方面已发挥一定的推动作用,但仍存在以下问题:
10.1)数据流清洗过程中仅针对特定类型的数据错误进行检测与修复,无法以自匹配方式有效应对数据种类与数据错误类型多样的应用场景;
11.2)数据清洗过程中无法实现基于实时数据的清洗算法自学习与自适应。
技术实现要素:
12.为解决数据流清洗算法适用的数据类型单一以及难以动态优化以适应外部环境变化的技术问题,本发明提出了一种基于过滤规则多级组合优化的数据流清洗模型、方法、存储介质和电子设备,目的是通过过滤规则与数据特征间的自匹配,实现面向多数据种类
与多数据错误类型的数据清洗,提高数据清洗算法的自学习与自适应能力。
13.本发明的技术方案是:
14.基于过滤规则多级组合优化的数据流清洗模型,其特殊之处在于:所述数据流清洗模型是按照下述方法建立的:
15.步骤1:数据流初步检测;
16.对输入的初始数据流进行初步检测,包括数据超出阈值、重复、缺失、不一致检测,并使用na替换检测出的异常数据;
17.步骤2:训练数据集构造;
18.选取异常最少的一段原始数据d,并向原始数据d中加入不同程度的异常数据进行脏化处理,以模拟数据清洗方法应用阶段将遇到的各种数据异常问题,得到脏数据集即为训练数据集;
19.步骤3:数据特征提取;
20.从集中趋势、离散程度、分布形态和其他特征四方面,对输入的训练数据进行数据特征提取;所述其他特征包括数据相关性、数据自相关性、数据量和缺失比例;
21.步骤4:数据过滤规则库建立;
22.根据所采集数据可能出现的各种质量问题及智能决策对输入数据的质量需求,选取多种异常检测算法和异常修复算法进行自由组合、逐一匹配集成,形成面向异常数据的异常检测算法-异常修复算法的多种数据过滤规则,将其放入数据过滤规则库中;
23.步骤5:数据特征-规则关联链构建;
24.使用数据过滤规则库中的各条数据过滤规则,依次对步骤2得到的训练数据集r中的数据进行清洗,并将清洗后数据与原始数据d的相对误差作为评价指标,选取评价最高的数据过滤规则并将其写入数据特征-规则关联链;
25.步骤6:规则匹配模型构造;
26.针对构建的数据特征-规则关联链,进一步学习数据特征和规则之间的匹配关系,构建规则匹配模型,该规则匹配模型即为所述数据流清洗模型。
27.进一步地,还包括步骤7:利用所述数据清洗模型对实际输入数据进行清洗后的数据进行质量评估,若评估结果超出所设阈值,则重复步骤6以更新所述数据流清洗模型。
28.进一步地,所述步骤4中:
29.异常检测算法包括3倍标准差法、箱型法和基于密度的空间聚类算法;
30.异常修复算法包括就近填补法、基于平均值的填补法、基于相关性的填补法和加权移动平均法。
31.进一步地,所述步骤5具体为:
32.步骤5.1:构建数据特征-规则关联链,将其表示为:
33.ruch=《num,fea,g》
34.式中,num为样本序号;fea为步骤3提取的数据特征集合;g为类别标签,代表对应特征集合fea的最合适数据过滤规则;
35.步骤5.2:分别使用各数据过滤规则中的算法对所述训练数据集进行处理,获得清洗后数据矩阵rk,并计算rk与原始数据d的相对误差将其表示为:
[0036][0037][0038]
式中,当1≤num≤m时,num=num,当m《num≤mp,num=num%m;m为采集所述初始数据流的传感器数目;
[0039]
步骤5.3:比较相对误差的大小,令g等于获取最小相对误差的数据过滤规则类别标签,从而使数据特征-规则关联链ruch=《num,fea,g》中每一数据特征fea对应的数据过滤规则为最优,将其表示为:
[0040][0041]
式中,s为数据过滤规则库中的数据过滤规则的数目。
[0042]
进一步地,所述步骤6具体为:
[0043]
步骤6.1:针对构建的数据特征-规则关联链ruch=《num,fea,g》中的fea进行主成分分分析,获取解释能力更充分的低维数据pca与特征向量矩阵p,将其表示为:
[0044]
pca={pca1,pca2,pca3,
…
,pcam}
[0045]
p=[p1,p2,p3,
…
,pk]k<<m
[0046]
式中,pi=[q1,q2,q3,
…
,qn]
t
,表示特征向量;
[0047]
步骤6.2:使用pca替换数据特征-规则关联链ruch中的fea,获得新的数据特征-规则关联链ruch
′
=《num,pca,g》;
[0048]
步骤6.3:通过随机森林算法对ruch
′
=《num,pca,g》进行学习,获取规则匹配模型rf:
[0049]
rf=rf(pca
test
,g)。
[0050]
本发明同时还提供了一种基于过滤规则多级组合优化的数据流清洗方法,其特殊之处在于:
[0051]
对实际输入数据先进行归一化再进行降维处理后,将处理结果输入权利要求1-5任一项所述的数据流清洗模型中,为其匹配最优的数据过滤规则对其进行数据清洗。
[0052]
进一步地,对实际输入数据进行处理的方法具体为:
[0053]
首先,对实际输入数据test={t1,t2,t3,
…
,tm}采用所述步骤1的方法进行初步异常检测;
[0054]
然后,对实际输入数据test={t1,t2,t3,
…
,tm}进行主成分分析,得到转换结果pca
test
:
[0055]
pca
test
=test*p。
[0056]
本发明还提供了一种存储介质,其特殊之处在于,所述存储介质上存储有计算机程序,所述计算机程序被所述处理器运行时执行如权利要求6或7所述的数据流清洗方法。
[0057]
本发明还提供了一种电子设备,其特殊之处在于,所述电子设备包括:
[0058]
处理器;
[0059]
存储介质,其上存储有计算机程序,所述计算机程序被所述处理器运行时执行如权利要求6或7所述的数据流清洗方法。
[0060]
与现有技术相比,本发明的有益效果:
[0061]
本发明将数据检测、数据修复、过滤规则配置、过滤规则优化融为一体,能够为数据驱动的规则匹配模型提供可信任的数据输入;将主成分分析与随机森林算法引入规则匹配模型的构建,能够在依据输入数据特征自匹配合适数据过滤规则的同时,通过获取解释能力更强的低维数据提高自匹配精度;所设计的过滤规则库具有可重构与可拓展特点并支持对规则的复杂逻辑描述,在对清洗后数据引入质量评估与反馈后,基于过滤规则多级组合优化(包括分层级数据检测清洗、多规则匹配)的数据清洗方法能够以自学习与自适应的方式应对多场景下多源数据的处理,突破传统面向单一应用场景的数据清洗算法的局限性。
附图说明
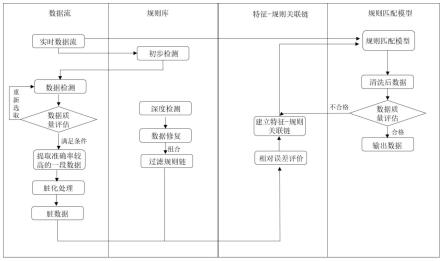
[0062]
图1是本发明方法的总体框架图。
[0063]
图2是本发明方法的总体流程图。
[0064]
图3是本发明的泳道图。
具体实施方式
[0065]
下面结合实施例和附图对本发明作进一步详细说明。
[0066]
如图1-3所示,本发明所提供的基于过滤规则多级组合优化的数据流清洗方法,目的是通过过滤规则与数据特征间的自匹配,实现面向多数据种类与多数据错误类型的数据流清洗,提高数据清洗算法的自学习与自适应能力。
[0067]
具体实施步骤如下:
[0068]
步骤1:数据流初步检测;
[0069]
对输入的初始数据流进行初步检测,包括数据超出阈值、重复、缺失、不一致四项检测,并使用na填补(替换)检测出的异常数据。
[0070]
步骤2:训练数据集构造;
[0071]
应用箱型法选取异常最少的一段原始数据d,并向原始数据d中加入不同程度的异常数据进行脏化处理,以模拟数据清洗方法应用阶段将遇到的各种数据异常问题,得到脏数据集即为训练数据集r;
[0072]
具体包括以下步骤:
[0073]
步骤2.1:在传感器j所采集的数据流中应用箱型法选取数据质量较高的一段数据dj,将其表示为:
[0074]dj
={d
j1
,d
j2
,
…
,d
jt
,
…
,d
jn
}
[0075]
式中,d
jt
表示传感器j在时刻t采集的数据,n表示数据的总量;
[0076]
步骤2.2:假设已部署m个相关或独立的传感器,则重复步骤2.1,直至构建n
×
m维原始数据矩阵d,将其表示为:
[0077][0078]
步骤2.3:对选定的原始数据矩阵d进行p次脏化处理,即在原始数据矩阵d中加入不同比例的噪声、缺失,从而得到n
×
mp维训练数据矩阵r,将其表示为:
[0079][0080]
式中,r
p
(d
mn
)表示第p次对数据d
mn
脏化处理后得到的数据。
[0081]
步骤2.4:为便于后续构建数据特征-规则关联链,令num代表n
×
mp维训练数据矩阵中列向量r的序号,即num∈{1,2,
…
,mp};
[0082]
步骤3:数据特征提取;
[0083]
针对输入数据,从集中趋势、离散程度、分布形态和其他特征四方面进行数据特征提取。其中,对训练数据r进行特征提取,将训练数据的特征用于在数据清洗方法训练阶段构建由数据特征与数据过滤规则组成的规则匹配模型。在实际的应用环境下,对输入的数据进行特征提取,将实际数据特征用作数据清洗方法应用阶段的输入参数,通过规则匹配模型为具有该特征的数据匹配最优数据过滤规则;
[0084]
具体包括以下步骤:
[0085]
步骤3.1:利用集中趋势衡量数据在总体水平向其中心聚集靠拢的程度,其测度指标主要包括算术平均数、调和平均值与加权平均值以衡量数据的集中趋势,将其表示为:
[0086]
1)算术平均值
[0087][0088]
2)加权平均值
[0089][0090]
3)调和平均值
[0091][0092]
式中,x
t
为某一传感器在t时刻采集的数据,n为时段t内该传感器的采样次数,w
t
为x
t
在时段t内重复出现的次数;
[0093]
步骤3.2:利用离散程度刻画数据总体分布的变异状况和取值差异,其测度指标主要包括极差、平均差、方差、标准差与变异系数,将其表示为:
[0094]
1)极差
[0095]
fea4=max(x
t
)-min(x
t
)
[0096]
2)平均差
[0097][0098]
3)方差
[0099][0100]
4)标准差
[0101][0102]
5)变异系数
[0103][0104]
式中,
[0105]
步骤3.3:利用分布形态反映数据总体分布的形状,如分布是否对称、尖鞘程度、峰凸程度,其测度指标主要包括偏态系数与峰态系数,将其表示为:
[0106]
1)偏态系数
[0107][0108]
2)峰态系数
[0109][0110]
步骤3.4:其他特征为本发明添加的描述数据的其他测度指标,主要包括数据相关性、数据自相关性、数据量和缺失比例,将其表示为:
[0111]
1)数据相关性
[0112][0113]
式中,x
t
为某一传感器在t时刻采集的数据,y
t
为另一传感器在t时刻采集的数据;为变量y
t
的平均值。
[0114]
2)数据自相关性
[0115]
fea
12
=cor(x
t
,x
t-i
),i=1,2,3
…
t
[0116]
3)数据量
[0117]
fea
13
=n
[0118]
4)缺失比例
[0119]
[0120]
式中,fea
13
表示一段时间内数据流包含的数据个数,error为数据集中检测到的存在的异常点的数量;
[0121]
步骤3.5:构建任一时段内数据的特征集合fea,将其表示为:fea={fea1,fea2,fea3,
…
,fea
14
},特征集合fea即为提取的数据特征;
[0122]
步骤4:数据过滤规则库建立;
[0123]
根据所采集数据可能出现的各种质量问题及智能决策对输入数据的质量需求(如数据准确性、数据完整性、数据可靠性),选取多种合适的通用或特定领域的异常检测算法与异常修复算法,进而将用于数据流清洗的异常检测算法与异常修复算法进行逐一匹配集成,形成面向异常数据的异常检测算法-异常修复算法的数据过滤规则,多条数据过滤规则共同组成数据过滤规则库ru;
[0124]
具体包括以下步骤:
[0125]
步骤4.1:本发明选用的异常检测算法主要为3倍标准差法、箱型法和基于密度的空间聚类算法(dbscan);3种算法的具体设定为:
[0126]
1)3倍标准差法:将超过三倍标准差的数据认定为异常值。
[0127]
2)箱型法:将数据进行分段处理,计算每一段的上限和下限,将超出上下限的数据划分为异常值。
[0128]
3)dbscan:以每个数据点为中心,设定邻域半径和临近点数量的阈值,如果样本点的邻域内临近点的数量少于阈值,则设定为异常点。
[0129]
步骤4.2:本发明选用的数据异常修复算法主要包括就近填补法、基于平均值的填补法、基于相关性的填补法、加权移动平均法;4种算法的具体设定为:
[0130]
1)就近填补法:对于异常数据采用最近的正常数据进行填补;
[0131]
2)基于平均值的填补法:对异常值采用数据整体的平均值进行填充;
[0132]
3)基于相关性的填补法,主要针对具有一定相关性的数据之间的填充;
[0133]
4)加权移动平均法,对缺失值采用前后正常数据的加权平均值进行填充;
[0134]
步骤4.3:将选定的3种异常检测算法与4种异常修复算法逐一匹配,形成深度检测算法-异常修复算法过滤规则ruk,k∈{1,2,
…
,12}。
[0135]
步骤4.4:步骤4.3得到的12条数据过滤规则组成数据过滤规则库ru,将其表示为:
[0136]
ru={ru1,ru2,ru3,
…
,ru
12
}
[0137]
步骤5:数据特征-规则关联链构建;
[0138]
使用规则库ru中的12条数据过滤规则,依次对n
×
mp维训练数据矩阵r中的数据进行清洗,在此基础上将清洗后数据与原始数据d的相对误差作为评价指标,选取评价最高的数据过滤规则并将其写入数据特征-规则关联链;
[0139]
具体包括以下步骤:
[0140]
步骤5.1:构建数据特征-规则关联链,将其表示为:
[0141]
ruch=《num,fea,g》
[0142]
式中,num为样本序号,g为类别标签,代表对应特征集合fea的最合适数据过滤规则;
[0143]
步骤5.2:分别使用12条数据过滤规则中的算法对n
×
mp维训练数据矩阵r进行处理,获得n
×
mp维清洗后数据矩阵rk,并计算rk与原始数据d的相对误差将其表示为:
[0144][0145][0146]
式中,当1≤num≤m时,num=num,当m《num≤mp,num=num%m。
[0147]
步骤5.3:比较相对误差的大小,令g等于获取最小相对误差的数据过滤规则类别标签,从而使数据特征-规则关联链ruch=《num,fea,g》中每一数据特征fea对应的数据过滤规则为最优,将其表示为:
[0148][0149]
步骤6:规则匹配模型构造;
[0150]
针对构建的数据特征-规则关联链,依次应用主成分分析与随机森林算法进一步学习数据特征和规则之间的匹配关系,从而构建规则匹配模型rf;
[0151]
具体步骤如下:
[0152]
步骤6.1:针对构建的数据特征-规则关联链ruch=《num,fea,g》中的fea={fea1,fea2,f3,
…
,fea
14
}进行主成分分分析,获取解释能力更充分的低维数据pca与特征向量矩阵p,将其表示为:
[0153]
pca={pca1,pca2,pca3,
…
,pcam}
[0154]
p=[p1,p2,p3,
…
,pk],k<<m
[0155]
式中,pi=[q1,q2,q3,
…
,qn]
t
,表示特征向量;
[0156]
步骤6.2:使用pca替换数据特征-规则关联链ruch中的fea,获得新的数据特征-规则关联链ruch
′
=《num,pca,g》;
[0157]
步骤6.3:通过随机森林算法对ruch
′
=《num,pca,g》进行学习,获取规则匹配模型rf,将其表示为:
[0158]
rf=rf(pca
test
,g)
[0159]
步骤7:数据清洗
[0160]
在数据清洗方法应用阶段,应用主成分分析对实际输入数据先进行归一化然后进行降维处理,以增强数据的差异性。然后将处理结果输入步骤6建立的规则匹配模型rf为其匹配最优的数据过滤规则对其进行数据清洗;
[0161]
具体包括以下步骤:
[0162]
步骤7.1:对实际输入数据test={t1,t2,t3,
…
,tm}执行步骤1,以完成初步异常检测;
[0163]
步骤7.2:对实际输入数据test={t1,t2,t3,
…
,tm}进行主成分分析,以获取转换结果pca
test
,将其表示为:
[0164]
pca
test
=test*p
[0165]
步骤7.3:在此基础上利用步骤6.3最终获得的规则匹配模型rf对数据所对应的规则过滤算法进行预测,为输入数据选择合适的数据过滤规则,从而完成数据清洗;
[0166]
步骤8:规则匹配模型更新;
[0167]
通过箱型法对清洗后数据进行质量评估,若评估结果超出所设阈值c(阈值根据对数据质量的要求设定),则重复步骤6以更新规则匹配模型;
[0168]
具体方法为:
[0169]
在步骤7.3执行后,利用箱型法对清洗后数据进行质量评估,若计算得到的异常值超过所设阈值c(如数据量的5%),则重复步骤6对规则匹配模型重新训练。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1