一种抵抗JPEG压缩的对抗样本的生成方法
一种抵抗jpeg压缩的对抗样本的生成方法
技术领域
1.本发明涉及一种对抗样本生成技术,尤其是涉及一种抵抗jpeg(joint photographicexperts group,联合图像专家小组)压缩的对抗样本的生成方法,其生成的对抗样本可以更好地抵抗jpeg压缩。
背景技术:
2.随着社交网络等新媒体技术的飞速发展,大量图片在互联网上传播。若这些图片在信道上以原始图片的方式进行传输时,需要占用大量的传输空间和存储空间,增加相关内容服务提供商的存储成本。因此,为了解决这个问题,传输前需要对原始图片进行压缩,以减少图片传输和存储所需要的成本。传统的压缩方法可分为有损压缩和无损压缩。无损压缩是指数据经过压缩后,信息不被破坏,压缩过程完全可逆,即可以将数据恢复原样。有损压缩是指将次要的数据舍弃,牺牲一些质量来减少数据量、提高压缩比。无损压缩常用于对图像质量要求较高的应用场景;有损压缩则更适合用户规模较大的场景,如社交网络。jpeg压缩技术是图像中最常见也是最通用的有损压缩技术,其特点是可以根据不同的压缩因子,对图像进行不同强度的压缩。jpeg压缩的一般流程如图1所示,编码过程首先将rgb格式的图像转换为ycrcb格式,然后进行分块和离散余弦变换(discrete cosine transform,dct),再对dct系数进行量化,最后将量化后的系数进行熵编码;解码过程首先进行熵解码得到dct系数,然后将解码后的dct系数进行逆dct变换,转换到像素空间,最后将得到的像素块组成图像,并由ycrcb格式转换回rgb格式,得到jpeg压缩后的图像。在jpeg压缩的流程中,量化操作是有损的,同时也是不可微的,对图像进行jpeg压缩后,由于量化的影响,因此每个8
×
8的像素块边界均会出现失真,严重影响了图像的视觉质量。
3.然而,评价一幅图像是否“好看”有很多种方法,传统的方法只能通过指标去静态的衡量图像的好坏,和人类的视觉无法联系在一起,因此,以人作为观测者,对图像进行主观评价,力求能够真实地反应人的视觉感知。基于深度学习的图像质量评价器相比于传统的方法能更直观地反应图像的视觉质量。以使用广泛的图像质量评价器(nima)为例,它在分类网络的基础上进行改造。将vgg16的最后一层用含有10个神经元的全连接层代替,其他部分的结构保持不变,然后使用数据对nima进行端到端的训练。由于训练集中的图片的长宽比例各不相同,因此在输入到nima之前会对训练集中的图片进行预处理,将图片变为256
×
256大小,随后将图片随机裁剪为224
×
224大小,最后每一张图片输入nima后会得到10个概率值,这10个概率值代表该图片落在1~10分中每个分数段的概率值,然后对这10个概率值进行加权平均得到该图片在nima中的图像质量得分。通过对nima进行端到端的训练,使其更加贴近人眼观察图像的好坏。
4.随着深度学习技术在各个领域的优异表现,深度学习模型的安全性也存在隐患。对抗样本是指在数据集中通过故意添加细微的干扰所形成的输入样本,其会导致深度学习模型以高置信度给出一个错误的输出,从而欺骗深度学习模型。对抗攻击可以分为白盒攻击和黑盒攻击,白盒攻击是指知道所攻击模型的网络结构以及参数等模型的具体信息,可
以通过梯度对模型进行攻击;黑盒攻击是指不知道所攻击模型的具体结构和参数等信息,攻击者只能通过对模型进行输入和输出的方式进行查询,然后建立替代模型,实现对模型的攻击。现有的白盒对抗样本生成方法一般分为两种:基于加性噪声的对抗样本生成方法和基于优化的对抗样本生成方法。
5.以最常用的fgsm(fast gradient sign method,快速梯度下降法方法)和pgd(project gradient descent,投影梯度下降法)方法作为示例。fgsm方法在白盒环境下,通过求出模型对输入的导数,然后用符号函数得到其具体的梯度方向,接着乘以一个步长,得到的“扰动”加在原来的输入上就得到了在fgsm攻击下的样本。虽然利用fgsm方法生成对抗样本的速度很快,但是由于fgsm只经过一次迭代,所添加的噪声是比较大的,因此利用fgsm生成的对抗样本有着肉眼可见的噪声,视觉质量较差。pgd方法可以看作是fgsm的翻版——k-fgsm(k表示迭代的次数),大概的思路就是,fgsm是仅仅做一次迭代,走一大步,而pgd是做多次迭代,每次走一小步,每次迭代都会将扰动clip(截剪)到规定范围(即限制到0~1)内。一般来说,pgd的攻击效果比fgsm要好,但是速度相对于fgsm较慢。利用pgd方法生成的对抗样本相比利用fgsm方法生成的对抗样本噪声更小,但是噪声依旧是肉眼可见的,视觉质量有待提高。
技术实现要素:
6.本发明所要解决的技术问题是提供一种抵抗jpeg压缩的对抗样本的生成方法,其生成的对抗样本在公共信道上进行传播时能够更好地抵抗jpeg压缩,进而保证了经过传播后的对抗样本依然具有很好的攻击性,且视觉质量好。
7.本发明解决上述技术问题所采用的技术方案为:一种抵抗jpeg压缩的对抗样本的生成方法,其特征在于包括训练阶段和测试阶段;
8.所述的训练阶段的具体过程为:
9.步骤1_1:选取q张原始rgb图像;然后将每张原始rgb图像缩放成256
×
256大小的图像;再对每张256
×
256大小的图像在其中心区域内进行随机裁剪,裁剪成224
×
224大小的图像,定义为裁剪图像;接着将每张裁剪图像输入到图像质量评价器中,图像质量评价器输出每张裁剪图像的质量得分,作为对应的原始rgb图像的真实质量得分;之后将所有原始rgb图像及每张原始rgb图像的真实质量得分构成训练集;再将训练集中的每张原始rgb图像对应的裁剪图像分割成625个相互重叠的32
×
32大小的图像块;其中,q≥1,图像块与图像块之间重叠8个像素点;
10.步骤1_2:构建空间形变网络:该空间形变网络包括定位网络和取样模块;
11.定位网络为一个卷积神经网络,其由依次连接的第一卷积块、第二卷积块、第三卷积块、第四卷积块、全连接层组成,第一卷积块由依次连接的第一卷积层、第一批归一化层、第一leakyrelu激活函数组成,第二卷积块由依次连接的第二卷积层、第二批归一化层、第二leakyrelu激活函数组成,第三卷积块由依次连接的第三卷积层、第三批归一化层、第三leakyrelu激活函数、平均池化层组成,第四卷积块由依次连接的第四卷积层、第四批归一化层、第四leakyrelu激活函数组成,第一卷积层的输入端接收一张32
×
32大小的rgb图像的三通道,第一批归一化层的输入端接收第一卷积层的输出端输出的64张15
×
15大小的特征图,第一leakyrelu激活函数的输入端接收第一批归一化层的输出端输出的64张15
×
15
大小的特征图,第二卷积层的输入端接收第一leakyrelu激活函数的输出端输出的64张15
×
15大小的特征图,第二批归一化层的输入端接收第二卷积层的输出端输出的64张7
×
7大小的特征图,第二leakyrelu激活函数的输入端接收第二批归一化层的输出端输出的64张7
×
7大小的特征图,第三卷积层的输入端接收第二leakyrelu激活函数的输出端输出的64张7
×
7大小的特征图,第三批归一化层的输入端接收第三卷积层的输出端输出的64张3
×
3大小的特征图,第三leakyrelu激活函数的输入端接收第三批归一化层的输出端输出的64张3
×
3大小的特征图,平均池化层的输入端接收第三leakyrelu激活函数的输出端输出的64张3
×
3大小的特征图,第四卷积层的输入端接收平均池化层的输出端输出的64张2
×
2大小的特征图,第四批归一化层的输入端接收第四卷积层的输出端输出的6张2
×
2大小的特征图,第四leakyrelu激活函数的输入端接收第四批归一化层的输出端输出的6张2
×
2大小的特征图,全连接层的输入端接收第四leakyrelu激活函数的输出端输出的6张2
×
2大小的特征图,全连接层的输出端输出由6个数值构成的向量;
12.其中,第一卷积层的输入通道数为3、输出通道数为64、卷积核的大小为5、卷积核的步长为2、填充为1,第二卷积层的输入通道数为64、输出通道数为64、卷积核的大小为5、卷积核的步长为2、填充为1,第三卷积层的输入通道数为64、输出通道数为64、卷积核的大小为5、卷积核的步长为2、填充为1,平均池化层的平均池化核的大小为2
×
2,第四卷积层的输入通道数为64、输出通道数为6、卷积核的大小为1、卷积核的步长为1、填充为0,第一leakyrelu激活函数、第二leakyrelu激活函数、第三leakyrelu激活函数、第四leakyrelu激活函数的激活参数均为0.2,全连接层的神经元个数为6;
13.取样模块将全连接层的输出端输出的向量中的前3个数值作为第一行、后3个数值作为第二行构成一个矩阵,记为θ;然后将输入定位网络的32
×
32大小的rgb图像及对应的矩阵θ输入到网格函数中,网格函数输出形变后的32
×
32大小的块,定义为形变块;再计算形变块中的每个像素点的像素值,对于形变块中的任一个像素点,当在输入定位网络的32
×
32大小的rgb图像中找到与该像素点的坐标位置有对应关系的坐标位置时,该像素点的像素值等于找到的坐标位置上的像素点的像素值;当在输入定位网络的32
×
32大小的rgb图像中找不到与该像素点的坐标位置有对应关系的坐标位置时,先使用双线性插值法获取该像素点的插值坐标位置,再在输入定位网络的32
×
32大小的rgb图像中找出与该像素点的插值坐标位置有对应关系的坐标位置,该像素点的像素值等于找出的坐标位置上的像素点的像素值;其中,θ的维数为2
×
3;
14.步骤1_3:将训练集中的每张原始rgb图像对应的裁剪图像作为原始样本;然后将每个原始样本中的每个32
×
32大小的图像块作为输入图像,输入到空间形变网络中,空间形变网络输出每个原始样本中的每个32
×
32大小的图像块对应的形变块;
15.步骤1_4:对每个原始样本中的每个32
×
32大小的图像块对应的形变块进行jpeg压缩,得到每个原始样本中的每个32
×
32大小的图像块对应的形变压缩块,在jpeg压缩过程中将形变块从rgb格式转换为ycrcb格式,然后将ycrcb格式的形变块分割成16个互不重叠的8
×
8大小的子块,接着对ycrcb格式的形变块中的每个子块进行dct变换,得到每个子块的dct系数矩阵,再采用一个三阶函数模拟量化操作,对每个子块的dct系数矩阵进行处理,将得到的结果记为x
approx
,x
approx
=round(round(x)+(x-round(x))3);其中,x
approx
的维数为8
×
8,round()表示四舍五入取整函数,x表示子块的dct系数矩阵,x的维数为8
×
8;
16.步骤1_5:从每个原始样本中的每个32
×
32大小的图像块对应的形变压缩块中,提取出以该形变压缩块的中心为中心的8
×
8大小区域作为提取块;然后针对每个原始样本,将提取出的625个提取块按该原始样本分割成的625个32
×
32大小的图像块的顺序组合成新的图像,再将该原始样本的四周每侧12个像素点宽的区域作为边缘外框、将新的图像作为中心区域拼接形成224
×
224大小的对抗样本;再将每个对抗样本输入到图像质量评价器中,图像质量评价器输出每个对抗样本的质量得分;
17.步骤1_6:计算每个原始样本与对应的对抗样本之间的损失函数,将第q个原始样本与对应的对抗样本之间的损失函数记为lossq,其中,1≤q≤q,表示第q个原始样本对应的对抗样本的质量得分,s0表示设定的质量分,s0∈[1,10],xq表示第q个原始样本,表示第q个原始样本对应的对抗样本,α为用于控制与之间的重要程度的权重,0<α<1,表示与s0的均方根误差,表示xq与之间的差异;
[0018]
步骤1_7:重复执行步骤1_3至步骤1_6更新空间形变网络中的参数,直至损失函数收敛,得到空间形变网络训练模型;
[0019]
所述的测试阶段的具体过程为:
[0020]
步骤2_1:对于任意一张测试rgb图像,将测试rgb图像缩放成256
×
256大小的图像;再对256
×
256大小的图像在其中心区域内进行随机裁剪,裁剪成224
×
224大小的图像,定义为测试裁剪图像;接着将测试裁剪图像分割成625个相互重叠的32
×
32大小的图像块;
[0021]
步骤2_2:将测试裁剪图像中的每个32
×
32大小的图像块作为输入图像,输入到训练好的空间形变网络训练模型中,空间形变网络训练模型输出测试裁剪图像中的每个32
×
32大小的图像块对应的形变块;然后按照步骤1_4的过程,以相同的方式对测试裁剪图像中的每个32
×
32大小的图像块对应的形变块进行jpeg压缩,得到测试裁剪图像中的每个32
×
32大小的图像块对应的形变压缩块;
[0022]
步骤2_3:从测试裁剪图像中的每个32
×
32大小的图像块对应的形变压缩块中,提取出以该形变压缩块的中心为中心的8
×
8大小区域作为测试提取块;然后将提取出的625个测试提取块按测试裁剪图像分割成的625个32
×
32大小的图像块的顺序组合成新的图像,再将测试裁剪图像的四周每侧12个像素点宽的区域作为边缘外框、将新的图像作为中心区域拼接形成224
×
224大小的测试对抗样本。
[0023]
所述的步骤1_6中,的获取过程为:将xq和同时输入到vgg16中的第二个卷积层中,获得xq对应的一张特征图和对应的一张特征图;然后计算两张特征图的l2范数距离,作为
[0024]
与现有技术相比,本发明的优点在于:
[0025]
1)本发明方法生成的对抗样本可以显著提高对抗样本在经过jpeg等压缩后的攻击性,同时还能保持更加良好的视觉观感。
[0026]
2)本发明方法构建的空间形变网络的结构非常轻量化,因此利用本发明方法可以
在很短的时间内生成对抗样本,生成对抗样本的速度很快。
[0027]
3)本发明方法对空间形变网络输出的形变块进行jpeg压缩时采用一个三阶函数模拟量化操作,保证了后面的梯度是可以正常回传的,因此可以完整地训练出空间形变网络训练模型。
附图说明
[0028]
图1为jpeg压缩过程的示意图;
[0029]
图2为本发明方法的总体实现框图;
[0030]
图3为本发明方法中构建的空间形变网络的组成结构示意图;
[0031]
图4a为一张原始图像;
[0032]
图4b为利用fgsm算法生成的对抗样本;
[0033]
图4c为利用fgsm算法生成的对抗样本与原始样本的差值;
[0034]
图4d为利用pgd算法生成的对抗样本;
[0035]
图4e为利用pgd算法生成的对抗样本与原始样本的差值;
[0036]
图4f为利用本发明方法生成的对抗样本;
[0037]
图4g为利用本发明方法生成的对抗样本与原始样本的差值。
具体实施方式
[0038]
以下结合附图实施例对本发明作进一步详细描述。
[0039]
本发明提出的一种抵抗jpeg压缩的对抗样本的生成方法,其总体实现框图如图2所示,其包括训练阶段和测试阶段。
[0040]
所述的训练阶段的具体过程为:
[0041]
步骤1_1:选取q张原始rgb图像;然后将每张原始rgb图像缩放成256
×
256大小的图像;再对每张256
×
256大小的图像在其中心区域内进行随机裁剪,裁剪成224
×
224大小的图像,定义为裁剪图像;接着将每张裁剪图像输入到图像质量评价器(neural image assessment,nima)中,图像质量评价器输出每张裁剪图像的质量得分,作为对应的原始rgb图像的真实质量得分;之后将所有原始rgb图像及每张原始rgb图像的真实质量得分构成训练集;再将训练集中的每张原始rgb图像对应的裁剪图像分割成625个相互重叠的32
×
32大小的图像块;其中,q≥1,q张原始rgb图像的大小不一,对每张256
×
256大小的图像在其中心区域内进行随机裁剪即256
×
256大小的图像的边缘部分不裁剪进,图像块与图像块之间重叠8个像素点,即在一行图像块中左边的图像块与右边的图像块之间重叠8个像素点,一列图像块中上边的图像块与下边的图像块之间重叠8个像素点,例如:第1个图像块取的是[0,32]的正方形区域,第2个图像块取的是[8,40]的正方形区域,其中有[8,32]的重叠部分,重叠的目的是为了避免边界伪影的出现。
[0042]
由于所使用的图像质量评价器只接收224
×
224大小的rgb图像,而q张原始rgb图像的大小各不相同,因此需要先对原始rgb图像进行预处理,即先缩放成256
×
256大小的图像,再随机裁剪成224
×
224大小的图像。
[0043]
由于后续生成对抗样本的要求是不可以和原始样本即裁剪图像有着很大的视觉差异,因此采取局部微小形变的方式生成对抗样本,故对原始样本即裁剪图像进行分块,以
此来获得局部微小形变的效果。
[0044]
步骤1_2:构建空间形变网络:如图3所示,该空间形变网络包括定位网络和取样模块;
[0045]
定位网络为一个卷积神经网络,其由依次连接的第一卷积块、第二卷积块、第三卷积块、第四卷积块、全连接层组成,第一卷积块由依次连接的第一卷积层、第一批归一化层、第一leakyrelu激活函数组成,第二卷积块由依次连接的第二卷积层、第二批归一化层、第二leakyrelu激活函数组成,第三卷积块由依次连接的第三卷积层、第三批归一化层、第三leakyrelu激活函数、平均池化层组成,第四卷积块由依次连接的第四卷积层、第四批归一化层、第四leakyrelu激活函数组成,第一卷积层的输入端接收一张32
×
32大小的rgb图像的三通道,第一批归一化层的输入端接收第一卷积层的输出端输出的64张15
×
15大小的特征图,第一leakyrelu激活函数的输入端接收第一批归一化层的输出端输出的64张15
×
15大小的特征图,第二卷积层的输入端接收第一leakyrelu激活函数的输出端输出的64张15
×
15大小的特征图,第二批归一化层的输入端接收第二卷积层的输出端输出的64张7
×
7大小的特征图,第二leakyrelu激活函数的输入端接收第二批归一化层的输出端输出的64张7
×
7大小的特征图,第三卷积层的输入端接收第二leakyrelu激活函数的输出端输出的64张7
×
7大小的特征图,第三批归一化层的输入端接收第三卷积层的输出端输出的64张3
×
3大小的特征图,第三leakyrelu激活函数的输入端接收第三批归一化层的输出端输出的64张3
×
3大小的特征图,平均池化层的输入端接收第三leakyrelu激活函数的输出端输出的64张3
×
3大小的特征图,第四卷积层的输入端接收平均池化层的输出端输出的64张2
×
2大小的特征图,第四批归一化层的输入端接收第四卷积层的输出端输出的6张2
×
2大小的特征图,第四leakyrelu激活函数的输入端接收第四批归一化层的输出端输出的6张2
×
2大小的特征图,全连接层的输入端接收第四leakyrelu激活函数的输出端输出的6张2
×
2大小的特征图,全连接层的输出端输出由6个数值构成的向量。
[0046]
其中,第一卷积层的输入通道数为3、输出通道数为64、卷积核的大小为5、卷积核的步长为2、填充为1,第二卷积层的输入通道数为64、输出通道数为64、卷积核的大小为5、卷积核的步长为2、填充为1,第三卷积层的输入通道数为64、输出通道数为64、卷积核的大小为5、卷积核的步长为2、填充为1,平均池化层的平均池化核的大小为2
×
2,第四卷积层的输入通道数为64、输出通道数为6、卷积核的大小为1、卷积核的步长为1、填充为0,第一leakyrelu激活函数、第二leakyrelu激活函数、第三leakyrelu激活函数、第四leakyrelu激活函数的激活参数均为0.2,全连接层的神经元个数为6,由于在此只是对图像进行2d变换,因此全连接层的输出端输出由6个数值构成的向量,如果对图像进行3d变换,那么全连接层的输出端输出由9个数值构成的向量。
[0047]
通过定位网络,将一张32
×
32大小的rgb图像经过一系列的卷积等操作变成了由6个数值构成的向量。
[0048]
取样模块将全连接层的输出端输出的向量中的前3个数值作为第一行、后3个数值作为第二行构成一个矩阵,记为θ;然后将输入定位网络的32
×
32大小的rgb图像及对应的矩阵θ输入到网格函数(grid generator)中,网格函数输出形变后的32
×
32大小的块,定义为形变块;再计算形变块中的每个像素点的像素值,对于形变块中的任一个像素点,当在输入定位网络的32
×
32大小的rgb图像中找到与该像素点的坐标位置有对应关系的坐标位置
时,该像素点的像素值等于找到的坐标位置上的像素点的像素值;当在输入定位网络的32
×
32大小的rgb图像中找不到与该像素点的坐标位置有对应关系的坐标位置时(即该像素点的坐标位置不是整数时),先使用双线性插值法获取该像素点的插值坐标位置,再在输入定位网络的32
×
32大小的rgb图像中找出与该像素点的插值坐标位置有对应关系的坐标位置,该像素点的像素值等于找出的坐标位置上的像素点的像素值;其中,θ的维数为2
×
3。
[0049]
步骤1_3:将训练集中的每张原始rgb图像对应的裁剪图像作为原始样本;然后将每个原始样本中的每个32
×
32大小的图像块作为输入图像,输入到空间形变网络中,空间形变网络输出每个原始样本中的每个32
×
32大小的图像块对应的形变块。
[0050]
步骤1_4:对每个原始样本中的每个32
×
32大小的图像块对应的形变块进行jpeg压缩,得到每个原始样本中的每个32
×
32大小的图像块对应的形变压缩块,在jpeg压缩过程中将形变块从rgb格式转换为ycrcb格式,然后将ycrcb格式的形变块分割成16个互不重叠的8
×
8大小的子块,接着对ycrcb格式的形变块中的每个子块进行dct变换(discrete cosine transform,离散余弦变换),得到每个子块的dct系数矩阵,再采用一个三阶函数模拟量化操作,对每个子块的dct系数矩阵进行处理,将得到的结果记为x
approx
,x
approx
=round(round(x)+(x-round(x))3),jpeg压缩的后续过程不变;其中,x
approx
的维数为8
×
8,round()表示四舍五入取整函数,x表示子块的dct系数矩阵,x的维数为8
×
8。
[0051]
由于jpeg压缩过程中的量化操作是不可微分的,而本发明需要最后的梯度回传来调节空间形变网络的参数,因此采用一个三阶函数模拟量化操作,从而使整个jpeg压缩过程由不可微分变成可以微分。
[0052]
步骤1_5:从每个原始样本中的每个32
×
32大小的图像块对应的形变压缩块中,提取出以该形变压缩块的中心为中心的8
×
8大小区域作为提取块;然后针对每个原始样本,将提取出的625个提取块按该原始样本分割成的625个32
×
32大小的图像块的顺序组合成新的图像,再将该原始样本的四周每侧12个像素点宽的区域作为边缘外框、将新的图像作为中心区域拼接形成224
×
224大小的对抗样本;再将每个对抗样本输入到图像质量评价器中,图像质量评价器输出每个对抗样本的质量得分。
[0053]
由于jpeg压缩时将图像划分成互不重叠的8
×
8大小的子块后会再进行dct变换,因此从形变压缩块中提取出中心的8
×
8大小区域作为提取块,这有利于抵抗jpeg的压缩过程。
[0054]
获得的对抗样本不仅可以攻击图像质量评价器,而且相比其他生成方法生成的对抗样本拥有更好的视觉质量。
[0055]
步骤1_6:计算每个原始样本与对应的对抗样本之间的损失函数,将第q个原始样本与对应的对抗样本之间的损失函数记为lossq,其中,1≤q≤q,表示第q个原始样本对应的对抗样本的质量得分,s0表示设定的质量分,s0∈[1,10],xq表示第q个原始样本,表示第q个原始样本对应的对抗样本,α为用于控制与之间的重要程度的权重,0<α<1,在本实施例中取α=0.2,表示与s0的均方根误差,表示xq与之间的差异,可以容忍微小形变。
[0056]
数理统计中均方根误差是指参数估计值与参数真值之差平方的期望值,记为mse,mse是衡量“平均误差”的一种较方便的方法,mse可以评价数据的变化程度,mse的值越小,说明预测模型描述实验数据具有更好的精确度。
[0057]
在本实施例中,步骤1_6中,的获取过程为:将xq和同时输入到vgg16中的第二个卷积层中,获得xq对应的一张特征图和对应的一张特征图;然后计算两张特征图的l2范数距离,作为
[0058]
步骤1_7:重复执行步骤1_3至步骤1_6更新空间形变网络中的参数,直至损失函数收敛,得到空间形变网络训练模型。
[0059]
所述的测试阶段的具体过程为:
[0060]
步骤2_1:对于任意一张测试rgb图像,将测试rgb图像缩放成256
×
256大小的图像;再对256
×
256大小的图像在其中心区域内进行随机裁剪,裁剪成224
×
224大小的图像,定义为测试裁剪图像;接着将测试裁剪图像分割成625个相互重叠的32
×
32大小的图像块。
[0061]
步骤2_2:将测试裁剪图像中的每个32
×
32大小的图像块作为输入图像,输入到训练好的空间形变网络训练模型中,空间形变网络训练模型输出测试裁剪图像中的每个32
×
32大小的图像块对应的形变块;然后按照步骤1_4的过程,以相同的方式对测试裁剪图像中的每个32
×
32大小的图像块对应的形变块进行jpeg压缩,得到测试裁剪图像中的每个32
×
32大小的图像块对应的形变压缩块。
[0062]
步骤2_3:从测试裁剪图像中的每个32
×
32大小的图像块对应的形变压缩块中,提取出以该形变压缩块的中心为中心的8
×
8大小区域作为测试提取块;然后将提取出的625个测试提取块按测试裁剪图像分割成的625个32
×
32大小的图像块的顺序组合成新的图像,再将测试裁剪图像的四周每侧12个像素点宽的区域作为边缘外框、将新的图像作为中心区域拼接形成224
×
224大小的测试对抗样本;再将每个测试对抗样本输入到图像质量评价器中,图像质量评价器输出每个测试对抗样本的质量得分。
[0063]
由于本发明的最终目的是训练一个空间形变网络,使得使用训练好的空间形变网络模型对图像进行处理后,生成图像质量评价器的对抗样本,且要求损失函数可以容忍微小的形变,因此不能用传统的l1或者l2等来测量两张图像之间的差异。
[0064]
为了进一步说明本发明方法的可行性和有效性,对本发明方法进行实验。
[0065]
使用基于python的深度学习库pytorch1.8.0搭建空间形变网络的架构。采用最大的真实图像数据集ava中的图像测试集来分析利用本发明方法生成的对抗样本到底效果如何。
[0066]
实验中采用的对比方法为两种传统的对抗样本生成方法,分别为fgsm(fast gradient sign method,快速梯度下降法)和pgd(project gradient descent,投影梯度下降法)。
[0067]
将真实图像数据集ava中的图像测试集中的每张图像作为测试图像,利用本发明方法、fgsm和pgd分别对每张测试图像进行对抗样本的生成,进而获取对抗样本与测试图像对应的测试裁剪图像之间的差异,以及对抗样本在经过不同量化系数的jpeg压缩后攻击性的下降程度。
[0068]
表1给出了利用本发明方法、fgsm和pgd分别生成的所有对抗样本在经过图像质量
评价器后的质量得分的平均值、经过jpeg压缩(qf=90)后的质量得分的平均值、psnr平均值。这里,qf代表jpeg压缩的量化系数,qf越大表明经过jpeg压缩后得到的图像质量越好,即jpeg压缩过程中丢掉的信息越少,由于现在的社交网络中的jpeg压缩的量化系数大部分都是分布在90附近,因此令qf=90更加接近社交网络的使用场景;psnr即峰值信噪比,是常用的评价图像质量的客观指标,psnr用于评价图像的失真程度。
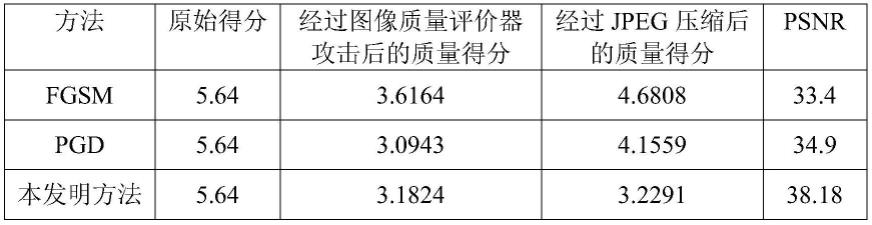
[0069]
表1 利用本发明方法、fgsm和pgd分别生成的所有对抗样本在经过图像质量评价器后的质量得分的平均值、经过jpeg压缩(qf=90)后的质量得分的平均值、psnr平均值
[0070][0071]
表1中,经过图像质量评价器后的质量得分是生成的对抗样本在图像质量评价器中所得到的质量得分,质量得分越接近3,说明攻击成功率越高;经过jpeg压缩后的质量得分是生成的对抗样本在经过qf=90的jpeg压缩后再进入图像质量评价器中所得到的质量得分,这个质量得分越接近经过图像质量评价器后的质量得分,说明对应的生成方法抵抗jpeg压缩的能力越强;
[0072]
从表1中的数据可知,按照本发明方法生成的对抗样本的结果是较好的,在抵抗jpeg压缩方面,利用本发明方法生成的对抗样本失真更小,说明利用本发明方法生成的对抗样本抵抗jpeg压缩的能力是最强的,同时还保持了更好的图像感知质量。
[0073]
图4a给出了一张原始图像,图4b给出了利用fgsm算法生成的对抗样本,图4c给出了利用fgsm算法生成的对抗样本与原始样本的差值,图4d给出了利用pgd算法生成的对抗样本,图4e给出了利用pgd算法生成的对抗样本与原始样本的差值,图4f给出了利用本发明方法生成的对抗样本,图4g给出了利用本发明方法生成的对抗样本与原始样本的差值。对比图4c、图4e、图4g,可以明显看出,利用本发明方法生成的对抗样本与原始样本的差值明显小于其他两种经典的对抗样本生成方法,这充分说明了利用本发明方法生成的对抗样本对原始图像的改变是最不明显的,即利用本发明方法生成的对抗样本是最接近原始图像的,这就意味着利用本发明方法生成的对抗样本是三种方法中最好的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1