基于情绪嵌入的情绪原因对抽取方法
1.本发明涉及情绪原因分析技术领域,特别是涉及一种基于情绪嵌入的情绪原因对抽取方法。
背景技术:
2.互联网变得越来越普及,人们的生活和互联网的联系越来越紧密,越来越多的人开始通过互联网获取各类资讯以及发表自己的看法与意见。文本数据是互联网上每天源源不断的产生新的数据中,质量最高,数量也最多的一种。另一方面,文本数据也是最符合人们语言习惯的一种数据类型,因成为是人们获取信息和表达情绪最重的一种载体之一。如何对这些海量的文本数据进行分析来获取有用信息有非常重要的研究价值,文本数据的情绪分析是具体分析的一个方向。但是目前的文本情绪分析仅仅关注情绪类别,属于比较浅层的情绪分析任务。而我们有时候更关心到底是什么原因导致了这些情感,由此衍生了更深层次的情绪分析任务:情绪原因对抽取。。
3.情绪原因对抽取任务在许多领域中都有重要的意义,可以广泛应用于医学、社会学、商业分析等领域。现有研究主要处理方式是先分别获取情绪特征表示和原因特征表示,然后将它们进行拼接组合,生成情绪原因对特征表示,最后再对此特征表示进行特征转换。这些研究完全忽略了情绪和原因之间存在因果关系这一事实,未能利用它们相互指示的特性。
技术实现要素:
4.本发明的目的是针对现有技术中存在的技术缺陷,而提供一种基于情绪嵌入的情绪原因对抽取模型,并提供基于情绪嵌入的情绪原因对抽取模型进行情绪原因对抽取的方法。
5.为实现本发明的目的所采用的技术方案是:
6.一种情绪嵌入的情绪原因对抽取方法,包括:
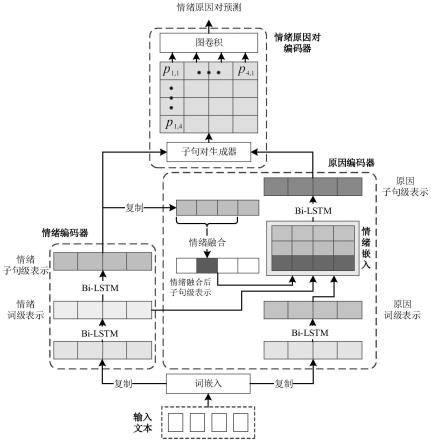
7.基于情绪嵌入的情绪原因对抽取模型实现情绪原因对抽取,该模型的实现步骤如下:
8.s1.词嵌入编码
9.模型的输入通过词嵌入得到文本的时序表示s={s1,s2,
…
,sn};
10.s2.情绪编码
11.通过第一层词级bi-lstm网络得到情绪词级特征表示
[0012][0013]
其中,是词级bi-lstm网络,用于提取情绪词特征然后将r
′e输入到子句级bi-lstm网络中,最终得到情绪子句级特征表示
[0014]
[0015]
其中,是子句级bi-lstm网络,用于提取情绪子句特征
[0016]
s3.原因编码
[0017]
原因编码包括词级bi-lstm网络、情绪融合模块、情感嵌入模块和子句级bi-lstm网络;
[0018]
通过词级bi-lstm网络,得到原因词级特征表示
[0019]
使用一个大小受限的窗口在情感子句表示re上进行滑动,然后将窗口中的所有特征表示进行融合,最后将融合后的特征嵌入到中心子的原因词级特征中;当融合窗口的大小为t时,表示以当前子句为中心,即0位置,需要对{-t,
…
,0,
…
,t}范围内的情绪子句进行情绪特征融合操作;当t=0时,表示不对情感子句做融合操作,换句话说,是情感和原因的子句级特征是独立提取的;
[0020]
在情感嵌入模块中,将原因词级特征表示r
′c、情感词级特征表示r
′e和情感子句级特征表示融合re′
进行拼接,生成带有情感特征嵌入的原因词级特征表示r
ce
;
[0021]rce
=[r
′c,r
′e,re′
]
[0022]
其中[,]表示拼接函数,然后将它们输入到一个子句级bi-lstm网络中,得到原因子句级特征表示;
[0023][0024]
其中,表示子句级别的bi-lstm网络,用于提取原因子句级特征表示
[0025]
s4.情绪原因对编码
[0026]
首先,将情感子句和原因子句两两组会配对,得到情感原因对,记为其中包括情感从句特征re和原因从句特征rc;
[0027][0028]
以作为图的一个节点,所有具有相同情绪特征的节点一起构建一个简单图,称为子句对图;一个n个子句的文档总共需要构建n个子句对图;另外,一般情绪子句与对应的原因子句的距离大部分都比较近,因此只将与中心节点距离小于等于2的子句对用于构建子句对图,即
[0029][0030]
每个图具有三种不同的边,分别是d0边,用于表示节点自迁移的自循环边;d1边,用于连接距离为1的邻接节点,例如对于中心节点则其邻接节点和需要用d1连接起来;d2边,用于连接距离为2的邻接节点,具体用法如d1;
[0031]
通过对情绪子句编码网络和情绪嵌入网络的输出进行特征转换,可以得到转换得到节点的特征表示具体情况是,子句对图中的特征是由与其连接的节点根据不同的边使用不同转换参数变换后集成得到;
[0032][0033]
其中是权重矩阵,分别表示与节点连接的d1边、d2边和d0边的权重;z是归一化因子,它的值等于节点的度,σ表示非线性激活函数,使用的是relu作为激活函数;
[0034]
在对情绪原因对进行分类前加入距离信息,对于候选子句对节点的最终表示p
final
是与d
i,j
的拼接,
[0035][0036]
其中是距离嵌入;
[0037]
s5.情绪原因对预测
[0038]
方法使用全连接神经网络作为分类器,对最终的情绪原因对p
final
进行分类;
[0039][0040]
其中,w
p
是权重矩阵,b
p
是偏置向量;
[0041]
通过最小化预测概率和真实标签之间的差值来得到最终的优化后的模型,文档中所有子句的交叉熵损失函数如下:
[0042][0043]
其中y
ij
和分别是子句对p
ij
的真实预测值。
[0044]
本发明模型与基准之间的差异具有统计学意义。使用准确率、召回率和f1值作为指标,将本发明模型与多个基准进行比较。本发明模型在ecpe任务中准确率和f1值方面均优于基线模型,eem-ecpe模型提高了分别提高了5.56%和1.22%,eem-ecpe-bert模型分别提高了4.45%和1.61%。结果证明,方法可以通过情绪嵌入明显增强情绪原因对抽取的性能。
附图说明
[0045]
图1是本发明的基于情绪嵌入的情绪原因对抽取模型整体结构图。
具体实施方式
[0046]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0047]
如图1所示,本发明的基于情绪嵌入的情绪原因对抽取方法,利用基于情绪嵌入的情绪原因对抽取的模型实现情绪原因对抽取,该模型的实现步骤如下:
[0048]
步骤一:词嵌入编码
[0049]
模型的输入通过词嵌入得到文本的时序表示s={s1,s2,
…
,sn},
[0050]
s2.情绪编码
[0051]
通过第一层词级bi-lstm网络得到情绪词级特征表示
[0052][0053]
其中,是词级bi-lstm网络,用于提取情绪词特征然后将r
′e输入到子句级bi-lstm网络中,最终得到情绪子句级特征表示
[0054][0055]
其中,是子句级bi-lstm网络,用于提取情绪子句特征
[0056]
步骤三:原因编码
[0057]
原因编码由四个组件组成,包括词级bi-lstm网络、情绪融合模块、情感嵌入模块和子句级bi-lstm网络;
[0058]
通过词级bi-lstm网络我们得到了原因词级特征表示
[0059]
使用一个大小受限的窗口在情感子句表示re上进行滑动,然后将窗口中的所有特征表示进行融合,最后将融合后的特征嵌入到中心子的原因词级特征中;当融合窗口的大小为t时,表示以当前子句为中心(即0位置),需要对{-t,
…
,0,
…
,t}范围内的情绪子句进行情绪特征融合操作;特别情况是当t=0时,表示不对情感子句做融合操作,换句话说,就是情感和原因的子句级特征是独立提取的;
[0060]
在情感嵌入模块中,将原因词级特征表示r
′c、情感词级特征表示r
′e和情感子句级特征表示融合re′
进行拼接,生成带有情感特征嵌入的原因词级特征表示r
ce
;
[0061]rce
=[r
′c,r
′e,re′
]
[0062]
其中[,]表示拼接函数,然后将它们输入到一个子句级bi-lstm网络中,得到原因子句级特征表示;
[0063][0064]
其中,表示子句级别的bi-lstm网络,用于提取原因子句级特征表示
[0065]
步骤四:情绪原因对编码
[0066]
首先,我们将情感子句和原因子句两两组会配对,得到情感原因对,记为其中包括情感从句特征re和原因从句特征rc;
[0067][0068]
以作为图的一个节点,所有具有相同情绪特征的节点一起构建一个简单图,称为子句对图;一个n个子句的文档总共需要构建n个子句对图;另外,一般情绪子句与对应的原因子句的距离大部分都比较近,因此只将与中心节点距离小于等于2的子句对用于构建子句对图,即
[0069]
[0070]
每个图具有三种不同的边,分别是d0边,用于表示节点自迁移的自循环边;d1边,用于连接距离为1的邻接节点,例如对于中心节点则其邻接节点和需要用d1连接起来;d2边,用于连接距离为2的邻接节点,具体用法如d1;
[0071]
通过对情绪子句编码网络和情绪嵌入网络的输出进行特征转换,可以得到转换得到节点的特征表示具体情况是,子句对图中的特征是由与其连接的节点根据不同的边使用不同转换参数变换后集成得到;
[0072][0073]
其中是权重矩阵,分别表示与节点连接的d1边、d2边和d0边的权重;z是归一化因子,它的值等于节点的度,σ表示非线性激活函数,使用的是relu作为激活函数;
[0074]
在对情绪原因对进行分类前加入距离信息,对于候选子句对节点的最终表示p
final
是与d
i,j
的拼接,
[0075][0076]
其中是距离嵌入;
[0077]
步骤五:情绪原因对预测
[0078]
使用全连接神经网络作为分类器,对最终的情绪原因对p
final
进行分类;
[0079][0080]
其中,w
p
是权重矩阵,b
p
是偏置向量;
[0081]
通过最小化预测概率和真实标签之间的差值来得到最终的优化后的模型,文档中所有子句的交叉熵损失函数如下:
[0082][0083]
其中y
ij
和分别是子句对p
ij
的真实预测值。
[0084]
实验验证:
[0085]
实验基于夏和丁开源的,通过与其他强大的基线模型进行比较来评估提出的模型的性能,并分析模型的性能。
[0086]
ecpe中文语料库是在新浪新闻情绪原因语料上进行了再次加工而来的,语料共有1945个样本,一个样本可能含有一个或多个情绪,一个情绪可能拥有一个或者多个与之所对应的原因。其中,仅含还有一个情绪的样本有1816个,占比高达93.34%;含有两个及以上情绪的样本有129个,仅占总样本数7.63%。
[0087]
90%的数据被随机选择用于训练,剩余的数据用于测试。实验重复两次10折交叉
验证共计20次实验并报告平均结果。在实验中,使用了词嵌入,它使用word2vec工具包在110万个中文微博语料库上进行了预训练,词嵌入的维度为200。此外,还使用了bert词向量表示中的基础中文模型。word2vec词嵌入的维数是200维,bi-lstm和gcn的隐藏单元都是100。bert词嵌入的维数是768维,bi-lstm和gcn的隐藏单元都是200。包括权重矩阵与偏置向量等其他可学习参数通过均匀分布u(-0.01,0.01)来初始化。在训练时,我们使用adam优化器来更新所有参数。小批量大小和学习率分别设置为32和0.005。为了减少过拟合,将dropou应用于所有特征向量,包括词嵌入和隐藏表示,并将其设置为0.5。每个子句的最多词数和每个文档的最大子句数分别设置为75和100。情感嵌入的方法使用的滑动窗口大小为1,融合方法维均值融合。
[0088][0089]
上表显示了本发明模型eem-ecpe-bert与基准在情绪原因对抽取(ecpe)任务和情绪子句抽取(ee)和原因子句抽取(ce)两个子任务的结果。eem-ecpe模型在ecpe任务中的准确率和f1值取得了最好的结果,优于所有基线模型。具体的,eem-ecpe模型与之前的最佳模型pairgcn相比,在ecpe的准确率和f1值分别提高了5.56%和1.22%。结果表明本发明模型确实能够利用情绪和原因之间的因果关系和相互指示的特性,提高了情绪原因对预测的能力。
[0090][0091]
上表显示了本发明模型eem-ecpe-bert与基准在情绪原因对抽取(ecpe)任务和情绪子句抽取(ee)和原因子句抽取(ce)两个子任务中使用的了bert的结果。eem-ecpe-bert模型在ecpe任务中的准确率和f1值取得了最好的结果,优于所有基线模型。
[0092]
具体的,eem-ecpe-bert模型与之前的最佳模型pairgcn-bert相比,在ecpe的准确率和f1值分别提高了4.45%和1.61%。结果表明本发明模型确实能够利用情绪和原因之间
的因果关系和相互指示的特性,提高了情绪原因对预测的能力。
[0093]
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1