基于改进SPEA2算法的机器多转速车间节能调度方法
基于改进spea2算法的机器多转速车间节能调度方法
技术领域
1.本发明属于智能优化调度技术领域,具体涉及基于改进spea2算法的机器多转速车间节能调度方法。
背景技术:
2.柔性作业车间调度问题主要通过合理的安排各机器上工件的加工顺序,同时为工序选择合适的加工设备以获得期望的生产性能。由于该问题具有很强的理论和应用背景,自提出以来,一直受到国内外学者的广泛关注,而且绝大多数fjsp已被证明具有np难特性。然而,传统fjsp只考虑与时间、质量或成本等相关的性能指标,未关注与环境相关的能耗指标,难以统筹协调企业各方面的优化目标。
技术实现要素:
3.本发明的目的是提供一种基于改进spea2算法的机器多转速车间节能调度方法,来解决现有技术中存在的车间生产过程能耗过高问题。
4.本发明所采用的技术方案是,基于改进spea2算法的机器多转速车间节能调度方法,具体按照以下步骤实施:
5.步骤1、构建柔性作业车间节能调度问题的数学模型;
6.步骤2、采用基于自然数三段式编码,三段式编码分别为工序码、设备码和速度码;任意一个工序码、设备码和速度码形成一个个体,采用随机方式生成规模为n的初始种群p0,创建空的外部档案a0,设置算法参数:算法参数包括当前迭代次数t,最大迭代次数t
max
,变换概率pm,退火速率μ,模拟退火选择机制的初始接受概率pr;
7.步骤3、计算当前种群p
t
和外部档案a
t
并集中所有个体的适应度;
8.步骤4、根据适应度选择前种群p
t
和外部档案a
t
中个体添加到下一代外部档案a
t+1
,如果a
t+1
的规模大于n,使用修剪策略修剪;否则,更新外部档案;
9.步骤5、对外部档案a
t+1
中个体适应度的大小进行排序,计算相邻个体之间的特殊拥挤度距离,取种群拥挤度距离小的20%的个体组成一个新的种群a;对剩余的个体求其平均适应度值,不大于平均适应度值的个体组成种群b,大于平均适应度值的个体组成种群c;从外部档案a
t+1
中模拟退火选择机制选择50%的个体组成种群d;
10.步骤6、在种群a选择部分个体进行反向学习操作形成子代种群a*;在种群b选择部分个体进行螺旋更新位置操作形成子代种群b*;在种群c选择部分个体进行高斯变异或随机扰动操作形成子代种群c*;对种群d中所有个体进行多位交换操作形成新的种群d
*
;种群a、b、c选择个体的机制是模拟退火选择机制;将子代种群a*、b*、c*、d
*
组成新的子代种群p
t+1
;
11.步骤7、如果迭代次数t小于t
max
,令t=t+1,将种群p
t
更新为新的子代种群p
t+1
,返回步骤3;否则将外部档案a
t+1
和新的子代种群p
t+1
中适应度值最小的个体,作为最优妥协解输出。
12.本发明的特点还在于:
13.步骤1具体过程为:
14.定义ji表示工件i的总工序数;表示工件i的完工时间;n表示工件总数;ti表示工件i的交货期;t
ijk
表示工件i的第j道工序在设备k上的加工时间;x
ijk
为0-1变量,如果工件i的第j道工序在设备k上的加工,则x
ijk
=1,否则x
ijk
=0;x
ijkl
(t)为0-1变量,如果机器mk以速度v
l
加工工序o
ij
,则x
ijkl
(t)=1,否则x
ijkl
(t)=0;e
kl
表示机器对应加工状态下的能耗,且e
kl
=4v
l2
,sek表示机器处于待机状态下的能耗,且sek=1,zk(t)为0-1变量,如果在t时刻,机器mk处于待机状态,则zk(t)=1,否则zk(t)=0,e
kl
与p
ijkl
两者的关系,如果工序o
ij
在机器mk上的加工速度增加,则相应加工时间会变小,但与之相反,其对应的能量消耗则会增大,具体如下:
[0015][0016]
所有机器在加工过程中始终保持开机状态,当其上没有工件加工时,对应机器处于待机状态,直到所有工件加工完成,机器才能关闭;
[0017]
构建柔性作业车间节能调度问题的数学模型的目标函数:
[0018][0019][0020][0021][0022]
步骤3具体过程为:
[0023]
步骤3.1、计算个体所支配的解和所有支配该个体的解:
[0024]
给每个个体y(i)设置两个参数ni和si,ni为种群中支配个体y(i)的个体数量,mi为被个体y(i)支配的其他个体的数量,根据柔性作业车间节能调度问题的数学模型目标函数计算个体目标值,当个体y(i)的所有目标值都优于个体y(j)对应的目标值时,定义个体y(i)支配个体y(j),否则个体y(i)不能支配个体y(j);
[0025]
步骤3.2、计算强度值:
[0026]
将个体所支配的解的数量,作为该个体的强度值s(i):
[0027]
s(i)=|{j|xj∈p
t
+a
t
,xi>xj}|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3-1)
[0028]
步骤3.3、计算原始适应度值:
[0029]
在计算出强度值的基础上,每个个体的原始适应度值为所有支配它的解的强度值之和,按下式计算:
[0030][0031]
步骤3.4、计算密度值:
[0032]
引入k阶近邻法密集度参数评估具有相同适应度值的个体:
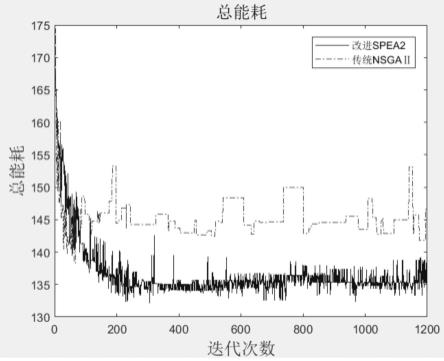
[0033][0034]
其中,σ
ik
为个体i与第k个相近的个体在目标函数空间上的欧几里得距离;d(i)越大表示个体i与第k近的个体距离越近,即越密集;
[0035]
步骤3.5、计算适应度值:
[0036]
将原始的适应度值与密度值的和作为个体i的适应度值f(i):
[0037]
f(i)=r(i)+d(i),i=1,2,...,n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3-4)
[0038]
步骤4具体如下:
[0039]
步骤4.1、将种群p
t
和外部档案a
t
并集中适应度值小于1的个体添加到a
t+1
中,如果a
t+1
的大小等于n,作为下一代档案a
t+1
;
[0040]
步骤4.2、如果a
t+1
的大小小于n,那么将p
t
和a
t
并集中最好的n-|a
t+1
|个受支配的解,即根据它们的适应度值大小排序后,最小的n-|a
t+1
|个个体加入到下一代档案a
t+1
中;
[0041]
步骤4.3、如果a
t+1
的大小大于n,要对a
t+1
实行修剪策略,直到a
t
的大小等于n为止,具体的操作是将满足下列条件的个体i从档案中删除,在外部档案a
t+1
中选取个体k,个体k根据以下公式确定:
[0042][0043]
其中,p表示种群的规模,a
*
表示外部档案a
t+1
规模;
[0044]
计算外部档案a
t+1
中每个个体j与个体k的欧几里得距离,将得到的距离从大至小进行排序,将距离较小的个体删除,使得外部档案a
t+1
中保留n个个体。
[0045]
步骤5中相邻个体之间的特殊拥挤度距离计算公式为:
[0046][0047]
其中,s
t_max
为第t代个体强度值的最大值,s
t_min
为第t代个体强度值的最小值,s(x
t_i+1
)和s(x
t_i-1
)表示第t代个体相邻的两个体的强度值。
[0048]
步骤5中从外部档案a
t+1
中取种群拥挤度距离小的20%的个体组成一个新的种群a;对剩余的个体求其平均适应度值,不大于平均适应度值的个体组成种群b,大于平均适应度值的个体组成种群c。
[0049]
步骤5中从外部档案a
t+1
中模拟退火选择机制选择50%的个体作为种群d具体过程为:
[0050]
从外部档案a
t+1
中随机选择2个个体a和b;
[0051]
计算个体a和b的适应度值fa、fb;
[0052]
判断fa是否大于fb;若不大于,则选择个体a作为父代种群l
t
中的一个个体;否则,则随机生成(0,1]上某个概率值p;
[0053]
判断随机概率值p是否满足式(5-2)和式(5-3)所示条件,若是,则选择个体a作为种群d中的一个个体;若否,则选择个体b作为种群d中的一个个体;
[0054]
随机概率值p的判断式为:
[0055]
p<min(1,exp(-(f
a-fb)/t))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5-2)
[0056]
当前温度t的计算式为:
[0057]
t=μi×
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5-3)
[0058]
初始退火温度t的计算式为:
[0059][0060]
其中,μ为退火速率;i为算法当前迭代次数;f
max
表示外部档案中最大适应度值;f
min
为外部档案中最小适应度值;pr为模拟退火选择机制的初始接受概率。
[0061]
步骤6中对种群a选择个体进行反向学习操作形成子代种群a*具体过程为:
[0062]
从种群a中模拟退火选择机制选择需要进行反向学习操作的个体;
[0063]
对选择的个体上关于工序的编码采用公式(6-1)进行更新,得到个体新的工序编码:
[0064][0065]
其中,λ∈(0,1)的随机数,b表示加工的总工序数,若则取若则xi和分别为当前解和反向解;
[0066]
随机产生工件xi,采用公式(6-1)计算出需要交换的另一个工件
[0067]
计算出需要两个工件总工序之差作为不需要交换工序的位置数,采用随机方式保留不需要交换工序的位置;
[0068]
将两工件需要交换的工序位置进行交换,得到新的个体的工序编码;
[0069]
随机选择设备位,按照式(6-5)进行设备选择,得到新的个体的设备编码;
[0070][0071]
其中,λ∈(0,1)是随机数,a
i,j
(t)表示第i个工件的第j道工序所使用花费最小时间的设备,b
i,j
(t)表示第i个工件的第j道工序所使用花费最大时间的设备;x
i,j,l
(t)和分别表示为第i个工件的第j道工序所使用的设备l和设备l
*
。
[0072]
根据新的个体的工序编码,随机选择速度,产生的新的个体构成子代种群a*。
[0073]
步骤6中对种群b选择个体进行螺旋更新位置操作形成子代种群b*具体过程为:
[0074]
从种群b中利用模拟退火选择机制获得需要进行螺旋搜索个体;
[0075]
将外部档案a
t+1
中适应度最小的个体作为最优个体,计算种群b中利用模拟退火选择机制获得的需要进行螺旋搜索的个体与最优个体的距离d';
[0076]
d'=|f*(t)-f(t)|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-3)
[0077]
其中,f*(t)为第t次迭代时的局部最优解的适应度值,f(t)表示需要进行螺旋搜索的个体的适应度值;
[0078]
利用公式(6-4)计算出需要交换的两个工件:
[0079][0080]
其中,b
*
为常量系数,l为l∈[0,1]的随机变量;x
*
(t)为需要进行螺旋搜索的工件,x(t+1)螺旋搜索需要交换的工件;若x(t+1)>max(x
*
t(,则取x(t+1)=max(x
*
(t)),若x(t+1)<1,则x(t+1)=1;
[0081]
计算出需要两个工件总工序之差作为不需要交换工序的位置数,采用随机方式保
留不需要交换工序的位置;
[0082]
将两个工件需要交换的工序位置进行交换,得到新的个体的工序编码,随机选择设备和速度,产生的新的个体构成子代种群b*。
[0083]
步骤6中对种群c选择个体进行高斯变异或随机扰动操作形成子代种群c*具体过程为:
[0084]
从种群c中利用模拟退火选择机制获得需要进行高斯变异或随机扰动操作的个体;
[0085]
若利用公式(6-5)是获得新个体适应度值小于模拟退火选择机制获得个体适应度值,采用公式(6-6)获得新个体;
[0086]
x(t+1)=(1+n(0,1))
·
x
*
(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-5)
[0087]
x(t+1)=lb+r3(ub-lb)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-6)
[0088]
其中,n(0,1)表示期望为0,标准差为1的正态分布随机数,lb为1,ub为加工工件总工序;r3为[0,1]的随机向量;
[0089]
对工序进行操作时,x
*
(t)为需要进行高斯变异或随机扰动操作的工件,x(t+1)进行高斯变异或随机扰动操作的工件,若x(t+1)>max(x
*
(t)),则取x(t+1)=max(x
*
(t)),若x(t+1)<1,则x(t+1)=1;
[0090]
随机产生需要进行高斯变异或随机扰动操作的工件x
*
(t),利用公式(6-5)或者公式(6-6)计算高斯变异或随机扰动操作的工件x(t+1)
[0091]
计算出需要两个工件总工序数之差作为不需要交换工序的位置数,采用随机方式保留不需要交换工序的位置;
[0092]
将两个工件需要交换的工序位置进行交换,得到新的个体的工序编码,随机选择速度,产生的新的个体构成子代种群c*。
[0093]
步骤6中对种群d进行多位交换操作形成新的种群d
*
具体过程为:
[0094]
对种群d中个体的工序采用多位变换操作,其中,p和c分别代表父代工序编码和子代工序编码;m和m'分别代表父代设备编码和子代设备编码;s代表随机生成的0-1字符串;k表示位置集,里面存放变换的所在编码位置;
[0095]
先进行工序变换操作:
[0096]
1)随机生成长度为工序数的0或1的字符串s;
[0097]
2)计算要参加变换的位数的公式如下:
[0098]
g=pm×
min(count(0),count(1))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-7)
[0099]
其中,g是参加变换的位数,pm为变换概率,count(0)和count(1)分别指生成字符串0和1的个数;
[0100]
3)随机生成位置集k,从工序排序编码p中选择位置集k包含的位置对应的工序进行随机交换,得到子代工序编码c;
[0101]
再进行设备变换操作:
[0102]
1)随机生成位置集k,从设备编码m中选择位置集k包含的位置对应的设备位,作为需要变换的设备位;
[0103]
2)对每个需要变换设备位,从对应设备集中随机选择一个设备,得到子代设备编码m';
[0104]
最后进行速度变换操作:
[0105]
根据新个体的工序编码c,随机选择速度,得到子代的速度编码。
[0106]
本发明的有益效果是:
[0107]
本发明基于改进spea2算法的机器多转速车间节能调度方法,spea2算法是一种专门求解多目标优化问题的算法,由于其特性,不需要将多目标问题转化为单目标,改进算法是在原算法的基础上引入了特殊拥挤度和平均适应度值对种群进行合理划分;对种群分别进行反向学习操作、螺旋更新位置操作、高斯变异或随机扰动操作;反向学习降低算法陷入局部最优的概率,加快算法的收敛速度,平衡算法的勘探和开采能力;螺旋更新位置操作搜索效率高,搜索过程灵活,有较好的普适性和易扩充性;高斯变异或随机扰动操作在进化前期,使得算法快速寻找最优解;在进化后期,增加种群多样性,为跳出局部最优创造了条件;除此之外,采用模拟退火选择机制来选择父代种群,能够找出2个相似度小的父本进行下一步操作,而且通过使用距离较远的2个父本来,能使后代个体范围增加,提高了算法的寻优能力,加快了进化的速度,突破了局部最优解。
附图说明
[0108]
图1是一个可行解的编码方案示意图;
[0109]
图2是适应度值计算示意图;
[0110]
图3是两种算法求解标准算例mk01所得最大完工时间收敛曲线图;
[0111]
图4是两种算法求解标准算例mk01所得总延期时长收敛曲线图;
[0112]
图5是两种算法求解标准算例mk01所得设备总负荷收敛曲线图;
[0113]
图6是两种算法求解标准算例mk01所得总能耗收敛曲线图;
[0114]
图7是两种算法求解标准算例mk01所得hv值收敛曲线图;
[0115]
图8是传统nsga-ii求解标准算例mk01所得调度结果甘特图;
[0116]
图9是改进spea2求解标准算例mk01所得调度结果甘特图。
具体实施方式
[0117]
下面结合附图和具体实施方式对本发明进行详细说明。
[0118]
本发明基于改进spea2算法的机器多转速车间节能调度方法,具体按照以下步骤实施:
[0119]
步骤1、构建柔性作业车间节能调度问题的数学模型;
[0120]
其中多目标柔性作业车间节能调度问题描述如下:
[0121]
设n个工件在m台设备上加工,每个工件有一道或多道工序,每道工序可在不同的设备上加工,但不同设备加工同一工序的时间不同,调度内容即是在满足约束条件的前提下,将工件的各道工序合理地安排给各台设备,并选择合适的加工速度,以实现最大完工时间、最小总延期时长、最小设备总负荷和最小系统总能耗。
[0122]
模型假设具体如下:
[0123]
设一台设备一次只能加工一个工件;
[0124]
设备开始加工中途不可停止;
[0125]
同一工件的工序加工有先后之分,即后道工序只有在前道工序加工完才可以加
工;
[0126]
不同工件没有先后约束;
[0127]
设备空闲时不停机;
[0128]
设备加工前的准备时间以及加工过程中工件的装载和卸载时间均不考虑;
[0129]
包括设备故障、任务加急在内的紧急情况均不考虑。
[0130]
构建柔性作业车间节能调度问题的数学模型具体过程为:
[0131]
定义ji表示工件i的总工序数;c
iji
表示工件i的完工时间;n表示工件总数;ti表示工件i的交货期;t
ijk
表示工件i的第j道工序在设备k上的加工时间;x
ijk
为0-1变量,如果工件i的第j道工序在设备k上的加工,则x
ijk
=1,否则x
ijk
=0;x
ijkl
(t)为0-1变量,如果机器mk以速度v
l
加工工序o
ij
,则x
ijkl
(t)=1,否则x
ijkl
(t)=0;e
kl
表示机器对应加工状态下的能耗,且e
kl
=4v
l2
,sek表示机器处于待机状态下的能耗,且sek=1,zk(t)为0-1变量,如果在t时刻,机器mk处于待机状态,则zk(t)=1,否则zk(t)=0,e
kl
与p
ijkl
两者的关系,如果工序o
ij
在机器mk上的加工速度增加,则相应加工时间会变小,但与之相反,其对应的能量消耗则会增大,具体如下:
[0132][0133]
所有机器在加工过程中始终保持开机状态,当其上没有工件加工时,对应机器处于待机状态,直到所有工件加工完成,机器才能关闭;
[0134]
构建柔性作业车间节能调度问题的数学模型的目标函数:
[0135]
f1=max(c
iji
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1-2)
[0136][0137][0138][0139]
其中,公式(1-2)表示最大完工时间最小的目标函数;公式(1-3)表示总延期时长最小的目标函数;公式(1-4)表示设备总负荷最小的目标函数;公式(1-5)表示系统总能耗最小的目标函数,系统总能耗又包括加工能耗、空载能耗。
[0140]
步骤2、采用基于自然数三段式编码,三段式编码分别为工序码、设备码和速度码;任意一个工序码、设备码和速度码形成一个个体,采用随机方式生成规模为n的初始种群p0,创建空的外部档案a0,设置算法参数:算法参数包括当前迭代次数t,最大迭代次数t
max
,变换概率pm,退火速率μ,模拟退火选择机制的初始接受概率pr;
[0141]
采用等长三段式编码方案分别表示包含的三个子问题,其中包括机器选择部分、工序排序部分编码方案、速度选择部分编码方案,速度选择部分采用与机器选择部分类似的编码方案,即每一位基因代表对应机器选择的速度档位,速度档位为正实数,不是整数,因此速度选择部分基因串内数值都不是整数。此处,每台机器的可选加工速度档位为v={1,1.2,1.5},对应一个可行解的编码方案如图1所示。
[0142]
步骤3、计算当前种群p
t
和外部档案a
t
并集中所有个体的适应度;具体过程为:
[0143]
步骤3.1、计算个体所支配的解和所有支配该个体的解:
[0144]
给每个个体y(i)设置两个参数ni和si,ni为种群中支配个体y(i)的个体数量,mi为被个体y(i)支配的其他个体的数量,根据柔性作业车间节能调度问题的数学模型目标函数计算个体目标值,当个体y(i)的所有目标值都优于个体y(j)对应的目标值时,定义个体y(i)支配个体y(j),否则个体y(i)不能支配个体y(j);
[0145]
步骤3.2、计算强度值:
[0146]
适应度赋值考虑个体的支配情况即每个个体所支配的解和所有支配该个体的解。将个体所支配的解的数量,作为该个体的强度值s(i):
[0147]
s(i)=|{j|xj∈p
t
+a
t
,xi>xj}|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3-1)
[0148]
步骤3.3、计算原始适应度值:
[0149]
在计算出强度值的基础上,每个个体的原始适应度值为所有支配它的解的强度值之和,按下式计算:
[0150][0151]
如图2所示,(求最大),在计算r(i)时,种群和外部档案内的个体都考虑在内,r(i)越大表明它被越多的解支配。图2中a点支配3个解,它的强度值为3;b点支配2个解,它的强度值为2;其它点依此类推。a点的原始适应度值为0,是非支配解;b点只被a点支配,它的原始适应度值为a的强度值即3;c点被a点、b点和d点支配,它的原始适应度值为这三点的强度值之和,即3+2+5;其它点依此类推。
[0152]
步骤3.4、计算密度值:
[0153]
原始的适应度赋值反映了个体的支配与被支配的信息,但是为了维护外部档案只知道这些信息是不够的,所以引入k阶近邻法密集度参数评估具有相同适应度值的个体:
[0154][0155]
其中,为个体i与第k个相近的个体在目标函数空间上的欧几里得距离;d(i)越大表示个体i与第k近的个体距离越近,即越密集;
[0156]
步骤3.5、计算适应度值:
[0157]
将原始的适应度值与密度值的和作为个体i的适应度值f(i):
[0158]
f(i)=r(i)+d(i),i=1,2,...,n
ꢀꢀ
(3-4)
[0159]
步骤4、外部档案具有固定的大小始终保持一个恒定的常数。根据适应度选择前种群p
t
和外部档案a
t
中个体添加到下一代外部档案a
t+1
,如果a
t+1
的规模大于n,使用修剪策略修剪;否则,更新外部档案;具体如下:
[0160]
步骤4.1、将种群p
t
和外部档案a
t
并集中适应度值小于1的个体添加到a
t+1
中,如果a
t+1
的大小等于n,作为下一代档案a
t+1
;
[0161]
步骤4.2、如果a
t+1
的大小小于n,那么将p
t
和a
t
并集中最好的n-|a
t+1
|个受支配的解,即根据它们的适应度值大小排序后,最小的n-|a
t+1
|个个体加入到下一代档案a
t+1
中;
[0162]
步骤4.3、如果a
t+1
的大小大于n,要对a
t+1
实行修剪策略,直到a
t
的大小等于n为止,具体的操作是将满足下列条件的个体i从档案中删除,在外部档案a
t+1
中选取个体k,个体k根据以下公式确定:
[0163][0164]
其中,p表示种群的规模,a
*
表示外部档案规模;
[0165]
计算外部档案a
t+1
中每个个体j与个体k的欧几里得距离,将得到的距离从大至小进行排序,将距离较小的个体删除,使得外部档案a
t+1
中保留n个个体。
[0166]
步骤5、依据适应度值的好坏对种群的进行排序。引入了特殊拥挤度的概念。对种群的个体进行排序后,根据排序结果计算拥挤度。拥挤度代表周围个体的密度。拥挤度越小,周围个体越密集。因此,选择拥挤程度较高的个体。
[0167]
对外部档案a
t+1
中个体适应度的大小进行排序,计算相邻个体之间的特殊拥挤度距离,取种群拥挤度距离小的20%的个体组成一个新的种群a;对剩余的个体求其平均适应度值,不大于平均适应度值的个体组成种群b,大于平均适应度值的个体组成种群c;从外部档案a
t+1
中模拟退火选择机制选择50%的个体组成种群d;
[0168]
相邻个体之间的特殊拥挤度距离计算公式为:
[0169][0170]
其中,s
t_max
为第t代个体强度值的最大值,s
t_min
为第t代个体强度值的最小值,s(x
t_i+1
)和s(x
t_i-1
)表示第t代个体相邻的两个体的强度值。
[0171]
从外部档案a
t+1
中模拟退火选择机制选择50%的个体作为种群d具体过程为:
[0172]
从外部档案a
t+1
中随机选择2个个体a和b;
[0173]
计算个体a和b的适应度值fa、fb;
[0174]
判断fa是否大于fb;若不大于,则选择个体a作为父代种群l
t
中的一个个体;否则,则随机生成(0,1]上某个概率值p;
[0175]
判断随机概率值p是否满足式(5-2)和式(5-3)所示条件,若是,则选择个体a作为种群d中的一个个体;若否,则选择个体b作为种群d中的一个个体;
[0176]
随机概率值p的判断式为:
[0177]
p<min(1,exp(-(f
a-fb)/t))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5-2)
[0178]
当前温度t的计算式为:
[0179]
t=μi×
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5-3)
[0180]
初始退火温度t的计算式为:
[0181][0182]
其中,公式(5-2)表示随机概率值p的判断式;公式(5-3)表示当前温度t的计算式;公式(5-4)表示初始退火温度t的计算式。
[0183]
其中,μ为退火速率;i为算法当前迭代次数;f
max
表示外部档案中最大适应度值;f
min
为外部档案中最小适应度值;pr为模拟退火选择机制的初始接受概率。
[0184]
步骤6、在种群a部分个体进行反向学习操作形成子代种群a*;在种群b选择部分个体进行螺旋更新位置操作形成子代种群b*;在种群c选择部分个体进行高斯变异或随机扰动操作形成子代种群c*;对种群d中所有个体进行多位交换操作形成新的种群d
*
;种群a、b、
c选择个体的机制是模拟退火选择机制;将子代种群a*、b*、c*、d
*
组成新的子代种群p
t+1
;
[0185]
为了协调算法的勘探和开采能力,对当前种群a个体执行反向学习策略。由反向学习策略可知,一方面将反向种群与当前种群合并,选出优秀个体进入下一代群体中以增强种群的多样性,能降低算法陷入局部最优的概率;另一方面,它又充分吸收了当前种群中外部档案个体的有益搜索信息,可以加快算法的收敛速度。由此可见,反向学习策略可平衡算法的勘探和开采能力。对种群a选择个体进行反向学习操作形成子代种群a*具体过程为:
[0186]
从种群a中模拟退火选择机制选择需要进行反向学习操作的个体;
[0187]
对选择的个体上关于工序的编码采用公式(6-1)进行更新,得到个体新的工序编码:
[0188][0189]
其中,λ∈(0,1)的随机数,b表示加工的总工序数,若则取若则xi和分别为当前解和反向解;
[0190]
随机产生工件xi,采用公式(6-1)计算出需要交换的另一个工件
[0191]
计算出需要两个工件总工序之差作为不需要交换工序的位置数,采用随机方式保留不需要交换工序的位置;
[0192]
将两工件需要交换的工序位置进行交换,得到新的个体的工序编码;
[0193]
随机选择设备位,按照式(6-5)进行设备选择,得到新的个体的设备编码;
[0194][0195]
其中,λ∈(0,1)是随机数,a
i,j
(t)表示第i个工件的第j道工序所使用花费最小时间的设备,b
i,j
(t)表示第i个工件的第j道工序所使用花费最大时间的设备;x
i,j,l
(t)和分别表示为第i个工件的第j道工序所使用的设备l和设备l
*
。
[0196]
根据新的个体的工序编码,随机选择速度,产生的新的个体构成子代种群a*。
[0197]
螺旋搜索过程灵活,有较好的普适性和易扩充性,搜索效率高,是一种具有较好的全局优化求解能力的自适应搜索技术。对种群b选择个体进行螺旋更新位置操作形成子代种群b*具体过程为:
[0198]
从种群b中利用模拟退火选择机制获得需要进行螺旋搜索个体;
[0199]
将外部档案a
t+1
中适应度最小的个体作为最优个体,计算种群b中利用模拟退火选择机制获得的需要进行螺旋搜索的个体与最优个体的距离d';
[0200]
d'=|f*(t)-f(t)|
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-3)
[0201]
其中,f*(t)为第t次迭代时的局部最优解的适应度值,f(t)表示需要进行螺旋搜索的个体的适应度值;
[0202]
利用公式(6-4)计算出需要交换的两个工件:
[0203][0204]
其中,b
*
为常量系数,l为l∈[0,1]的随机变量;x
*
(t)为需要进行螺旋搜索的工件,x(t+1)螺旋搜索需要交换的工件;若x(t+1)>max(x
*
t(,则取x(t+1)=max(x
*
t(,若x(t+1)<1,则x(t+1)=1;
[0205]
计算出需要两个工件总工序之差作为不需要交换工序的位置数,采用随机方式保
留不需要交换工序的位置;
[0206]
将两个工件需要交换的工序位置进行交换,得到新的个体的工序编码,随机选择设备和速度,产生的新的个体构成子代种群b*。
[0207]
为维持此算法进化过程中种群的多样性,进而增强算法摆脱局部最优解的能力,保证算法的搜索精度。采用高斯变异或随机扰动的方法,在进化前期,使得算法快速寻找最优解;在进化后期,增加种群多样性,为跳出局部最优创造了条件。对种群c选择个体进行高斯变异或随机扰动操作形成子代种群c*具体过程为:
[0208]
从种群c中利用模拟退火选择机制获得需要进行高斯变异或随机扰动操作的个体;
[0209]
若利用公式(6-5)是获得新个体适应度值小于模拟退火选择机制获得个体适应度值,采用公式(6-6)获得新个体;
[0210]
x(t+1)=(1+n(0,1))
·
x
*
(t)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-5)
[0211]
x(t+1)=lb+r3(ub-lb)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-6)
[0212]
其中,n(0,1)表示期望为0,标准差为1的正态分布随机数,lb为1,ub为加工工件总工序;r3为[0,1]的随机向量;
[0213]
对工序进行操作时,x
*
(t)为需要进行高斯变异或随机扰动操作的工件,x(t+1)进行高斯变异或随机扰动操作的工件,若x(t+1)>max(x
*
(t)),则取x(t+1)=max(x
*
(t)),若x(t+1)<1,则x(t+1)=1;
[0214]
随机产生工件x
*
(t),利用公式(6-5)或者(6-6)计算出需进行高斯变异或随机扰动操作的工件x(t+1);
[0215]
计算出需要两个工件总工序数之差作为不需要交换工序的位置数,采用随机方式保留不需要交换工序的位置;
[0216]
将两个工件需要交换的工序位置进行交换,得到新的个体的工序编码,随机选择速度,产生的新的个体构成子代种群c*。
[0217]
对种群d进行多位交换操作形成新的种群d
*
具体过程为:
[0218]
对种群d中个体的工序采用多位变换操作,其中,p和c分别代表父代工序编码和子代工序编码;m和m'分别代表父代设备编码和子代设备编码;s代表随机生成的0-1字符串;k表示位置集,里面存放变换的所在编码位置;
[0219]
先进行工序变换操作:
[0220]
1)随机生成长度为工序数的0或1的字符串s;
[0221]
2)计算要参加变换的位数的公式如下:
[0222]
g=pm×
min(count(0),count(1))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6-7)
[0223]
其中,g是参加变换的位数,pm为变换概率,count(0)和count(1)分别指生成字符串0和1的个数;
[0224]
3)随机生成位置集k,从工序排序编码p中选择位置集k包含的位置对应的工序进行随机交换,得到子代工序编码c;
[0225]
再进行设备变换操作:
[0226]
1)随机生成位置集k,从设备编码m中选择位置集k包含的位置对应的设备位,作为需要变换的设备位;
[0227]
2)对每个需要变换设备位,从对应设备集中随机选择一个设备,得到子代设备编码m';
[0228]
最后进行速度变换操作:
[0229]
根据新个体的工序编码c,随机选择速度,得到子代的速度编码。
[0230]
步骤7、如果迭代次数t小于t
max
,令t=t+1,将种群p
t
更新为新的子代种群p
t+1
,返回步骤3;否则将外部档案a
t+1
和新的子代种群p
t+1
中适应度值最小的个体,作为最优妥协解输出。
[0231]
实施例
[0232]
对标准算例mk01-mk10进行仿真实验,将分别采用改进spea2和传统nsga
‑ⅱ
两种算法用matlab2017b编程,在配置为内存8g,r5 3.2ghz的计算机上,在win10操作系统下进行仿真求解。由于标准算例仅包含加工时间数据,不能直接应用本发明算法求解,为了有效应用本发明算法对mk01-mk10进行求解,其中标准算例原有的加工时间作为基本加工时间,所有设备的加工速度都包括v={1,1.2,1.5}三个档位,加工能耗空载能耗sek=1;所有工件的交货期数据按照如下来生成。
[0233][0234]
其中,dj代表第j个工件的交期时间,rj代表第j个工件的投放时间,tj代表第j个工件的松紧度,sj代表第j个工件的工序数,p
l,j
代表第j个工件的第l个工序的加工时间。tj有三个取值:tj=2表示时间宽松,tj=1.5表示时间适中,tj=1表示时间紧张。每个案例中,具有不同时间松紧程度(紧张、适中、宽松)的工件数量分别为34%,33%,33%。
[0235]
传统nsga
‑ⅱ
算法的参数设置为n=200,pc=0.8,pm=0.15,t
max
=1200,采用加权法来从pareto解集中选择最优妥协解。改进spea2算法的参数设置为n=200,pm=0.9,t
max
=1200,pr=0.35,μ=0.85。
[0236]
两种算法针对每个算例求解运行10次。求解结果如表1所示:
[0237]
表1
[0238]
[0239][0240]
根据表1可知,在最大完工时间指标上,改进spea2算法取得了mk01-mk10共10个算例的最优值,取得了mk01-mk10共10个算例的最优平均值;传统nsga
‑ⅱ
算法取得了0个算例的最优值,取得了0个算例的最优平均值,两种算法求解标准算例mk01所得最大完工时间收敛曲线图如图3所示。
[0241]
在总延期时长指标上,改进spae2算法取得了mk01,mk02,mk03,mk05-mk10共9个算例的最优值,取得了mk01-mk10共10个算例的最优平均值;传统nsga
‑ⅱ
算法取得了mk01,mk02,mk03,mk04,mk06共5个算例的最优值,取得了mk01,mk02,mk04,mk06共4个算例的最优平均值,两种算法求解标准算例mk01所得总延期时长收敛曲线图如图4所示。
[0242]
在总负荷指标上,改进spea2算法取得了mk01-mk10共10个算例的最优值,取得了mk01-mk10共10个算例的最优平均值;传统nsga
‑ⅱ
算法取得了0个算例的最优值,取得了0个算例的最优平均值,两种算法求解标准算例mk01所得设备总负荷收敛曲线图如图5所示。
[0243]
在总能耗指标上,改进spea2算法取得了mk01-mk10共10个算例的最优值,取得了mk01-mk10共10个算例的最优平均值;传统nsga
‑ⅱ
算法取得了0个算例的最优值,取得了0个算例的最优平均值,两种算法求解标准算例mk01所得总能耗收敛曲线图如图6所示。
[0244]
为了进一步分析算法的优化性能,将两种算法求解机器多转速柔性作业车间调度问题所得hv结果对比如表2所示,两种算法求解标准算例mk01所得hv值收敛曲线图如图7所示。
[0245]
表2
[0246][0247][0248]
分析表2可知,传统nsga
‑ⅱ
算法取得了mk04共1个算例的最优的hv值,传统nsga-ii求解标准算例mk01所得调度结果甘特图如图8所示。改进spea2算法取得了mk01,mk02,mk03,mk05,mk06,mk07,mk08,mk09,mk10共9个算例的最优hv值,改进spea2求解标准算例mk01所得调度结果甘特图如图9所示。
[0249]
综上可知,改进spea2算法在求解机器多转速柔性作业车间调度问题上,较传统nsga
‑ⅱ
算法拥有更好的综合性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1