一种基于改进YOLOv2模型的海上目标检测识别方法和处理装置
一种基于改进yolo v2模型的海上目标检测识别方法和处理装置
技术领域
1.本发明涉及计算机视觉领域的目标检测方法,特别涉及一种基于改进yolo v2模型的海上目标的检测识别方法和处理装置。
背景技术:
2.近年来,随着我国综合实力的提升及国家统一战略的需要,我国大力发展海洋军事,为了应对潜在敌人强大海军力量的威胁,对于敌人航母的检测与精准识别成为一重要课题。众所周知,航母舰岛属于航母的“头部”,起着指挥调度的作用,这就要求我方能够实时快速地识别出敌方舰岛并实施精准打击。现有的雷达探测方法不能够很好识别出航母上的舰岛,引入图像识别是现代化信息化海战的应有之意。此外,多变的海洋气象状况和海水运动导致海洋中时有大雾大雨天气,这就为航母舰岛的精准实时检测带来了挑战。
3.现有的图像目标检测算法基本可分成两类:two-stage类别的目标检测算法和one-stage类别的目标检测算法。
4.two-stage类别的目标检测算法是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。对于two-stage的目标检测网络,主要通过一个卷积神经网络来完成目标检测过程,其提取的是cnn卷积特征,在训练网络时,其主要训练两个部分,第一步是训练rpn网络,第二步是训练目标区域检测的网络。网络的准确度高、速度相对one-stage慢。two-stage算法的代表是r.girshick等人在2014年提出的r-cnn到faster r-cnn网络。虽然two-stage类别的目标检测算法检测精度较高,但大量的候选框区域重叠导致特征重复提取,检测速度慢,实时性很差,不适用于海上目标的实时检测。
5.one-stage类别的目标检测算法直接回归物体的类别概率和位置坐标值(无regionproposal),但准确度低,速度相比于two-stage快。one-stage类别的目标检测算法通过主干网络给出类别和位置信息,没有使用rpn网路。这样的算法速度更快,但是精度相对two-stage目标检测网络了略低。目前常用的典型的one-stage目标检测网络为yolov1、yolov2、yolov3、ssd、dssd和retina-net等。
6.随着基于深度学习的目标检测算法的进一步发展,出现了满足实时性要求的单阶段方法yolo(you only look once)。yolo网络将目标检测看成一个回归问题来求解,即空间分离的边界框和相关的类概率,将候选区域框选和检测分类二合一,用一个单一的神经网络在一次评估中得到全图像的边界框和类概率。
技术实现要素:
7.本发明解决的技术问题是:多变的海洋气象状况和海水运动导致传统的航母舰岛图像清晰度低,传统的目标检测方法难以很好针对低清晰度图像进行精确检测,同时传统方法实时性有所欠缺。
8.为此,本发明的目的之一是提供一种基于改进yolo v2模型的海上目标的检测识
别方法,其通过训练生成对抗网络得到生成器作为去雾网络,首先通过将图像输入去雾网络进行去雾处理,再将去雾后的高清晰度图像输入基于改进yolo v2网络的目标检测模型进行检测识别。
9.本发明的目的之二是提供一种用于执行上述基于改进yolo v2模型的海上目标的检测识别方法的处理装置。
10.为了解决上述技术问题,本发明提供了以下技术方案:
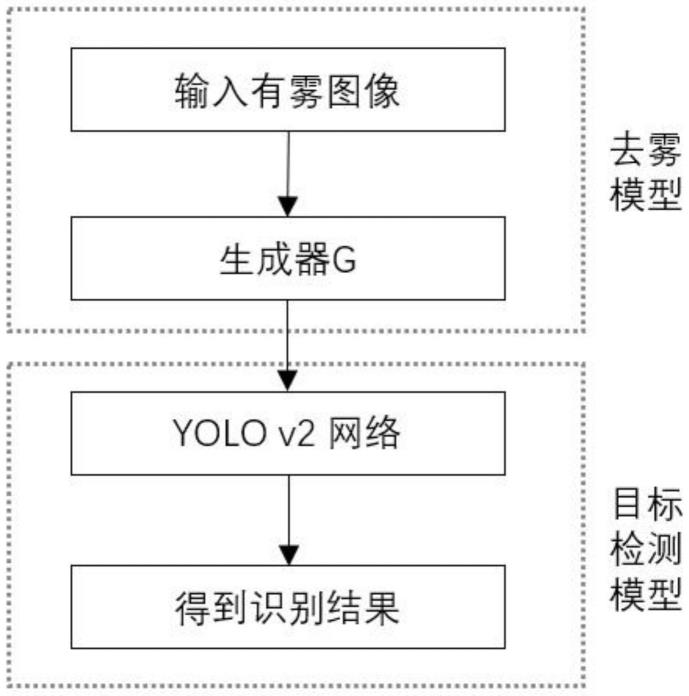
11.第一方面,一种基于改进yolo v2模型的海上目标检测方法,包括以下步骤:
12.步骤a,基于生成对抗网络(gan)训练有雾图像,经过若干次迭代得到gan的生成器作为去雾网络,利用去雾网络对原始图像进行高清晰度训练处理得到高清晰化训练图像;
13.步骤b,利用基于yolo v2网络的目标检测模型对步骤a的高清晰化训练图像进行目标检测,识别图像中是否存在对应的目标。
14.在本发明的一个优选实施例中,所述步骤a包括以下步骤:
15.s11,基于大气散射模型的雾天图像成像模型将所述的高清晰度训练图像合成有雾图像;
16.s12,将所述的高清晰度训练图像和步骤s11得到的相应的合成有雾图像输入生成对抗网络进行若干次迭代,得到可作为去雾网络的生成器。
17.在本发明的一个优选实施例中,在所述步骤s12中,所述步骤s11得到的相应的合成有雾图像当作所述生成器的输入图像,而将高清晰度训练图像当作真实图像。
18.在本发明的一个优选实施例中,将所述生成器的生成图像与真实图像作为所述生成对抗网络的判别器输入,在判别器中进行判别;所述生成对抗网络中的生成器与判别器在对抗中互相优化,优化后继续对抗,经过若干次迭代训练后以达到最终的平衡状态,此时经过训练后的生成器即可成为所述的去雾网络。
19.在本发明的一个优选实施例中,所述的生成器为基于dehazenet的神经网络,相较于原始dehazenet网络,生成器删去了其maxout激活函数,以加快计算速度。
20.在本发明的一个优选实施例中,所述判别器选用alexnet网络。
21.在本发明的一个优选实施例中,所述步骤b中的基于改进yolo v2网络的目标检测模型建立包括以下步骤:
22.s21,利用darknet-19网络提取特征
23.所述darknet-19特征提取网络包括19个卷积层和5个最大池化层,在网络输入图像尺寸为416*416,输出维度13*13的特征图;
24.s22,边界框预测
25.采用k-means聚类方法对训练集中的边界框做了聚类分析,选择合适先验框,每个网格输入图像都输出5个边界框信息,输出维度为13*13*5;
26.s23,类别预测。通过置信度计算每一个边界框的综合得分,保留综合得分超过阈值的边界框,再通过非极大值抑制得到分类结果。
27.在本发明的一个优选实施例中,所述的yolo v2网络的激活函数采用elu,该激活函数与leaky-relu在x取正值时一样,但在x为负值时采用的是指数函数,当参数不断变小时,函数逐渐收敛到一个负值。而收敛意味着其具有较小的导数值,这便减少了传播到下一层的变化和信息。因此,该激活函数对于噪声信息具有较强鲁棒性且其复杂度相对较低。
28.在本发明的一个优选实施例中,所述的步骤b包括如下步骤:
29.第一步,先在高清晰度训练集上预训练darknet-19网络,此时模型输入为224*224,共训练160代;
30.第二步,将网络的输入调整为448*448,继续在高清晰度训练集上微调分类模型,训练10代;
31.第三步,修改darknet-19分类模型为检测模型,并在高清晰度训练集上继续微调网络;网络修改包括:移除最后一个卷积层、全局平均池化层以及softmax层,并且新增了三个尺寸为3*3*1024的卷积层,在每个卷积层后加入一个尺寸为1*1的卷积层输出预测结果。
32.本发明第二方面的一种处理装置,包括:
33.存储器,用于存储计算机程序;
34.处理器,用于用所述存储器调用并运行所述计算机程序,以执行第一方面所述的方法。
35.通过上述技术方案,本发明的有益效果包括:
36.1.提出了一种利用生成对抗模型来训练去雾网络的方法,该方法将训练好的生成器作为去雾网络对图像进行去雾操作,能够有效应对海洋中复杂的多变气候带来的多雾天气给目标检测带来的困难。
37.2.利用yolo v2网络进行目标检测,检测快速准确,实时性强。
附图说明
38.图1为本发明的基于改进yolo v2模型的海上目标检测方法的流程图。
39.图2为本发明的生成器(去雾网络)训练示意图。
40.图3为本发明的海上目标检测模型的流程图。
具体实施方式
41.以下结合附图对本发明中的具体实施细节做进一步阐述。
42.本发明的一种基于改进yolo v2模型的海上目标检测方法,包括以下步骤:
43.步骤a,基于生成对抗网络(gan)训练有雾图像,经过若干次迭代得到gan的生成器作为去雾网络,利用去雾网络对原始图像进行高清晰度训练处理得到高清晰化训练图像;
44.步骤b,利用基于yolo v2网络的目标检测模型对步骤a的高清晰化训练图像进行目标检测,识别图像中是否存在对应的目标。
45.步骤a包括以下步骤:
46.步骤s11中,基于大气散射模型的雾天图像成像模型将高清晰度训练图像合成有雾图像。大气散射模型可由以下公式表示:i(x)=j(x)t(x)+a(1-t(x))。其中i(x)是观察者观测到的景物在x处的亮度,在本发明中即有雾图像,j(x)是景物在x处实际的真实亮度,在本发明中即为无雾图像,定义透射率公式为t=e-(βd(x))
,a(1-t(x))为大气光。该式反映了有雾的天气状况下空气透射光线的能力。
47.步骤s12中,引入了生成对抗网络。
48.在训练阶段,将上一步骤s11中输出的合成有雾图像当作生成器的输入图像,而将高清晰度训练图像当作真实图像。进一步将生成器的生成图像与真实图像作为所述生成对
抗网络的判别器输入,在判别器中进行判别;所述生成对抗网络中的生成器与判别器在对抗中互相优化,优化后继续对抗,经过若干次迭代训练后以达到最终的平衡状态,此时经过训练后的生成器即可成为所述的去雾网络。
49.作为本发明的优选方案,采用的生成器为基于dehazenet的神经网络,相较于原始dehazenet网络,生成器删去了其maxout激活函数,以加快计算速度。由于生成对抗网络的生成器与判别器两个模型会经过若干次相互对抗优化,会导致损失函数较快的resnet网络很快进入局部最优状态,因此判别器弃用传统的resnet网络而选用alexnet网络。
50.本发明步骤b即为利用基于改进yolo v2网络的目标检测模型对经去雾模型处理后的图像进行目标识别检测。
51.yolo v2网络采用的激活函数为leaky-relu,该激活函数在取负值时采用一个斜率较小的线性函数虽然有输出但不能确保失活状态下的噪声鲁棒性。
52.针对这一问题,本发明的目标检测模型采用的激活函数为elu,其公式定义为:
[0053][0054]
该公式中:x为上一层卷积层的输出,y为经过激活函数后输入给下层卷积层的值。
[0055]
该激活函数与leaky-relu在x取正值时一样,但在x为负值时采用的是指数函数,当参数不断变小时,函数逐渐收敛到一个负值。而收敛意味着其具有较小的导数值,这便减少了传播到下一层的变化和信息。因此,该激活函数对于噪声信息具有较强鲁棒性且其复杂度相对较低。
[0056]
本发明基于改进yolo v2网络的目标检测模型建立步骤如下:
[0057]
步骤s21,利用darkent-19网络提取特征。darknet-19网络包括19个卷积层和5个最大池化层,计算量较小。darknet-19与vgg16网络设计原则是一致的,主要采用3*3卷积,采用2*2的最大池化层之后,特征图维度降低2倍。与nin(network in network)类似,darknet-19最终采用全局平均池化做预测,并且在3*3卷积之间使用1*1卷积来压缩特征图通道以降低模型计算量和参数。darknet-19每个卷积层后面使用了batch normalization层以加快收敛速度,降低模型过拟合。网络输入图像尺寸416*416,输出维度13*13的特征图。
[0058]
步骤s22,边界框预测。本发明借鉴了faster r-cnn中rpn网络的先验框(anchor boxes)策略。与在faster r-cnn中先验框的维度(长和宽)都是手动设定的不同,本发明采用k-means聚类方法对训练集中的边界框做了聚类分析,选择合适先验框。每个候选框会输出5个边界框信息,每一边界框包括5个值(t
x
,ty,tw,th,to),前四个值确定目标在图像中的位置,后一个值确定目标所属类别,(t
x
,ty)为边界框的坐标,(tw,th)为边界框的宽和高,都为归一化后的值,to为置信度。置信度计算公式为:
[0059][0060]
式中,pr(o
object
)为候选框中是否存在目标,存在为1,否则取0。为候选框与真实目标框之间的iou。
[0061]
步骤s23,类别预测。每个边界框的置信度与类别信息相乘能够得到每个边界框的综合得分:
[0062][0063]
式中,p(ci|o
object
)为条件概率,意为如果该边界框中存在一个目标o
object
,那么它是标记目标ci的概率。
[0064]
得到综合得分后,再与所设置阈值进行比较,对大于阈值的边界框信息保留,再通过非极大值抑制来最终得到类别预测。
[0065]
本发明的改进yolov2网络模型训练主要包括三个阶段:
[0066]
1)第一阶段就是先在高清晰度训练集上预训练darknet-19,此时模型输入为224*224,共训练160代。
[0067]
2)第二阶段将网络的输入调整为448*448,继续在高清晰度训练集上微调分类模型,训练10代。
[0068]
3)第三阶段就是修改darknet-19分类模型为检测模型,并在高清晰度训练集上继续微调网络。网络修改包括:移除最后一个卷积层、全局平均池化层以及softmax层,并且新增了三个尺寸为3*3*1024的卷积层,在每个卷积层后加入一个尺寸为1*1的卷积层输出预测结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1