一种企业危险废物瞒报漏报风险的智能评估方法
1.本发明涉及危险废物产量评估技术领域,特别是涉及一种企业危险废物瞒报漏报风险的智能评估方法。
背景技术:
2.危险废物是指列入国家危险废物名录或者根据国家规定的危险废物鉴别标准和鉴别方法认定的具有危险特性(包括腐蚀性、毒性、易燃性、反应性和感染性)的固体废物。近年来随着城市化和工业化进程的加快,我国危险废物的产生量保持高位增长。且危险废物种类繁多,成分复杂,整体呈现产生强度大、处置利用能力不足、污染事故频发的态势,对生态环境和人体健康带来巨大威胁。
3.国家高度重视生态文明建设和环境保护工作,固体废物尤其是危险废物的管理工作是加强生态文明建设和改善环境质量的关键。危险废物的管理工作目前面临的挑战之一是危险废物底数不清。为了获取企业危险废物的产生和流动信息,我国目前实施的是基于企业自主申报登记危废信息的管理制度。然而部分企业在经济利益和侥幸心理的驱动下,极易发生瞒报漏报的行为。瞒报漏报的现象如果不能被及时有效地管控,可能会导致大量危险废物游离于监管范围之外,被非法地处置或倾倒,造成严重的环境风险。
4.为了确定企业是否存在瞒报漏报行为,需要准确掌握企业理论产废量,将理论产废量与企业申报值进行对比后,判断企业是否瞒报漏报。现有的预测企业理论产废量的方法主要包括:产排污系数法、物料衡算法和实测法。产排污系数法依据《排放源统计调查产排污核算方法和系数手册》等各类手册获得污染物产排系数,结合企业产品产量信息,计算出特定污染物的排放总量;物料衡算法和实测法通过实地研究和对特定企业生产条件的考虑,直接从生产设施收集信息。现有的技术方法都存在着一定局限性:
①
产废系数从地区或行业的平均水平考虑,对具体企业的实用性及适应性存在局限;
②
物料衡算法和实测法需精准掌握企业的生产工艺和流程,技术难度大,也很难在国家和地区层面上实施;
③
上述方法在工艺复杂、干扰因素多时都会引入较大偏差。
5.因此,有必要运用更加科学恰当的方法评估企业级别的危险废物排放,掌握企业危险废物的理论产生量,结合自主申报数据进行核查,从而实现对企业瞒报漏报行为的智能识别,有效提升危险废物管理水平。
技术实现要素:
6.本发明所要解决的技术问题是:为了克服现有技术中的不足,本发明提供一种企业危险废物瞒报漏报风险的智能评估方法,提高环境监管的准度和效率。
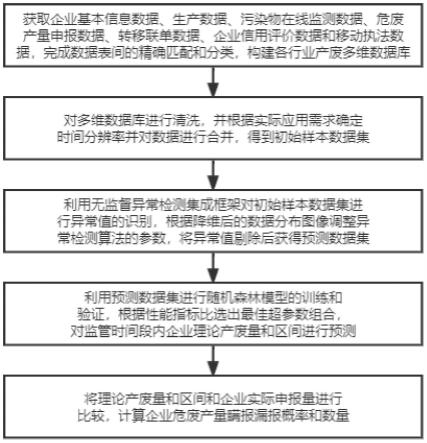
7.本发明解决其技术问题所要采用的技术方案是:一种企业危险废物瞒报漏报风险的智能评估方法,包括以下步骤:
8.步骤1:获取企业基本信息表、企业生产数据表、污染物在线监测数据表、危废产量申报数据表、转移联单数据表、企业信用评价数据表和移动执法数据表,完成数据表间的精
确匹配,并根据行业代码进行分类,构建不同行业的产废多维数据库。
9.步骤2:针对步骤1中的产废多维数据库中的数据进行人工清洗,消除多维数据库中的脏数据,具体的;并根据实际应用需求确定时间分辨率,对人工清洗后的数据进行合并,得到初始样本数据集;其中,脏数据是指影响预测模型构建的数据,具体是把重复、不合规、异常数据统称为脏数据;时间分辨率是指数据整理时候用的时间,也就是训练和预测的时间是企业每天、每月、还是每年产生的危废量。
10.步骤3:利用无监督异常检测集成框架对步骤2中的初始样本数据集进行异常数据的识别,然后,将初始样本数据集中异常数据剔除,获得预测数据集;其中,无监督异常检测集成框架是一种已知的技术,在目前异常检测任务中应用比较广泛且有比较完善的python库。
11.步骤4:利用步骤3中的预测数据集,以危废总产量或单类危废产量作为因变量,进行随机森林模型的训练和验证,根据均方根误差rmse的平均数和回归决定系数r2的平均数比选出最佳超参数组合,对监管时间段内企业的理论产废量和理论产废范围进行预测,其中,监管时间段是指需要对企业产废量进行预测,并评估瞒报数量和概率的时间段。
12.步骤5:将步骤4获得的理论产废量与企业实际申报量进行比较,计算企业危废产量瞒报漏报概率和数量。
13.进一步,步骤1具体包括以下步骤:
14.步骤1-1:从企业级别的信息化系统中获得企业相关数据表,其中,企业级别的信息化系统为危险废物全生命周期监控系统、污染物在线监测系统等,获得权限后可访问,还可以采用其他满足要求的信息化系统。
15.所述企业相关数据表包括:
16.企业基本信息表:包括但不限于企业名称、企业id、组织机构代码、污染源代码、行业类别代码和企业员工数;
17.企业生产数据表:包括但不限于原辅料名称、原辅料用量、主要产品名称、主要产品产量、用电量、用水量和企业总产值;
18.污染物在线监测数据表:包括但不限于监测时间、污染源代码、污染因子(包括废水流量、废气流量、总铜、总铬、ph、氨氮、二氧化硫等)、污染物排放量;
19.危废产量申报数据表:包括但不限于废物名称、废物代码、产生量、单位、申报时间和产生单位名称;
20.转移联单数据表:包括但不限于转移联单编号、废物名称、废物代码、移出量、转移时间和产生单位名称。
21.企业信用评价数据表:包括但不限于企业名称、污染源代码、评价时间、信用评分和信用评级;
22.移动执法数据表:包括但不限于企业名称、污染源代码、检查时间、是否涉及环境违法和违法类型。
23.步骤1-2,根据企业名称、污染源代码和组织机构代码精确匹配步骤1-1中各数据表,构建初始产废多维数据库。
24.步骤1-3,根据国民经济行业分类与代码(gb/t 4754-2017)中小类代码划分步骤1-2中获得的初始产废多维数据库,使用历史时间段数据构建不同行业的产废多维数据库,
其中,历史时间段是指用于构建模型时使用的数据集对应的时间段。
25.步骤1-4,可选的,根据相关企业规模划分标准(如:国家统计局印发的《统计上大中小微型企业划分办法(2017)》),将企业按企业员工数和总产值划分为大、中、小、微四个企业规模层级,并根据企业规模层级进一步对不同行业的产废多维数据库进行划分,或将企业规模作为后续预测模型输入变量之一。
26.进一步,步骤2具体包括以下步骤:
27.步骤2-1:采用人工筛选的方式,对步骤1获得的产废多维数据库中不符合用户定义完整性的数据和重复数据进行删除,以及对有大量缺失值的不可用变量进行删除。
28.步骤2-2:针对产废多维数据库中的产废企业进行合规性检验,对合规性较低的企业观测进行初步筛除;其中,合规性检验是在企业环境信用越差,环境违法行为越多,申报数据越容易作假的假设下,对数据进行粗筛查,以保证构建预测模型的数据可靠性更高,也属于人工清洗的一部分。
29.步骤2-3:根据实际应用需求确定时间分辨率,将经过步骤2-1和步骤2-2人工清洗后的产废多维数据库中的数据按照指定的时间周期进行合并,得到初始样本数据集。其中,时间分辨率和时间周期是根据实际需求确定的,例如:如果想要预测企业周产废量,则需要把清洗后的数据按周加和;如果想要预测企业月产废量,则需要把清洗后的数据按月加和;如果想要预测季产废量,则需要把清洗后的数据按季加和,以此类推。
30.具体的,步骤2-2中对企业的合规性检验包括以下步骤:
31.步骤2-2-1:通过企业基本信息、企业信用评价数据和移动执法数据的匹配,获得企业合规性信息表。
32.步骤2-2-2:根据合规性信息表统计产废企业每年检查次数和其中的违法次数,计算违法率:
[0033][0034]
步骤2-2-3,根据合规性信息表计算产废企业年平均信用评分结果,确定企业环保信用等级;在确定环保信用等级时,根据相关的法律法规、部门规章等进行确定,本实施例中对应《江苏省企事业环保信用评价办法》,确定企业环保信用等级。
[0035]
步骤2-2-4,将违法率或环保信用等级不符合要求的企业视为低合规性企业,并删除该企业和对应年份的数据。
[0036]
进一步,为了提高异常数据的识别效果,步骤3中还包括对无监督异常检测集成框架中异常检测算法的重要参数和异常比例进行优化调整的过程。
[0037]
进一步,步骤3具体包括以下步骤:
[0038]
步骤3-1:针对步骤2中的初始样本数据集,选取各类危废产量、各类废水因子监测值和各类废气因子监测值作为异常检测特征,对异常检测特征进行标准差标准化操作,获得标准化检测数据集;
[0039]
标准差标准化(z-normalization)操作的公式为:
[0040][0041]
其中,x
*
为转换后数据,x为原数据,μ为所有样本数据的均值,δ为所有样本数据的
标准差。
[0042]
步骤3-2,构建无监督异常检测集成框架,识别标准化检测数据集中的异常数据。
[0043]
由于采用无监督异常检测集成框架确定的异常数据为多维异常数据,无法在二维、三维空间绘图,因此,需要对多维异常数据进行降维后映射到二维坐标图上,才能形成可视化的异常数据分布图像,对异常检测算法的重要参数和异常比例进行优化调整,因此,具体为:
[0044]
步骤3-3,利用降维算法对多维异常数据进行降维,并对降维后的异常数据分布特征进行可视化,形成异常数据的分布图像,结合分布图像中异常数据分布特征调整异常检测集成框架中异常检测算法的重要参数和异常比例,作为优选,选取图像中离群值皆被标记且异常数据和正常数据的标记没有较多重叠的分布图像作为识别结果,将初始样本数据集中异常值剔除后获得预测数据集。其中,不同异常检测算法的参数不尽相同,因此,在进行参数调整时,也存在差异,但是每种异常检测算法都需要设定异常比例。作为优选,映射到二维坐标图上的数据,将正常点和异常点分别用蓝色和红色区分标记,当图像中显著离群观测点都被标记为红色,且两种数据分布没有较多重叠时,识别效果较好。
[0045]
可选的,使用的降维算法为以下算法中的一种:
[0046]
主成分分析(principal component analysis)、t-sne(t-distributed stochastic neighbor embedding)、多维标度分析(multidimensional scaling)等。
[0047]
进一步,步骤3-2中具体包括以下步骤:
[0048]
步骤3-2-1:利用若干异常检测算法分别对步骤3-1所述标准化检测数据集分别进行异常识别,获得若干单维异常分数矩阵。
[0049]
可选的,常用的异常检测算法主要包括:
[0050]
线性模型(linear model):最小协方差矩阵(minimum covariance determinant)、单类支持向量机(one-class support vector machines)等;
[0051]
基于接近度算法(proximity-based):k邻近(k nearest neighbors)、局部利群因子(local outlier factor)等;
[0052]
基于概率算法(probabilistic):绝对中位差(angle-based outlier detection)等;
[0053]
集成检测(outlier ensembles):孤立森林(isolation forest)等;
[0054]
神经网络(neural networks):变分自编码器(variational autoencoder)等。
[0055]
步骤3-2-2:将步骤3-2-1所述的若干单维异常分数矩阵合并成一个多维异常分数矩阵,进行标准差标准化操作,获得标准化多维异常分数矩阵。
[0056]
步骤3-2-3:将步骤3-2-2所述的标准化多维异常分数矩阵采用组合函数合并,按异常比例选取综合异常得分最高的部分数据定义为异常数据。
[0057]
可选的,使用的组合函数为以下算法中的一种:
[0058]
简单平均(average)、加权平均(weighted average)、最大化(maximization)、简单平均和最大化结合(aom:average of maximum、moa:maximum of average)等。
[0059]
进一步,步骤4具体包括以下步骤:
[0060]
步骤4-1:确定预测的因变量,以危废总产量或单类危废产量作为预测的因变量。
[0061]
步骤4-2:随机森林模型的训练与验证整体采用k折交叉验证的方法,根据所预测
的因变量的数据特征,将预测数据集划分成因变量数据分布一致的k组数据,每次取k-1组数据作为训练集,剩余的1组数据作为验证集,共进行k次。
[0062]
步骤4-3:确定随机森林模型的超参数,并设置每种超参数的取值范围和步长,生成备选超参数列表,对备选超参数列表使用网格搜索法将不同超参数组合分别代入随机森林模型进行训练与验证;其中,随机森林模型的超参数的选取是根据验证结果不断调试的过程,对不同的数据适宜选取的超参范围可能差别较大,因此,通过训练和验证以获得超参数的最优值。网格搜索法(grid search方法)是调参中十分常见的做法,简单说就是穷举法。比如超参数a可以取[1,2],超参数b可以取[3,4],a和b就会有1和3,2和3,1和4,2和4四种超参数组合。
[0063]
主要比选的超参数包括:
[0064]
决策树数量(n_estimators):在利用最大投票数或平均值来预测之前,想要建立子树的数量,较多的子树可以让模型有更好的性能;
[0065]
节点数(max_features):每个节点上随机选择的变量最大数目,进而在其中选择影响最大的变量;
[0066]
最大树深(max_depth):限制子树的分裂高度,以减少过拟合。
[0067]
步骤4-4:根据k次验证均方根误差rmse的平均数和回归决定系数r2的平均数两种性能指标,对步骤4-3所述超参数组合进行比选,获得最优超参数组合;
[0068]
均方根误差rmse:
[0069][0070]
其中,为验证集上真实值-预测值,m为验证集样本数;
[0071]
回归决定系数r2:
[0072][0073]
其中,分子部分表示真实值与预测值的平方差之和;分母部分表示真实值与均值的平方差之和。
[0074]
步骤4-5:根据目标企业所属行业选取最优超参数组合对应的随机森林模型作为最优模型,针对监管时间段,整理企业的自变量参数输入最优模型,对企业的理论产废量进行预测;
[0075]
步骤4-6:自变量参数输入最优模型后,根据随机森林模型预测监管时间段内企业理论产废量的残差分布,并确定残差覆盖范围,综合预测数据集的预测结果及残差覆盖范围,生成预测结果的置信区间,即企业理论产废范围,其中,预测结果指预测的企业理论产废量。
[0076]
具体的,步骤4-6中企业的理论产废量范围预测具体包括以下步骤:
[0077]
步骤4-6-1:对于随机森林模型构建中未被抽样的包外数据集,使用步骤4-5中的最优模型进行理论产废量的预测,计算包外数据集预测产废量和实际值y
oob
的残差ε;
[0078]
步骤4-6-2:利用包外数据自变量参数,以残差ε为因变量,按步骤4-2至4-4的流程
重新构建一个残差预测随机森林模型,预测包外数据集的残差与加和获得校正后的包外数据产废量预测值
[0079]
步骤4-6-3:利用校正后的包外数据集产废量预测值与真实值y
oob
相减,获得校正后包外数据的残差
[0080]
步骤4-6-4:对于新输入的监管时间段数据集x
new
,根据步骤4-5中最优模型构建过程中的包外数据集将与x
new
处于同一决策树最终节点的数据样本构成新的集合bop(x
new
),利用残差预测模型计算出bop(x
new
)中各数据的校正后残差获得数据集的残差分布;
[0081]
步骤4-6-5:对于步骤4-6-4中获得的残差分布,设置置信度为α,残差分布中至少覆盖α%样本的上限和下限即为残差覆盖范围;
[0082]
步骤4-6-6:在残差覆盖范围上下限基础上同时加上步骤4-5中预测的理论产废量,获得置信区间,即为企业理论产废范围。
[0083]
进一步,步骤5具体包括以下步骤:
[0084]
步骤5-1:获取并计算目标企业预测周期内危废产量申报数据,作为实际申报量,将步骤4得到的企业理论产废量作为理论预测量,计算瞒报数量:
[0085][0086]
其中,为理论预测量,y为实际申报量。
[0087]
步骤5-2:在理论产生废量符合正态分布的前提假设下,根据步骤4预测的理论产废范围获得理论产废量的累积分布函数曲线,获得取值为目标企业实际申报量时对应的概率值,即为企业瞒报概率:
[0088]
瞒报概率=f
x
(a)=p(x》a)
[0089]
其中,f
x
(a)为理论产废量的互补累积分布函数曲线,p(x》a)为理论产废量大于a时的概率,当a取值恰好为实际申报值时,f
x
(a)可代表理论产废量超过实际申报量的概率,即瞒报概率,此概率越大说明实际申报量偏少的可能性越高。
[0090]
步骤5-3:根据数据实际情况,拟取阈值,将瞒报数量和瞒报概率大于阈值的企业纳入高瞒报漏报风险企业名单,作为环保执法的重点对象。作为优选,瞒报数量的阈值可以选取该行业企业产废均值,瞒报概率的阈值可以选取50%,即将瞒报数量大于该行业企业产废均值和概率大于50%的企业纳入高瞒报漏报风险企业名单,作为环保执法的重点对象。
[0091]
本发明的有益效果是:
[0092]
(1)构建融合多维度产废数据的数据库,可为危废产量的精准预测提供全面可靠的数据基础,避免参数选择不当导致模型准确度低,计算时间长,以及适用范围小的不足。
[0093]
(2)综合采用人工数据清洗与无监督异常检测集成框架结合的方法,消除多维数据库中的脏数据,可解决目前自主申报数据真实性相对不足的问题,确保模型输入数据的可靠性,提高模型预测精度。
[0094]
(3)基于多维产废数据库,使用泛化能力良好的机器学习算法,可构建出偏差小、行业内普遍适用的模型,以解决现有危废核算方法精确性和适用性不足的问题,实现在企业级别进行危险废物排放强度的核算。
[0095]
(4)利用本发明所述方法全流程,可以实现涉废企业危废产量“瞒报漏报”的智能识别,解决环境执法针对性不足,执法相对滞后和监管能力有限的问题。
附图说明
[0096]
下面结合附图和实施例对本发明作进一步说明。
[0097]
图1是本发明智能评估方法的整体流程图。
[0098]
图2为集成异常数据检测方法流程图。
[0099]
图3为基于随机森林模型实现瞒报漏报智能识别方法流程图。
具体实施方式
[0100]
现在结合附图对本发明作详细的说明。此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0101]
本发明提供了一种企业危险废物瞒报漏报风险的智能评估方法,本实施例阐述了将本发明所提供的方法应用于江苏省电子电路制造行业(行业代码为c3982),识别企业危险废物瞒报漏报行为的情况。
[0102]
结合附图1,本发明的一种企业危险废物瞒报漏报风险的智能评估方法,包括以下步骤:
[0103]
步骤1:获取企业基本信息表、企业生产数据表、污染物在线监测数据表、危废产量申报数据表、转移联单数据表、企业信用评价数据表和移动执法数据表,完成数据表间的精确匹配,并根据行业代码进行分类,构建不同行业的产废多维数据库。
[0104]
步骤2:针对步骤1中的产废多维数据库中的数据进行人工清洗,消除多维数据库中的脏数据,具体的;并根据实际应用需求确定时间分辨率,对人工清洗后的数据进行合并,得到初始样本数据集;其中,脏数据是指影响预测模型构建的数据,具体是把重复、不合规、异常数据统称为脏数据;时间分辨率是指训练和预测的对象是企业每天、每月、还是每年产生的危废量;周期合并就是把日数据加起来变成月数据,把月数据加起来变成年数据。
[0105]
步骤3:利用无监督异常检测集成框架对步骤2中的初始样本数据集进行异常数据的识别,然后,将初始样本数据集中异常数据剔除,获得预测数据集;其中,无监督异常检测集成框架是一种已知的技术,在目前异常检测任务中应用比较广泛且有比较完善的python库。
[0106]
步骤4:利用步骤3中的预测数据集,以危废总产量或单类危废产量作为因变量,进行随机森林模型的训练和验证,根据均方根误差rmse的平均数和回归决定系数r2的平均数比选出最佳超参数组合,对监管时间段内企业的理论产废量和理论产废范围进行预测。
[0107]
步骤5:将步骤4获得的理论产废量与企业实际申报量进行比较,计算企业危废产量瞒报漏报概率和数量。
[0108]
本实施例步骤1具体包括:
[0109]
步骤1-1:从危险废物全生命周期监控系统、污染物在线监测系统等企业级别的信息化系统获得相关数据表,包括:企业基本信息、企业生产数据、污染物在线监测数据、危废产量申报数据、转移联单数据、企业信用评价数据和移动执法数据。
[0110]
步骤1-2:根据企业名称、污染源代码和组织机构代码精确匹配各数据表,构建产
废多维数据库。
[0111]
步骤1-3:根据国民经济行业分类与代码(gb/t 4754-2017)中小类代码划分产废多维数据库,筛选出所属行业为c3982的企业数据,共92家,使用2020年1月至2021年11月的历史数据,构建所属行业为c3982的企业产废多维数据库。
[0112]
本实施例步骤2具体包括:
[0113]
步骤2-1:对c3982的企业产废多维数据库中不符合用户定义完整性的数据、重复数据进行删除,以及对有大量缺失值的不可用变量进行删除。
[0114]
步骤2-2:通过企业基本信息、企业信用评价数据和移动执法数据的匹配,获得企业合规性信息表。统计产废企业每年检查次数和其中的违法次数,计算违法率,并根据信用评分结果,对应《江苏省企事业环保信用评价办法》,确定企业环保信用等级。将违法率大于10%或环保信用等级低于蓝色等级的企业视为低合规性企业,并删除该企业对应的数据。
[0115]
违法率:
[0116][0117]
步骤2-3,时间分辨率指整理数据时用的分辨率,本实施例中为“月”,将经过人工清洗后的数据集以月为分辨率进行合并,即将属于相同月份的数据进行合并,具体方式为各类危废、废水流量、氨氮、cod值按月加和,得到初始样本数据集,共608条数据。
[0118]
结合附图2,本实施例步骤3具体包括:
[0119]
步骤3-1:选取初始样本数据集的危废总量、废水流量、氨氮、cod共四个特征作为异常检测特征,对异常检测特征进行标准差标准化操作,获得标准化检测数据集;
[0120]
标准差标准化(z-normalization):
[0121][0122]
其中,x
*
为转换后数据,x为原数据,μ为所有样本数据的均值,δ为所有样本数据的标准差。
[0123]
步骤3-2:选取六种常用异常检测模型,分别为孤立森林(iforest)、最小协方差矩阵(mcd)、局部离群因子法(lof)、k最邻近法(knn)、基于聚类的局部离群因子法(cblof)和基于直方图异常点检测法(hbos),构建无监督异常检测集成框架,对标准化检测数据集进行异常值识别检测,获得六个单维异常分数矩阵。对模型识别的六维异常分数矩阵再次进行标准化处理,采用aom(average of maximum)的组合函数合并,按异常比例选取综合异常得分最高的部分数据定义为异常数据;
[0124]
具体的,孤立森林(iforest)是一种基于多决策树集成的检测算法。其基本原理是。在孤立森林中递归地随机分割数据集,直到所有的样本点都是孤立的,综合所有决策树结果,总路径较短的通常为异常值;
[0125]
最小协方差行矩阵(mcd)是一种基于马氏距离的检测算法。其基本原理是,利用最小协方差行列式计算获取更稳健的均值和协方差估计量,再根据马氏距离计算,马氏距离大于临界值的为异常值;
[0126]
局部离群因子法(lof)是一种基于密度的检测算法。其基本思想是,根据数据点周围的数据密集情况,计算每个数据点的一个局部可达密度,通过局部可达密度进一步计算
得到每个数据点的一个离群因子,该离群因子即标识了一个数据点的离群程度,因子值越大,表示离群程度越高;
[0127]
k最邻近法(knn)是一种基于距离的检测算法。其基本原理是,依次计算每个样本点与它最近的k个样本的平均距离,计算的平均距离大于阈值,则认为是异常点;
[0128]
基于聚类的局部离群因子法(cblof)是一种基于聚类的检测算法。其基本原理是,使用聚类来确定数据中的密集区域,然后对每个聚类进行密度估计;
[0129]
基于直方图异常点检测法(hbos)是一种基于统计方法的检测算法。其基本原理是,假设每个维度独立,对每个维度再进行区间划分,每个区间所对应的异常值取决于密度。密度越高,异常值越低;
[0130]
aom组合函数是一种简单平均和最大化结合的组合方法。具体方式为将多维异常得分矩阵按维度平均划分成几组,每条数据在组内取最大异常得分,并在组间取平均值后获得综合异常得分。
[0131]
步骤3-3:利用t-sne(t-distributed stochastic neighbor embedding)降维算法对多维异常数据分布特征进行可视化,形成异常数据的分布图像,可结合分布图像中异常数据分布特征调整算法重要参数和异常比例,最终选择了10%(60条)异常数据从初始样本数据集中剔除,获得预测数据集。
[0132]
具体的,t-sne算法是一种非线性的降维技术,可以较好地通过视觉可视化来验证算法的性能。将数据点之间的相似度转换为概率,高维空间中的相似度由高斯联合概率表示,低维空间的相似度由“学生t分布”表示,通过尽可能提高高低维空间分布相似度完成数据的降维。
[0133]
结合附图3,本实施例步骤4和步骤5具体包括:
[0134]
步骤4-1:使用随机森林(random forest)算法,以预测数据集中废水流量、氨氮、cod三个特征为自变量,危废总产量作为因变量,进行模型的训练与验证;
[0135]
具体的,随机森林是一种基于决策树集成的算法。在应用于回归与测试时,其基本原理为,从原始训练样本集n中有放回地重复随机抽取k个样本生成新的训练样本集合,然后生成k个回归树组成随机森林,新数据的预测值为所有回归树预测结果的平均值。
[0136]
步骤4-2:随机森林模型的训练与验证整体采用十折交叉验证的方法,根据所预测的因变量数据特征,将预测数据集划分成因变量数据分布一致的10组。每次取9组作为训练集,剩余1组作为验证集,共进行10次;
[0137]
步骤4-3:对三种主要超参数设置一定取值范围和步长,生成备选超参数列表,对备选超参数列表使用网格搜索法将不同超参数组合分别代入模型进行训练与验证。
[0138]
主要比选超参数包括:
[0139]
决策树数量(n_estimators):在利用最大投票数或平均值来预测之前,想要建立子树的数量,较多的子树可以让模型有更好的性能;
[0140]
节点数(max_features):每个节点上随机选择的变量最大数目,进而在其中选择影响最大的变量;
[0141]
最大树深(max_depth):限制子树的分裂高度,以减少过拟合。
[0142]
步骤4-4:根据k次验证均方根误差(rmse)平均数和回归决定系数(r2)平均数两种性能指标,对超参数组合进行比选,获得最优模型;最优模型的性能指标为r2=0.74,rmse
=603.21。
[0143]
均方根误差(rmse):
[0144][0145]
其中,为验证集上真实值-预测值,m为验证集样本数;
[0146]
回归决定系数(r2):
[0147][0148]
其中,分子部分表示真实值与预测值的平方差之和;分母部分表示真实值与均值的平方差之和;
[0149]
步骤4-5:以2021年12月作为监管时间段,企业a为例,将其2021年12月废水流量、氨氮、cod作为自变量特征数值输入最优模型,预测其理论产废量为381.83吨;
[0150]
步骤4-6:根据建立随机森林模型时所产生的包外数据集,预测输入数据集的残差分布。综合预测数据集的预测结果及设置的残差覆盖范围,生成预测结果的95%置信区间,获得企业理论产废范围为[122.54,479.93]。
[0151]
步骤5-1:获取企业a在2021年12月危废产量申报数据,实际申报值为137.81吨,计算得瞒报数量为244.02吨。
[0152]
瞒报数量:
[0153][0154]
其中,为预测得出的理论产废量,y为实际申报量;
[0155]
步骤5-2:在理论产生量符合正态分布的前提假设下,根据理论产废范围获得理论产生量的互补累积分布函数曲线,获得目标企业实际申报量对应的概率值为97.5%,即企业瞒报概率为97.5%。
[0156]
步骤5-3,瞒报概率的阈值选取50%,企业a瞒报数量远超过了理论产废量的50%且瞒报概率高达97.5%,可认为该企业有较高的瞒报漏报风险,应作为重点监管对象。
[0157]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1