一种基于域适应的眼科OCT术后轮廓图生成方法及系统
一种基于域适应的眼科oct术后轮廓图生成方法及系统
技术领域
1.本发明涉及视网膜图像仿真生成技术领域,特别是涉及一种基于域适应的眼科oct术后轮廓图生成方法及系统。
背景技术:
2.眼科oct检查,是光学相干断层扫描(optical coherence tomography)的缩写,它是一种利用光的干涉现象成像的断层扫描技术,并结合计算机图像技术,可以观察眼内的超微组织结构的横断面图像。它是一种分辨率高、成像快的非侵入性、非接触性的检查,被称为眼科的ct。oct在视网膜疾病、黄斑疾病、视神经疾病、青光眼等临床研究方面有重要价值。它可为视网膜疾病,尤其是黄斑病的诊断及鉴别诊断提供有价值的的依据,可以观察细微病变的形态学改变,可直接进行组织测量,对眼底病变进行定量分析,可以发现一些极微小的眼底病变,可以鉴别血性与浆液性脱离;可为黄斑前膜、黄斑裂孔、黄斑下脉络膜新生血管膜、玻璃体黄斑牵引综合征等的手术适应症的选择提供有价值的资料,亦可作为评价手术治疗是否成功的依据之一;可以追踪某些病变的变化及治疗效果。
3.oct在眼病诊断上效果有效,但费用却相对较高,某些眼病患者在术后需要随访,例如孔源性视网膜脱离(rrd)术后持续视网膜下积液(srf),包括术前、术后1个月和术后3个月均需要对患者进行相关的临床检查,期间需要进行多次oct扫描,将给患者造成不小的经济负担。为了解决这个问题,有部分研究指出可以利用深度学习技术,根据术前oct图像直接生成术后oct图像,但由于oct图像分辨率高以及配对标注数据有限,导致图像生成难度大且效果差,容易出现重影、模糊等问题,难以准确评估手术治疗效果。
4.现有技术公开了一种具有可行性和有效性的视网膜oct疾病影像生成的方法,生成的oct影像可用于扩充oct疾病影像分类算法的训练数据集;该方法以条件生成对抗网络cgan为基础,网络结构由生成器与判别器组成,通过将生成对抗损失函数cgan loss与一种新型结构相似性损失函数ssim loss相结合,将正常视网膜oct影像转化成可用于补充分类模型训练集的oct疾病影像。该专利通过训练生成对抗网络,根据已有的oct影像自动生成多种病变的视网膜oct影像,由于oct图像分辨率高以及配对标注数据有限,导致图像生成难度大且效果差。
技术实现要素:
5.本发明的目的是提供一种简单高效、准确率高的基于域适应的眼科oct术后轮廓图生成方法及系统。
6.为了实现上述目的,本发明提供了一种基于域适应的眼科oct术后轮廓图生成方法,包括如下步骤:
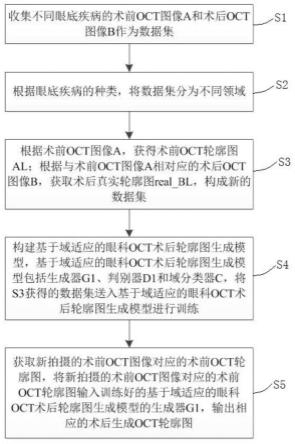
7.s1、收集不同眼底疾病的术前oct图像a和术后oct图像b作为数据集;
8.s2、根据眼底疾病的种类,将数据集分为不同领域;
9.s3、根据术前oct图像a,获得术前oct轮廓图al;根据与术前oct图像a相对应的术
后oct图像b,获取术后真实轮廓图real_bl,构成新的数据集;
10.s4、构建基于域适应的眼科oct术后轮廓图生成模型,基于域适应的眼科oct术后轮廓图生成模型包括生成器g1、判别器d1和域分类器c,将s3获得的数据集送入基于域适应的眼科oct术后轮廓图生成模型进行训练,包括:
11.s4.1通过卷积神经网络对术前oct轮廓图al进行特征提取,并转化为张量表示;之后输入生成器g1,得到预测生成的术后生成轮廓图fake_bl;
12.s4.2、将术前oct轮廓图al、术后真实轮廓图real_bl和术后生成轮廓图fake_bl输入判别器d1,根据判别结果计算判别器损失loss_d1并更新判别器d1的参数;
13.s4.3、将术前oct轮廓图al、术后真实oct轮廓图real_bl和术后生成轮廓图fake_bl输入域分类器c,根据对领域的判别结果计算域分类器损失loss_c并更新域分类器c的参数;
14.s4.4、计算生成器损失loss_g1并更新生成器g1的参数,其中,判别器d1和域分类器c的判别结果参与生成器损失loss_g;
15.s4.5、重复步骤s4.2、s4.3和s4.4,直至训练结束,得到训练好的基于域适应的眼科oct术后轮廓图生成模型;
16.s5、获取新拍摄的术前oct图像对应的术前oct轮廓图,将新拍摄的术前oct图像对应的术前oct轮廓图输入训练好的基于域适应的眼科oct术后轮廓图生成模型的生成器g1,输出相应的术后生成oct轮廓图。
17.作为优选方案,在步骤s4.2中,将术前oct轮廓图al和术后生成轮廓图fake_bl拼接起来,得到negative_img_d1,再将negative_img_d1送入判别器d1,得到张量pred_fake_d1,判别器d1为其打上标签0,即判别器d1认为这张图是假的,计算pred_fake_d1的gan损失loss_d1_fake;
18.将术前oct轮廓图al和术后真实oct轮廓图real_bl拼接起来,得到positive_img_d1,再将positive_img_d1送入判别器d1,得到pred_real_d1,判别器d1为其打上标签1,即判别器d1认为这张图是真的,计算pred_real_d1的gan损失loss_d1_real;
19.将loss_d1_fake和loss_d1_real的gan损失相加,得到判别器损失loss_d1。
20.作为优选方案,在步骤s4.3中,将术前oct轮廓图al和术后生成轮廓图fake_bl拼接起来,得到negative_img_c,再将negative_img_c送入域分类器c,得到张量pred_fake_c,域分类器c打上的标签不为其所在领域对应的标签,即域分类器c未判别出这张图所在正确的领域,计算pred_fake_c的gan损失loss_c_fake;
21.将术前oct轮廓图al和术后真实oct轮廓图real_bl拼接起来,得到positive_img_c,再将positive_img_c送入域分类器c,得到pred_real_c,域分类器c打上其所在领域对应的标签,即域分类器c判别出这张图所在的领域,计算pred_real_c的gan损失loss_c_real;
22.将loss_c_fake和loss_c_real的gan损失相加,得到域分类器损失loss_c。
23.作为优选方案,在步骤s4.4中,包括:
24.s4.4.1、获取步骤s4.2中的pred_real_d1的gan损失loss_d1_real;
25.s4.4.2、获取步骤4.3中的pred_fake_c的gan损失loss_c_fake;
26.s4.4.3、计算步骤s4.2中的pred_fake_d1和pred_real_d1的逐像素损失l1;
27.s4.4.3、计算步骤s4.3中的pred_fake_c和pred_real_c的逐像素损失l2;
28.s4.4.5、计算术前oct图像a和术后生成轮廓图fake_bl的vgg特征损失,记为loss_g_vgg;
29.s4.4.6、将loss_d1_real、loss_c_fake、l1、l2和loss_g_vgg相加,得到生成器损失loss_g。
30.作为优选方案,判别器d1和域分类器c均为多尺度判别器。
31.作为优选方案,生成器g1包括全局生成器网络g1.1和局部增强网络g1.2,全局生成器网络g1.1的输入和输出的分辨率一致,局部增强网络g1.2的输出尺寸是输入尺寸的4倍;局部增强网络g1.2用于将全局生成器网络g1.1生成的图像的分辨率扩大,在训练时,将术前oct轮廓图al输入全局生成器网络g1.1,将全局生成器网络g1输出的图像输入局部增强网络g1.2。
32.作为优选方案,全局生成器网络g1.1的网络结构为u-net,负责图像特征的编码解码。
33.作为优选方案,在步骤s2中,通过对术前oct图像a和术后oct图像b中的神经纤维层内表面、内核层内表面、外核层内表面、椭圆体带以及rpe外表面进行描边得到术前oct轮廓图al和术后真实轮廓图real_bl。
34.作为优选方案,在步骤s2中,将术前oct图像a输入术前oct轮廓图生成模型,输出术前oct轮廓图al;术前轮廓图生成模型为生成对抗网络;术前轮廓图生成模型包括生成器g2和判别器d2。
35.本发明还提供一种基于域适应的眼科oct术后轮廓图生成系统,包括:
36.数据获取模块,用于获取不同眼底疾病的术前oct图像和术后oct图像以构成数据集;
37.分类模块,用于根据眼底疾病的种类将数据集分为不同领域;
38.轮廓图像获取模块,用于根据术前oct图像a,获得术前oct轮廓图al;根据与术前oct图像a相对应的术后oct图像b,获取术后真实轮廓图real_bl;
39.模型构建模块,用于构建基于域适应的眼科oct术后轮廓图生成模型,基于域适应的眼科oct术后轮廓图生成模型包括生成器g1、判别器d1和域分类器c,生成器g1用于根据术前oct图像a生成术后生成轮廓图fake_bl,判别器d1用于对术后生成轮廓图fake_bl和术后真实oct轮廓图real_bl进行判别,域分类器c用于对术后生成轮廓图fake_bl和术后真实oct轮廓图real_bl的领域进行判别;
40.损失函数构建模块,用于构建多目标损失函数;多目标损失函数包括生成器g1的损失函数、判别器d1的损失函数和域分类器c的损失函数;
41.训练模块,用于将术前oct轮廓图al和术后真实oct轮廓图real_bl构成的样本作为基于域适应的眼科oct术后轮廓图生成模型的输入,基于多目标损失函数对基于域适应的眼科oct术后轮廓图生成模型进行迭代训练,得到训练好的基于域适应的眼科oct术后轮廓图生成模型;
42.应用模块,用于将新拍摄的术前oct图像对应的术前oct轮廓图输入训练好的基于域适应的眼科oct术后轮廓图生成模型的生成器g1,得到相应的术后生成oct轮廓图。
43.与现有技术相比,本发明的有益效果在于:
44.本发明通过获得术前oct图像对应的术前oct轮廓图,根据术前oct轮廓图通过基
于域适应的眼科oct术后轮廓图生成模型生成术后oct轮廓图,相比直接生成高分辨率、纹理信息复杂的术后oct图像,其技术难度明显降低,简单高效,且生成的轮廓图噪声极小,使生成的轮廓图的准确度高,利用术后oct轮廓图,即可测量部分关键的病理指标,并不需要术后oct图像辅助,医生也能一定程度上评估患者的术后恢复效果,实用性强;并且,不同眼底疾病的术前oct图像及其术后oct轮廓图之间内在联系具有一定相似性,本发明利用迁移学习技术整合源领域和目标领域多个来源的数据,有效扩大训练数据规模,改善了深度学习模型训练效果。
附图说明
45.图1是本发明实施例的基于域适应的眼科oct术后轮廓图生成方法的流程图。
46.图2是本发明实施例的基于域适应的眼科oct术后轮廓图生成模型的框架图。
47.图3是本发明实施例的基于域适应的眼科oct术后轮廓图生成模型的判别器d1的框架图。
48.图4是本发明实施例的基于域适应的眼科oct术后轮廓图生成模型的域分类器c的框架图。
49.图5是本发明实施例的基于域适应的眼科oct术后轮廓图生成模型的生成器g1框架图。
50.图6是本发明实施例的基于域适应的眼科oct术后轮廓图生成模型的全局生成器网络g1.1框架图。
51.图7是本发明实施例的基于域适应的眼科oct术后轮廓图生成系统的原理框图。
具体实施方式
52.下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
53.实施例一
54.如图1至图6所示,本发明优选实施例的一种基于域适应的眼科oct术后轮廓图生成方法,其特征在于,包括如下步骤:
55.s1、收集不同眼底疾病的术前oct图像a和术后oct图像b作为数据集;
56.s2、根据眼底疾病的种类,将数据集分为不同领域;
57.s3、根据术前oct图像a,获得术前oct轮廓图al;根据与术前oct图像a相对应的术后oct图像b,获取术后真实轮廓图real_bl,构成新的数据集;
58.s4、构建基于域适应的眼科oct术后轮廓图生成模型,基于域适应的眼科oct术后轮廓图生成模型包括生成器g1、判别器d1和域分类器c,将s3获得的数据集送入基于域适应的眼科oct术后轮廓图生成模型进行训练,包括:
59.s4.1通过卷积神经网络对术前oct轮廓图al进行特征提取,并转化为张量(多维向量)表示;之后输入生成器g1,得到预测生成的术后生成轮廓图fake_bl;
60.s4.2、将术前oct轮廓图al、术后真实轮廓图real_bl和术后生成轮廓图fake_bl输入判别器d1,根据判别结果计算判别器损失loss_d1并更新判别器d1的参数;
61.s4.3、将术前oct轮廓图al、术后真实oct轮廓图real_bl和术后生成轮廓图fake_
bl输入域分类器c,根据对领域的判别结果计算域分类器损失loss_c并更新域分类器c的参数;
62.s4.4、计算生成器损失loss_g1并更新生成器g1的参数,其中,判别器d1和域分类器c的判别结果参与生成器损失loss_g;
63.s4.5、重复步骤s4.2、s4.3和s4.4,直至训练结束,得到训练好的基于域适应的眼科oct术后轮廓图生成模型;本实施例的训练直至验证集指标趋于最优,即可停止训练,防止过拟合;
64.s5、获取新拍摄的术前oct图像对应的术前oct轮廓图,将新拍摄的术前oct图像对应的术前oct轮廓图输入训练好的基于域适应的眼科oct术后轮廓图生成模型的生成器g1,输出相应的术后生成oct轮廓图。
65.本实施例通过获得术前oct图像对应的术前oct轮廓图,根据术前oct轮廓图通过基于域适应的眼科oct术后轮廓图生成模型生成术后oct轮廓图,相比直接生成高分辨率、纹理信息复杂的术后oct图像,其技术难度明显降低,简单高效,且生成的轮廓图噪声极小,使生成的轮廓图的准确度高,利用术后oct轮廓图,即可测量部分关键的病理指标,并不需要术后oct图像辅助,医生也能一定程度上评估患者的术后恢复效果,实用性强;并且,不同眼底疾病的术前oct图像及其术后oct轮廓图之间内在联系具有一定相似性,本实施例利用迁移学习技术整合源领域和目标领域多个来源的数据,有效扩大训练数据规模,改善了深度学习模型训练效果。本实施例有效融合深度学习和迁移学习技术,充分利用术前oct图像及其特征,预测并生成患者的术后oct轮廓图,进而计算相关病理指标,有效辅助医生评估患者术后恢复效果。通过迁移学习,使本发明所提出的模型考虑多模态数据,训练数据来自多个领域,而非单一模态数据,综合考虑多个因素,使得生成的术后oct轮廓图更准确,特征细节更丰富。
66.本实施例的轮廓图是对神经纤维层内表面、内核层内表面、外核层内表面、椭圆体带以及rpe外表面描边获得的。
67.在实施例中,基于域适应的眼科oct术后轮廓图生成模型为生成对抗网络。步骤s2中,术前oct轮廓图al是眼科医生对术前oct图像a进行轮廓标注获得的。将术前oct轮廓图al与其对应的术后真实oct轮廓图real_bl进行配对,作为标注样本训练网络,实现由术前oct轮廓图al自动生成术后生成轮廓图fake_bl。基于域适应的眼科oct术后轮廓图生成模型主要由三部分组成:生成器g1、判别器d1和域分类器c。训练用的数据包括源领域和目标领域,所谓领域指的是oct图像对应患病种类的数据集,为了使生成的oct轮廓图拥有准确的目标特征,将数据集划分为源领域和目标领域,输入术前oct轮廓图al和术后真实oct轮廓图real_bl配对数据可能来自源领域或目标领域。在对抗训练过程中,模型首先提取术前oct轮廓图al和术后真实oct轮廓图real_bl配对数据的图像特征,之后分别送入判别器d1和域分类器c,对其进行损失计算并迭代判别器d1和域分类器c的网络参数,使得判别器d1能够辨别术后真实oct轮廓图real_bl和术后生成轮廓图fake_bl,而域分类器c无法识别术前oct轮廓图al的来源领域,最后固定判别器d1和域分类器c网络参数,由生成器g1生成准确的术后生成轮廓图fake_bl。
68.可选地,本实施例的判别器d1和域分类器c均为多尺度判别器。
69.具体地,在步骤s2中,通过眼科医生对术前oct图像a和术后oct图像b中的神经纤
维层内表面、内核层内表面、外核层内表面、椭圆体带以及rpe外表面进行描边得到术前oct轮廓图al和术后真实轮廓图real_bl。
70.更新判别器d1,可降低其损失函数计算得到的损失值,即判别器d1能准确区分由眼科医生标注得到的术后真实轮廓图real_bl和术后生成轮廓图fake_bl,对抗训练完成后的判别器d1却对术后真实轮廓图real_bl和术后生成轮廓图fake_bl区分困难,即说明术后生成轮廓图fake_bl拥有术后真实轮廓图real_bl的图像特征,可视为生成图像准确。本实施例在步骤s4.2中,将术前oct轮廓图al和术后生成轮廓图fake_bl拼接起来,得到negative_img_d1,再将negative_img_d1送入判别器d1,得到张量pred_fake_d1,判别器d1为其打上标签0,即判别器d1认为这张图是假的,计算pred_fake_d1的gan损失loss_d1_fake;将术前oct轮廓图al和术后真实oct轮廓图real_bl拼接起来,得到positive_img_d1,再将positive_img_d1送入判别器d1,得到pred_real_d1,判别器d1为其打上标签1,即判别器d1认为这张图是真的,计算pred_real_d1的gan损失loss_d1_real;将loss_d1_fake和loss_d1_real的gan损失相加,得到判别器损失loss_d1。
71.另外,更新域分类器c,降低其损失函数计算得到的损失值,即域分类器c能准确区分图像领域来源,对生成器g1生成的术后生成轮廓图fake_bl的领域进行判别,当训练优化后的域分类器c无法识别术后生成轮廓图fake_bl的领域,即表示生成器g1生成的术后生成轮廓图fake_bl学习到了各个目标领域中术后真实轮廓图real_bl的共同特征,也就是所要生成的目标特征。本实施例在步骤s4.3中,将术前oct轮廓图al和术后生成轮廓图fake_bl拼接起来,得到negative_img_c,再将negative_img_c送入域分类器c,得到张量pred_fake_c,域分类器c打上的标签不为其所在领域对应的标签,即域分类器c未判别出这张图所在正确的领域,计算pred_fake_c的gan损失loss_c_fake;将术前oct轮廓图al和术后真实oct轮廓图real_bl拼接起来,得到positive_img_c,再将positive_img_c送入域分类器c,得到pred_real_c,域分类器c打上其所在领域对应的标签,即域分类器c判别出这张图所在的领域,计算pred_real_c的gan损失loss_c_real;将loss_c_fake和loss_c_real的gan损失相加,得到域分类器损失loss_c。
72.此外,更新生成器g1,降低其损失函数计算得到的损失值,使其生成的图像足够真实,且拥有目标生成图像的主要特征。生成器g1包括全局生成器网络g1.1和局部增强网络g1.2,全局生成器网络g1.1的输入和输出的分辨率一致(如1024*512),局部增强网络g1.2的输出尺寸(2048*1024)是输入尺寸(1024*512)的4倍,即局部增强网络g1.2输出图像的高度和宽度均为输入图像的2倍;局部增强网络g1.2用于将全局生成器网络g1.1生成的图像的分辨率扩大,在训练时,将术前oct轮廓图al输入全局生成器网络g1.1,将全局生成器网络g1输出的图像输入局部增强网络g1.2。全局生成器网络g1.1的网络结构为u-net,负责图像特征的编码解码;局部增强网络g1.2则使模型可以生成分辨率更高的图像。
73.本实施例在步骤s4.4中,包括:
74.s4.4.1、获取步骤s4.2中的pred_real_d1的gan损失loss_d1_real;
75.s4.4.2、获取步骤4.3中的pred_fake_c的gan损失loss_c_fake;
76.s4.4.3、计算步骤s4.2中的pred_fake_d1和pred_real_d1的逐像素损失l1;
77.s4.4.3、计算步骤s4.3中的pred_fake_c和pred_real_c的逐像素损失l2;
78.s4.4.5、计算术前oct图像a和术后生成轮廓图fake_bl的vgg特征损失,记为loss_
g_vgg;
79.s4.4.6、将loss_d1_real、loss_c_fake、l1、l2和loss_g_vgg相加,得到生成器损失loss_g。
80.生成器g1的损失函数由gan损失、逐像素损失和vgg损失三部分组成,有利于模型参数优化。可选地,可使用mse函数、bce函数等计算gan损失。
81.因此,本实施例首先收集收集患者的术前oct图像a和配对的术后oct图像b,收集的图像包含多种眼底疾病,要求图像清晰且分辨率高,用以训练深度迁移学习模型——基于域适应的眼科oct术后轮廓图生成模型,并且采用医学专业处理过的数据集对该模型进行训练,使得优化后的模型权重参数能够带来更好的图像生成效果;本实施例是采用由糖网、rvo和amd的oct图像构成的三个数据集对模型进行训练的;然后将收集到的oct图像数据集进行分类并打上领域标签,之后进行oct轮廓图标注,并进行预处理操作,保留512*512的图像数据;接着对基于域适应的眼科oct术后轮廓图生成模型进行训练,将术后真实轮廓图real_bl经卷积神经网络提取特征后,送入判别器d1与域分类器c训练;术前oct轮廓图al分别输入生成器g1、判别器d1及域分类器c进行训练,并在验证集指标出现过拟合前停止迭代并保留各自模型权重。并且进行损失函数的计算,依据计算得到的损失函数值对模型的权重参数值进行调整,使其函数值最小,得到更小的损失函数结果以及优化后的模型权重,由此迭代生成器g1、判别器d1和域分类器c的网络参数,使生成器g1能准确生成oct术后轮廓图。本实施例融合深度学习和迁移学习,通过扩大训练数据规模,更准确地提取多种眼病oct图像的特征,改善术后oct轮廓图生成结果,有效提升模型预测能力。
82.实施例二
83.本实施例与实施例一的区别在于,在实施例一的基础上,本实施例还包括术前oct轮廓图生成模型
84.在步骤s2中,将术前oct图像a输入术前轮廓图生成模型,输出术前oct轮廓图al;术前轮廓图生成模型为生成对抗网络;术前轮廓图生成模型包括生成器g2和判别器d2。由术前轮廓图生成模型根据术前oct图像a生成的术前oct轮廓图al对基于域适应的眼科oct术后轮廓图生成模型进行训练,能够减轻标注的工作量。
85.在步骤s5中,将新拍摄的术前oct图像输入训练好的术前轮廓图生成模型后,输出相应的术前oct轮廓图。再将术前轮廓图生成模型输出的术前oct轮廓图输入训练好的基于域适应的眼科oct术后轮廓图生成模型的生成器g1,输出相应的术后生成oct轮廓图。
86.因此,本实施例的方法包括两个阶段,第一阶段,训练术前轮廓图生成模型,使术前轮廓图生成模型能够生成准确的术前oct轮廓图;第二阶段,训练基于域适应的眼科oct术后轮廓图生成模型,使基于域适应的眼科oct术后轮廓图生成模型能够根据术前oct轮廓图生成准确的术后oct轮廓图。
87.可选地,本实施例的术前轮廓图生成模型可采用经典pix2pix、pix2pixhd和spade等模型,实现术前oct图像到术前oct轮廓图的转换。
88.本实施例的其他步骤与实施例一相同,此处不再赘述。
89.实施例三
90.本实施例提出一种基于实施例一或实施例二的基于域适应的眼科oct术后轮廓图生成方法的系统,包括:
91.数据获取模块,用于获取不同眼底疾病的术前oct图像和术后oct图像以构成数据集;
92.分类模块,用于根据眼底疾病的种类将数据集分为不同领域;
93.轮廓图像获取模块,用于根据术前oct图像a,获得术前oct轮廓图al;根据与术前oct图像a相对应的术后oct图像b,获取术后真实轮廓图real_bl;
94.模型构建模块,用于构建基于域适应的眼科oct术后轮廓图生成模型,基于域适应的眼科oct术后轮廓图生成模型包括生成器g1、判别器d1和域分类器c,生成器g1用于根据术前oct图像a生成术后生成轮廓图fake_bl,判别器d1用于对术后生成轮廓图fake_bl和术后真实oct轮廓图real_bl进行判别,域分类器c用于对术后生成轮廓图fake_bl和术后真实oct轮廓图real_bl的领域进行判别;
95.损失函数构建模块,用于构建多目标损失函数;多目标损失函数包括生成器g1的损失函数、判别器d1的损失函数和域分类器c的损失函数;
96.训练模块,用于将术前oct轮廓图al和术后真实oct轮廓图real_bl构成的样本作为基于域适应的眼科oct术后轮廓图生成模型的输入,基于多目标损失函数对基于域适应的眼科oct术后轮廓图生成模型进行迭代训练,得到训练好的基于域适应的眼科oct术后轮廓图生成模型;
97.应用模块,用于将新拍摄的术前oct图像对应的术前oct轮廓图输入训练好的基于域适应的眼科oct术后轮廓图生成模型的生成器g1,得到相应的术后生成oct轮廓图。
98.综上,本发明实施例提供一种基于域适应的眼科oct术后轮廓图生成方法,其通过获得术前oct图像对应的术前oct轮廓图,根据术前oct轮廓图通过基于域适应的眼科oct术后轮廓图生成模型生成术后oct轮廓图,相比直接生成高分辨率、纹理信息复杂的术后oct图像,其技术难度明显降低,简单高效,且生成的轮廓图噪声极小,使生成的轮廓图的准确度高,利用术后oct轮廓图,即可测量部分关键的病理指标,并不需要术后oct图像辅助,医生也能一定程度上评估患者的术后恢复效果,实用性强;并且,不同眼底疾病的术前oct图像及其术后oct轮廓图之间内在联系具有一定相似性,本实施例利用迁移学习技术整合源领域和目标领域多个来源的数据,有效扩大训练数据规模,改善了深度学习模型训练效果。本实施例有效融合深度学习和迁移学习技术,充分利用术前oct图像及其特征,预测并生成患者的术后oct轮廓图,进而计算相关病理指标,有效辅助医生评估患者术后恢复效果。通过迁移学习,使本发明所提出的模型考虑多模态数据,训练数据来自多个领域,而非单一模态数据,综合考虑多个因素,使得生成的术后oct轮廓图更准确,特征细节更丰富。
99.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和替换,这些改进和替换也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1