一种战时野外智能救护系统的制作方法
1.本技术各实施例属于野外智能救护技术领域,特别是涉及一种战时野外智能救护系统。
背景技术:
2.军事训练是军事理论教育和作战技能教练的活动,它通常分为部队训练、院校训练和预备役训练。军事训练是军队平时的主要任务,是战备的重要方面,为了提高军队的实战能力时常会在大型的军事场地进行军事演习,军事演习有时会持续数天,严重考验着士兵的持续作战能力,然而长时间的军事训练演习难免出现意外和紧急状况,需要进行救护。
3.然而,现有的对于大型的军事训练演习中的救护方式存在以下的问题:缺乏专门的针对大型军事训练和演习设计的救护系统,在实际的操作中容易出现救援不及时的情况。为此,需要设计相应的技术方案解决存在的技术问题。
技术实现要素:
4.本技术实施例的目的在于提供一种战时野外智能救护系统,采用关键词文字、图像和/或语音进行识别检索等多种形式准确直观将其展示给经验欠缺非专业人员,指导其进行典型战创伤应急处置,提高战时应急条件下伤员存活率,可以根据伤员现场语音、影像数据的采集,智能化的辨别伤情,并选择出应急处置措施和处置步骤,引导伤员自主或互助完成急救操作,同时记录相关影像数据,在战后自动匹配和重构战场伤情应急救治的虚拟现实技能训练案例,最大程度模拟实战化条件提高日常训练的有效性,从而解决背景技术中的问题。
5.为了解决上述技术问题,本技术实施例提供的战时野外智能救护系统的技术方案具体如下:
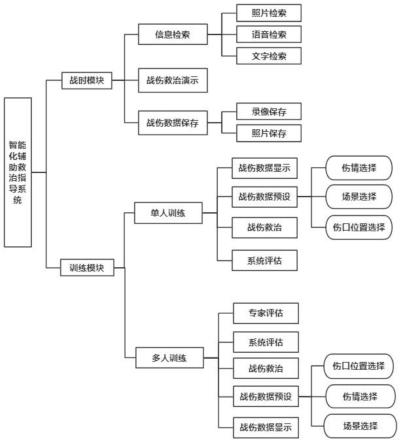
6.本技术实施例公开了一种战时野外智能救护系统,所述系统包括:
7.战时模块,用于士兵在多模态战伤数据库中,通过关键词文字、图像和/或语音进行识别检索,以对战伤信息进行检索匹配,根据检索匹配后的信息,获取精准的治疗方案;
8.若在作战时期,则通过采集到图像、语音、文字数据进行自动保存到多模态战伤数据库中,并通过智能交互眼镜采集到的数据回收到军事总部之后,数据传输到多模态战伤数据库中,通过智能化情景影像分析;
9.训练模块,所述训练模块包括训练参数设置,训练参数设置用于自主进行训练参数的选择,训练参数包括作战环境、战伤类别;虚拟战伤救治,虚拟战伤救治用于对训练参数里的虚拟人进行战伤救治。
10.在上述任一方案中优选的实施例,所述虚拟战伤救治,还包括以下步骤:
11.通过训练参数设置的设定,将战伤场景,战伤类别以及位置在虚拟人上进行虚拟构建出来;
12.士兵根据训练参数设置提供的救治工具对虚拟人进行模拟战伤救治操作,其中,
所述模拟战伤救治操作包括对虚拟人进行缩放或旋转,操控精准定位战伤细节并实施救治。
13.在上述任一方案中优选的实施例,所述智能化情景影像分析,其分析包括以下步骤:
14.步骤1:找到空间中一p点,通过kdtree找到离p点最近的n个点,计算n个点到p点的距离,将距离小于阈值的点归入q类;
15.步骤2:在q类中找到未搜索的点,重复步骤1。
16.步骤3:直到q类内所有点都被搜索完成,则完成,当场景内的平面点云被分割出来后,一个个的物体点云被抽取出来,通过欧式聚类方法设立阈值对场景物体进行分割,提取出场景的不同点云规模的物体。
17.在上述任一方案中优选的实施例,所述智能化情景影像分析,还包括以下步骤:
18.步骤31:当物体点云被分割出来后,通过计算将物体点云团进行投影,投影到2d平面,每点的像素坐标计算为:
19.clound.point[i].pixel_x=clound.indices[i]%width;
[0020]
clound.point[i].pixel_y=clound.indices[i]/width其中,point[i].pixel_x为x坐标,point[i].pixel_y为y坐标,indices[i]为像素点索引值,width为图像宽度;
[0021]
步骤32:当将物体点云投影到像素坐标后,通过比较点云在像素坐标坐标轴方向上的最大值和最小值,获得物体点云在像素坐标下的2d包围框;
[0022]
步骤33:将物体点云的反投影二维包围盒与目标检测算法所输出的外接矩形包围盒进行匹配相似度计算,记录与目标检测识别出物体最相似的物体点云,生成带有标签的3d目标物体虚拟对象模型,并进行虚拟对象模型和真实环境的叠加,其中,所述相似度计算采用iou、边框中心距离和尺寸差距作为匹配相似度的计算指标。
[0023]
在上述任一方案中优选的实施例,所述iou用于表示模型产生的目标区域和原来标记真实区域的重叠率,即检测边框与真实边框的交集比上检测边框与真实边框的并集,计算公式为:
[0024][0025]
在上述任一方案中优选的实施例,所述边框中心距离,其计算方法包括以下步骤:
[0026]
通过采用两边框中心p1,p2的距离描述距离的相似性,通过尺寸差距来描述大小相似性,其中,两边框相似性,其中,两边框匹配其中,x代表p点横坐标和p点纵坐标。
[0027]
在上述任一方案中优选的实施例,所述虚拟对象模型和真实环境的叠加,其叠加方法包括以下步骤:
[0028]
步骤331:从视频流中提取标识经过投影后的四边形区域以及四边形区域内的特征点,根据当前特征点位置和运动方向调整追踪窗口的大小和位置,若标识可见,则进入步
骤332;若标识不可见,但待注册区域内四个以上非共线特征点追踪成功,则进入步骤333,否则置当前帧的三维变换矩阵与前一帧相同,且则进入步骤334;
[0029]
步骤332:整个标识可见,直接根据标识投影计算三维变换矩阵和摄像机内参矩阵,并进入步骤334;
[0030]
步骤333:利用平面间单应性关系以及上一帧变换矩阵计算当前三维变换矩阵,若摄像机内部参数不发生变化,则进入步骤334;
[0031]
步骤334:利用变换矩阵实现三维注册,并进入步骤331。
[0032]
在上述任一方案中优选的实施例,所述虚拟对象模型和真实环境的叠加,其叠加方法还包括以下步骤:
[0033]
步骤3311:确保每个特征点位于多条直线的交点上;
[0034]
步骤3312:采用基于全局单应性矩阵的虚实配准方法,利用前一帧所对应的全局单应性矩阵对初始图像作变换,并将变换后的图像与当前图像做特征匹配;
[0035]
步骤3313:建立当前帧与初始帧之间的单应性关系。
[0036]
在上述任一方案中优选的实施例,所述虚拟对象模型和真实环境的叠加,其叠加方法还包括以下步骤:
[0037]
步骤33121:对图像特征点进行提取;
[0038]
步骤33122:通过图像特征描述子实现图像特征点与局部地图点的有效匹配;
[0039]
步骤33123:计算地图点重投影误差,利用光束平差法进行相机位姿的优化,实现每帧图像采集时刻相机的跟踪和定位。
[0040]
在上述任一方案中优选的实施例,所述步骤33123中,若跟踪定位失败,则基于词袋模型利用重定位方法找到与当前帧描述最为相近的关键帧,将该关键帧与当前帧进行特征点匹配与位姿估计。
[0041]
与现有技术相比,本技术实施例的战时野外智能救护系统,采用关键词文字、图像和/或语音进行识别检索等多种形式准确直观将其展示给经验欠缺非专业人员,指导其进行典型战创伤应急处置,提高战时应急条件下伤员存活率,可以根据伤员现场语音、影像数据的采集,智能化的辨别伤情,并选择出应急处置措施和处置步骤,引导伤员自主或互助完成急救操作,同时记录相关影像数据,在战后自动匹配和重构战场伤情应急救治的虚拟现实技能训练案例,最大程度模拟实战化条件提高日常训练的有效性。
附图说明
[0042]
此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一组件分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。后文将参照附图以示例性而非限制性的方式详细描述本技术的一些具体实施例。附图中相同的附图标记标示了相同或类似的组件件或组件分,本领域技术人员应该理解的是,这些附图未必是按比例绘制的,在附图中:
[0043]
图1为本技术实施例战时野外智能救护系统的流程示意图。
[0044]
图2为本技术实施例战时野外智能救护系统的救治专家知识库示意图。
[0045]
图3为本技术实施例战时野外智能救护系统的投影匹配结果示意图。
[0046]
图4为本技术实施例战时野外智能救护系统的点云语义融合结果示意图。
[0047]
图5为本技术实施例战时野外智能救护系统的遮挡条件下的角点跟踪三维注册流程示意图。
[0048]
图6为本技术实施例战时野外智能救护系统的orb-slam2-rgbd模式框架示意图。
[0049]
图7为本技术实施例战时野外智能救护系统的基于语义深度图的稀疏点云虚实融合流程示意图。
[0050]
图8为本技术实施例战时野外智能救护系统的虚拟对象模型和真实环境的叠加方法流程示意图。
具体实施方式
[0051]
为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本技术一组件分的实施例,而不是全组件的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本技术保护的范围。
[0052]
实施例
[0053]
如图1所示,本技术实施例提供了一种战时野外智能救护系统,所述系统包括:
[0054]
战时模块,用于士兵在多模态战伤数据库中,通过关键词文字、图像和/或语音进行识别检索,以对战伤信息进行检索匹配,根据检索匹配后的信息,获取精准的治疗方案;
[0055]
若在作战时期,则通过采集到图像、语音、文字数据进行自动保存到多模态战伤数据库中,并通过智能交互眼镜采集到的数据回收到军事总部之后,数据传输到多模态战伤数据库中,通过智能化情景影像分析;
[0056]
训练模块,所述训练模块包括训练参数设置,训练参数设置用于自主进行训练参数的选择,训练参数包括作战环境、战伤类别;虚拟战伤救治,虚拟战伤救治用于对训练参数里的虚拟人进行战伤救治。
[0057]
在本发明实施例所述的战时野外智能救护系统中,采用关键词文字、图像和/或语音进行识别检索等多种形式准确直观将其展示给经验欠缺非专业人员,指导其进行典型战创伤应急处置,提高战时应急条件下伤员存活率,可以根据伤员现场语音、影像数据的采集,智能化的辨别伤情,并选择出应急处置措施和处置步骤,引导伤员自主或互助完成急救操作,同时记录相关影像数据,在战后自动匹配和重构战场伤情应急救治的虚拟现实技能训练案例,最大程度模拟实战化条件提高日常训练的有效性。
[0058]
如图1和图2所示,所述虚拟战伤救治,还包括以下步骤:
[0059]
通过训练参数设置的设定,将战伤场景,战伤类别以及位置在虚拟人上进行虚拟构建出来;
[0060]
士兵根据训练参数设置提供的救治工具对虚拟人进行模拟战伤救治操作,其中,所述模拟战伤救治操作包括对虚拟人进行缩放或旋转,操控精准定位战伤细节并实施救治。
[0061]
在本发明实施例所述的战时野外智能救护系统中,训练参数设置,士兵自主进行训练参数的选择,包括作战环境、战伤类别等,野战环境可选择包括热带雨林作战、沙漠作战等常见不同作战环境,同时野战环境还可以进行白天或者黑夜的模式切换,战场伤类类
别根据系统内部建立的伤类数据库,可以选择常见伤种,同时根据不同的战伤类别可进一步进行伤口位置的设定;虚拟战伤救治,主要由士兵对系统里面的虚拟人进行战伤救治,前期通过参数的设定,已经将战伤场景,战伤类别以及位置在虚拟人上进行虚拟构建出来,士兵可以根据系统提供的救治工具对虚拟人进行模拟战伤救治操作,可以对虚拟进行缩放、旋转等操控精准定位战伤细节并实施救治,同时系统也提供了救治方案的提示,通过图片、文字任意一种方式呈现给士兵,辅助其更好的进行战伤救治。
[0062]
在本发明实施例所述的战时野外智能救护系统中,所述战时野外智能救护系统还包括系统救治评分,系统评分的标准依据是多维度,即根据系统内部建立的环境难度、动作标准、完成时间、工具使用、协助能力、急救原则六个维度进行综合客观评分,同时支持成绩数据导出。环境难度为,基于不同场景环境的考核,可评估受训人员在恶劣环境下的紧急应变能力;动作标准为,基于不同伤情救治的考核,可评估受训人员自身各项战场救治技术的掌握熟练度;完成时间为,基于救治的成功率与救治时间成反比,可评估受训人员战场救治技术的掌握熟练度。工具使用为,基于正确的使用救治工具才能达到救治的效果,可评估受训人员的判断能力及战场救治技术的掌握度;协助能力为,基于多人之间的配合是否到位,可评估受训人员的分析能力以及团队协作能力;急救原则为,基于战场救治实施的先后原则,评估受训人员的判断能力、团队协助能力以及战场救治能力。通过多维度的客观及主观打分,综合评估参训人员的战场救治水平及综合能力。
[0063]
在本发明实施例中,所述智能化情景影像分析,其分析包括以下步骤:
[0064]
步骤1:找到空间中一p点,通过kdtree(k-dimensional树的简称)找到离p点最近的n个点,计算n个点到p点的距离,将距离小于阈值的点归入q类;
[0065]
步骤2:在q类中找到未搜索的点,重复步骤1。
[0066]
步骤3:直到q类内所有点都被搜索完成,则完成,当场景内的平面点云被分割出来后,一个个的物体点云被抽取出来,通过欧式聚类方法设立阈值对场景物体进行分割,提取出场景的不同点云规模的物体。
[0067]
在本发明实施例所述的战时野外智能救护系统中,通过采用上述分析方法,可以快速分割物体点云。
[0068]
如图3和图4所示,所述智能化情景影像分析,还包括以下步骤:
[0069]
步骤31:当物体点云被分割出来后,通过计算将物体点云团进行投影,投影到2d平面,每点的像素坐标计算为:
[0070]
clound.point[i].pixel_x=clound.indices[i]%width;
[0071]
clound.point[i].pixel_y=clound.indices[i]/width;其中,point[i].pixel_x为x坐标,point[i].pixel_y为y坐标,indices[i]为像素点索引值,width为图像宽度;
[0072]
步骤32:当将物体点云投影到像素坐标后,通过比较点云在像素坐标坐标轴方向上的最大值和最小值,获得物体点云在像素坐标下的2d包围框;
[0073]
步骤33:将物体点云的反投影二维包围盒与目标检测算法所输出的外接矩形包围盒进行匹配相似度计算,记录与目标检测识别出物体最相似的物体点云,生成带有标签的3d目标物体虚拟对象模型,并进行虚拟对象模型和真实环境的叠加,其中,所述相似度计算采用iou、边框中心距离和尺寸差距作为匹配相似度的计算指标。
[0074]
如图3和图4所示,所述iou用于表示模型产生的目标区域和原来标记真实区域的
重叠率,即检测边框与真实边框的交集比上检测边框与真实边框的并集,计算公式为:
[0075][0076]
如图3和图4所示,所述边框中心距离,其计算方法包括以下步骤:
[0077]
通过采用两边框中心p1,p2的距离描述距离的相似性,通过尺寸差距来描述大小相似性,其中,两边框尺寸匹配通过将所述相似度计算采用iou、边框中心距离和尺寸差距作为匹配相似度的计算指标,可以描述物体点云投影框与目标检测结果包围框的匹配相似度,将点云分割结果与目标检测结果进行融合其中,x代表p点横坐标和p点纵坐标。
[0078][0079]
如图5和图8所示,所述虚拟对象模型和真实环境的叠加,其叠加方法包括以下步骤:
[0080]
步骤331:从视频流中提取标识经过投影后的四边形区域以及四边形区域内的特征点,根据当前特征点位置和运动方向调整追踪窗口的大小和位置,若标识可见,则进入步骤332;若标识不可见,但待注册区域内四个以上非共线特征点追踪成功,则进入步骤333,否则置当前帧的三维变换矩阵与前一帧相同,且则进入步骤334;
[0081]
步骤332:整个标识可见,直接根据标识投影计算三维变换矩阵和摄像机内参矩阵,并进入步骤334;
[0082]
步骤333:利用平面间单应性关系以及上一帧变换矩阵计算当前三维变换矩阵,若摄像机内部参数不发生变化,则进入步骤334;
[0083]
步骤334:利用变换矩阵实现三维注册,并进入步骤331。
[0084]
在本发明实施例所述的战时野外智能救护系统中,为达到虚拟对象模型和真实环境的叠加稳定融合的效果,利用多摄像头实时扫描物理空间,根据摄像头采集的图像数据进行实时计算得到实现三维场景的重构。主要的步骤为:
[0085]
(1)摄像头校正,由于摄像头出厂时存在扭曲,为得到精确的数据需要在使用前基于棋盘格的各个姿态进行拍照校正。
[0086]
(2)图像对齐,因为两个摄像头的位置不同,各自看到的场景有偏差,需要对相同的场景部分的左右图像匹配,形成深度图。
[0087]
(3)三维渲染,根据摄像头采集得到实际场景数据,根据相机姿态,通过迭代对齐算法,跟踪得到当前相机与最初相机的位置与姿态变化,将姿态已知情况下的深度数据融合到三维空间,采用特征跟踪法和空间定位法相结合的方式,实现真实场景和虚拟物体间的准确融合,基准标志法实现简单,但在多个基准标志遮挡情况下,依然会出现误差,相对而言,使用特征法更能有效解决遮挡问题。
[0088]
如图6所示,所述虚拟对象模型和真实环境的叠加,其叠加方法还包括以下步骤:
[0089]
步骤3311:确保每个特征点位于多条直线的交点上;
[0090]
步骤3312:采用基于全局单应性矩阵的虚实配准方法,利用前一帧所对应的全局单应性矩阵对初始图像作变换,并将变换后的图像与当前图像做特征匹配;
[0091]
步骤3313:建立当前帧与初始帧之间的单应性关系。
[0092]
在本发明实施例所述的战时野外智能救护系统中,通过采用采用基于全局单应性矩阵的虚实配准方法,利用前一帧所对应的全局单应性矩阵对初始图像作变换,并将变换后的图像与当前图像做特征匹配,可以保证算法的有效性,在避免误差积累问题的同时,有效提高了特征点匹配的正确性,最大限度保证了算法的健壮性。
[0093]
如图6所示,所述虚拟对象模型和真实环境的叠加,其叠加方法还包括以下步骤:
[0094]
步骤33121:对图像特征点进行提取;
[0095]
步骤33122:通过图像特征描述子实现图像特征点与局部地图点的有效匹配;
[0096]
步骤33123:计算地图点重投影误差,利用光束平差法进行相机位姿的优化,实现每帧图像采集时刻相机的跟踪和定位,若跟踪定位失败,则基于词袋模型利用重定位方法找到与当前帧描述最为相近的关键帧,将该关键帧与当前帧进行特征点匹配与位姿估计。
[0097]
在本发明实施例所述的战时野外智能救护系统中,orb-slam2方法将地图点、关键帧等场景信息存储在地图中,进而通过地图元素基于图优化进行全局位姿优化,算法地图由关键帧、地图点、共视图和生成树构成。关键帧能够记录邻近帧绝大多数的信息,只有帧图像特征点信息变换大于阈值时,才会将当前帧记录为关键帧。地图点是由图像提取的特征点的三维世界坐标点组成的。共视图则是用来记录不同关键帧之间的关系,其可以描述不同关键帧可以看到多少相同的地图点。在共视图中,每个关键帧是一个节点,如果两个关键帧之间的共视地图点数量大于门限值,则在两个节点之间建立边,边的权重是两关键帧共同可见的地图点的个数。生成树是共视图的子集,其保留了共视图的所有节点(即关键帧),但是每个节点只保留和最多共视地图点关键帧之间的边。
[0098]
在本发明实施例所述的战时野外智能救护系统中,算法跟踪线程的主要功能为估计每帧的相机位姿并判断该帧是否是关键帧。其输入为每一帧的相机采集图像。线程首先对图像特征点进行提取,然后通过特征描述子实现图像特征点与局部地图点的有效匹配。然后计算地图点重投影误差,利用光束平差法进行相机位姿的优化,实现每帧图像采集时刻相机的跟踪和定位。如果跟踪定位失败,则基于词袋模型利用重定位方法找到与当前帧描述最为相近的关键帧,将该关键帧与当前帧进行特征点匹配与位姿估计。
[0099]
在本发明实施例所述的战时野外智能救护系统中,基于语义深度图的稀疏点云遮挡算法的传感器数据图像帧就包含了各类物体信息,所以以深度学习的语义识别优势结合虚实遮挡算法提供的位置信息就能够提取出场景的语义信息,建立场景语义地图。考虑到增强现实设备的便携性要求,增强现实设备很难搭载高性能的gpu,而深度学习中的点云语义分割或者图像语义分割segnet,mask-rcnn等方法在没有gpu加速的情况下耗时较长,无法保证算法的实时性要求。本发明通过步骤33123,使得算法的实时性获得了保证,但是图像目标检测方法只能够获取二维图像语义信息,丢失了深度信息,通过点云物体分割将三维数据投影到二维空间内,降低了目标检测算法输出信息为平面矩形包围框所带来的语义误差,通过语义信息,标识场景内的动态物体,提取动态物体上的特征点。
[0100]
如图7所示,当语义数据库更新完成后,系统记录获得的局部语义点云,由于增强
现实穿戴设备资源有限,对于场景而言,如果将场景所有的稠密点云进行保存,代价较大。应用只对语义点云信息较为关心,对于场景的其他稠密点云信息而言,应用其实只需要获取其表面情况,便于应用与环境的交互。只保留局部语义的稠密点云,对于场景背景采取贪心三角网格化的方式,将全局海量稠密点云数据生成为单一的网格。
[0101]
最后应说明的是:以上各实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述各实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中组件分或者全组件技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1