一种基于动态加权聚合的联邦学习负荷预测方法与流程
1.本发明涉及电力系统短期负荷预测方法及分布式及机器学习领域,属于基于联邦学习的优化技术及分布式负荷预测技术,特别涉及一种基于动态加权聚合的联邦学习负荷预测方法。
背景技术:
2.随着电力系统数字化的发展,电力系统要处理的数据量呈指数递增,精确的负荷预测能够协助电能调度,有利于维持居民区的电力稳定。传统的集中式电力负荷预测方法,由于数据量的增大,对服务器造成较大的负担,同时存在数据的隐私泄露问题。为解决分布式训练中的数据隐私等问题,部分研究者提出了联邦学习框架。
3.联邦学习是一种新型的面向分散式多用户场景的机器学习框架,在模型训练过程中,各参与用户的原始数据不需要进行共享,因此有效保护了用户的数据隐私安全。联邦学习利用分散在各参与方的数据集,在参与方本地进行局部模型训练,将训练好的局部模型参数上传至服务端,在服务端进行模型聚合,生成全局模型,该全局模型可以在各数据参与方之间共享和部署使用。近年来,联邦学习逐渐被电力系统研究者们尝试应用。例如,公开文献《基于生成对抗网络和联邦学习的非侵入式负荷分解方法》提出了一种基于联邦学习的网络模型实施方案,采用云边协同的方式对模型进行训练,同时使用基于生成对抗网络的负荷分解模型,在保护用户数据隐私的情况下,有效进行非侵入式负荷分解。公开文献《electrical load forecasting using edge computing and federated learning》第一次使用联邦学习进行家庭负荷的预测,采用分布式训练方式,同时不干涉用户隐私。
4.然而,由于电力负荷数据存在一定波动性,且各采集点的数据质量不一,局部模型的训练效果也参差不齐,直接将局部模型在服务端进行聚合可能存在聚合模型精度下降等问题。为了解决该问题,一些研究者提出了针对特定设备进行模型清洗的解决方法,但是这些方法无法为其他特征相似的边缘设备所适用。解决该问题需要从各局部模型中找出不利于全局模型训练进度的脏模型,一定程度上降低脏模型对全局模型的影响。
技术实现要素:
5.本发明要解决的技术问题是,克服现有技术中的不足,提供一种基于动态加权聚合的联邦学习负荷预测方法。
6.为解决技术问题,本发明的解决方案是:
7.提供一种基于动态加权聚合的联邦学习负荷预测方法,包括以下步骤:
8.(1)在云端服务器和多个边缘计算装置分别搭建统一的神经网络模型,使用相同的模型参数进行初始化;获取各边缘计算装置所在居民区的用电数据与气象数据,进行预处理后作为本地数据用于各自神经网络模型即局部模型的输入;
9.(2)在各边缘计算装置上,分别利用相应的本地数据对其局部模型进行训练;然后利用服务器所提供的验证集,计算各局部模型的准确度;
10.(3)向服务器上传各局部模型的参数变化向量和准确度的数据;
11.(4)对于所有参与训练的局部模型,计算其参数变化向量之间的相似度;然后生成本轮相似度矩阵,并计算各局部模型之间的一致度向量;
12.(5)基于局部模型对服务器验证集的准确度和各局部模型之间的一致度,在服务器上进行加权的聚合处理,得到全局神经网络模型即全局模型;
13.(6)服务器将全局模型下发至各边缘计算装置,再利用本地数据对全局模型进行训练,获得新一轮的局部模型更新结果;然后利用服务器所提供的验证集,重新计算各局部模型的准确度;
14.(7)重复步骤(3)-(6),直到在执行步骤(6)前检测到训练已经达到预设的轮数或全局模型在验证集上的精度达到预设精度,则跳过步骤(6),执行步骤(8);
15.(8)以步骤(5)生成的模型作为用于负荷预测的全局预测模型,服务器将全局预测模型下发至所有边缘计算装置,分别执行各自所在居民区的负荷预测任务。
16.与现有技术相比,本发明的有益效果是:
17.1、本发明提供的联邦学习负荷预测方法,在分布式电力负荷预测的场景中,能够同时实现保护电力用户隐私与电力负荷高精度预测,解决了现有技术中不能有效避免局部模型可能训练出的脏模型的问题。在训练中对聚合过程进行动态加权,基于每轮局部模型针对服务端验证集的准确度与局部模型之间的一致度,提供了针对联邦学习中的数据异构问题的有效解决方案,加快全局模型训练的收敛。
18.2、本发明利用局部模型网络参数更新量之间的余弦相似度,表征了局部模型之间的参数更新方向相似性,基于局部模型的相似度矩阵,定义了利用局部模型对全局模型进行更新时的一致度矩阵与一致度向量,依据一致度向量对局部模型的权重赋值,一定程度上确保了全局模型的更新方向与多数局部模型的更新方向相同,提高全局模型的收敛速度。
19.3、本发明基于每轮局部模型针对服务端验证集的准确度与局部模型之间的一致度,提出基于局部模型模型一致度与准确度的动态加权聚合方式,对局部模型的权重进行动态更新,确保各局部模型数据得到公平训练,与传统的基于局部数据集数量的聚合权重设置相比,实现了更合理的数据利用与权重分配。
20.4、本发明通过相似度矩阵与一致度矩阵,获得局部模型的训练情况,在保护局部模型数据隐私的情况下,展示局部模型训练结果差异,提供有效的局部数据质量的反馈给服务器。
21.5、本发明不仅可以用于负荷预测应用场景,也可以应用其他通用的联邦学习场景。
附图说明
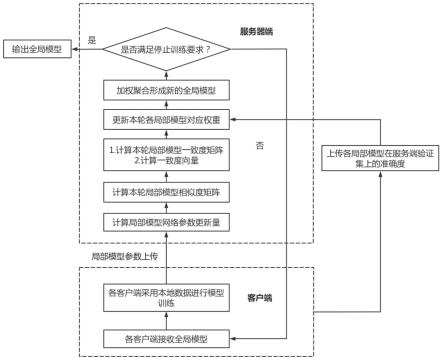
22.图1为本发明预测方法的架构图;
23.图2为本发明的模型训练流程图;
24.图3为本发明的模型实施方案模型结构图。
具体实施方式
25.针对现有联邦学习负荷预测方法在聚合全局模型时未全面评判局部模型优劣的问题,提出一种基于动态加权聚合的联邦学习负荷预测方法。由边缘计算装置采用本地数据进行神经网络训练,获得的网络参数变化向量上传至云端服务器,进行两两相似度计算,生成相似度矩阵。利用相似度矩阵,计算本轮训练中局部模型之间的一致度向量。基于每轮局部模型针对服务端验证集的准确度与局部模型之间的一致度,对不同局部模型的网络参数变化进行加权,实现局部模型清洗的效果,云端服务器将更新后的全局模型再下发至边缘计算装置,重复上述步骤,直至服务器达到预设训练轮数。本发明中基于联邦学习的预测方法的架构图和训练流程图分别如图1、图2所示。
26.具体地,本发明中基于动态加权聚合的联邦学习负荷预测方法,包括以下步骤:
27.(1)在云端服务器和多个边缘计算装置分别搭建统一的神经网络模型,使用相同的模型参数进行初始化;
28.本发明所述神经网络模型采用了卷积与长短期记忆神经网络相结合的神经网络(convlstm),同时具备卷积网络的特征提取与lstm的时序预测能力。具体的网络结构均可直接采用现有技术,本发明不做特别要求。
29.获取各边缘计算装置所在居民区的用电数据与气象数据,进行预处理后作为本地数据用于各自神经网络模型即局部模型的输入。对数据的预处理具体包括:对各边缘计算装置所处区域的负荷数据进行处理,采用平均值填充法对缺失值进行补充。例如,可采用该缺失值前方3个与后方3个数据的平均值进行填补。由于负荷数据与气象数据存在不同的量纲,需要将不同类型的数据先进行归一化,再作为神经网络的输入。
30.(2)在各边缘计算装置上,分别利用相应的本地数据对其局部模型进行训练;然后利用服务器所提供的验证集,计算各局部模型的准确度。
31.首先利用本地数据对从服务器获得的全局模型进行训练;在第t轮训练中,编号为i的局部模型在服务器验证集上的准确度为acc
it
,其取值范围为[0,1],具体的计算方式如公式(1)所示:
[0032][0033]
式中,load
predict,i
与load
real,i
分别表示第i个局部模型在服务器验证集上的预测负荷结果向量与对应负荷精确值向量,mean()函数表示求取括号中向量的平均值。
[0034]
(3)向服务器上传各局部模型的参数变化向量和准确度的数据;
[0035]
局部模型的参数变化向量是指该局部模型在当前轮次的本地训练中所获得的参数更新量,是由训练完毕后的局部模型参数值减去训练前模型参数值得到。
[0036]
全局模型和局部模型的模型参数的数据类型为字典,表示神经网络中的各神经元对应的参数值,主要包括:卷积层、lstm层以及全连接层。由于全局模型与局部模型拥有相同的网络结构,因此,可以对其中相同位置的神经元参数值进行求差,获得本次局部模型参数更新值;示例的伪代码如下:
[0037][0038]
[0039]
其中mlocal
1i
表示第一轮的第i个客户端训练完毕后的局部模型参数字典,l
1i
表示第1轮的第i个客户端训练完毕后的局部模型参数更新字典,两个字典中的键相同,以上代码中,使用参数name对字典进行循环索引。m0为系统初始化后第一次下发到客户端的全局模型参数字典。
[0040]
(4)对于所有参与训练的局部模型,计算其参数变化向量之间的相似度;然后生成本轮相似度矩阵,并计算各局部模型之间的一致度向量;
[0041]
根据各局部模型在当前轮次训练中的参数更新量,计算各局部模型的参数更新向量两两之间的余弦相似度;生成所有参与训练的局部模型的本轮相似度矩阵,利用相似度矩阵计算各局部模型之间的一致度向量;
[0042]
假设n为所有参与训练的局部模型集合,n为n中包含的局部模型个数;序号为p的局部模型与序号为r的局部模型的当前迭代中,经过本地数据进行训练之后的本地更新表示为:δl
p
和δlr,其中:l
pi
表示模型序号为p的局部模型更新δl
p
的第i个参数的更新值,l
ri
表示模型序号为r的局部模型更新δlr的第i个参数的更新值,m为神经网络参数个数;则依据余弦相似度算法,计算各局部模型两两之间的更新相似度,即:
[0043][0044]
公式(2)计算出的余弦相似度取值范围为[-1,1],该值越接近1,说明两个局部模型的更新梯度相似度越高,反之,该值越接近-1,说明两个局部模型的更新梯度相似度越低,甚至更新梯度呈相反方向。
[0045]
相似度矩阵表示为s,如公式(3)所示,其中的元素均由公式(2)获得:
[0046][0047]
根据公式(3)计算获得各局部模型参与聚合时的权重,用于在服务器上进行模型的加权聚合处理;
[0048]
将相似度矩阵中的元素分类,分类标准如公式(4)所示:
[0049][0050]
其中,任意两个局部模型δl
p
和δlr的分类结果用g(δl
p
,δlr)表示;当元素分类为1时,表示该相似度有效,对应的两个局部模型的一致度增加;当元素分类为0时,表示该相似度无效,对应的两个局部模型的一致度不变;
[0051]
分类后得到一致度矩阵表示为g,如公式(5)所示:
[0052][0053]
将一致度矩阵中各列相加,得到所有局部模型一致度的一致度向量表示为k,任意局部模型i的一致度表示为ki,为一致度向量的第i个元素,如公式(6)所示:
[0054][0055]
(5)基于局部模型对服务器验证集的准确度和各局部模型之间的一致度,在服务器上进行加权的聚合处理,得到全局神经网络模型(即全局模型);
[0056]
在训练轮数为t时,基于各局部模型的一致度向量,以及各局部模型在服务器验证集上表现出的精确度,得到全局模型更新方式,如公式(7)所示:
[0057][0058]
其中,m
t
表示第t+1轮聚合之前的全局模型网络参数值;δl
t+1i
表示第i个局部模型在第t+1轮本地训练更新后的参数更新值;m
t+1
表示第t+1轮聚合之后的全局模型网络参数值,epo为设定最大的训练轮数,n为参与聚合的局部模型数;acc
it+1
为第t+1轮本地训练之后,第i个局部模型在服务器验证集上的准确度;k
it+1
为第t+1轮本地训练之后,第i个局部模型的一致度值;
[0059]
本发明提出基于局部模型一致度与准确度的动态加权聚合方式(fed-simmatch)。在全局模型训练的整个过程中,一致度对权重的影响逐渐降低,准确度对权重的影响逐渐升高,使得全局模型参数在训练前期能快速适应多客户端场景,在训练后期能达到更高的精确度。
[0060]
联邦学习的fedmatch聚合算法基于局部模型在服务器验证数据集上的准确度对模型聚合过程进行加权,然而这种方法仅能在服务器中反映各客户端的模型准确度,未考虑客户端之间的模型一致性,导致模型训练前期受到个别准确度高的客户端影响较大,无法快速适应多数客户端的数据特征,同时可能导致训练出的全局模型对验证集存在过拟合风险。
[0061]
(6)服务器将全局模型下发至各边缘计算装置,再利用本地数据对全局模型进行训练,获得新一轮的局部模型更新结果;然后利用服务器所提供的验证集,重新计算各局部模型的准确度;
[0062]
(7)重复步骤(3)-(6),直到在执行步骤(6)前检测到训练已经达到预设的轮数或全局模型在验证集上的精度达到预设精度,则跳过步骤(6),执行步骤(8);
[0063]
(8)以步骤(5)生成的模型作为用于负荷预测的全局预测模型,服务器将全局预测模型下发至所有边缘计算装置,各自分别执行所在居民区的负荷预测任务。
[0064]
在不泄露本地数据隐私的前提下,各局部模型参与了全局模型的训练过程,同时
获得了精确度和泛化性更高的全局模型以用于负荷预测。
[0065]
更为具体的应用示例:
[0066]
在本示例的方案中,对10个居民区采用本方法的局部模型进行负荷预测,本地数据为居民区用电数据与气象数据。居民区负荷数据时间间隔为15min,一天中负荷记录点为96个,气象数据为当天最高温度、最低温度与平均湿度。模型输入为前一天的负荷数据与待预测当天的气象数据(根据天气预报获得),共99个输入数据,模型输出数据为后一天的全天负荷数据,共96个输出数据。
[0067]
局部模型与全局模型的网络结构为卷积与长短期记忆神经网络相结合的网络(convlstm),模型结构如图3所示,其中,时序卷积能提取输入数据特征,长短期记忆神经网络能对长时间序列进行准确预测。
[0068]
首先对10个局部模型采用本地数据训练1轮模型,获得第一轮局部模型集合;然后采用本轮局部模型对服务端验证集进行预测,根据公式(6),获得本轮局部模型准确度如表1所示。
[0069]
表1第一轮训练个局部模型在服务端验证集上的准确度
[0070][0071]
各局部模型在本轮本地训练中获得了参数更新,其参数更新值为训练完毕后的局部模型参数值减去训练前接收的全局模型参数值。
[0072]
局部模型与全局模型的神经网络参数的数据类型均为字典,表示神经网络中的各神经元对应的参数值,主要包括:卷积层、lstm层以及全连接层。由于全局模型与局部模型拥有相同的网络结构,因此,可以对其中相同位置的神经元参数值进行求差,获得本次局部模型参数更新值,伪代码如下:
[0073][0074][0075]
其中mlocal
1i
表示第一轮的第i个局部模型训练完毕后的局部模型参数字典,m0为系统初始化后第一次下发到局部模型的全局模型参数字典,在本实施方案中,初始化网络为pytorch默认初始结果。
[0076]
将模型参数更新结果与各局部模型准确度上传至服务端。其次,根据公式(2),在服务器上计算本轮局部模型更新结果之间的相似度矩阵s。
[0077][0078]
依据本轮相似度矩阵s,根据公式(3),获得本轮局部模型更新结果的一致度矩阵g。
[0079][0080]
依据本轮一致度矩阵g,根据公式(5)计算获得本轮局部模型更新结果的一致度向量k。
[0081]
k=[9,8,8,1,4,6,7,8,8,9]
t
[0082]
最后,在服务器上对全局模型进行更新,预设训练轮数epo为500,根据公式(7)更新结果如下:
[0083][0084]
进行完毕本轮全局模型更新后,将全局模型的参数下发至10个局部模型,局部模型继续采用本地数据进行1轮模型训练,获得第二轮局部模型集合,重复上述全局模型权重影响因素计算及更新步骤,直到达到预设训练轮数。
[0085]
达到预设训练轮数epo或全局模型在验证集上的精确度达到97%后,云端服务器将最终获得的全局模型下发至各局部模型,在各局部模型进行负荷预测任务。
[0086]
本发明的各局部模型在不泄露本地数据隐私的前提下,参与了全局模型的训练过程,同时获得了精确度和泛化性更高的全局模型,用于负荷预测。本模型训练方法不仅可以用于负荷预测应用场景,也可以应用其他通用的联邦学习场景。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1