一种基于神经网络架构搜索技术的对话文本情景划分方法
1.本发明涉及自然语言处理技术领域,尤其涉及一种基于神经网络架构搜索技术的对话文本情景划分方法。
背景技术:
2.随着计算机网络的发展,一类以对话为主体的文本数据逐渐增多,如社交聊天、客服对话、医患诊断、ai问答等。通过对对话文本进行建模并其按照情景进行划分,能够更好地理解对话文本中的语义信息,对许多下游任务都能提供良好的支持。对话文本情景划分有着十分广阔的应用前景,并已经成为自然语言处理领域的研究热点。
3.作为自动机器学习的子领域之一,神经网络架构搜索是一种针对特定任务来设计的用于自动搜索网络模型架构的技术。神经网络架构搜索技术具有十分广阔的应用价值与研究意义,近年来得到了研究人员的广泛关注,并取得了一定的研究进展。搜索空间、搜索策略、评估是评估神经网络架构搜索技术最重要的三个方向,其中,搜索空间定义了网络架构的基本单元或者操作方式,而搜索策略则定义了从搜索空间中搜索一个完整的子架构的具体实现方法,最后评价策略负责对搜索到的子架构的最终表现进行打分,并将得分结果返回给搜索策略,指导其进行下一步的搜索过程。
4.强化学习是神经网络架构搜索技术中常用的一种搜索策略。基于强化学习的神经网络架构搜索方法中,通常是用循环神经网络(rnn)来采样一个子网络结构,之后在任务训练集上训练该子网络结构至收敛,根据该子网络结构最终表现算出其得分,将该得分作为强化学习中的奖励来更新rnn模型。其中搜索子网络架构的rnn模型又被称为控制器(controller),它会按照设定在不同时间步搜索指定的网络架构参数。控制器和搜出的网络架构的权重交替更新,其中搜出的网络架构权重更新时,控制器权重参数保持不变;而在控制器更新期间,会对以往搜出的网络架构采样进行评估。
5.在目前对话文本情景划分方法中,对话语义捕获能力较差,不能通过构建正负样本对来提取语义信息的中句向量,且在对话语义的捕获过程中,存在训练样本短缺的问题,不能为对话文本领域相关下游任务提供更好的支持。
技术实现要素:
6.本发明的目的在于克服现有技术的不足,提供一种基于神经网络架构搜索的对话文本情景划分方法,使用神经网络架构搜索技术完成了对话文本中关键模型的搜索,解决了训练样本短缺的问题,有着更强的对话语义捕获能力,并结合情景段落聚类算法,可以更好地将对话文本按照情景进行划分。
7.本发明的目的是通过以下技术方案来实现的:
8.一种基于神经网络架构搜索技术的对话文本情景划分方法,包括以下步骤:
9.步骤一:对话文本句向量转换,训练一个用于捕获对话语义信息的句向量模型,在句向量模型构建完成后,利用模型将对话文本语句转换为同一维度的句向量特征;
10.步骤二:将对话文本按照语义特征划分为若干段落,构建分段模型,将对话文本分段作为序列标注任务,使用三个分段符号标识一个文本段落;在分段模型中使用条件随机场crf约束最后输出分段符号之间的先后顺序,并基于神经网络架构搜索技术搜索一种用于捕获对话语义信息的循环神经网络rnn结构;
11.步骤三:将离散的文本段落按照对话情景划分,基于dbscan算法提出一种对话段落情景聚类算法进行对话文本聚类,并通过调控密度半径和样本阈值调整最后的聚类效果,最后形成的聚类簇即可视为划分好的对话情景。
12.具体的,所述步骤一具体包括以下子步骤:
13.步骤11:构建对话文本句向量模型dsimcse的训练样本数据集;
14.步骤12:以正样本对的目标函数作为句向量模型的训练目标,对句向量模型进行训练,正样本对的目标函数如下式所示:
[0015][0016]
其中si表示正样本对中的原始语句,s
+i
表示正样本对中的新语句,m表示对话语句个数,t表示温度超参数,sim表示余弦相似度函数;
[0017]
对于负样本对,将正样本对的训练目标取相反后对句向量模型进行训练;
[0018]
步骤13:将对话语句输入对话文本句向量模型dsimcse进行句向量特征转换,获得对话语句对应的句向量特征。
[0019]
具体的,所述步骤11包括以下步骤:
[0020]
步骤111:将同一篇对话文本中的不同语句作为负样本对;
[0021]
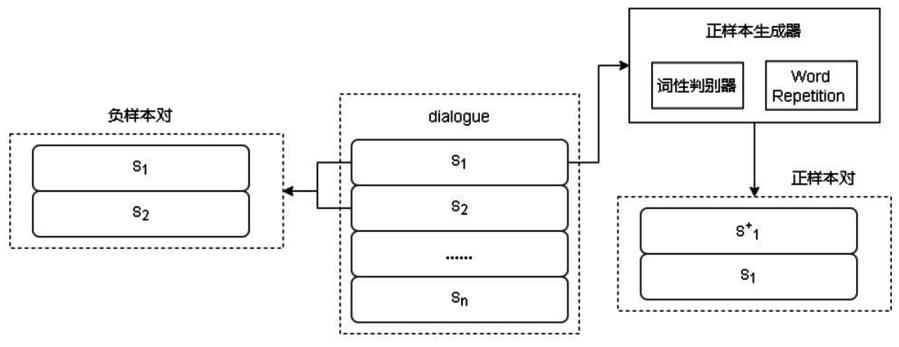
步骤112:在构建正样本对时,对于每条对话语句,首先通过词性判别器识别出对话语句中词性为名词或动词的单词,通过对这类单词进行重复得到新的语句,将新语句与原始语句作为一组正样本对。
[0022]
具体的,所述步骤二具体包括以下子步骤:
[0023]
步骤21:通过基于强化学习的神经网络架构搜索方法搜索一种新型循环神经网络架构drnn,用于捕获对话句向量中的语义信息;
[0024]
步骤22:在drnn的输出特征矩阵之后接一层使用条件随机场crf来约束分段符号之间的顺序,其中《s》表示段落开始语句,《m》表示段落中间的语句,《e》表示段落结束语句;对于已知输入对话序列dialogue={s1,s2,...,sm},经过crf输出的分段标记符号为t={t1,t2,...,tm},则t的得分可如下式所示:
[0025][0026]
其中,score(s,t)表示分段标记符号t的得分,a表示crf的转移矩阵,p表示输出的概率矩阵;
[0027]
当训练完成后,确定crf的转移矩阵参数;输出所有序列得分并取序列得分最大的序列作为对话句向量的最终语义输出,具体如下式所示:
[0028][0029]
其中,ts表示输入对话序列s时可以输出的所有分段标记序列;
[0030]
步骤23:在训练集上优化对分段模型的参数进行优化;
[0031]
步骤24:在验证集上对控制器的参数进行优化;
[0032]
步骤25:得到对话文本的分段结果。
[0033]
具体的,所述步骤21包括以下子步骤:
[0034]
步骤211:将drnn的搜索空间定义为一个有着n个节点的有向无环图,图中的每个节点代表一个激活函数计算节点,节点之间的有向边表示着信息的流动方向;边的起始节点代表输入特征,边的终止节点表示输出特征,从输入特征到输出特征的计算由终止节点上的激活函数决定;
[0035]
步骤212:通过控制器控制drnn的搜索过程,分两个时间步来搜索drnn结构上的计算节点信息;在搜索节点i时,第一个时间步确定当前节点的前驱节点,确保前驱节点已经先于节点i被搜索;第二个时间步确定节点i上需要的激活函数。
[0036]
具体的,所述步骤23包括以下子步骤:
[0037]
步骤231:固定控制器参数;
[0038]
步骤232:控制器搜索一个drnn架构;
[0039]
步骤233:通过drnn架构捕获对话语义信息,并输出最后的crf结果,计算分段损失,如下式所示:
[0040][0041]
步骤234:优化分段模型的参数。
[0042]
具体的,所述步骤24包括以下子步骤:
[0043]
步骤241:固定drnn中特征节点上的参数;
[0044]
步骤242:控制器搜索多个drnn架构;
[0045]
步骤243:通过表现最好的drnn计算控制器损失;
[0046]
步骤244:优化控制器的参数。
[0047]
具体的,所述步骤三包括以下子步骤:
[0048]
步骤31:对于最后得到段落语句向量集合s={s1,s2,..,sm},si∈rn,使用段落语句均值表示整个段落向量,如下式所示:
[0049][0050]
步骤32:遍历段落集合,对于两个段落si和sj,通过下式计算两者之间的距离:
[0051][0052]
步骤33:通过调控密度半径和样本阈值获得核心段落集合,并将密度相连的核心段落聚为一类视为一个不同的情景;
[0053]
步骤34:重复步骤33,获得所有划分好的对话情景。
[0054]
具体的,所述步骤33包括以下子步骤:
[0055]
步骤331:初始化核心段落集合为空,依次遍历各个段落,并计算核心段落与其他段落之间的距离,统计各个段落在密度半径eps以内的相邻段落,如果相邻段落个数大于等于样本阈值minpts,将其加入核心段落集合中;
[0056]
步骤332:依次遍历核心段落集合,将核心段落密度半径eps之内的段落聚为一类,并从核心段落集合中删去这些段落。
[0057]
本发明的有益效果:
[0058]
1、提出一种无监督对话文本句向量模型,解决了训练样本短缺的问题,对于对话文本领域一些下游任务能提供更好的支持;
[0059]
2、基于神经网络架构搜索技术实现的对话文本分段模型,有着更强的对话语义捕获能力,并结合情景段落聚类算法,可以更好地将对话文本按照情景进行划分。
附图说明
[0060]
图1是本发明的方法流程示意图。
[0061]
图2是dsimcse句向量模型正负样本的构建过程示意图。
[0062]
图3是drnn的搜索过程示意图。
[0063]
图4是对话文本分段模型结构图。
[0064]
图5是对话文本分段模型训练算法图。
[0065]
图6是情景段落聚类算法图。
具体实施方式
[0066]
为了对本发明的技术特征、目的和有益效果有更加清楚的理解,现对本发明的技术方案精选以下详细说明。显然,所描述的实施案例是本发明一部分实施例,而不是全部实施例,不能理解为对本发明可实施范围的限定。基于本发明的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的其他所有实施例,都属于本发明的保护范围。
[0067]
实施例一:
[0068]
本实施例中,如图1所示,一种基于神经网络架构搜索技术的对话文本情景划分方法,包括以下步骤:
[0069]
步骤1:对话文本句向量转换,训练一个用于捕获对话语义信息的句向量模型,首先基于策略解决正负样本对的构建问题,在句向量模型构建完成后,可用其将对话语句转换为同一维度的句向量特征;
[0070]
步骤2:将对话文本按照语义特征划分为若干段落,首先提出一个分段模型,该分
段模型将对话文本分段看作是序列标注任务,使用三个分段符号标识一个文本段落,在该分段模型中使用条件随机场(crf)约束最后输出分段符号之间的先后顺序,并基于神经网络架构搜索技术搜索一种用于捕获对话语义信息的rnn结构。
[0071]
步骤3:将离散的段落按照对话情景划分,基于dbscan算法提出一种对话段落情景聚类算法,通过调控密度半径和样本阈值来调整最后的聚类效果,最后形成的聚类簇即可视为划分好的对话情景。
[0072]
进一步的,所述步骤1包括以下子步骤:
[0073]
步骤11:如图2所示,构建对话文本句向量模型dsimcse的训练样本数据集;
[0074]
进一步的,步骤11包括以下步骤:
[0075]
步骤111:将同一篇对话文本中的不同语句作为负样本对;
[0076]
步骤112:在构建正样本对时,对于一条对话语句,首先通过词性判别器对该语句中词性为名词或动词的单词识别出来,通过对这类单词进行重复得到新的语句,将新语句与原始语句作为一组正样本对看待;
[0077]
步骤12:以下公式作为句向量模型的训练目标对其进行训练,其中si表示正样本对中的原始语句,s
+i
表示正样本对中的新语句,m表示对话语句个数,t表示温度超参数,sim表示余弦相似度函数。该式为正样本对的目标函数,而对于负样本对来说,训练目标取相反即可。
[0078][0079]
步骤13:将对话语句输入dsimcse,获得该语句转换为对应的句向量特征;
[0080]
进一步的,所述步骤2包括以下子步骤:
[0081]
步骤21:通过基于强化学习的神经网络架构搜索方法搜索一种新型rnn架构-drnn,用于捕获对话句向量中的语义信息。
[0082]
进一步的,步骤21包括以下子步骤:
[0083]
步骤211:对drnn的搜索空间进行设计,将其定义为一个有着n个节点的有向无环图,
[0084]
图中的每个节点代表一个激活函数计算节点,而节点之间的有向边表示着信息的流动方向,其中边的起始节点代表输入特征,边的终止节点表示输出特征,而从输入特征到输出特征的计算则由终止节点上的激活函数所决定。
[0085]
步骤212:通过控制器控制drnn的搜索过程,如图3所示。控制器在搜索drnn结构时,会分两个时间步来搜索drnn上的一个计算节点信息。在搜索节点i时,第一个时间步会确定当前节点的前驱节点,也就是确定计算的输入特征来自于哪一个节点,应确保该前驱节点已经先于节点i被搜索过,即其编号应位于[1,i-1]之间。这种节点之间的连线方式也运用了跳跃连接的思想,这使得搜索出的drnn单元具有更强大的表征能力。第二个时间步主要确定节点i上应该要进行的激活函数,这些激活函数包括常见的relu、tanh、sigmoid等。
[0086]
步骤22:如图4所示,在drnn的输出特征矩阵之后接一层crf来约束分段符号之间
的顺序,其中《s》表示段落开始语句,《m》表示段落中间的语句,《e》表示段落结束语句。对于已知输入对话序列dialogue={s1,s2,...,sm},经过crf输出的分段标记符号为t={t1,t2,...,tm},则t的得分可如下式被定义,其中a表示crf的转移矩阵,p表示输出的概率矩阵。
[0087][0088]
当训练完成后,crf的转移矩阵参数是确定的,此时只需要输出所有序列得分并取得分最大的那个序列作为最终输出即可,具体过程如下式所示,其中ts表示输入对话序列s时可以输出的所有分段标记序列,也包括那些在逻辑上不可能出现的情况。
[0089][0090]
步骤23:在训练集上优化对分段模型的参数进行优化。
[0091]
进一步的,步骤23包括以下子步骤:
[0092]
步骤231:固定控制器参数;
[0093]
步骤232:控制器搜索一个drnn架构;
[0094]
步骤233:通过drnn捕获对话语义信息,并输出最后的crf结果,计算分段损失,如下式所示:
[0095][0096]
步骤234:优化分段模型的参数;
[0097]
步骤24:在验证集上对控制器的参数进行优化。
[0098]
进一步的,步骤24包括以下子步骤:
[0099]
步骤231:固定drnn中特征节点上的参数;
[0100]
步骤232:控制器搜索多个drnn架构;
[0101]
步骤233:通过表现最好的drnn计算控制器损失;
[0102]
步骤234:优化控制器的参数;
[0103]
步骤25:得到对话文本的分段结果。整体模型的训练方法如图5所示。
[0104]
进一步的,所述步骤3包括以下子步骤:
[0105]
步骤31:对于最后得到段落语句向量集合s={s1,s2,..,sm},si∈rn,使用段落语句均值表示整个段落向量,如下式所示:
[0106][0107]
步骤32:遍历段落集合,对于两个段落si和sj,通过下式计算两者之间的距离:
[0108][0109]
步骤33:通过调控密度半径和样本阈值获得核心段落集合,并将密度相连的核心段落聚为一类视为一个不同的情景,具体过程如图6所示。
[0110]
进一步的,步骤33包括以下子步骤:
[0111]
步骤331:初始化核心段落集合为空,依次遍历各个段落,并计算与其他段落之间的距离,统计各个段落在密度半径eps以内的相邻段落,如果相邻段落个数大于等于样本阈值minpts,将其加入核心段落集合中。
[0112]
步骤332:依次遍历核心段落集合,将核心段落密度半径eps之内的段落聚为一类,并从核心段落集合中删去这些段落。
[0113]
步骤34:重复步骤33,获得所有划分好的对话情景。
[0114]
本实施例通过训练一个用于捕获对话语义信息的句向量模型,用其将对话语句转换为同一维度的句向量特征,基于策略解决了正负样本对的构建问题。同时将对话文本按照语义特征划分为若干段落,首先提出一个分段模型,该分段模型将对话文本分段看作是序列标注任务,使用三个分段符号标识一个文本段落,在该分段模型中使用条件随机场(crf)约束最后输出分段符号之间的先后顺序,并基于神经网络架构搜索技术搜索一种用于捕获对话语义信息的循环神经网络(rnn)结构。将离散的段落按照对话情景划分,基于dbscan算法提出一种对话段落情景聚类算法,通过调控密度半径和样本阈值来调整最后的聚类效果,最后形成的聚类簇即可视为划分好的对话情景。本发明提出一种无监对话文本句向量模型,解决了训练样本短缺的问题,也能为对话文本领域相关下游任务提供更好的支持。基于神经网络架构搜索技术实现的对话文本分段模型,有着更强的对话语义捕获能力,并结合情景段落聚类算法,可以更好地将对话文本按照情景进行划分。
[0115]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护的范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1