一种融合类别信息的疫情问答系统相似问句识别方法
1.本发明提出一种融合类别信息的疫情问答系统相似问句识别方法,是对特定领域问句的表示和处理的研究,属于数据识别领域。
背景技术:
2.2020年初,新冠肺炎疫情暴发,关于新冠肺炎的流行和发展状况信息在社交媒体上传播迅速,引起了公众的广泛关注与讨论,同时引发了民众在医疗健康类问答平台、社交媒体上的信息搜索热潮。由于疫情的特殊性,准确而科学的问答信息能够及时地解答网民的疑惑。此类疫情信息问答系统的搭建能够为疫情相关信息的收集与汇总综合提供平台。
3.文本相似度计算技术是自然语言处理领域一项重要的技术,其广泛应用在文本摘要生成、限定领域问答系统、抄袭检测、相似内容推荐等自然语言处理任务中。然而,对于汉语来说,同义词、否定含义以及复杂多样的句式结构都增加了计算的难度。在问答系统中,由于问题长度较短,没有上下文,而且用户提问的多样性和复杂性,对中文问答系统的准确性和推理能力有一定的要求。
4.传统的基于统计和向量空间的语义文本相似度计算方法无法有效捕捉句子的语义信息,基于语义树的方法精度不够,需要持续地人工维护。深度学习方法不仅可以有效提取句子特征,还可以捕捉句子上下文信息,达到较高的准确率。现有的深度学习方法大多是通过改进模型结构或研究模型的集成来寻求模型性能的提升,事实上句子的主语和焦点也可以反映问题的主要背景并指明提问者的主要关注领域和方向。
5.本发明创新之处是将疫情相关问题分类信息融入到问句向量的生成中,使向量生成部分承载了更多的语义信息,可以更好地学习句子的深层语义特征,在疫情领域问答系统的相似问句识别环节具有重要的实用意义。能够有效解决民众在疫情期间的各种相关问题,有利于民众对疫情形式的跟踪与及时地进行自我防护,有利于丰富现有健康信息分类体系和支撑有关部门掌握民众的健康信息需求动态从而制定更加切实有效的公共健康政策。
技术实现要素:
6.本发明的目的是为了解决上述提出的疫情领域问答系统相似问句识别不够准确的技术问题,一种融合类别信息的疫情问答系统相似问句识别方法。本发明在句向量的生成过程中将疫情问句的类别信息作为嵌入层之一,利用注意力机制更好的获得句子的语义信息,从而提高相似语义识别的准确率与速度。
7.本发明的目的是通过下述技术方案实现的。
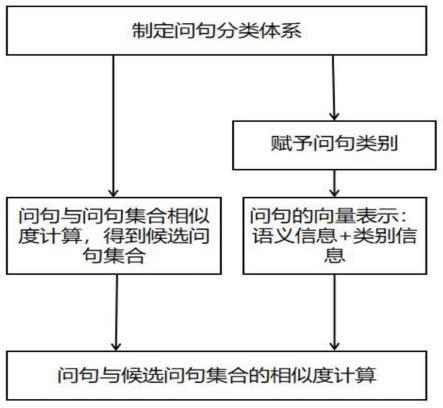
8.一种融合类别信息的疫情问答系统相似问句识别方法,包括以下步骤:
9.步骤1:在互联网上采集新冠肺炎疫情领域真实问句,形成问句集合d={d1,d2,...,dj,...dn},其中dj为采集到具体问句,根据bert模型的向量生成方式对问句dj进行编码,并将问句的关键词作为问句相应的类别,最终形成包含类别信息和相应的问句的新
冠肺炎疫情领域问句的分类信息集;
10.步骤2:对步骤1中的dj的类别信息采用一位有效编码方式进行编码cj={0,0,0,1,0
……
,0};
11.步骤3:选择d中任意问句记作q,计算q与问句集合d中其他所有问句的相关性;将输入问句q分解为词素的集合,表示为q={q1,q2,q3,q4,...qi...},(1≤i≤m),根据词素qi分别在问句dj和问句集合d中出现的频次信息计算qi与dj的相关性,并对所有词素相对于dj的相关性进行加权,最后得出问句q与问句集d中某一问句dj的相关性得分score(q,dj);计算公式如下:
[0012][0013]
qi代表q分解后的词素,wi代表qi的权重,r(qi,dj)表示词素qi与句子dj的相关性;
[0014]
wi计算公式如下:
[0015][0016]
n是集合d中的问题数量,df(qi)表示包含词素qi的句子数;r(qi,dj)的计算公式如下:
[0017][0018][0019][0020]
其中,1.2≤k1≤2.0,表示词素在句子中出现的频率与得分的关系;0≤b≤1,表示句子长度对计算平均长度的影响;tf(qi,dj)为dj中词素qi出现的频率,len(dj)为dj的长度,avdl为问句集d中所有问句的平均长度;
[0021]
步骤4:将步骤3中得到score(q,dj)按从大到小顺序进行排序,排序前20的对应问句构成问句集合d’;
[0022]
步骤5:根据bert模型的向量生成方式,将问句集合d’中所有问句的类别信息利用一位有效编码方式嵌入到bert模型当中;首先,将步骤4中集合d’中的每一个问句转化为词的线性序列x=(x1,x2,
……
x
t
,...xn);然后,将词的线性序列x=(x1,x2,
……
x
t
,...xn)输入到bert嵌入层;
[0023]
将类别信息cj与bert模型的三种不同的向量表示dj进行平均,合成向量e=(e1,e2,......,e
t
,...en),作为transformer编码器部分的输入;
[0024]
步骤6:将步骤5中的x=(x1,x2,
……
x
t
,...xn)输入注意力机制模型进行问句全局特征的学习;首先将输入的句子信息记为source,将source分解成一系列(key,value)对,(key,value)对指d’中每个句子的对应位置字符的向量及其值,然后采用点乘的方式计算输入问句中的任意一个字符query和每个key的相关度simi(keyi,query)=keyi·
query;然后使用softmax函数进行归一化从而得到问句中的字符在整个问句中的注意力的权值,用ai
表示,ai=l
x
是句子长度;最后将字符的注意力权值ai与字符实际的值valuei进行加权求和,并最终得到注意力分数进行加权求和,并最终得到注意力分数
[0025]
计算过程:首先创建三个分别由query、key和value转换的矩阵q、k、v;并通过引入缩放因子的方式进行调节使内积不至于过大而影响计算,dimk表示key的维度,dimk=64;在这里,对于注意力机制的运算采用多个维度学习的结果,也就是多头注意力机制,可以获得更丰富的语义特征表达:
[0026]
multihead(q,k,v)=concat(head1,......,headh)wo[0027]
其中headi=attention(qw
iq
,qw
ik
,qw
iv
)
[0028]
表示第i个head的q、k、v权重矩阵(i=1,2,
……
,h,h=8),h表示注意力的个数,d
model
是拼接后向量的维度,dimk=dimv=d
model
/h,每个注意力捕获问句中一个子空间的信息,将h个注意力头利用矩阵力捕获问句中一个子空间的信息,将h个注意力头利用矩阵进行拼接得到多头注意力值,作用是将多头注意力进行拼接,是通过训练得到的;
[0029]
步骤7:在注意力机制层之后,加入全连接层综合所有语义和类别信息进行相似识别,输出问句q和候选问句集d’中问句的相似度数值similarity;全连接层由relu激活函数层和线性函数层组成,整体公式表示为similarity=max(0,xw1+bias1)w2+bias2,w1,w2是两个可训练权重矩阵,bias1和bias2代表两个偏移向量,x为激活函数的输入。
[0030]
有益效果
[0031]
与现有技术相比,本发明所述疫情领域问答系统问句相似度计算方式将问句的类别信息作为重要因素嵌入句向量的生成过程,并采用多头注意力机制。基于上述理由,本发明不仅可以较好的解决疫情相关问题识别,也可在其他限定领域广泛推广。
附图说明
[0032]
图1实施例融合新冠肺炎疫情类别信息的问答系统相似问句识别方法的流程框图;
[0033]
图2基于注意力机制的相似问句识别方法流程图。
具体实施方式
[0034]
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图及具体实施方式对本发明的技术方案进行详细说明。
[0035]
如图1所示,本发明相似问句识别方法包括如下步骤:
[0036]
步骤1:在互联网上采集新冠肺炎疫情领域真实问句4506条,形成问句集合d={d1,d2...,dj,...dn},其中dj(1≤j≤n)为采集到具体问句,根据bert模型的向量生成方式
对问句dj进行编码,并将问句的关键词作为问句相应的类别,最终形成包含类别信息和相应的问句的新冠肺炎疫情领域问句的分类信息集;
[0037]
步骤2:对步骤1中的dj的类别信息采用一位有效编码方式进行编码cj={0,0,0,1,0
……
,0};
[0038]
步骤3:选择d中任意问句记作q,计算q=“得了新冠怎么办?”与问句集合d中其他所有问句的相关性;将输入问句q分解为词素的集合,表示为q={q1,q2,q3,q4,...qi...},(1≤i≤m),根据词素qi分别在问句dj和问句集合d中出现的频次信息计算qi与dj的相关性,并对所有词素相对于dj的相关性进行加权,最后得出问句q与问句集d中某一问句dj的相关性得分score(q,dj);计算公式如下:
[0039][0040]
qi代表q分解后的词素,wi代表qi的权重,r(qi,dj)表示词素qi与句子dj的相关性;
[0041]
wi计算公式如下:
[0042][0043]
n是集合d中的问题数量,df(qi)表示包含语素qi的句子数;r(qi,dj)的计算公式如下:
[0044][0045][0046][0047]
其中,1.2≤k1≤2.0,表示词素在句子中出现的频率与得分的关系;0≤b≤1,表示句子长度对计算平均长度的影响;tf(qi,dj)为dj中词素qi出现的频率,len(dj)为dj的长度,avdl为问句集d中所有问句的平均长度;
[0048]
步骤4:将步骤3中得到score(q,dj)按从大到小顺序进行排序,排序前20的对应问句构成问句集合
[0049]
d’={
[0050]“得了新冠肺炎怎么办:13.82169669”;
[0051]“新冠肺炎确诊后该怎么办:12.36328026”;
[0052]“得了新冠吃什么药效果最好:12.35062094”;
[0053]“新冠预后如何:11.89526051”;
[0054]“得了新冠怎么治疗:11.89526051”;
[0055]“新型冠状病毒的治疗方式有哪些:11.45995442”;
[0056]“感染新型冠状病毒的常见症状有哪些:11.05538355”;
[0057]“得了新冠是什么感觉:11.05538355”;
[0058]“疫情期间隔离措施有哪些:11.05538355”;
[0059]“新型冠状病毒如何预防:10.67840377”;
[0060]“新冠病毒感染表现:10.67840377”;
[0061]“新型冠状病毒肺炎如何判断:10.67840377”;
[0062]“新冠如何能治好,得了新冠的饮食:10.46877347”;
[0063]“哺乳期得了新冠该怎么办:10.32628565”;
[0064]“新冠如何医治,怎么预防:9.996648272”:
[0065]“新冠合并高血压应该如何治疗:9.687405337”;
[0066]“得了新冠的护理方法:9.687405337”;
[0067]“新冠有何预防措施:9.506486953”;
[0068]“新冠和流感有何区别:8.636723046”;
[0069]“如何控制新冠病情:8.611672945”;
[0070]
}。
[0071]
步骤5:根据bert模型的向量生成方式,将问句集合d’中所有问句的类别信息利用一位有效编码方式嵌入到bert模型当中;首先,将步骤4中集合d’中的每一个问句转化为词的线性序列x=(x1,x2,
……
x
t
,...xn);然后,将词的线性序列x=(x1,x2,
……
x
t
,...xn)输入到bert嵌入层;
[0072]
将类别信息cj与bert模型的三种不同的向量表示dj进行平均,合成向量e=(e1,e2,......,e
t
,...en),作为transformer编码器部分的输入;
[0073]
步骤6:将步骤5中的x=(x1,x2,
……
x
t
,...xn)输入注意力机制模型进行问句全局特征的学习;首先将输入的句子信息记为source,将source分解成一系列(key,value)对,(key,value)对指d’中每个句子的对应位置字符的向量及其值,然后采用点乘的方式计算输入问句中的任意一个字符query和每个key的相关度simi(keyi,query)=keyi·
query;然后使用softmax函数进行归一化从而得到问句中的字符在整个问句中的注意力的权值,用ai表示,表示,l
x
是句子长度;最后将字符的注意力权值ai与字符实际的值valuei进行加权求和,并最终得到注意力分数进行加权求和,并最终得到注意力分数如图2所示;
[0074]
计算过程:首先创建三个分别由query、key和value转换的矩阵q、k、v;attention(query,source)=softmax()v,并通过引入缩放因子的方式进行调节使内积不至于过大而影响计算,表示key的维度,dimk=64;在这里,对于注意力机制的运算采用多个维度学习的结果,也就是多头注意力机制,可以获得更丰富的语义特征表达:
[0075]
multihead(q,k,v)=concat(head1,......,headh)wo[0076]
其中headi=attention(qw
iq
,qw
ik
,qw
iv
)
[0077]
表示第i个head的q、k、v权重矩阵(i=1,2,
……
,h,h=8),h表示注意力的个数,d
model
是拼接后向量的维度,dimk=dimv=d
model
/h,每个注意力捕获问句中一个子空间的信息,将h个注意力头利用矩阵个注意力捕获问句中一个子空间的信息,将h个注意力头利用矩阵进行拼接得到多头注意力值,作用是将多头注意力进行拼接,是通过训练得到的;
[0078]
步骤7:在注意力机制层之后,加入全连接层综合所有语义和类别信息进行相似识别,输出问句q和候选问句集d’中问句的相似度数值similarity,结果为:
[0079]
{
[0080]“得了新冠怎么治疗similarity=0.894480407”;
[0081]“新冠如何医治,怎么预防similarity=0.13762705”;
[0082]“新冠肺炎确诊后该怎么办similarity=0.033919051”;
[0083]“得了新冠吃什么药效果最好similarity=0.033315331”;
[0084]“新型冠状病毒的治疗方式有哪些similarity=0.032382693”[0085]
};
[0086]
全连接层由relu激活函数层和线性函数层组成,整体公式表示为similarity=max(0,xw1+bias1)w2+bias2,w1,w2是两个可训练权重矩阵,bias1和bias2代表两个偏移向量,x为激活函数的输入。
[0087]
通过当前计算方法可以提升文本相似度计算的准确度,对于不同类别的问句具有良好的识别与匹配功能,能够应用在限定领域的问答系统问句相似度计算过程中。最后应说明的是,以上各实施例仅用以说明本发明的技术方案,而非对其限制。因此,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1