一种用于SIMD计算指令的交互型运算装置及执行方法
一种用于simd计算指令的交互型运算装置及执行方法
技术领域
1.本发明涉及计算机系统结构设计领域,具体来说,涉及加速器芯片设计领域,更具体地说,涉及一种用于simd计算指令的交互型运算装置以及simd计算指令执行方法。
背景技术:
2.计算机指令是指挥机器工作的指示和命令,计算机系统中,将指令处理过程进一步细分,如图1所示,可划分为如下六个阶段:
3.取指阶段(简称为fi):从存储器取出一条指令放入指令部件缓冲区;
4.指令译码阶段(简称为di):确定操作性质和操作数地址形成方式;
5.计算操作数地址阶段/地址形成(简称为co):计算操作有效地址;
6.取操作数阶段(简称为fo):从存储器中取出操作数;
7.执行指令阶段(简称为ei):执行指令,并将结果存入目的位置;
8.写操作数阶段/回写结果(简称为wo):将结果存入寄存器。
9.如图1所示,指令执行过程分为多个阶段后,每个阶段需要的资源和硬件不一样,fi对应于取指令部件、di对应于指令译码部件、co对应于地址形成部件、fo对应于取操作数部件、ei对应于操作执行部件、wo对应回写结果部件,因此可以采用流水线多发技术,同时执行多条指令的不同阶段。如图2所示,可以实现指令的6级流水操作,纵轴为每个时刻被同时使用的流水步骤、横轴为时间,可以看出,将指令分阶段后,可以在同一时刻执行不同指令的不同阶段,例如,图2中所示的,在第2个时钟周期,可以同时执行指令1的di和指令2的fi阶段。
10.simd(single instruction multipledata,单指令多数据流)是能够复制多个操作数、并把它们打包在大型寄存器的一组指令集。如图3所示,一个包含两个数据向量的simd计算操作数,每个向量包含多个数据分量,其中一个向量包含a11、b11、c11、d11四个数据分量,另一个向量a12、b12、c12、d12四个数据分量,包含simd型的cpu中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算,这个特点使simd特别适合于多媒体应用等数据密集型运算。但是传统的simd技术及硬件模块存在以下问题:1、当涉及到多种数据精度类型,例如单/双精度/定点整型的simd处理时,需要硬件上配置多套流水线,硬件开销较大;2、传统的simd技术不支持条件分支的情况,如图4所示,不同的simd分量需要根据分支条件执行不同的代码路径,传统的simd技术下不同的结果难以合并。
11.现有的流水线多发技术主流的有超标量技术和超长指令字技术。
12.如图5所示,超标量技术是在每个时钟周期内同时并发多条独立指令,在处理机中配置多个功能部件和指令译码电路、多个寄存器端口和总线,由编译程序决定哪几条相邻指令可以并行执行。但是该技术存在以下缺点:1、需要多套取指、译码、写回的控制逻辑,硬件资源开销大;2、运算执行部件(如图5中所示的ei部分)只能同步执行,难以支持所需时钟周期不同步的混合计算精度;3、不能支持simd计算模式。
13.超长指令字技术是由编译程序挖掘出指令间潜在的并行性,并将多条能并行操作
的指令合成一条具有多个操作码字段的超长指令,如图6所示的示例,将co、fo、di三个阶段合并为一个阶段(ex),同时把多条可并行执行的指令中的ex阶段合成一条具有多个操作码字段的超长指令。但是该技术存在以下缺点:1、需要编译器软件在程序上进行协调调度、组合起来的运算操作数难以分离;2、如果程序混合不同的计算精度时,编译器协调调度难度较大,并行优化效果较差;3、不能支持simd的计算模式。
14.综上所述,现有技术下的缺点可以总结为如下两个方面:
15.1、传统的simd单指令多数据流技术:当需要支持多种数据精度格式时,需要配备多套硬件流水线,开销较大,且传统的simd向量部件不支持条件分支的情况,难以合并条件结果。
16.2、超标量技术和超长指令字技术:需要多套取指,译码,写回的控制逻辑,硬件资源开销大;其中运算执行部分只能同步执行,难以支持混合计算精度;需要编译器做大量的指令调度协调的工作;不支持simd计算模式,数据的计算吞吐量不足。
技术实现要素:
17.因此,本发明的目的在于克服上述现有技术的缺陷,提供一种用于simd计算指令的运算装置以及simd计算指令执行方法。
18.根据本发明的第一方面,提供一种用于simd计算指令的运算装置,所述运算装置包括:数据打包流水寄存器,用于接收并寄存待处理simd计算指令以及指令对应的一组操作数,并根据指令类型的不同将操作数派发到定点译码器或浮点译码器,其中,指令类型包括定点整型指令和浮点指令;定点译码器,用于对定点整型指令对应的操作数进行译码重排处理并传输到定点整型运算器;定点整型运算器;用于对定点译码器处理后的操作数执行整型运算;浮点译码器,用于对浮点指令对应的操作数进行译码重排处理并根据指令将重排后的操作数传送到浮点乘加器或浮点除法器;浮点乘加器,用于对浮点译码器处理后的操作数进行浮点乘加计算;浮点除法器,用于对浮点译码器处理后的操作数进行浮点除法计算;运算结果仲裁器,用于对定点整型运算器、浮点乘加器、浮点除法器的运算结果进行选择以输出最终simd计算结果。
19.在本发明的一些实施例中,所述数据打包流水寄存器接收的一组操作数中的操作数数量为1至3。优选的,所述每一组输入的操作数均为1024比特的simd数据。
20.在本发明的一些实施例中,所述定点译码器被配置为按照指令精度需要将输入的1024比特的操作数解析为128个8比特整数或32个32比特整数。
21.在本发明的一些实施例中,所述浮点译码器被配置为按照指令精度需求将输入的1024比特的操作数解析为32个3位单精度浮点数或16个64位双精度浮点数。
22.优选的,所述定点整型运算器被配置为在一个时钟周期内完成计算;所述浮点乘加器被配置为在两个时钟周期内完成计算;所述浮点除法器被配置为在9个时钟周期内完成计算。优选的,所述运算结果仲裁器配置有3比特结果有效寄存器,用于判断计算部件是否有输出,所述定点整型运算器、浮点乘加器、浮点除法器的输出端分别对应于结果有效寄存器的一个比特位,比特位值为1时,指示该比特位对应的计算部件有输出。在同一个时钟周期多个部件同时输出计算结果时,所述运算结果仲裁器被配置为按照如下优先级顺序选择最终结果:浮点除法器》浮点乘加器》定点整型运算器。
23.优选的,所述装置还包括:条件掩码标记寄存器,用于存储条件掩码,并将条件掩码发送到运算结果仲裁器以控制其对包含条件分支的simd操作数的不同分支计算结果进行合并。
24.根据本发明的第二方面,提供一种基于本发明第一方面所述装置的simd计算指令执行方法,所述方法包括如下步骤:获取simd计算指令以及指令对应的一组操作数;判定指令类型是定点整型指令还是浮点指令,以将定点整型指令对应的操作数派发到定点译码器,将浮点指令对应的操作数派发到浮点译码器;通过定点译码器对定点整型指令对应的操作数进行译码重排处理,并由定点整型运算器对定点译码器处理后的操作数执行整型运算;通过浮点译码器对浮点指令对应的操作数进行译码重排处理并根据指令功能选择浮点乘加器或浮点除法对对浮点译码器处理后的操作数进行计算;通过运算结果仲裁器对定点整型运算器、浮点乘加器、浮点除法器的运算结果进行选择以输出最终simd计算结果。
25.根据本发明的第三方面,提供一种加速芯片,所述芯片上配置有如本发明第二方面所述的用于simd计算指令的运算装置。
26.与现有技术相比,本发明的优点在于:本发明通过采用运算装置采用单发射+多部件选择仲裁的方式,以及条件掩码标记的方式能够实现如下功能:只使用一套指令执行序列的硬件资源,节省硬件资源,降低部件功耗,计算部件只使用了单条控制流水线+仲裁器选择器,实现了3类不同精度运算部件的并发执行,能够覆盖不同精度混合运算的场合,同时只占用较少的硬件资源;每类运算部件都是采取向量部件的方式,能够支持simd多数据的并发计算,有比较高的数据吞吐量,能够在指令计算过程中,实现异步并行执行,支持不同执行周期数的计算精度,在保留单套单套控制流水线的基础上,实现不同精度、延迟的运算装置的异步高效执行;能兼容simd单指令多数据模式,并通过条件掩码实现simd分量结果的分支控制功能,扩充了simd功能的通用性。
附图说明
27.以下参照附图对本发明实施例作进一步说明,其中:
28.图1为根据本发明实施例的现有技术下的指令过程分阶段示意图;
29.图2为根据本发明实施例的现有技术下指令流水线执行过程的时序示意图;
30.图3为根据本发明实施例的simd计算示例示意图;
31.图4为根据本发明实施例的simd条件分支计算示例示意图;
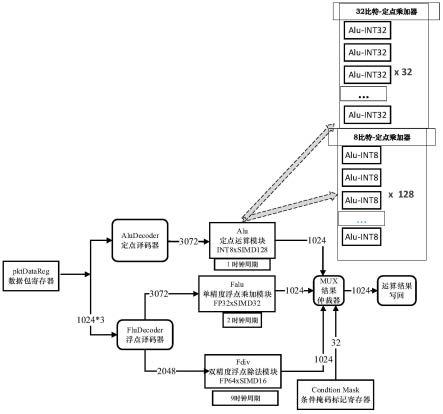
32.图5为根据本发明实施例的超标量流水技术示意图;
33.图6为根据本发明实施例的超长指令字流水技术示意图;
34.图7为根据本发明实施例的用于simd计算指令的交互型运算装置结构示意图。
具体实施方式
35.为了使本发明的目的,技术方案及优点更加清楚明白,以下通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
36.本发明的目的在于解决现有技术下的流水线技术不能支持simd计算模式以及传统simd计算技术不支持混合精度计算等问题。发明人在进行通用处理器中高吞吐量运算部
件设计研究时,发现现有技术中运算部件的设计在计算精度上较为单一,对于多精度计算场景往往需要多套流水线部件来实现,存在控制逻辑和时序寄存器资源的冗余,带来较大的硬件开销。另外对应simd的单指令多数据类型的计算模式,不具备数据分量上的条件判断执行,难以满足常见程序代码中的一些简单的条件判断操作。针对以上的问题,本发明专门设计混合精度型条件可控的simd向量部件,以解决上述问题。
37.根据本发明的一个实施例,提供一种用于simd计算指令的交互型运算装置,所述装置包括:数据打包流水寄存器,用于接收并寄存待处理simd计算指令以及指令对应的一组操作数,并根据指令类型的不同将操作数派发到定点译码器或浮点译码器,其中,指令类型包括定点整型指令和浮点指令;定点译码器,用于对定点整型指令对应的操作数进行译码重排处理并传输到定点整型运算器;定点整型运算器;用于对定点译码器处理后的操作数执行整型运算;浮点译码器,用于对浮点指令对应的操作数进行译码重排处理并根据指令功能选择性的将重排后的操作数传送到浮点乘加器或浮点除法器;浮点乘加器,用于对浮点译码器处理后的操作数进行浮点乘加计算;浮点除法器,用于对浮点译码器处理后的操作数进行浮点除法计算;运算结果仲裁器,用于对定点整型运算器、浮点乘加器、浮点除法器的运算结果进行选择以输出最终simd计算结果;条件掩码寄存器,用于存储条件掩码,并将条件掩码发送到运算结果仲裁器并控制其对包含条件分支的simd操作数的不同分支计算结果进行合并以得到最终的simd计算结果。为了更好的理解本发明,下面结合附图详细说明本发明。
38.如图7所示为本发明的用于simd计算指令的交互型运算装置以及运算装置运行过程中的部件流水线图。其中,运算装置中包括3类不同运算精度类型的部件阵列和调度控制逻辑。如图7所示的示例,3组计算部件分别是:1)128个int8精度的alu(定点乘加部件,也叫定点整型运算器);2)32个单精度float32的falu(单精度乘加部件);3)16个单精度float64的fdiv(双精度除法部件)。调度控制逻辑为condition mask(条件掩码标记寄存器)。所述运算装置运行过程包括如下几个阶段:输入操作数、指令译码和执行、写回结果。
39.1、输入操作数
40.输入的一组操作数均为高位宽1024比特的simd数据,从pktdatareg(数据打包流水寄存器)送入,其中,指令功能的不同,需要输入的操作数数量不一样,数量为1到3,假设操作数依次为data0、data1和data2,通过如下举例来说明不同的指令功能对应的不同操作数:
41.(1)fmadd浮点乘加指令,实现功能为result=data0*data1+data2,需要三个操作数,所需要的3个data操作数依次送到falu单精度乘加部件的3个输入端口src_input0、src_input1、src_input2,falu单精度乘加部件属于芯片设计领域内容易见到的部件,此处不对该部件进行过多赘述。
42.(2)not定点取非指令,实现功能为result=~data0,需要一个操作数,所需要的1个操作数送到alu定点运算部件的src_input0,定点运算部件也属于芯片设计领域内容易见到的部件,此处不对该部件进行过多赘述。
43.(3)fsub浮点减法指令,实现功能为result=data0-data1,需要两个操作数,所需要的2个data操作数,依次送到falu的2个输入端口src_input0、src_input2(src_input1置空)。
44.(4)fdiv浮点除法指令,实现功能为result=data0/data1,需要两个操作数,所需要的2个data操作数依次送到fdiv双精度除法部件的2个输入端口src_input0、src_input1,fdiv双精度除法部件部件属于芯片设计领域内容易见到的部件,此处不对该部件进行过多赘述。
45.2、指令译码和执行
46.如果当前执行的是定点整型指令,操作数会被派发到aludecoder(定点译码器)进行译码重排,然后送到alu(定点整型运算部件)。其中1024比特位宽的操作数,可以被解析成128个int8整数或32个int32整数,以对应到不同精度需求的运算类型。定点整型运算部件1个时钟周期能算出结果。
47.如果当前执行的是浮点指令,操作数会被派发到fludecoder(浮点译码器)译码,然后根据指令功能选择性地送到falu(浮点乘加器)或fdiv(浮点除法器),每一组操作数同样为1024比特,可解析为32个fp32(单精度浮点数)或16个fp64(双精度浮点数),其中falu在2个时钟周期算出结果,fdiv为9个时钟周期出结果。
48.3、写回结果
49.alu、falu和fdiv的输出端口,都连接到mux(运算结果仲裁器)进行选择,每个计算部件对应一个比特位,三个计算部件对应三个比特位,当计算部件有结果输出时,该计算部件对应的结果有效寄存器比特值为1,如果同一个时钟周期,有多个计算部件同时输出结果,会根据三个计算部件输出端对应的结果有效寄存器值进行判断,优先级(fdiv》falu》alu)选出当前应该写回的结果值。为了更好的理解写回结果的执行原理,下面通过举例方式来进一步说明。
50.是否有结果输出,依据三个计算部件输出端送入的3比特结果有效寄存器值进行判断:
51.1)如果3个计算部件中只有其一输出结果,即寄存器值为001,010,100,此时选择当前有效结果输出即可。
52.2)若寄存器值为011,110,101,表示同时有两个部件输出结果,此时根据优先级(fdiv》falu》alu)选择高优先级结果输出。
53.3)若寄存器值为111,表示三个部件同时输出结果,此时选择优先级最高的fdiv除法运算结果进行输出。
54.当simd计算出现条件分支的情况时,mux仲裁器会根据32比特condition mask寄存器输入进来的条件掩码,对经过不同分支得到的分量结果进行合并,组合到结果的simd数据值中,作为最终的simd计算结果。
55.例如,假设simd计算出现了条件分支的情况为:一组操作数中包含整型加运算和浮点乘运算,那么condition mask寄存器中会存储对应的条件掩码以指示mux对整型运算结果和浮点乘结果进行合并。
56.由此可见,本发明通过采用运算装置采用单发射+多部件选择仲裁的方式,以及条件掩码标记的方式能够实现如下功能:只使用一套指令执行序列的硬件资源,节省硬件资源,降低部件功耗,计算部件只使用了单条控制流水线+仲裁器选择器,实现了3类不同精度运算部件的并发执行,能够覆盖不同精度混合运算的场合,同时只占用较少的硬件资源;每类运算部件都是采取向量部件的方式,能够支持simd多数据的并发计算,有比较高的数据
吞吐量,能够在指令计算过程中,实现异步并行执行,支持不同执行周期数的计算精度,在保留单套单套控制流水线的基础上,实现不同精度、延迟的运算装置的异步高效执行;能兼容simd单指令多数据模式,并通过条件掩码实现simd分量结果的分支控制功能,扩充了simd功能的通用性。
57.需要说明的是,虽然上文按照特定顺序描述了各个步骤,但是并不意味着必须按照上述特定顺序来执行各个步骤,实际上,这些步骤中的一些可以并发执行,甚至改变顺序,只要能够实现所需要的功能即可。
58.本发明可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本发明的各个方面的计算机可读程序指令。
59.计算机可读存储介质可以是保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以包括但不限于电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式压缩盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。
60.以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1