一种文本分词方法、装置、设备及计算机存储介质与流程
本文涉及信息处理领域,尤其涉及一种文本分词方法、装置、设备及计算机存储介质。
背景技术:
1、自然语言处理(natural language processing,nlp)是人工智能(artificialintelligence,ai)中一项重要的技术,通过自然语言处理使得计算机能够分析、理解人类语言,其应用场景非常广泛,如语言翻译、文本文档信息摘要提取、人机交互、搜索引擎、数据库数据检索等。尤其是非分词语言,如汉语、日语和泰语,没有空格或分隔符,大多数单词是连续书写的,难以找到每个单词的精确边界。分词是非分段语言分析处理中首要解决的问题。
2、常见中文分词方法有基于匹配的词典分词、基于标注的机器学习算法及基于理解的深度学习算法,其中基于匹配的词典分词又分为最大匹配分词算法及最短路径分词算法。最大匹配分词算法虽然可以在o(n)时间对文本(如句子、段落等)进行分词,但是效果很差,工业界几乎不会直接使用此类方法作为分词模块的实现方法。
3、最短路径分词基本思想是:根据词典,找出文本中所有可能的词,根据它们构造该文本的有向无环图。不失一般性可以从0开始的自然数表示节点,长度为n的字符串需要n+1个节点,每个词对应一条有向边,第i个字对应的起点为i-1和终点为i。可通过各种策略(词图中所有边的权重都为某个常量、-ln(词的频率)、经-ln函数处理的其它统计模型等)给这些边赋予权重,把分词问题转化为求解从起点0到终点n的最短路径问题。求解分词最短路径问题常用的算法有dijkstra算法和n最短路径算法,但这两种算法都受限于松弛操作,存在分词效率低的问题。
4、具体的,dijkstra算法只需记录每个节点的前驱节点,每次迭代都会依赖当前处理节点的所有的邻接边,无法保证保留的最短路径分词结果是文本正确的分词结果。同时,dijkstra算法使用松弛操作,频繁地用更优的数据替换之前的计算结果,严重扰乱数据结构的状态,存在耗费计算资源、时间复杂度大的问题。
5、n-最短路径算法是dijkstra算法的扩展。n-最短路径算法为每个节点创建一个最小堆,记录迭代中最短的前n种长度的所有路径的前驱节点和相关信息,通过回溯得到最短路径。n-最短路径算法同样使用松弛机制,松弛机制的使用对n-最短路径算法维护多条路径的代价有着决定性的影响:用一个最小堆维护每个节点的n种长度的路径信息,无法让更优的路径信息更早地进入到最小堆中,为了维护这种无序性从而保持n-最短路径结果,最小堆需要频繁的操作,松弛操作会进一步降低n-最短路径算法的效率低,导致较高的时间复杂度。
技术实现思路
1、本文用于解决现有技术中采用基于松弛操作的图最短路径方法(如dijkstra算法和n最短路径算法)分词时存在分词效率低、时间复杂度高的问题。
2、为了解决上述技术问题,本文第一方面提供一种文本分词方法,所述方法包括:
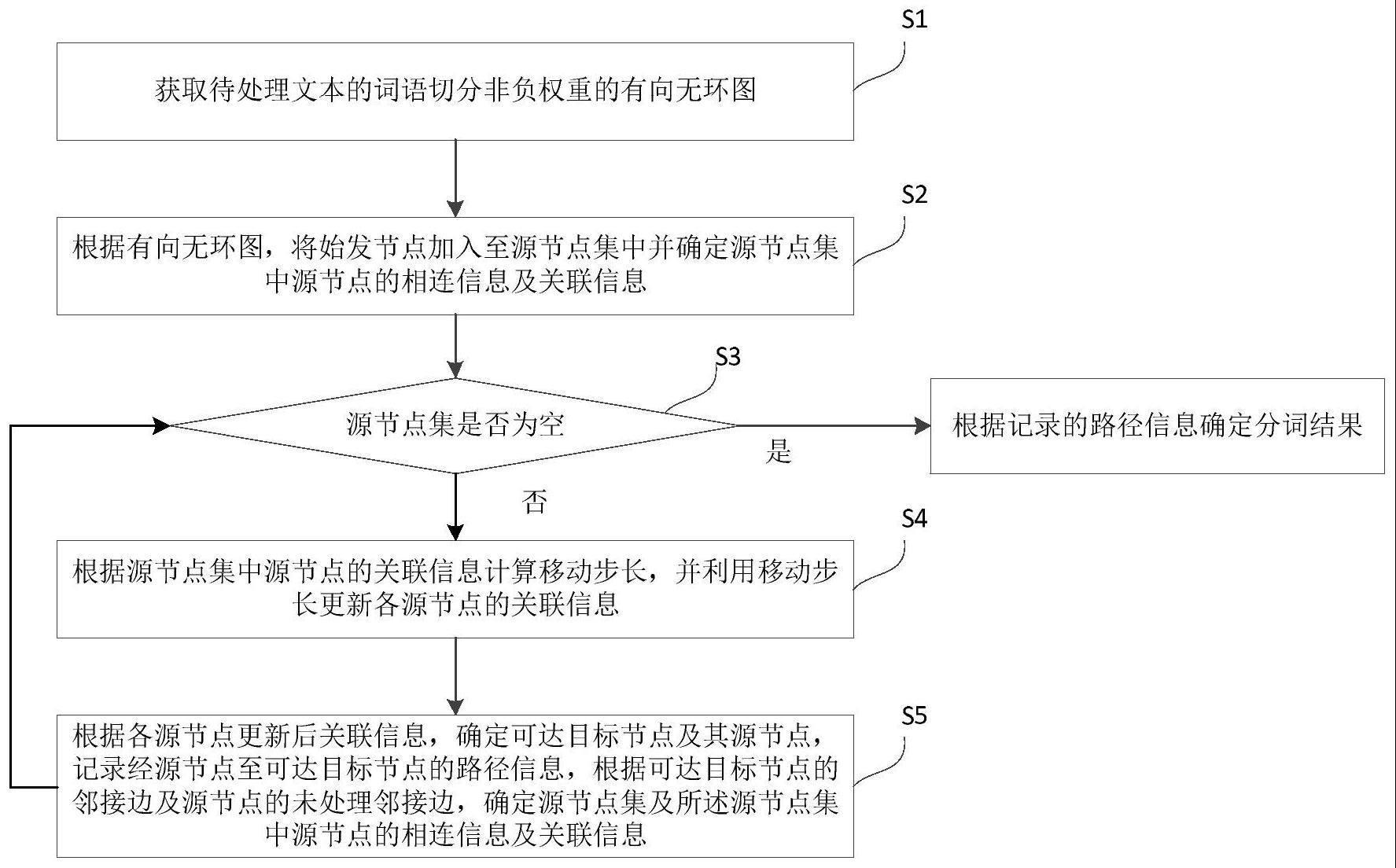
3、s1,获取待处理文本的词语切分非负权重的有向无环图;
4、s2,根据所述有向无环图,将始发节点加入至源节点集中并确定源节点集中源节点的相连信息及关联信息,所述源节点的相连信息包括待处理邻接边及目标节点,所述待处理邻接边为源节点权重最小的未处理邻接边,所述目标节点为所述待处理邻接边邻接的非源节点,所述源节点的关联信息反映源节点与目标节点间邻接边的可移动权重信息;
5、s3,判断所述源节点集是否为空,若是,则根据记录的路径信息确定分词结果,若否,则执行步骤s4;
6、s4,根据所述源节点集中源节点的关联信息计算移动步长,并利用移动步长更新各源节点的关联信息;
7、s5,根据各源节点更新后关联信息,确定可达目标节点及其源节点,记录经源节点至可达目标节点的路径信息,根据可达目标节点的邻接边及源节点的未处理邻接边,确定所述源节点集及所述源节点集中源节点的相连信息及关联信息,跳转至步骤s3。
8、作为本文进一步实施例中,经源节点至可达目标节点的路径信息包括:经源节点至可达目标节点所在路径的节点信息及经源节点至可达目标节点的权重。
9、作为本文进一步实施例中,每一节点关联一线性表,用于存储每一节点预定的前n种路径权重值的路径信息,其中,线性表中有多条记录,每条记录由记录号、路径权重值、一个或多个前驱节点及前驱节点的记录号组成。
10、本文第二方面提供一种文本分词装置,包括:
11、分析单元,用于分析待处理文本,得到待处理文本的词语切分非负权重的有向无环图;
12、初始化单元,用于根据所述有向无环图,将始发节点加入至源节点集中并确定源节点集中源节点的相连信息及关联信息,所述源节点的相连信息包括待处理邻接边及目标节点,所述待处理邻接边为源节点权重最小的未处理邻接边,所述目标节点为所述待处理邻接边邻接的非源节点,所述源节点的关联信息反映源节点与目标节点间邻接边的可移动权重信息;
13、控制单元,用于判断所述源节点集是否为空,若是,则根据记录的路径信息确定分词结果,若否,则启动计算单元;
14、计算单元,用于根据所述源节点集中源节点的关联信息计算移动步长,并利用移动步长更新各源节点的关联信息;
15、移动和更新单元,用于根据各源节点更新后关联信息,确定可达目标节点及其源节点,记录经源节点至可达目标节点的路径信息,根据可达目标节点的邻接边及源节点的未处理邻接边,确定所述源节点集及所述源节点集中源节点的相连信息及关联信息。
16、本文第三方面提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现前述任一实施例所述文本分词方法。
17、本文第四方面提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被计算机设备的处理器运行时,执行根据前述任一实施例所述文本分词方法的指令。
18、本文提供的文本分词方法及装置,通过将已确定路径的节点置于源节点集中,且为源节点集中节点确定相连信息及关联信息,源节点的相连信息包括待处理邻接边及目标节点,待处理邻接边为源节点权重最小的未处理邻接边,所述目标节点为所述待处理邻接边邻接的非源节点,关联信息反映源节点与目标节点间邻接边的可移动权重信息,基于源节点集中节点的相连信息及关联信息迭代确定路径信息,使得每一次迭代中,都向前移动相同的路径长度,且会计算出一个或多个节点的路径信息,并稳定的地向其它节点逼近,从而依次得到最优路径信息,本文充分利用最短路径问题的内在的数据并行性,避免使用松弛机制引入的各种问题,能够降低时间复杂度,提高文本分词效率。
19、进一步的,在并行计算环境中,为了提高分词系统的运行效率,可利用并行计算,如数据级并行,处理多个节点的累计权重及剩余权重。具体地,可把所有正处理状态节点的剩余权重或累计权重存储到对应的数组中,用向量操作计算剩余权重或累计权重,所述路径寻优控制组可按照如下结构体进行设置:
20、{indexofremainder、indexofreduced、from、to、index};
21、其中,indexofremainder为第一节点的剩余权重在数组中的索引,indexofreduced为第一节点的累计权重在数组中的索引。数组中某些位置的元素可能没有索引指向,当数组的存储密度(数组中实际元素数量/(数组中元素的最大索引值+1))小于某临界值时,把数组中大索引指向的元素移到前面的空闲位置上,以提高数组的存储密度。具体可把数组划分为多个等长互不相交的子数组,每个数组用一个最小堆维护其空闲元素位置,优先使用更靠近数组头部的子数组,优先使用子数组中索引位置更小的存储空间,在存储密度小于某值时,把离数组头部最远的子数组存储的数据移动到其它子数组中。
22、为让本文的上述和其他目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附图式,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!