医学编码方法及装置与流程
1.本公开主要涉及医学信息技术领域。更具体地,本公开涉及医学编码方法及装置。
背景技术:
2.医学编码是临床试验数据管理过程中的重要步骤或关键环节。需要编码的数据通常来自病例报告表(case report form,简称“crf”)采集过程中自由填写的文本内容,包括患者的病史、疾病诊断、不良事件、合并用药等内容。由于研究者在地域、语言、民族、文化、知识背景等方面的差异,导致对同一术语的表达描述也存在一定差异,而编码的目的就是通过术语的标准化为药物的安全性和疗效数据分析提供正确合理的分析信息。
3.传统医学编码一般为线下编码,首先由医学编码人员获取电子数据捕获系统(electronic data capture system,简称“edc系统”)内原始数据集交付技术人员,然后由技术人员使用sas宏或其他工具根据官方医学词典(如whodrug和/或meddra)对数据进行自动编码,生成结果文件(包含自动匹配与未自动匹配文件)后返给医学编码人员;由医学编码人员根据官方医学词典对未能自动编码的数据进行人工编码,然后再次传递给技术人员,技术人员将上述数据合并后交付医学编码审核人员审核,审核通过后编码工作结束,审核有误时文件需再次移交医学编码人员编码,医学编码人员进行修改后,再由技术人员合并数据并交由医学编码审核人员审核,直至所有结果文件审核通过。当edc官方医学词典版本升级或edc数据集更新时,编码工作再次进入循环。以上步骤过程繁琐,不仅容易造成编码结果前后不一致,而且人工编码结果无法复用,当开始新试验医学编码时,之前在其它试验已编码完成但是官方医学词典未能自动匹配的术语,仍然需要医学编码人员再次手动编码,大大增加了时间成本和人力成本,降低了医学编码效率。
技术实现要素:
4.为了至少部分地解决背景技术中提到的技术问题,本公开的方案提供了一种医学编码方法及装置。
5.根据本公开的第一方面,本公开提供一种医学编码方法,其中,所述方法包括:获取待编码变量名称;将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息;在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
6.可选地,将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码
变量名称的第一编码结果包括:将所述待编码变量名称与医学词典的第一术语名称信息进行匹配,获得与所述待编码变量名称完全匹配的第一术语名称;若所述第一术语名称仅对应一条医学词典信息,则将所述第一术语名称对应的医学词典信息作为所述待编码变量名称的所述第一编码结果;若与所述第一术语名称对应两条或两条以上医学词典信息,则根据预设匹配规则获取其中一条医学词典信息作为所述待编码变量名称的所述第一编码结果。
7.可选地,所述同义词库与所述医学词典相对应,所述同义词库包括扩展术语信息和第二术语名称信息,所述扩展术语信息与所述第二术语名称信息相对应,所述第二术语名称信息与所述医学词典中的所述第一术语名称信息相对应。
8.可选地,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果包括:将所述待编码变量名称与同义词库的扩展术语信息进行匹配,获得与所述待编码变量名称完全匹配的扩展术语名称;根据所述扩展术语名称对应的第二术语名称,在所述医学词典中获得所述待编码变量名称的第二编码结果。
9.可选地,若所述医学词典升级为新版医学词典,所述方法还包括:将已获得的编码结果根据所述新版医学词典进行编码结果更新。
10.可选地,将已获得的编码结果根据所述新版医学词典进行编码结果更新包括:根据所述已获得的编码结果中的变量名称和/或术语名称在所述新版医学词典中进行查找,以获得与所述已获得的编码结果中的变量名称和/或术语名称对应的第三编码结果,并对所述已获得的编码结果进行更新。
11.可选地,将已获得的编码结果根据所述新版医学词典进行编码结果更新包括:将所述已获得的编码结果中的变量名称与所述新版医学词典的第三术语名称信息进行比对,以获得与所述已获得的编码结果中的变量名称对应的第三术语名称,并将所述第三术语名称对应的一条医学词典信息作为所述第三编码结果,并对所述已获得的编码结果进行更新;在根据所述已获得的编码结果中的变量名称无法获得所述第三编码结果的情况下,根据所述已获得的编码结果中的变量名称对应的术语名称在所述新版医学词典中获得与之对应的一条医学词典信息,作为所述第三编码结果,并对所述已获得的编码结果进行更新。
12.根据本公开的第二方面,本公开提供一种医学编码装置,其中,所述装置包括:获取模块,其配置为用于获取待编码变量名称;词典编码模块,其配置为用于将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息;词库编码模块,其配置为用于在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
13.可选地,所述词典编码模块用于采取如下方式将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根
据所述第一术语名称获得所述待编码变量名称的第一编码结果:将所述待编码变量名称与医学词典的第一术语名称信息进行匹配,获得与所述待编码变量名称完全匹配的第一术语名称;若所述第一术语名称仅对应一条医学词典信息,则将所述第一术语名称对应的医学词典信息作为所述待编码变量名称的所述第一编码结果;若与所述第一术语名称对应两条或两条以上医学词典信息,则根据预设匹配规则获取其中一条医学词典信息作为所述待编码变量名称的所述第一编码结果。
14.可选地,所述同义词库与所述医学词典相对应,所述同义词库包括扩展术语信息和第二术语名称信息,所述扩展术语信息与所述第二术语名称信息相互对应,所述第二术语名称信息与所述医学词典中的所述第一术语名称信息相对应。
15.可选地,所述词库编码模块用于采取如下方式将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果:将所述待编码变量名称与同义词库的扩展术语信息进行匹配,获得与所述待编码变量名称完全匹配的扩展术语名称;根据所述扩展术语名称对应的第二术语名称,在所述医学词典中获得所述待编码变量名称的第二编码结果。
16.可选地,所述装置还包括更新模块,其配置为用于在所述医学词典升级为新版医学词典的情况下,将已获得的编码结果根据所述新版医学词典进行编码结果更新。
17.可选地,所述更新模块用于采取如下方式将已获得的编码结果根据所述新版医学词典进行编码结果更新:根据所述已获得的编码结果中的变量名称和/或术语名称在所述新版医学词典中进行查找,以获得与所述已获得的编码结果中的变量名称和/或术语名称对应的第三编码结果,并对原编码结果进行更新。
18.可选地,所述更新模块用于采取如下方式将已获得的编码结果根据所述新版医学词典进行编码结果更新:将所述已获得的编码结果中的变量名称与所述新版医学词典的第三术语名称信息进行比对,以获得与所述已获得的编码结果中的变量名称对应的第三术语名称,并将所述第三术语名称对应的一条医学词典信息作为所述第三编码结果,并对所述已获得的编码结果进行更新;在根据所述已获得的编码结果中的变量名称无法获得所述第三编码结果的情况下,根据所述已获得的编码结果中的变量名称对应的术语名称在所述新版医学词典中获得与之对应的一条医学词典信息,作为所述第三编码结果,并对所述已获得的编码结果进行更新。
19.根据本公开的第三方面,本公开提供一种电子装置,其中,所述电子装置包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器执行所述计算机程序时,实现上述本公开的第一方面的方法。
20.根据本公开的第四方面,本公开提供一种计算机可读存储介质,其中,所述存储介质存储有计算机程序,所述计算机程序被执行时,实现上述本公开的第一方面的方法。
21.本公开的医学编码方法和装置,采用医学词典和同义词库进行自动化医学编码,有效降低了人工参与度,大大提高了医学编码效率。更重要地,通过采用同义词库进行医学编码,有效提高了编码结果的复用率;此外,本公开实现了医学词典升级后的医学编码结果自动更新,避免人工重复劳动,较大地节约了人力成本与时间成本。
附图说明
22.通过参考附图阅读下文的详细描述,本公开示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本公开的若干实施方式,并且相同或对应的标号表示相同或对应的部分其中:
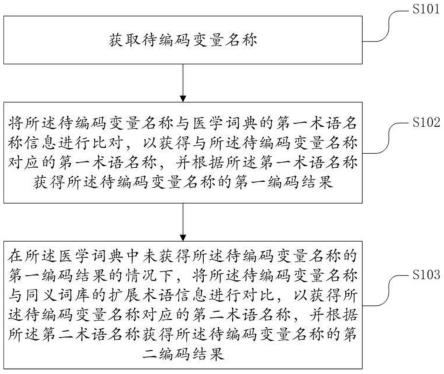
23.图1是示出根据本公开的一个实施例的医学编码方法的流程图;
24.图2是示出根据本公开的一个实施例的医学编码装置的示意性框图。
具体实施方式
25.下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
26.下面结合附图来详细描述本公开的具体实施方式。
27.本公开提供一种医学编码方法。参照图1,图1是示出根据本公开的一个实施例的医学编码方法的流程图。如图1中所示,所述方法包括以下步骤s101-s103。步骤s101:获取待编码变量名称。步骤s102:将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息。步骤s103:在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
28.本公开的医学编码方法和装置,采用医学词典和同义词库进行自动化医学编码,有效降低了人工参与度,大大提高了医学编码效率。更重要地,通过采用同义词库进行医学编码,有效提高了编码结果的复用率。
29.在步骤s101中,可以获取待编码变量名称。
30.根据本公开的实施例,为了实现医学术语的标准化,需将待编码变量名称通过医学编码转换成相对统一的、规范的医学术语,以便为后续药物的安全性和疗效数据分析提供正确合理的分析信息。待编码变量名称可以是不良反应/不良事件、疾病、药物名称等中的一种或多种;待编码变量名称可以从edc系统的原始数据集中获取,可以由系统自动识别获取,也可以由人工录入,在此不做特别限定。
31.在步骤s102中,可以将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息。
32.根据本公开的实施例,可以通过将待编码变量名称与医学词典中的术语名称信息进行比对,从而获得与待编码变量名称相匹配的术语名称,并将该术语名称对应的医学词典信息作为该待编码变量名称的编码结果。
33.优选地,将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果包括:将所述待编码变量名称与医学词典的第一术语名称信息进行匹配,获得与所述待编码变量名称完全匹配的第一术语名称;若所述第一术语名称仅对应一条医学词典信息,则将所述第一术语名称对应的医学词典信息作为所述待编码变量名称的所述第一编码结果;若与所述第一术语名称对应两条或两条以上医学词典信息,则根据预设匹配规则获取其中一条医学词典信息作为所述待编码变量名称的所述第一编码结果。可以理解的是,本公开实施例中,术语名称信息是术语名称的集合,即医学词典中所有术语名称构成的集合称为“术语名称信息”。
34.根据本公开的实施例,官方医学词典可以是meddra或whodrug,其中,meddra(medical dictionary for regulatory activities,监管活动医学词典)为ich(国际人用药品注册技术协调会)国际医学用语词典,收录范围包括:体征和症状、疾病、诊断、治疗的指征、适应症的名称、理化检查的定性结果、外科与内科的处置、医学史、社会史以及家族史等;whodrug广义上称为whodrug global,是医药产品方面最综合的电子词典,其包括世界卫生组织药物词典(who-dd)、世界卫生组织药物词典增强版(who-dde)、世界卫生组织草药词典(who-hd)、综合词典(combined dictionary)4种词典。上述官方医学词典经数据处理后形成一个或多个医学词典数据表进行存储,以便医学编码使用。本公开实施例中,“医学词典”特指官方医学词典经数据处理后形成的一个或多个医学词典数据表。
35.具体地,以meddra为例,获取官方医学词典文件,并解压缩,获取其中的核心文件,如mdhier词典文件(mdhier.asc)和ae_llt词典文件(llt.asc),以行为单位提取核心文件的信息,并按照预设分隔符对所提取的信息进行分割提取,以获得所需的关键信息,按照信息之间的对应关系组合形成一个或多个医学词典数据表进行存储,以获得本公开实施例的与meddra对应的医学词典(以下简称“meddra医学词典”)。
36.举例说明:
37.例如,mdhier.asc中的一行文本为:“10000002$10021608$10021605$10027433$11-β-羟化酶缺乏$各种类固醇合成异常$先天代谢异常类疾病$代谢及营养类疾病$metab$$10010331$n$”,在以“$”符号分割后,拆分为:1
‑“
10000002”、2
‑“
10021608”、3
‑“
10021605”、4
‑“
10027433”、5
‑“
11-β-羟化酶缺乏”、6
‑“
各种类固醇合成异常”、7
‑“
先天代谢异常类疾病”、8
‑“
代谢及营养类疾病”、9
‑“
metab”、10
‑“”
、11
‑“
10010331”、12
‑“
n”,共12个字符串,上述字符串根据1-ptcode(首选语代码)、2-hltcode(高位语代码)、3-hlgtcode(高位组语代码)、4-soccode(系统器官分类代码)、5-ptname(首选语名称)、6-hltname(高位语名称)、7-hlgtname(高位组语名称)、8-socname(系统器官分类名称)的对应规则,保存到m_ae_mdhier表内。
38.类似的,例如,llt.asc中的一行文本为:“10000001$“换气性”肺炎$10081988$$$$$$$n$$”,分割为:1
‑“
10000001”、2
‑““
换气性”肺炎”、3
‑“
10081988”、4
‑“”
、5
‑“”
、6
‑“”
、7
‑“”
、8
‑“”
、9
‑“”
、10
‑“
n”、11
‑“”
,共11个字符串,上述字符串根据1-lltcode(低位语代码)、2-lltname(低位语名称)、3-ptcode(首选语代码)的对应规则,保存到m_ae_llt表内。
39.需要说明的是,上述举例仅列举了部分关键信息的对应规则,其中,低位语(llt,lowest level terms)是医学上的同义词汇,其用最细致的语言描述特定的事件,口语的不
同表达方式与某种语言所特有的事件只能见于这一层级;首选语(pt,preferred term)用来表达独特的、明确的医学概念,是国际医学情报交换的基本用语,首选语下的低位语数量没有限制;高位语(hlt,high level terms)将首选语按解剖学、病理学、生物学、病因学、生理机能等多种方式分类,以用于检索、归类;高位组语(hlgt,high level group terms)是hlt之上更广义的概念;系统器官分类(soc,system organ class)相当于其他医学术语中的系统分类,首选语至少可以连接到一个soc;若两个分隔符“$”之间无字符或为空格,则提取的信息列为“空”或舍弃。除上述关键信息外,官方医学词典中提取的相关字符串可按照预设规则罗列入相应医学词典数据表中或舍弃,在此不再赘述。上述举例仅作为示例,不作为对本公开技术方案的限定。
40.可以理解的是,将官方医学词典文件中不同核心文件提取关键信息后,可按照信息对应关系分别形成不同的医学词典数据表进行存储,如上述实施例,也可以按照信息对应关系整合为一个医学词典数据表,在此不做特别限定。
41.对于“不良反应/不良事件、疾病”等的编码,可采用meddra对应的医学词典。具体地,将待编码变量名称与m_ae_llt表内lltname信息(即第一术语名称信息)进行匹配,获得与待编码变量名称完全匹配的低位语名称(即第一术语名称),若该低位语名称仅对应一条医学词典信息,则将此条医学词典信息,包括:m_ae_llt表中与该低位语名称对应的ptcode、lltcode及对应的m_ae_mdhier表中的hltcode、hltname、hlgtcode、hlgtname、soccode,socname等,作为该待编码变量名称的编码结果;若该低位语名称对应多条医学词典信息,则优先获取m_ae_mdhier表内ptname与待编码变量名称一致的m_ae_mdhier数据集,再找出m_ae_llt表内lltcode与m_ae_mdhier数据集内ptcode一致的数据,并将最终获得的该条医学词典信息作为该待编码变量名称的编码结果;若采用上述匹配规则仍无法获得所需的医学词典信息,则可以选取m_ae_llt表内lltname与待编码变量名称一致的数据集中的首条m_ae_llt数据的ptcode与m_ae_mdhier表中的ptcode进行匹配,并将获得的一条数据词典信息作为该待编码变量名称的编码结果。如果上述处理后仍无法获得编码结果,则匹配失败,可于后续通过同义词库进一步编码。
42.以whodrug为例,获取官方医学词典文件,并解压缩,获取其中的核心文件,如dd词典文件(dd.txt)、dda词典文件(dda.txt)、及ina词典文件(ina.txt),以行为单位提取核心文件的信息,并按照预设字段对所提取的信息进行分割提取,以获得所需的关键信息,按照信息之间的对应关系组合形成一个或多个医学词典数据表进行存储,以获得本公开实施例的与whodrug对应的医学词典(以下简称“whodrug医学词典”)。
43.举例说明:
44.例如,dd.txt中的一行文本为:“000001010024t20ken 01041aldomet[甲基多巴]”,提取前11个字符“00000101002”对应w_dd表内drugcode(药物编号)字段,第31个字符开始到结尾的字符“aldomet[甲基多巴]”对应w_dd表内productname(药物名称)字段,提取后保存到w_dd表内。
[0045]
类似的,例如,dda.txt中的一行文本:“000017040015s02aa”,提取前11个字符“00001704001”对应w_dda表内drugcode(药物代码)字段,第13个-第17个字符“s02aa”对应w_dda表内atccode(解剖-治疗-化学分类代码)字段,第13个字符“s”对应w_dda表内atccode1字段,第13个-第15个字符“s02”对应w_dda表内atccode2字段,第13个-第16个字
符“s02a”对应w_dda表内atccode3字段,第13个-第17个字符“s02aa”对应w_dda表内atccode4字段,全部提取后保存到w_dda表内。
[0046]
同样的,ina.txt中的一行文本:“a01ab 4口腔局部用抗感染和抗菌药物”,提取前7个字符“a01ab”对应w_ina表内atccode字段,第8个字符“4”对应w_ina表内levelcode字段,第9个字符到结尾“口腔局部用皮质类固醇药物”对应w_ina表内atctext(解剖-治疗-化学分类文本)字段。
[0047]
需要说明的是,上述举例仅作为示例,以说明whodrug对应的医学词典的建立方法,不作为对本公开技术方案的限定。其中,在对医学词典文件以行为单位提取信息时,每行文本中的每个空格算作一个字符;atc分类(解剖-治疗-化学分类)为whodrug采用的药物分类系统,该系统将所有药物按照其治疗的解剖学器官/系统,分为14大类(atccode1),然后根据药理学/治疗学进行再分类(atccode2),atccode3和atccode4则是根据化学/药理学/治疗学继续将药物分为不同的亚类。
[0048]
可以理解的是,将官方医学词典文件中不同核心文件提取关键信息后,可按照信息对应关系分别形成不同的医学词典数据表进行存储,如上述实施例,也可以按照信息对应关系整合为一个医学词典数据表,在此不做特别限定。
[0049]
对“用药/药物”进行编码,可采用whodrug对应的医学词典。具体地,将待编码变量名称与w_dd表中productname信息(即第一术语名称信息)进行匹配,获得与待编码变量名称完全匹配的药物名称(即术语名称),若该药物名称仅对应一条医学词典信息,则将此条医学词典信息,包括:drugcode、productname、preferredcode、preferredname、atccode1、atccode2、atccode3、atccode4等,作为该待编码变量名称的编码结果;其中,preferredcode为w_dd表内drugcode后三位数字替换为“001”获得的编码,preferredname为w_dd表内drugcode与preferredcode匹配的首条数据的productname。若该药物名称对应多条医学词典信息,例如对应多个atccode,则可以根据用药目的、适应症等选择合适的atccode,并将对应的整条医学词典信息作为该待编码变量名称的编码结果。如果未获得与待编码变量名称匹配的productname,则医学词典编码失败,可于后续通过同义词库进一步编码。
[0050]
在步骤s103中,可以在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
[0051]
根据本公开的实施例,为了保证编码的统一性与规范性,所述同义词库与所述医学词典相对应,所述同义词库包括扩展术语信息和第二术语名称信息,所述扩展术语信息与所述第二术语名称信息相互对应,所述第二术语名称信息与所述医学词典中的所述第一术语名称信息相对应。本公开实施例的同义词库,其第二术语名称信息来源于对应医学词典的第一术语名称信息,以使同义词库与对应的医学词典建立强相关,便于后续医学编码使用。
[0052]
具体地,本公开实施例的同义词库至少包括扩展术语信息与第二术语名称信息,其中,扩展术语信息为未包含在医学词典中的可能的医学术语表达,第二术语名称信息与
医学词典中的第一术语名称信息相对应,从而使得通过同义词库与医学词典的相互配合使用,可以对未包含在医学词典中的可能的医学术语进行编码。本公开实施例的同义词库,主要用于将未被收录入医学词典的术语表达与医学词典的术语名称建立联系,构成对医学词典的有效补充,从而可以对更多的医学表达进行自动化编码,有效提高医学编码的效率,降低人力成本及时间成本。
[0053]
需要说明的是,本公开中“第一”“第二”仅用于区分相同或类似的对象,而不作为先后顺序的限定。例如,“所述第二术语名称信息与所述医学词典中的所述第一术语名称信息相对应”,意在说明,通过同义词库的第二术语名称信息,可以在医学词典中的第一术语名称信息找到与之匹配的术语名称,从而获得相应的编码结果。
[0054]
优选地,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果包括:将所述待编码变量名称与同义词库的扩展术语信息进行匹配,获得与所述待编码变量名称完全匹配的扩展术语名称;根据所述扩展术语名称对应的第二术语名称,在所述医学词典中获得所述待编码变量名称的第二编码结果。可以理解的是,本公开实施例中,扩展术语信息是扩展术语名称的集合,即同义词库中所有扩展术语名称构成的集合称为“扩展术语信息”。
[0055]
具体地,根据待编码变量名称的性质,选择合适的同义词库,例如,“不良反应/不良事件、疾病”类待编码变量名称,可选择与meddra医学词典对应的同义词库,“用药/药物”类待编码变量名称,可选择与whodrug医学词典对应的同义词库,将待编码变量名称与同义词库的扩展术语信息进行匹配,然后根据匹配的扩展术语信息获得对应的第二术语名称,并根据第二术语名称在对应的医学词典中获得对应的医学词典信息,作为待编码变量名称的编码结果。根据第二术语名称在对应的医学词典中获得对应的医学词典信息的方法同上述医学词典编码方法,在此不再赘述。
[0056]
可以理解的是,若通过上述医学词典编码和同义词库编码仍无法获得编码结果,则可以通过人工编码的方式进行,并将人工编码获得的编码结果相关信息,例如可以包括但不限于:变量名称、术语名称、医学词典版本id等,存入同义词库的对应项中,以补充丰富同义词库,便于后续编码复用。
[0057]
作为本公开一个优选的实施例,医学词典在建立时,根据官方医学词典的版本号生成对应的医学词典的版本id(identity document,识别码),与提取的信息一并存储于相应的医学词典数据表中。
[0058]
进一步优选地,本公开实施例的同义词库包括同义词主库和至少一个同义词项目子库。在采用同义词库进行编码时,可根据实际需要同时或依次选择同义词主库和待编码项目对应的同义词项目子库进行编码,也可以根据需要选择其一进行编码,本公开不做特别限定。
[0059]
作为一种优选的实施例,当官方医学词典升级时,可根据升级版的官方医学词典再次建立对应的医学词典数据表,作为升级版的医学词典,医学词典的版本id与官方医学词典的版本号对应更新。
[0060]
在此情况下,本公开实施例的医学编码方法还包括:将已获得的编码结果根据所述新版医学词典进行编码结果更新。
[0061]
优选地,将已获得的编码结果根据所述新版医学词典进行编码结果更新包括:根据所述已获得的编码结果中的变量名称和/或术语名称在所述新版医学词典中进行查找,以获得与所述已获得的编码结果中的变量名称和/或术语名称对应的第三编码结果,并对所述已获得的编码结果进行更新。
[0062]
具体地,将所述已获得的编码结果中的变量名称与所述新版医学词典的第三术语名称信息进行比对,以获得与所述已获得的编码结果中的变量名称对应的第三术语名称,并将所述第三术语名称对应的一条医学词典信息作为所述第三编码结果,并对所述已获得的编码结果进行更新;在根据所述已获得的编码结果中的变量名称无法获得所述第三编码结果的情况下,根据所述已获得的编码结果中的变量名称对应的术语名称在所述新版医学词典中获得与之对应的一条医学词典信息,作为所述第三编码结果,并对所述已获得的编码结果进行更新。
[0063]
以meddra医学词典为例,将编码结果中的变量名称与新版meddra医学词典中的lltname信息进行比对,找到相匹配的低位语名称,然后将与该低位语名称对应的一条医学词典信息作为更新的编码结果;若无法在新版meddra医学词典中找到与变量名称相匹配的低位语名称,则可以根据编码结果中与该变量名称对应的低位语名称,在新版meddra医学词典中找到对应的一条医学词典信息,作为更新的编码结果。根据低位语名称获得对应的医学词典信息的具体方法同前述meddra医学词典编码方法,在此不再赘述。
[0064]
以whodrug医学词典为例,将编码结果中的变量名称与新版whodrug医学词典中的productname信息进行比对,找到相匹配的药物名称,然后将与该药物名称对应的一条医学词典信息作为更新的编码结果;若无法在新版whodrug医学词典中找到与变量名称相匹配的药物名称,则可以根据编码结果中与该变量名称对应的药物名称,在新版whodrug医学词典中找到对应的一条医学词典信息,作为更新的编码结果。根据药物名称获得对应的医学词典信息的具体方法同前述whodrug医学词典编码方法,在此不再赘述。
[0065]
进一步优选地,对采用whodrug医学词典获得的编码结果进行更新时,若新旧whodrug医学词典中同一药物名称对应的atccode不同,则可以根据用药目的、适应症等在新版whodrug医学词典中选择更合适的atccode,也可以保留原编码结果中的atccode(前提是原编码结果中的atccode同样存在于新版whodrug医学词典中),并给出提示以便人工复核。
[0066]
可以理解的是,若通过上述方法无法在新版医学词典中获得对应的编码结果,则可以通过人工操作,对无法更新的编码结果进行人工编码,以使编码结果与新版医学词典同步。
[0067]
本公开还提供一种医学编码装置。该装置用于执行以上结合图1所描述的医学编码方法实施例中的步骤。
[0068]
参照图2,图2是示出根据本公开的一个实施例的医学编码装置100的示意性框图。该装置100包括获取模块101、词典编码模块102和词库编码模块103。该获取模块101配置为用于获取待编码变量名称。该词典编码模块102配置为用于将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息。该词库编码模块103配
置为用于在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
[0069]
根据本公开的实施例,所述词典编码模块102用于采取如下方式将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果:将所述待编码变量名称与医学词典的第一术语名称信息进行匹配,获得与所述待编码变量名称完全匹配的第一术语名称;若所述第一术语名称仅对应一条医学词典信息,则将所述第一术语名称对应的医学词典信息作为所述待编码变量名称的所述第一编码结果;若与所述第一术语名称对应两条或两条以上医学词典信息,则根据预设匹配规则获取其中一条医学词典信息作为所述待编码变量名称的所述第一编码结果。
[0070]
根据本公开的实施例,所述同义词库与所述医学词典相对应,所述同义词库包括扩展术语信息和第二术语名称信息,所述扩展术语信息与所述第二术语名称信息相互对应,所述第二术语名称信息与所述医学词典中的所述第一术语名称信息相对应。
[0071]
根据本公开的实施例,所述词库编码模块103用于采取如下方式将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果:将所述待编码变量名称与同义词库的扩展术语信息进行匹配,获得与所述待编码变量名称完全匹配的扩展术语名称;根据所述扩展术语名称对应的第二术语名称,在所述医学词典中获得所述待编码变量名称的第二编码结果。
[0072]
根据本公开的实施例,所述装置还包括更新模块,其配置为用于在所述医学词典升级为新版医学词典的情况下,将已获得的编码结果根据所述新版医学词典进行编码结果更新。
[0073]
根据本公开的实施例,所述更新模块用于采取如下方式将已获得的编码结果根据所述新版医学词典进行编码结果更新:根据所述已获得的编码结果中的变量名称和/或术语名称在所述新版医学词典中进行查找,以获得与所述已获得的编码结果中的变量名称和/或术语名称对应的第三编码结果,并对所述已获得的编码结果进行更新。
[0074]
优选地,所述更新模块用于采取如下方式将已获得的编码结果根据所述新版医学词典进行编码结果更新:将所述已获得的编码结果中的变量名称与所述新版医学词典的第三术语名称信息进行比对,以获得与所述已获得的编码结果中的变量名称对应的第三术语名称,并将所述第三术语名称对应的一条医学词典信息作为所述第三编码结果,并对所述已获得的编码结果进行更新;在根据所述已获得的编码结果中的变量名称无法获得所述第三编码结果的情况下,根据所述已获得的编码结果中的变量名称对应的术语名称在所述新版医学词典中获得与之对应的一条医学词典信息,作为所述第三编码结果,并对所述已获得的编码结果进行更新。
[0075]
可以理解的是,关于以上参照图2描述的实施例中的医学编码装置,其中各个模块执行操作的具体方式已经在结合图1所描述的医学编码方法方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0076]
本公开实施例还提供一种电子装置,其中,所述电子装置包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器执行所述计算机程序时,实现如下步骤:获取待编码变量名称;将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息;在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
[0077]
可以理解的是,所述处理器执行所述计算机程序时实现的步骤与上述方法中的各个步骤的实现方式基本一致,具体方式已经在有关医学编码方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0078]
在另一方面中,本公开提供一种计算机可读存储介质,其中,所述存储介质存储有计算机程序,所述计算机程序被执行时,实现如下步骤:获取待编码变量名称;将所述待编码变量名称与医学词典的第一术语名称信息进行比对,以获得与所述待编码变量名称对应的第一术语名称,并根据所述第一术语名称获得所述待编码变量名称的第一编码结果;所述第一编码结果为所述医学词典中与所述待编码变量名称对应的一条医学词典信息;在所述医学词典中未获得所述待编码变量名称的第一编码结果的情况下,将所述待编码变量名称与同义词库的扩展术语信息进行对比,以获得所述待编码变量名称对应的第二术语名称,并根据所述第二术语名称获得所述待编码变量名称的第二编码结果;所述第二编码结果为所述医学词典中与所述第二术语名称对应的一条医学词典信息。
[0079]
可以理解的是,所述处理器执行所述计算机程序时实现的步骤与上述方法中的各个步骤的实现方式基本一致,具体方式已经在有关医学编码方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0080]
以上对本公开实施例进行了详细介绍,本文中应用了具体个例对本公开的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本公开的方法及其核心思想;同时,对于本领域的一般技术人员,依据本公开的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本公开的限制。
[0081]
应当理解,本公开的权利要求、说明书及附图中的术语“第一”和“第二”、等是用于区别不同对象,而不是用于描述特定顺序。本公开的说明书和权利要求书中使用的术语“包括”和“包含”指示所描述特征、整体、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。
[0082]
还应当理解,在此本公开说明书中所使用的术语仅仅是出于描述特定实施例的目的,而并不意在限定本公开。如在本公开说明书和权利要求书中所使用的那样,除非上下文清楚地指明其它情况,否则单数形式的“一”、“一个”及“该”意在包括复数形式。还应当进一步理解,在本公开说明书和权利要求书中使用的术语“和/或”是指相关联列出的项中的一个或多个的任何组合以及所有可能组合,并且包括这些组合。
[0083]
以上对本公开实施例进行了详细介绍,本文中应用了具体个例对本公开的原理及
实施方式进行了阐述,以上实施例的说明仅用于帮助理解本公开的方法及其核心思想。同时,本领域技术人员依据本公开的思想,基于本公开的具体实施方式及应用范围上做出的改变或变形之处,都属于本公开保护的范围。综上所述,本说明书内容不应理解为对本公开的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1