一种基于XGBoost的车辆行驶工况识别方法与流程
一种基于xgboost的车辆行驶工况识别方法
技术领域
1.本发明涉及一种车辆行驶工况识别方法,尤其是一种基于xgboost的车辆行驶工况识别方法,属于智能网联汽车数据分析技术领域。
背景技术:
2.当前国内汽车保有量不断增长,车联网数据也正在爆发式增长,而这些数据犹如巨大的矿产资源,利用数据分析、机器学习、深度学习从大量的车联网数据中挖掘出有价值的信息,对于提高用户安全出行行为以及车辆节能环保具有重要的意义。
3.行驶工况反映汽车在行驶过程中速度随时间的变化曲线,通过该曲线可以看出汽车在运行过程中所处的道路环境类型,汽车的行驶工况影响着汽车的安全性与经济性能等,实时的分析汽车所处的工况,对各个汽车生产厂家在开发新能源汽车的过程中具有重要的参考意义,对无人驾驶等策略研究提供丰富的研究素材,同时通过研究汽车的行驶工况,有利于设计更为精准的能量管理策略,增强汽车的燃油利用率。
4.因而在汽车远程监控管理系统的功能开发和车辆控制器控制策略设计过程中,对汽车运行数据进行挖掘分析,将行驶工况这一信息引入到监控管理系统和车辆控制策略中,来提高车辆行驶安全性和节能环保是一个亟待解决的问题。为此,提出一种基于xgboost的车辆行驶工况识别方法,显得尤为重要。
技术实现要素:
5.本发明的目的在于针对现有技术存在的问题,提出一种基于xgboost的车辆行驶工况识别方法,能够对车辆行驶工况进行识别与统计,充分利用现有车辆各硬件设施性能,从而对车辆行驶道路环境类型进行进一步研究分析,实现汽车远程监控管理系统功能开发以及设计良好的车辆控制器控制策略。
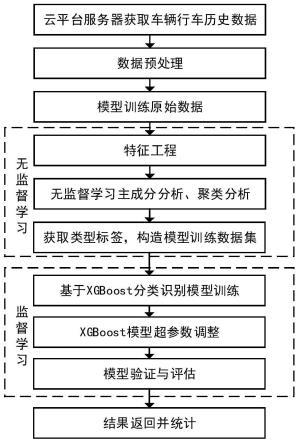
6.本发明的具体技术方案如下:一种基于xgboost的车辆行驶工况识别方法,包括如下具体步骤:
7.步骤1,由企业车联网服务云平台数据库中获取车辆某一天24小时有效历史行车数据,所述行车历史数据为依维柯现有车辆网硬件设备能够采集到的数据信息,包括数据采集时间、车速、累计里程、经度、纬度、大气压力(kpa)、发动机净输出扭矩(%)、发动机转速(rpm)、发动机燃料流量(l/h)、反应剂余量(%)、进气量(kg/h)、scr入口温度(℃)、dpf压差(kpa)、发动机冷却液温度(℃)、油箱液位(%)等,本发明主要所需为数据采集时间、车辆行驶车速和经纬度位置信息这三种。
8.步骤2,对前述步骤中的历史行驶数据进行处理,形成适用xgboost分类算法模型的车辆行驶数据样本;
9.步骤3,对xgboost分类识别模型进行训练数据集准备,通过采集某一地区道路或者采用车辆标准行驶循环工况数据,经处理形成适用于无监督学习算法的初始数据集;
10.步骤4,前述步骤中形成的初始数据集经无监督学习算法学习后,分析确定出初始
数据集中各样本数据行驶工况类型标签,形成分类识别模型训练数据集;
11.步骤5,利用带有行驶工况类别标签的数据集训练xgboost分类识别模型,经超参数调整后,准确率达到最优;
12.步骤6,利用训练好的xgboost车辆行驶工况识别模型对车辆行驶数据样本进行识别,并对行驶工况类型进行统计。
13.进一步的,所述步骤2中,历史行驶数据的处理步骤具体为:
14.步骤2.1,将步骤1获取的历史行车数据表示为data=[t veh_v lon lat],其中车辆数据采集时间t=[t
1 t2…
tn],间隔时间1s采集一次车辆状态信息;
[0015]
车辆运行状态信息为行驶车速veh_v=[v
1 v2…
vn];
[0016]
位置信息为经度lon=[lon
1 lon2…
lonn],纬度lat=[lat
1 lat2…
latn];
[0017]
步骤2.2,待识别行驶数据data分块处理,将行驶数据data从第一个速度不为0的时间点开始以固定行驶时间t进行窗口化划分,得到行驶数据工况块;
[0018]
步骤2.3,对每一个工况块的速度信息差值求取加速度信息;
[0019]
步骤2.4,计算各工况块的特征参数信息,所述特征参数信息为15种,包括平均车速、运行时平均车速、最大车速、速度标准差、平均加速度、最大加速度、平均减速度、最大减速度、加速度标准差、减速度标准差、加速时间比例、减速时间比例、怠速时间百分比、巡航时间百分比及高速时长占比;
[0020]
步骤2.5,各特征参数信息的计算公式分别为:
[0021]
平均车速:
[0022]
运行时平均车速:
[0023]
最大车速:v
max
=max(v1,v2,v3,v4,
…
,vn);
[0024]
速度标准差:
[0025]
平均加速度:
[0026]
最大加速度:a
max
=max(a1,a2,a3,a4,
…
,an);
[0027]
平均减速度:
[0028]
最大减速度:d
max
=max(d1,d2,d3,d4,
…
,dn);
[0029]
加速度标准差:
[0030]
减速度标准差:
[0031]
加速时间比例:
[0032]
减速时间比例:
[0033]
怠速时间百分比:
[0034]
巡航时间百分比:
[0035]
高速时长占比:
[0036]
步骤2.6,所有的工况块对步骤2.5中十五种特征参数进行计算,然后表示为:pre_data=[v
ave v
av v
max v
m a
av a
max d
av d
max a
m d
m a
p d
p s
p v
p h
p
]。
[0037]
进一步的,所述步骤3中,xgboost分类识别模型进行训练数据集准备的具体步骤为:
[0038]
步骤3.1,采集某一区域道路或者采用车辆标准行驶循环工况数据作为初始模型训练数据;
[0039]
步骤3.2,将模型训练数据经步骤2的窗口化处理,并进一步进行复合划分,增加数据集样本数目,以及降低训练数据的事件偶然性和随机性,得到训练数据data
training
;
[0040]
步骤3.3,对步骤3.2中获得的训练数据data
training
进行无监督学习,获取训练样本的真实标签,对训练样本进行归一化处理,计算公式为:
[0041][0042]
步骤3.4,经步骤3.3归一化处理后的数据进行数据降维,数据降维方法至少包括主成分分析法、自动编码器、线性判别分析、奇异值分解及局部线性嵌入方法,选用合适的降维方法对数据进行数据降维,降低模型的研究复杂度,最终获取降维数据data
dimensionality reduction
;
[0043]
步骤3.5,对前述步骤中的降维数据进行聚类分析,找出数据中的类别标签,根据sse和聚类轮廓系数以及结合日常驾驶环境类型,将行驶工况分为四类,即城市拥堵、城市、郊区、高速四种行驶工况,采用k-means++聚类算法进行聚类分析,为了对应前述四类行驶工况,将初始聚类类别设为四种,在聚类初始时需要定义要聚类个数,然后按照四种类型聚类,聚类后对最终聚类中心进行数值分析每一类对应上述具体哪一种行驶工况类型,得到每个数据样本的真实标签,将数据标签返回至步骤3.2的训练数据data
training
中,最终使训练数据中每条样本对应一条行驶工况类型标签。
[0044]
进一步的,所述步骤3.1中,某一区域道路为具有某一地形趋势的区域,以及车辆实际生产过程中长期行驶的区域,经采集得到数据;车辆标准行驶循环工况数据为国际通用的车辆测试标准行驶工况。
[0045]
进一步的,所述步骤4中,分析训练数据集中行驶工况类型标签的具体步骤为:
[0046]
步骤4.1,经步骤3.5聚类分析后的标签返回到训练数据data
training
中,以返回数据标签进行分类,对每一类数据中15种特征参数求取平均值,作为最终聚类中心;
[0047]
步骤4.2,对四个聚类中心数据进行分析比较,通过分析比较对各数据标签赋予相对应的类型。
[0048]
进一步的,所述步骤5中,xgboost分类识别模型训练包括:
[0049]
步骤5.1,对data
training
数据集进行划分,其中数据集中的80%作为训练集,20%的作为验证集;
[0050]
步骤5.2,利用训练集对xgboost机器学习模型进行训练学习,采用cart回归树模型,可使用python3语言调用sklearn库,使用xgboost模块进行模型训练,或使用xgboost库原生接口进行调用学习;
[0051]
步骤5.3,确定学习速率和决策树数量,选择学习速率learning_rate,一般情况下,学习速率的值为0.1,但是,对于不同的问题,理想的学习速率有时候会在0.05~0.3之间波动,选择对应于此学习速率的理想决策树数量,在此选择学习速率为0.1;
[0052]
步骤5.4,给定的学习速率和决策树数量后,进行决策树特定参数调优,树的最大深度max_depth,通常在3~10之间;最小叶子节点样本权重min_child_weight;节点分裂所需的最小损失函数下降值gamma,默认为0;随机采样的比例subsample,一般在0.5~1之间;每棵随机采样的列数的占比colsample_bytree,一般在0.5~1之间,在确定一棵树的过程中,依据经验数值给予各超参数一个初始数值,利用网格搜索和三折交叉验证实现参数寻优;
[0053]
步骤5.5,xgboost正则化参数的调优,lambda和alpha参数调整,降低模型的复杂度,从而提高模型的泛化能力;
[0054]
步骤5.6,降低学习速率learning_rate=0.01,调整决策树数量,重复步骤5.4和步骤5.5,进一步确定理想参数。
[0055]
进一步的,所述步骤6中,xgboost行驶工况识别模型应用步骤包括:
[0056]
步骤6.1,获取步骤2.6中pre_data数据,利用机器学习模型xgboost行驶工况识别模型进行识别,返回数据标签;
[0057]
步骤6.2,返回的数据标签映射为相对应的行驶工况类型信息,对行驶工况类型进行统计分析,获取各类型占比数据,也通过类型占比可以看出车辆在一段时间内趋近于某一种行驶工况。
[0058]
与现有技术相比,本发明的有益效果为:本发明提出的一种基于xgboost的车辆行驶工况识别方法,通过对用户历史行车数据进行分析,识别与统计车辆行驶工况,为实现对用户出行安全性分析和监控提供数据支撑,充分利用现有车载设备以及车联网云平台数据库等条件,通过一套识别及统计方法,即可实现企业车联网云平台内所有车辆出行数据的行驶工况识别与统计或作为关键信息调节车辆控制策略,该方法简单高效,具有较强的泛化能力,可在多种平台下进行部署应用,利于实际生产应用。
附图说明
[0059]
下面结合附图对发明本作进一步的说明。
[0060]
图1是本发明所叙述基于xgboost的车辆行驶工况识别与统计方法流程图。
[0061]
图2是本发明所叙述历史行驶数据进行处理流程图。
[0062]
图3是本发明所叙述训练数据集工况块复合划分原理图。
[0063]
图4是本发明所叙述训练数据行驶工况类型标签分析流程图。
[0064]
图5是本发明所叙述pca主成分分析贡献率以及累积贡献率图。
[0065]
图6是本发明所叙述sse随聚类类别k变化曲线图。
[0066]
图7是本发明所叙述k=4时轮廓系数阴影面积与平均轮廓系数图。
[0067]
图8是本发明所叙述聚类中心数值分析结果图。
[0068]
图9是本发明所叙述xgboost分类模型训练流程图。
[0069]
图10是本发明所叙述行驶工况识别记录及统计流程图。
具体实施方式
[0070]
实施例
[0071]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和具体实施方式,对本发明做进一步的说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
[0072]
如图1所示,基于xgboost的车辆行驶工况识别方法,包括如下步骤:
[0073]
(1)从企业车联网服务云平台数据库中获取车辆具体某一天24小时有效行车历史数据,该行车历史数据主要包括数据采集时间、车辆行驶车速和经纬度位置信息;
[0074]
(2)对历史行驶数据进行处理,形成适用xgboost分类算法模型的车辆行驶数据样本;
[0075]
(3)xgboost分类识别模型训练数据集准备,通过采集某一地区道路或者采用车辆标准行驶循环工况数据,经处理形成适用于无监督学习算法初始数据集;
[0076]
(4)初始数据集无监督学习算法学习后,分析确定出初始数据集中各样本数据行驶工况类型标签,形成分类识别模型训练数据集;
[0077]
(5)利用带有行驶工况类别标签的数据集训练xgboost分类识别模型,经超参数调整后,准确率达到最优;
[0078]
(6)利用训练好的xgboost车辆行驶工况识别模型对车辆行驶数据样本进行识别,并对行驶工况类型进行统计。
[0079]
如图2所示,所述步骤(2)历史行驶数据进行处理步骤包括:
[0080]
(2.1)将步骤(1)获取的数据表示为data=[t veh_v lon lat],其中车辆数据采集时间t=[t
1 t2…
tn],间隔时间1s采集一次车辆状态信息;
[0081]
车辆运行状态信息:行驶车速veh_v=[v
1 v2…
vn];
[0082]
位置信息:经度lon=[lon
1 lon2…
lonn],纬度lat=[lat
1 lat2…
latn];
[0083]
(2.2)待识别行驶数据data分块处理,将行驶数据data从第一个速度不为0的时间点开始以固定行驶时间t进行窗口化划分,得到行驶数据工况块;
[0084]
(2.3)对每一个工况块的速度信息差值求取加速度信息;
[0085]
(2.4)计算各工况块的特征参数信息,包括平均车速、运行时平均车速、最大车速、速度标准差、平均加速度、最大加速度、平均减速度、最大减速度、加速度标准差、减速度标准差、加速时间比例、减速时间比例、怠速时间百分比、巡航时间百分比、高速时长占比,共
15种特征参数;
[0086]
(2.5)所述的特征参数信息计算公式:
[0087]
平均车速:
[0088]
运行时平均车速:
[0089]
最大车速:v
max
=max(v1,v2,v3,v4,
…
,vn);
[0090]
速度标准差:
[0091]
平均加速度:
[0092]
最大加速度:a
max
=max(a1,a2,a3,a4,
…
,an);
[0093]
平均减速度:
[0094]
最大减速度:d
max
=max(d1,d2,d3,d4,
…
,dn);
[0095]
加速度标准差:
[0096]
减速度标准差:
[0097]
加速时间比例:
[0098]
减速时间比例:
[0099]
怠速时间百分比:
[0100]
巡航时间百分比:
[0101]
高速时长占比:
[0102]
(2.6)所有的工况块对(2.5)中15种特征参数进行计算,然后表示为:
[0103]
pre_data=[v
ave v
av v
max v
m a
av a
max d
av d
max a
m d
m a
p d
p s
p v
p h
p
]
[0104]
如图4所示,所述步骤(3)xgboost分类模型训练数据准备步骤包括:
[0105]
(3.1)采集某一区域道路或者采用车辆标准行驶循环工况数据作为初始模型训练数据;
[0106]
(3.2)所述的某一区域道路为具有某一地形趋势的区域,以及车辆实际生产过程中长期行驶的区域,经采集得到数据;
[0107]
(3.3)所述的车辆标准行驶循环工况数据为国际通用的车辆测试标准行驶工况;
[0108]
(3.4)将模型训练数据进行步骤(2)窗口化处理,并进一步进行复合划分,如图3所示,增加数据集样本数目,以及降低训练数据的事件偶然性、随机性,得到训练数据data
training
;
[0109]
(3.5)无监督学习,获取训练样本的真实标签,对训练样本进行归一化处理,计算公式为:
[0110][0111]
(3.6)经步骤(3.5)归一化处理后的数据进行数据降维,常用的数据将为方法有主成分分析法(pca)、自动编码器(ae)、线性判别分析(lda)、奇异值分解(svd)、局部线性嵌入(lle)等方法,选用合适的将为方法对数据进行数据将为,降低模型的研究复杂度,在这里选用主成分分析方法进行数据降维,如图5所示,一般可以认为累积贡献率大于80%前n个主成分即可表达出初始数据集代表信息,为此,在这里选取累积贡献率大于85%的前四个主成分代表初始训练数据,得到降维数据data
dimensionality reduction
。
[0112]
(3.7)降维数据进行聚类分析,找出数据中的类别标签,如图6和7所示,根据sse和聚类轮廓系数曲线,可以看出当聚类类别k=4时,sse曲线出现拐点,利用肘部法则,k=4为最佳聚类类别数,并且针对每一类别的轮廓系数面积阴影均超过样本呢平均轮廓系数虚线,故聚类个数合理的,进一步结合日常驾驶环境类型,可将行驶工况分为四类,即城市拥堵、城市、郊区、高速四种行驶工况,目前常用的聚类算法有,基于划分k-means、k-medoids、k-modes、k-medians、kernel k-means,基于层次birch、cure、chameleon,基于密度dbscan、optics、denclu等,综合考虑数据样本以及分类任务,采用k-means++聚类算法进行聚类分析,初始聚类类别为四种,得到每个数据样本的真实标签,将数据标签返回到步骤(3.4)训练数据data
training
中,至此训练数据中每条样本对应一条行驶工况类型标签。
[0113]
如图5所示,所述步骤(4)分析训练数据集中行驶工况类型标签步骤包括:
[0114]
(4.1)经步骤(3.7)聚类分析后标签返回到训练数据data
training
中,以返回数据标签进行分类,对每一类数据中15种特征参数求取平均值,作为最终聚类中心,如图8所示,所得到的聚类中心对各特征参数数值分析后,映射相应的行驶工况类型标签,对于高速工况,从图中分析其最高车速100.4600km/h、平均车速83.770km/h相对于其它三种类型均为最大,加速度相关的特征相对最小,如最大加速度0.8155,最小减速度-3.5118,即速度波动相对于其余三种较小,巡航时间占比0.98最大,怠速时间占比0.0105最小,拥堵工况则与之相反,其余两种工况介于高速和拥堵之间。
[0115]
(4.2)对四个聚类中心数据进行分析比较,通过分析比较对各数据标签赋予相对应的类型。
[0116]
如图9所示,所述步骤(5)xgboost分类识别模型训练包括:
[0117]
(5.1)对data
training
数据集进行划分,其中数据集中的80%作为训练集,20%的作为验证集;
[0118]
(5.2)利用训练集对xgboost机器学习模型进行训练学习,xgboost是一种提升树
模型,是将许多树模型集成在一起,形成一个很强的分类器,所用到的树模型则是cart回归树模型,可使用python语言调用sklearn库,使用xgboost模块进行模型训练,或使用xgboost库原生接口进行调用学习;
[0119]
(5.3)确定学习速率和决策树数量,选择学习速率learning_rate,一般情况下,学习速率的值为0.1,但是,对于不同的问题,理想的学习速率有时候会在0.05~0.3之间波动,选择对应于此学习速率的理想决策树数量,在此选择学习速率为0.1;
[0120]
(5.4)给定的学习速率和决策树数量后,进行决策树特定参数调优,树的最大深度max_depth,通常在3~10之间;最小叶子节点样本权重min_child_weight;节点分裂所需的最小损失函数下降值gamma,默认为0;随机采样的比例subsample,一般在0.5~1之间;每棵随机采样的列数的占比colsample_bytree,一般在0.5~1之间,在确定一棵树的过程中,依据经验数值给予各超参数一个初始数值,利用网格搜索和三折交叉验证实现参数寻优;
[0121]
(5.5)xgboost正则化参数的调优,lambda和alpha参数调整,降低模型的复杂度,从而提高模型的泛化能力;
[0122]
(5.6)降低学习速率learning_rate=0.01,调整决策树数量,重复步骤(5.4)和步骤(5.5),进一步确定理想参数。
[0123]
如图10所示,xgboost行驶工况识别模型应用步骤包括:
[0124]
(6.1)获取步骤(2)中pre_data数据,利用机器学习模型xgboost行驶工况识别模型进行识别,返回数据标签;
[0125]
(6.2)返回的数据标签映射为相对应的行驶工况类型信息,对行驶工况类型进行统计分析,获取各类型占比数据,也通过类型占比可以看出车辆在一段时间内趋近于某一种行驶工况。
[0126]
在具体生产部署应用时,本发明可以运行在在线云平台服务器用户终端或中,应用部署较为灵活,可应用于多种服务框架中,作为一种简单高效的分析识别方法工具,通过调用企业内部车联网服务云平台数据库或车辆终端实时进行实时分析识别,并将识别结果传递给车联网远程监控服务云平台或车辆控制器,实现对用户驾驶车辆行驶工况分析与追踪,保障驾驶员行车安全性,或作为关键信息制定良好的控制策略,提高车辆节能环保。
[0127]
总体来说,本发明提供了一种简单高效灵活泛化能力强的算法识别模型,利用大量车辆行驶数据进行分析,从大量用户行车数据中获取驾驶员在驾驶车辆时车辆所处的行驶工况状态信息,探寻车辆在行驶过程中表现出的行驶环境变化规律,以便后续结合数据挖掘、机器学习、深度学习等技术对车辆以及用户画像模型开发,以及根据车辆行驶时工况变化信息设计更加完善车辆控制策略;对于识别出的长期处于特定行驶工况的车辆,可对应车辆驾驶员制定安全教育推荐项目、ubi车险方案等风险管理措施,提高道路交通安全性并降低企业运营风险。
[0128]
除上述实例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1