移动轨迹大数据驱动的异常轨迹检测方法、系统和电子设备
1.本发明涉及移动轨迹大数据驱动的异常轨迹检测技术领域,特别涉及一种移动轨迹大数据驱动的异常轨迹检测方法、系统和电子设备。
背景技术:
2.轨迹异常通常指在空间上偏离其他轨迹或发生某些偏离预期的行为,例如出租车的绕路行为、风向突变的飓风、盘旋绕行的飞机、频繁改变航向的渔船等。出租车作为城市中出行的主要交通工具之一,出行带来了极大的便利。但是,部分出租车司机为了从中获得更多利益,恶意地选择行驶比正常路径更长的路线,造成了服务市场的混乱和侵犯了乘客的利益。为此,基于移动轨迹大数据对乘客出行轨迹的异常情况进行检测,对提高出租车的服务质量和保护乘客的基本利益具有重要的指导意义和实际的应用价值。
3.当前,现有的大多数异常轨迹检测的研究仅仅挖掘分析了轨迹在空间上呈现的异常情况。但是,在实际生活中,关于绕行行为产生的异常轨迹不仅是在空间上的异常,而且也是通过乘客在持续时间和实际行驶距离上产生的成本异常,以定义乘客出行轨迹的异常。由此,现有的检测方法在检测效率、准确识别绕路行为的异常轨迹方面仍存在一定的局限性,在检测绕行的异常轨迹中没有充分考虑实际行驶距离和行驶时长与轨迹绕行之间的相关性,从而导致异常轨迹检测准确性低的技术问题。
技术实现要素:
4.针对上述问题,本发明提出了一种移动轨迹大数据驱动的异常轨迹检测方法、系统和电子设备,能够解决传统方法检测效率低、无法准确识别绕路行为的异常轨迹等问题,以及识别不按正常路线行驶、绕路等现象的异常行为。
5.为了实现上述目的,本发明所采用的技术方案如下:
6.一种移动轨迹大数据驱动的异常轨迹检测方法,其特征在于,包括以下步骤:
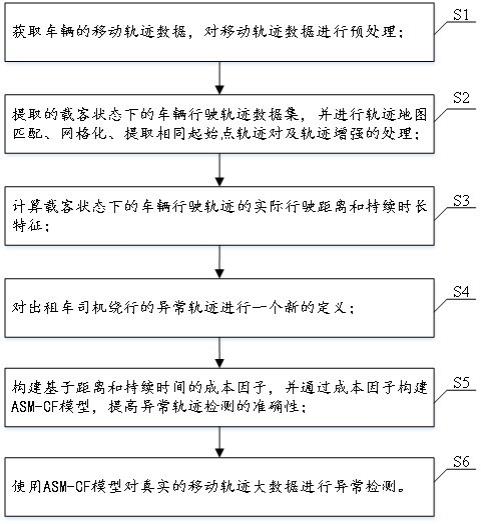
7.s1:获取车辆的移动轨迹数据,对移动轨迹数据进行预处理;
8.s2:提取载客状态下的车辆行驶轨迹数据集,并进行轨迹地图匹配、网格化、相同起始点轨迹对提取以及对所述轨迹对中的轨迹进行增强处理;
9.s3:计算载客状态下的车辆行驶轨迹的实际行驶距离和持续时长特征;
10.s4:重新定义出租车司机绕行的异常轨迹,将异常轨迹定义为在形状上不同且具有较长的实际行驶距离和持续时间的行驶轨迹;
11.s5:构建基于实际行驶距离和持续时间的成本因子,通过成本因子构建asm-cf模型,并通过asm-cf模型对真实的出租车移动轨迹大数据进行异常轨迹检测;
12.s6:输出异常轨迹检测结果。
13.进一步地,在hadoop分布式计算平台下,基于spark并行处理框架,s2的具体操作步骤包括:
14.s201:对预处理后的移动轨迹大数据进行提取,得到运营状态连续为111
…
10的轨
迹数据,其中载客状态记为1,空车状态记为0;
15.s202:对所述运营状态连续为111
…
10的轨迹数据进行数据剔除,仅保留每一条载客状态下的车辆行驶轨迹的经纬度和时间数据;
16.s203:根据s202处理后的载客状态下的车辆行驶轨迹数据,对其进行地图匹配,得到车辆在实际道路网络上的行驶轨迹;
17.s204:根据s203得到的匹配后的载客状态下的车辆行驶轨迹数据,对道路网络进行栅格化,得到网格序列轨迹,统计网格内起始点数量,提取具有相同起始点的轨迹对;
18.s205:对具有相同起始点的轨迹对内的行驶轨迹进行增强处理,得到以连续网格序列为代表的网格映射轨迹。
19.进一步地,s201的具体步骤包括:
20.s2011:读取hdfs文件中的移动轨迹大数据,并转化为spark中的rdd弹性分布数据集;
21.s2012:对所述rdd弹性分布数据集进行分片并过滤掉gps状态为0的无效轨迹点的数据,获得第一保留数据,所述第一保留数据包括车辆id、运营状态、时间和经纬度信息;
22.s2013:将所述第一保留数据按照车辆id排序,查找车辆id相同的运营状态连续为111
…
10的轨迹数据;
23.s2014:保留运营状态连续为111
…
10的轨迹数据,即载客状态下的车辆行驶轨迹数据。
24.进一步地,s203的具体步骤包括:
25.s2031:读取s2014所述的载客状态下的轨迹数据,再读取地图数据并对地图进行栅格处理,将gps观测点匹配到最近的栅格,并以该gps观测点为圆心,以50米为半径的圆区域作为误差区域,对误差区域内的路段作投影,以获取匹配候选路段及候选点;
26.s2032:根据载客状态下的轨迹数据与路网数据的特征,计算观测概率和转移概率,构建隐马尔可夫模型,且观测概率和转移概率的计算公式为:
27.观测概率的计算公式为:
[0028][0029]
其中,p
t
为所述载客状态下的行驶轨迹中在t时刻的待匹配轨迹点,ri为轨迹点p
t
的第i个候选路段,x
t,i
为轨迹点p
t
在候选路段i上的候选点,circle为两点间的地球表面距离,σz为待匹配轨迹点的标准偏差,σz=1.4826median
t
(||p
t-x
t,i
||
circle
);
[0030]
转移概率的计算公式为:
[0031][0032]
其中,d
t
=|||p
t-p
t+1
||
circle-||x
t,i-x
t+1,i
||
route
|,轨迹点p
t+1
与轨迹点p
t
为相邻轨迹点,x
t+1,i
为轨迹点p
t+1
在候选路段i上的候选点,route为两点间在路网中的距离;
[0033]
s2033:通过维特比算法利用观测概率和转移概率模型公式,计算得出概率最大的
一条匹配轨迹,从而得到最优的匹配路径,以及匹配后的每一条行驶轨迹的轨迹点的经纬度。
[0034]
进一步地,s204的具体步骤包括:
[0035]
s2041:提取载客状态下行驶轨迹的上车点与下车点的经纬度信息;
[0036]
s2042:将道路网络进行500
×
500m网格大小的划分,并将行驶轨迹的起始点映射到网格道路网络中,统计每一个网格的起始点的数量,得到具有相同起始点的多个轨迹对。
[0037]
进一步地,s205的具体步骤包括:
[0038]
s2051:将所述轨迹对中的各条行驶轨迹映射到网格尺寸为100
×
100m的路网中,得到网格映射轨迹;
[0039]
s2052:对s2051的网格映射轨迹进行增强处理,即将轨迹经过的网格全部记录,得到连续的网格映射轨迹。
[0040]
进一步地,s3具体步骤包括:
[0041]
s301:基于所述载客状态下的行驶轨迹,根据半正矢公式计算行驶轨迹的实际行驶距离s
t
和行驶持续时间δt
t
以及经度δlon和纬度δlat:
[0042][0043]
δt
t
=t
d-ts[0044]
δlon=lon
i+1-loni[0045]
δlat=lat
i+1-lati[0046]
其中,n为每一条行驶轨迹中的轨迹点总数,loni,lon
i+1
,lati,lat
i+1
分别为当前轨迹点与下一个轨迹点的经度和纬度,ts和td分别为轨迹起始点的时间戳,r为取值6371千米的地球半径;
[0047]
s302:剔除实际行驶距离和持续时间分别小于3千米和5分钟的行驶轨迹。进一步地,所述s5的具体步骤包括:
[0048]
s501:计算所述连续的网格映射轨迹之间的轨迹距离,轨迹距离越小则表示两条轨迹的相似性越大;反之,轨迹距离越大则表示两条轨迹的相似性越小,轨迹距离计算公式为:
[0049][0050]
其中,|ti\tj|表示连续的网格映射轨迹ti与连续的网格映射轨迹tj的网格差集的长度,i,j∈1,2,
…
,n且i≠j,n为每一个轨迹对的轨迹总数,|ti∩tj|表示ti与tj的网格并集的长度;
[0051]
s502:根据s301所述的实际行驶距离s
t
和持续时间δt
t
,获得成本因子cf
t
,并将成本因子进行正则化得到一个[0,1]中的值;
[0052]
cf
t
=s
t
×
δt
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0053][0054]
其中,i∈1,2,
…
,n,n为每一个轨迹对的轨迹总数;
[0055]
s503:通过差集和并集得到所述连续的网格映射轨迹基于形状的轨迹得分ss(ti);
[0056][0057]
其中,|ti\tj|表示连续的网格映射轨迹ti与连续的网格映射轨迹tj的网格差集的长度,i,j∈1,2,
…
,n且i≠j,n为每一个轨迹对的轨迹总数,|ti∩tj|表示ti与tj的网格并集的长度;
[0058]
s504:根据s502中正则化的成本因子和s503中基于形状的轨迹得分ss(ti)构建asm-cf模型,基于asm-cf模型得到轨迹的异常得分s(ti);
[0059][0060]
s505:对每一个轨迹对的异常得分进行降序排序,取每一个轨迹对的第k个异常得分为阈值δ,其中k为每一个轨迹对中异常轨迹的数量;
[0061]
s506:将所述的异常得分s(ti)与所述的阈值δ进行比较,如果异常得分大于或等于阈值,表明该条行驶轨迹是异常的;反之,表明该条行驶轨迹是正常的。
[0062]
一种移动轨迹大数据驱动的异常轨迹检测系统,其特征在于,包括轨迹数据获取模块、轨迹数据预处理模块、模型构建模块、轨迹检测模块;
[0063]
所述轨迹数据获取模块,用于获取载客状态下的行驶轨迹数据并发送至所述轨迹数据预处理模块;
[0064]
所述轨迹数据预处理模块,用于对所述载客状态下的行驶轨迹数据进行预处理,获得网格映射的行驶轨迹数据并发送至所述模型构建模块;
[0065]
所述模型构建模块,用于根据所述网格映射的行驶轨迹数据构建asm-cf模型,并使用所述asm-cf模型进行轨迹检测;
[0066]
所述轨迹检测模块,用于计算所提取的轨迹对数据的异常轨迹得分,根据设置的阈值对轨迹的异常进行判断。
[0067]
一种电子设备,包括存储器和处理器,存储器存储计算机程序,其特征在于;所述处理器执行所述计算机程序时实现如权利要求1-8任一所述的移动轨迹大数据驱动的异常轨迹检测方法。
[0068]
本发明的有益效果是:
[0069]
第一,本发明构建了asm-cf模型,并使用asm-cf模型进行轨迹检测,判断轨迹是否存在绕行等异常行为,解决了无法准确识别绕行行为的异常轨迹检测问题,提升了大规模移动轨迹数据的处理效率,提高了异常轨迹检测的精确性。
[0070]
第二,本发明在hadoop分布式计算平台下,基于spark并行处理框架,对移动轨迹大数据进行了数据提取、数据过滤以及去重等预处理,确保了提取行驶轨迹数据的质量,并选择状态为111
…
10的轨迹数据而不是所有的行驶轨迹数据,主要根据载客状态下的行驶轨迹数据检测是否存在绕行异常行为,对轨迹数据进行映射,提高异常轨迹检测的准确性;
由于其去除了移动轨迹数据中不在载客状态下的行驶轨迹数据,从而能够减少计算量,加快计算效率。
[0071]
第三,在传统的异常轨迹检测中,主要将异常轨迹定义为一种在空间上偏离其他轨迹或发生某些偏离预期的行为,实际上基于司机恶意的绕行行为的异常轨迹并不仅仅指在空间上的异常,由此,将异常轨迹定义为在形状上不同且具有较长的实际行驶距离和持续时间的行驶轨迹,能够更为准确地说明出租车司机绕行行为的异常轨迹问题。
[0072]
第四,本发明通过设置模型阈值能够快速简单地得出符合条件的异常阈值,避免了不同轨迹对使用同一个阈值而造成的高误报率。
[0073]
综上所述,本发明在hadoop分布式计算平台下,利用spark中rdd弹性分布数据集对移动轨迹大数据进行数据预处理,得到载客状态下的车辆行驶轨迹,并提取所得到的载客状态下的车辆行驶轨迹进行相同起始点轨迹对,基于时间和空间特征构建成本因子,以及结合成本因子与基于形状的异常得分以构建本发明的异常得分模型—asm-cf模型,充分考虑行驶轨迹的空间位置差异性和乘客出行的成本差异性,能够较好地适用于司机存在侥幸心理绕行而引起的异常轨迹情况,可以有效提高异常轨迹检测的准确性和鲁棒性,解决了移动轨迹大数据处理效率低、异常轨迹检测效率低和无法准确识别绕路行为的异常轨迹的问题。
附图说明
[0074]
图1为本发明一种移动轨迹大数据驱动的异常轨迹检测方法及系统流程图;
[0075]
图2为本发明实施例提供的轨迹数据预处理流程图;
[0076]
图3为本发明实施例提供的轨迹数据地图匹配流程图;
[0077]
图4(a)-(e)为本发明实施例提供的轨迹对示例图;
[0078]
图5为本发明实施例提供的轨迹映射说明图;
[0079]
图6为本发明异常轨迹定义说明图;
[0080]
图7为本发明一种移动轨迹大数据驱动的异常轨迹检测系统框架图;
[0081]
图8为本发明实施例提供的一种移动轨迹大数据驱动的异常轨迹检测系统结构示意图。
具体实施方式
[0082]
为了使本领域的普通技术人员能更好地理解本发明的技术方案,下面结合附图和实施例对本发明的技术方案作进一步描述。
[0083]
参照附图1,一种移动轨迹大数据驱动的异常轨迹检测方法,包括以下步骤:
[0084]
s1:获取车辆的移动轨迹数据,对移动轨迹数据进行数据过滤、数据缺失和数据冗余等预处理操作;
[0085]
s2:提取载客状态下的车辆行驶轨迹数据集,并进行轨迹地图匹配、网格化、相同起始点轨迹对提取以及对所述轨迹对中的轨迹进行增强处理;
[0086]
s3:计算载客状态下的车辆行驶轨迹的实际行驶距离和持续时长特征;
[0087]
s4:重新定义出租车司机绕行的异常轨迹;
[0088]
s5:构建基于实际行驶距离和持续时长的成本因子,并通过成本因子构建asm-cf
模型;
[0089]
s6:使用所述asm-cf模型对真实的出租车移动轨迹大数据进行异常轨迹检测。
[0090]
在本实施例中,采用出租车gps轨迹大数据,对载客行驶轨迹数据进行提取,基于提取到的行驶轨迹的实际行驶距离和持续时间特征构建成本因子,通过成本因子与轨迹行驶的强相关性,构建基于成本因子异常得分模型(asm-cf),利用asm-cf模型检测异常轨迹得到异常得分,通过阈值输出轨迹的异常与正常。
[0091]
参考附图2,在hadoop分布式计算平台下,基于spark并行处理框架,s2的具体步骤包括:
[0092]
s201:由于本发明主要检测行驶轨迹中司机在载客行驶过程中是否发生了绕行行为的异常轨迹,由此,本发明提取的行驶轨迹数据应为载客状态下的车辆行驶轨迹数据集,即对预处理后的移动轨迹数据提取运营状态连续为111
…
10的轨迹数据,其中载客状态记为1,空车状态记为0;
[0093]
s202:对所述运营状态连续为111
…
10的轨迹数据进行数据剔除,仅保留每一条载客状态下的车辆行驶轨迹的经纬度和时间数据;
[0094]
s203:根据所述载客状态下的车辆行驶轨迹数据,对其进行地图匹配,得到其在实际道路网上的行驶轨迹,即匹配后的载客状态下的车辆行驶轨迹数据;
[0095]
s204:根据所述的匹配后的载客状态下的车辆行驶轨迹数据,对道路网络进行栅格化,得到网格序列轨迹,统计网格内起始点数,提取具有相同起始点的轨迹对;
[0096]
s205:根据提取的轨迹对,对轨迹对内的行驶轨迹进行增强处理,得到以连续网格序列为代表的映射轨迹。
[0097]
进一步地,步骤s201具体包括:
[0098]
s2011:读取hdfs文件中的移动轨迹数据,并转化为spark中的rdd弹性分布数据集;
[0099]
s2012:对所述rdd弹性分布数据集进行分片并过滤掉gps状态为0的数据,去掉无效数据,从而获得第一保留数据,第一保留数据包括车辆id、运营状态、时间和经纬度信息;
[0100]
s2013:将所述第一保留数据按照车辆id排序,查找车辆id相同的运营状态连续为111
…
10的轨迹数据;
[0101]
s2014:保留运营状态连续为111
…
10的轨迹数据。
[0102]
以上利用spark中rdd弹性分布数据集对移动轨迹大数据进行数据处理,提高了移动轨迹大数据的处理效率。
[0103]
进一步地,参考附图3,s203具体包括以下步骤:
[0104]
s2031:读取s202保留的载客状态下的轨迹数据,然后读取地图数据对地图进行栅格处理,将gps观测点匹配到最近的栅格,并以该gps观测点为圆心,以50米为半径的圆区域作为误差区域,对误差区域内的路段作投影以获取匹配候选路段和候选点;
[0105]
s2032:分析载客状态下的轨迹数据与路网数据(地图数据)的特征,计算观测概率和转移概率,构建隐马尔可夫模型;
[0106]
观测概率的计算公式为:
[0107][0108]
其中,p
t
为所述载客状态下的行驶轨迹中在t时刻的待匹配轨迹点,ri为轨迹点p
t
的第i个候选路段,x
t,i
为轨迹点p
t
在候选路段i上的候选点,circle为两点间的地球表面距离,σz为待匹配轨迹点的标准偏差,
[0109]
转移概率的计算公式为:
[0110][0111]
其中,d
t
=|||p
t-p
t+1
||
circle-||x
t,i-x
t+1,i
||
route
|,轨迹点p
t+1
与轨迹点p
t
为相邻轨迹点,x
t+1,i
为轨迹点p
t+1
在候选路段i上的候选点,route为两点间在路网上的距离;
[0112]
s2033:利用维特比算法得到最优的匹配路径,得到匹配后的每一条行驶轨迹的轨迹点的经纬度,其中,维特比算法中主要是利用观测概率和转移概率这两个概率模型计算得出概率最大的一条匹配轨迹。
[0113]
进一步地,s204的具体操作步骤包括:
[0114]
s2041:提取所述每一条载客状态下行驶轨迹的上车点与下车点的经纬度,即所述运营状态连续为111
…
10的轨迹数据的第一个运营状态为1和第一个运营状态为0的经纬度信息;
[0115]
s2042:将道路网络进行500
×
500m网格大小的划分,并将载客状态下的行驶轨迹的起始点映射到网格道路网络中,统计每一个网格的起始点的数量,得到具有相同起始点数量较多的轨迹对,所提取到的轨迹对,如附图4(a)-(e)所示。
[0116]
进一步地,参考附图5,s205的具体步骤包括:
[0117]
s2051:将地图划分为n
×
nm的网格,通过对不同网格尺寸的实验进行对比,最后获取得到最佳的网格尺寸为100
×
100m,将所述轨迹对映射到网格尺寸为100
×
100m的路网中,得到基于网格序列为集合的网格映射轨迹t=<g1,g2,l,gn>,gi为网格的编号,i∈1,2,
…
,n,n为所述运营状态连续为111
…
10的轨迹中的轨迹点的数量;
[0118]
s2052:对s2051所述的网格映射轨迹进行增强处理,即在将轨迹映射为网格时不仅记录轨迹点的网格,而且全部记录轨迹行驶过的网格,如图5所示,灰色网格为本发明对轨迹进行的增强处理,黑色网格和紫色网格为轨迹点实际经过的网格。本发明将轨迹所经过的网格全部记录下来以得到网格映射轨迹的增强轨迹t=<g1,g2,
…
,gm>,gi为网格的编号,i∈1,2,
…
,m,m为载客状态下的车辆行驶轨迹所经过网格的数量,且m≥n。
[0119]
进一步地,s3计算载客状态下的车辆行驶轨迹的实际行驶距离和持续时长特征的具体步骤包括:
[0120]
s301:根据所述载客状态下的行驶轨迹,根据半正矢公式计算行驶轨迹的实际行驶距离s
t
和行驶持续时间δt
t
以及经度δlon=lon
i+1-loni和纬度δlat=lat
i+1-lati,其中loni,lon
i+1
分别为当前轨迹点与下一个轨迹点的经度,lati,lat
i+1
分别为当前轨迹点与下一个轨迹点的纬度;ts和td分别为轨迹起始点的时间戳,r取值6371千米的地球半径;
[0121][0122]
δt
t
=t
d-ts[0123]
s302:剔除实际行驶距离和持续时间分别小于3千米和5分钟的行驶轨迹。
[0124]
参照附图6,s4对出租车司机绕行的异常轨迹进行新的定义,该定义为:异常轨迹为在形状上不同且具有较长距离和时长的行驶轨迹。
[0125]
给定一个轨迹对sdi=(t
i1
,t
i2
,l,t
in
),i为所提取的轨迹对的对数,n为每一个轨迹对的轨迹总数,在原有异常轨迹的定义中是将经常行驶的轨迹t1以外的轨迹t2、t3、t4、t5和t6均视为异常,因为极少数人行驶这几条路径。但是,在实际情况中,可以明显地得出t6是一条捷径,以及t2和t3相比于正常轨迹t1而言距离稍长,如果他们的时长比正常轨迹所花费的时长更少,这不应该被判定为绕行。由此,在本发明中,基于出租车司机的绕行行为,被异常轨迹定义为在形状上不同且具有较长距离和时长的行驶轨迹。
[0126]
进一步地,所述s5的具体操作步骤为:
[0127]
s501:获取所述连续的网格映射轨迹之间的轨迹距离:
[0128]
基于行驶轨迹是映射后的网格序列集合,可根据集合的差集和并集计算轨迹之间的距离,轨迹距离越大,表明两条轨迹的相似性越小;反之,轨迹距离越小,则表明两条轨迹的相似性越大,具体计算如式(1):
[0129][0130]
其中,|ti\tj|表示轨迹ti与轨迹tj的网格差集的长度,i,j∈1,2,
…
,n且i≠j,n为每一个轨迹对的轨迹总数,而|tj\ti|表示tj与ti的网格差集的长度,|ti∩tj|表示ti与tj的网格并集的长度,例如,ti=(g1,g2,g5,g7,g
11
,g
12
,g
15
,g
16
,g
19
),tj=(g1,g2,g3,g6,g8,g
11
,g
12
,g
15
,g
22
,g
20
,g
19
),|ti\tj|=3,|tj\ti|=5,|ti∩tj|=6,则
[0131]
s502:根据s3提取的实际行驶距离和持续时间,获得成本因子cf
t
,并将成本因子进行正则化;
[0132]
cf
t
=s
t
×
δt
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0133][0134]
公式(5)将成本因子cf
t
进行正则化得到一个[0,1]之间的值,将其称之为形状异常得分的相关系数,该系数越大,则乘客花费的成本越高;
[0135]
s503:通过差集和并集得到所述映射轨迹基于形状的轨迹得分ss(ti);
[0136][0137]
在每一个轨迹对中,轨迹对sdi=(t
i1
,t
i2
,l,t
in
)由多条轨迹组成,i为所提取的轨迹对的对数,n为每一个轨迹对的轨迹总数。由此,将多条轨迹的距离进行组合即可得到轨
迹与其他轨迹的距离,如公式(2):
[0138][0139]
该模型容易受到极值的影响,虽然两条轨迹的起始点相同,但是由于选取划分轨迹对时的网格尺寸与最后映射轨迹的网格尺寸不一样,两条轨迹没有交点的情况是可能发生的,此时公式(1)的分母为0。由此,如果直接将轨迹ti与tj的距离进行平均得到轨迹ti的得分是不恰当的,而是直接将差集之和与并集之和的比值作为ti与其他轨迹的距离,它是直接与轨迹位置相关,则将其定义为轨迹的形状得分,见公式(3)。
[0140]
s504:根据所述的正则化的成本因子和基于形状的轨迹得分ss(ti)构建asm-cf模型,基于asm-cf模型得到轨迹的异常得分s(ti);
[0141][0142]
s505:设置asm-cf模型的阈值:对轨迹的异常得分s(ti)进行降序排序之后,取得分的第k个异常得分分数为阈值,k为每一个轨迹对中异常的数量,例如,sdi中有20条为异常轨迹,则第20个轨迹的异常得分为阈值,该方法能够快速简单地得出符合条件的异常阈值,避免了不同轨迹对使用同一个阈值而造成的高误报率;
[0143]
s506:将s504得到轨迹的异常得分通过s505设置的阈值进行轨迹判断,如果异常得分大于阈值,表明轨迹是异常;反之,表明轨迹是正常。
[0144]
综上,结合附图7可知本发明的实施原理为:首先,数据预处理:经过数据过滤、数据缺失和数据冗余等预处理步骤后,基于运营状态提取得到载客状态下的行驶轨迹数据集;并通过基于隐马尔可夫模型的地图匹配算法将行驶轨迹匹配到实际路网中,降低gps采集轨迹点时产生的经纬度误差,根据对网格内的起始点数量的统计提取出具有相同起始点的轨迹对。其次,通过网格化轨迹和增强处理得到映射轨迹,降低由于行驶不同路径而轨迹点记录不同所产生高误报的概率。再次,基于距离和时间构建成本因子,通过成本因子提出asm-cf模型,以提高检测移动轨迹中由于司机故意绕行的异常轨迹行为。该模型主要是通过成本因子与轨迹形状得分相结合来进行异常轨迹的检测,并对检测到的异常轨迹进行绕行分析。最后,基于阈值判断轨迹的异常,输出轨迹的异常情况。
[0145]
本发明还公开了一种移动轨迹大数据驱动的异常轨迹检测系统,结合附图6可知,所述异常轨迹检测系统包括:轨迹数据获取模块、轨迹数据预处理模块、模型构建模块和轨迹检测模块;
[0146]
所述轨迹数据获取模块,用于获取和提取载客状态下的行驶轨迹数据并发送至所述轨迹数据预处理模块;
[0147]
所述轨迹数据预处理模块,用于对所述载客状态下的行驶轨迹数据进行预处理,获得网格映射的行驶轨迹数据并发送至所述模型构建模块;
[0148]
所述模型构建模块,用于根据所述网格映射的行驶轨迹数据构建基于成本因子异常得分模型的异常轨迹检测方法(asm-cf模型),以及使用所述asm-cf模型进行轨迹检测;
[0149]
所述轨迹检测模块,用于计算所提取的轨迹对数据的异常轨迹得分,根据设置的阈值对轨迹的异常进行判断。
[0150]
所述轨迹数据获取模块通过步骤s201得到运营状态连续为111
…
10的轨迹数据;
[0151]
所述轨迹数据预处理模块通过步骤s203获取与实际路网相匹配的行驶轨迹;通过步骤204获取具有相同起始点的轨迹对;通过步骤205获取以网格序列为集合的映射轨迹。
[0152]
所述模型构建模块通过公式(1)获取行驶轨迹之间的轨迹距离,通过公式(2)-(3)获取行驶轨迹基于空间位置的得分;通过公式(4)获取行驶轨迹的成本因子;获取公式(6)所示的基于成本因子异常得分模型;
[0153]
所述轨迹检测模块通过s505获取判断轨迹是否异常的阈值,通过s506的判断方式,判断行驶轨迹是异常或是正常。
[0154]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明思路和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都纳入要求保护的本发明范围。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1