基于大数据的工程管理文件分类识别方法及系统与流程
1.本技术涉及数据处理领域,具体涉及一种基于大数据的工程管理文件分类识别方法及系统。
背景技术:
2.随着计算机以及互联网的飞速发展,数字化文件已经逐渐替代传统纸质文档,成为各个生产领域主要的文件存储形式。在文件的管理方面,分类是最常见的文件管理方式。而文件的分类存在着多种分类方式,各个文件的类别可能会因为个人的分类偏好而改变,而不同的分类方式对于新文件汇入也会存在适应性的不同,这些文件分类问题普遍存在于文件的分类管理中并亟待解决。
3.工程管理文件作为建筑施工过程中最主要的文件,对其进行分类管理有助于提高存储以及调取效率,进而提升工程各项指标的评价效率。工程文件的主要特征即为文件的格式较为固定,其分类特征大多隐含在各级目录以及标题中,而现有技术对于工程文件的分类方式一般为将文本内容形式化地描述为多维空间中一点。进而基于现有的如支持向量机、k近邻分类器对多维空间内的文本数据点进行分类。但其假设标记的关键词是相互独立的,其不符合实际应用自然语言本身存在比如同义词、近义词和多义词等复杂的语义现象,所以其应用存在着分类缺陷。这就需要一种可利用工程文件本身分类特征所处文件位置结合关键词大数据实现工程管理文件的无监督分类。
技术实现要素:
4.本发明提供一种基于大数据的工程管理文件分类识别方法,解决分类效率低且繁琐复杂的问题,采用如下技术方案:
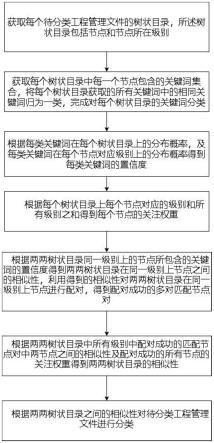
5.一种基于大数据的工程管理文件分类识别方法,包括:
6.获取每个待分类工程管理文件的树状目录,所述树状目录包括节点和节点所在级别;
7.获取每个树状目录中每一个节点包含的关键词集合,将每个树状目录获取的所有关键词中的相同关键词归为一类,完成对每个树状目录的关键词分类;
8.根据每类关键词在每个树状目录上的分布概率,及每类关键词在每个节点对应级别上的分布概率得到每类关键词的置信度;
9.根据每个树状目录上每个节点对应的级别和所有级别之和得到每个节点的关注权重;
10.根据两两树状目录同一级别上的节点所包含的关键词的置信度得到两两树状目录在同一级别上节点之间的相似性,利用得到的相似性对两两树状目录在同一级别上节点进行配对,得到配对成功的多对匹配节点对;
11.根据两两树状目录中所有级别中配对成功的匹配节点对中两节点之间的相似性及配对成功的所有节点的关注权重得到两两树状目录的相似性;
12.根据两两树状目录之间的相似性对待分类工程管理文件进行分类。
13.所述每类关键词的置信度的计算方法为:
[0014][0015]
式中,zk为第k类关键词的置信度,为第k类关键词在每个树状目录上出现的普遍性,为第k类关键词在每个节点对应级别上出现的普遍性。
[0016]
所述每类关键词在每个树状目录上出现的普遍性和每类关键词在每个节点对应级别上出现的普遍性的计算方法如下:
[0017][0018]
式中,i的范围为1到n,n为树状目录集中的树状目录个数,pk(i)为第k类关键词分布在第i个树状目录集上得概率;
[0019][0020]
式中,j的范围为0到m,m为树状目录集中,节点级别最大值,即最细分的节点所在级别,pk(j)为第k类关键词分布在第j个节点对应级别上的概率。
[0021]
所述每个节点的关注权重的计算方法为:
[0022][0023]
式中,为第i个树状目录si上第d个节点的关注权重,为si上第d个节点的级别,di为si上所有节点的个数,σ为所有节点的级别总和。
[0024]
所述节点之间的相似性的获取方法为:
[0025]
获取两两节点对应的关键词集合的交集与并集;
[0026]
将两两节点对应的关键词集合交集中每个关键词的置信度累加之和与两两节点对应的关键词集合并集中每个关键词的置信度累加之和的比值作为两两节点之间的相似性。
[0027]
所述多对匹配节点对的获取方法如下:
[0028]
获取每个树状目录中节点的集合;
[0029]
将两两树状目录中节点级别最小的根节点作为初始匹配节点;
[0030]
获取两个初始匹配节点各自的下一级节点集合,计算一个节点集合中每个节点与另一个节点集合中每个节点的相似性的最大相似性期望值,根据最大相似性期望值进行两两匹配;
[0031]
重复上述操作对两两树状目录中所有级别的节点进行匹配,得到多对匹配节点
对。
[0032]
所述两两树状目录的相似性的计算方法为:
[0033][0034]
式中,x
(α,β)
为树状目录s
α
和树状目录s
β
之间的相似性,r范围为1到r,r为x
(α,β)
为树状目录s
α
和树状目录s
β
之间已匹配节点对的数量,为树状目录s
α
、s
β
中第r对已匹配节点的两个节点关注权重的均值,ηr为第r对已匹配节点的两个节点之间的相似性。
[0035]
所述根据两两树状目录之间的相似性对待分类工程管理文件进行分类的方法为:
[0036]
根据两两树状目录之间的相似性构建相似矩阵;
[0037]
根据相似矩阵得到最大树,利用最大树聚类算法,将待分类工程管理文件分为不同的类别。
[0038]
本技术方案还提供一种基于大数据的工程管理文件分类识别系统,包括获取数据模块、计算模块、分类模块:
[0039]
所述获取数据模块:获取每个待分类工程管理文件的树状目录,包括节点和节点所在级别;获取每个节点对应的关键词集合,将相同关键词归为一类得到关键词种类个数;
[0040]
所述计算模块:
[0041]
根据每类关键词在每个树状目录上的分布概率和每类关键词在每个节点对应的级别上的分布概率得到每类关键词的置信度;
[0042]
根据每个树状目录上的节点数量和每个节点的目录级别得到每个节点的关注权重;
[0043]
对两两树状目录进行升序同级别目录匹配得到两两树状目录之间的已匹配节点集合;
[0044]
获取已匹配节点集合中两两两节点对应的关键词集合的交集与并集,根据交集和并集中每类关键词的置信度得到两两节点之间的相似性;
[0045]
根据已匹配节点集合中两两节点之间的相似性和每个节点的关注权重两两树状目录的相似性;
[0046]
所述分类模块:
[0047]
根据两两树状目录之间的相似性对待分类工程管理文件进行分类。
[0048]
本发明的有益效果是:获取待分类工程管理文件构成待分类文件集,根据每个文件的目录数据构建每个文件的树状目录,获取每个节点对应的关键词集合,根据每类关键词在每个树状目录上和每个节点对应的级别上的分布概率得到每类关键词的置信度;根据每个树状目录上的节点数量和每个节点的目录级别得到每个节点的关注权重;获取两两树状目录之间的已匹配节点集合并计算两两节点之间的相似性,根据相似性和每个节点的关注权重两两树状目录的相似性,构建相似矩阵,利用相似矩阵和最大树聚类算法对分类工程管理文件进行分类,方法智能、高效。
附图说明
[0049]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现
有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0050]
图1是本发明的一种基于大数据的工程管理文件分类识别方法的流程图;
[0051]
图2是本发明的一种基于大数据的工程管理文件分类识别方法中节点匹配示意图;
[0052]
图3是本发明的一种基于大数据的工程管理文件分类识别系统的结构框图。
具体实施方式
[0053]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0054]
本发明的一种基于大数据的工程管理文件分类识别方法的实施例,如图1所示:
[0055]
步骤一:获取每个待分类工程管理文件的树状目录,所述树状目录包括节点和节点所在级别;
[0056]
该步骤的目的是,构建每个待分类工程管理文件数据的树状目录。
[0057]
其中,构建待分类数据集中每个数据的树状目录,树状目录即以文件标题为根节点,根节点级别为0,一级标题为由根节点延伸的子节点,一级标题对应节点的级别为1,二级标题是由一级标题对应的树状图节点为父节点的子节点,二级标题对应节点的级别为2,以此类推,可构建每个工程管理文件的树状目录。则所构建的树状目录集与原始的待分类的工程管理文件数据集是一一对应的,即通过将原工程管理文件简化为树状目录使原始待分类数据集简化为树状目录集。
[0058]
步骤二:获取每个树状目录中每一个节点包含的关键词集合,将每个树状目录获取的所有关键词中的相同关键词归为一类,完成对每个树状目录的关键词分类;
[0059]
该步骤的目的是,工程管理文件的关键词大数据库识别各级目录中的关键词。获取每个待分类工程管理文件数据的各级目录对应的关键词集合。
[0060]
其中,关键词种类个数获取方法为:
[0061]
将树状目录集中的数据按照关键词大数据库中的数据进行对比识别。获取树状目录的各级目录对应的关键词集合。每个树状目录中的一个节点对应着一个关键词集合(种类集合)。即所述关键词种类个数即为整个树状目录集中所有出现过的关键词种类个数k。这个k可由所有树状目录的各级别目录对应的关键词集合进行合并后,其集合内元素个数就是k。
[0062]
步骤三:根据每类关键词在每个树状目录上的分布概率,及每类关键词在每个节点对应级别上的分布概率得到每类关键词的置信度;
[0063]
该步骤的目的是,根据不同种类关键词在树状目录中的分布情况计算各个种类关键词的置信度。
[0064]
其中,每类关键词的置信度的计算方法为:
[0065][0066]
式中,zk为第k类关键词的置信度,为第k类关键词在每个树状目录上出现的普遍性,为第k类关键词在每个节点对应的级别上出现的普遍性,zk为0-1之间的数,越趋近于1,越说明置信度越大。以此方式计算所有种类关键词的置信度,一共可获得k个置信度。即zk(k=1,2,
…
,k)。
[0067]
其中,每类关键词在每个树状目录上出现的普遍性和每类关键词在每个节点对应的级别上出现的普遍性的计算方法如下:
[0068][0069]
式中,i的范围为1到n,n为树状目录集中的树状目录个数,pk(i)为第k类关键词分布在第i个树状目录集上得概率;
[0070][0071]
式中,j的范围为0到m,m为树状目录集中,目录级别值最大的目录级别,即最细分的目录级别,pk(j)为第k类关键词分布在第j个目录级别的概率。为0-1之间的数,其越趋近于1越说明其分布越普遍,越不可信。
[0072]
需要说明的是,对于一个树状目录,其各个节点均对应一个关键词集合,每个节点按照距离根节点的路径距离(直接相连的两个节点即为距离1,节点与自己距离0。)分为0级节点(根节点,对应原工程管理文件的大标题),1级节点(与根节点直接相连的节点,对应工程管理文件的一级标题。)2级节点(与1级结点直接相连的非0级节点,对应工程管理文件的2级标题)。以此类推。且每个节点对应一个关键词集合。
[0073]
对于一个种类的关键词,其可能出现在不同树状目录上不同级别节点的关键词集合中。若这个关键词出现在所有的树状目录中,即在所有树状目录中均有分布,说明其可用来区分两个树状目录的可信性小,即置信度小。同样的,若一个关键词出现在所有树状目录的各级别节点关键词集合中,其也说明该关键词可用来区分两个树状目录各级别节点的可信性小,即置信度小。
[0074]
步骤四:根据每个树状目录上每个节点对应的级别和所有级别之和得到每个节点的关注权重;
[0075]
该步骤的目的是根据树状目录结构设定各级目录的关注权重。
[0076]
其中,每个节点的关注权重的计算方法为:
[0077]
[0078]
式中,为第i个树状目录si上第d个节点的关注权重,为si上第d个节点的级别,di为si上所有节点的个数,σ为所有节点的级别总和,则即对于一个si,其上所有节点的关注权重和为1,以此方式计算所有树状目录上各个节点的关注权重。
[0079]
步骤五:根据两两树状目录同一级别上的节点所包含的关键词的置信度得到两两树状目录在同一级别上节点之间的相似性,利用得到的相似性对两两树状目录在同一级别上节点进行配对,得到配对成功的多对匹配节点对;
[0080]
该步骤的目的是,根据每个待分类工程管理文件数据目录的级别对两个待分类工程管理文件数据进行升序同级目录匹配,得到匹配节点集合,并计算匹配节点之间的相似性。
[0081]
其中,多对匹配节点对的获取方法如下:
[0082]
对两两树状目录进行升序同级别目录匹配:
[0083]
(1)获取每个树状目录中节点的集合;
[0084]
(2)将两两树状目录中节点级别最小的根节点作为初始匹配节点;
[0085]
(3)获取两个初始匹配节点各自的下一级节点集合,计算一个节点集合中每个节点与另一个节点集合中每个节点的相似性的最大相似性期望值,根据最大相似性期望值进行两两匹配;
[0086]
(4)重复上述操作对两两树状目录中所有级别的节点进行匹配,得到多对匹配节点对。
[0087]
其中,节点之间的相似性的计算方法为:
[0088]
(1)获取匹配节点中两两节点对应的关键词集合的交集与并集;
[0089]
(2)将两两节点对应的关键词集合交集中每个关键词的置信度累加之和与两两节点对应的关键词集合并集中每个关键词的置信度累加之和的比值作为两两节点之间的相似性η。这个相似性是一个0-1之间的归一化数据,越趋近于1,越相似。
[0090]
在本实施例中,对于s
i1
、s
i2
来说即是将s
i1
的根节点(0级节点)与s
i2
的根节点进行配对。然后将s
i1
、s
i2
的一级节点各看成一个集合,配对过程就是在s
i1
的一级节点集合中寻找一个节点,与s
i2
的一级节点集合中的一个节点进行配对。配对完成后,已配对的一级节点对下属的二级节点再次进行上述配对。直到两个树状目录的节点配对完,未匹配节点保留。
[0091]
如图2所示,对于两个树状目录,左侧树状目录的根节点与右侧的根节点均仅有一个(所有树状目录均只有一个根节点)因此根节点的匹配直接为o-o匹配。当根节点匹配完成后。对两个根节点的下属一级节点进行匹配。即在集合{a,b}、集合{a,b,c}中寻找匹配结果,通过获取{a,b}和{a,b,c}中两两节点之间的最大相似性期望值,将{a,b}中每个节点与{a,b,c}中最大相似性期望值的节点进行配对。在进行匹配后,可获得匹配结果a-a、b-b。其中节点c未能匹配成对。将已经匹配好的一级节点的下属二级节点进行匹配,即将匹配结果a-a下属的二级节点集合{c,d}、{d}进行匹配;将匹配结果b-b下属的二级节点集合{e,f}、{e,f}进行匹配。获得二级节点匹配结果d-d、e-e、f-f。未匹配的一级节点c的下属二级节点集合{g,h}仍为未匹配,二级节点中本身未配对的节点为c。
[0092]
步骤六:根据两两树状目录中所有级别中配对成功的匹配节点对中两节点之间的相似性及配对成功的所有节点的关注权重得到两两树状目录的相似性;
[0093]
该步骤的目的是,计算两两树状目录的相似性。
[0094]
其中,两两树状目录的相似性的计算方法为:
[0095][0096]
式中,x
(α,β)
为树状目录s
α
和树状目录s
β
之间的相似性,r范围为1到r,r为x
(α,β)
为树状目录s
α
和树状目录s
β
之间已匹配节点对的数量,为树状目录s
α
、s
β
中第r对已匹配节点的两个节点关注权重的均值,ηr为第r对已匹配节点的两个节点之间的相似性,x
(α,β)
越趋近于1,说明树状目录s
α
、s
β
越相似。也即说明树状目录s
α
、s
β
对应的最原始数据集中的两个工程管理文件越相似。
[0097]
步骤七:根据两两树状目录之间的相似性对待分类工程管理文件进行分类。
[0098]
该步骤的目的是,根据两两树状目录之间的相似度构建相似矩阵并进行基于最大树的模糊聚类,实现工程管理文件数据集的无监督分类。
[0099]
其中,根据相似性对待分类工程管理文件进行分类的方法为:
[0100]
根据获取的两两树状目录的相似度构建相似矩阵。根据相似度矩阵为一个(n*n)的矩阵,其主对角线上的元素值均为1。获取相似矩阵的最大树,进行基于最大树的模糊聚类,取最大树模糊聚类参数λ=0.7(推荐值为0.7,此参数为0-1之间,越大分类越细,越小分类越粗糙。)获取c类树状目录结果。由于每个树状目录结果对应一个工程管理文件,因此工程管理文件的分类结果与其相同,至此,实现无监督分类。
[0101]
本技术方案的另一种实施例如图3所示:一种基于大数据的工程管理文件分类识别系统,包括获取数据模块s100、计算模块s101、分类模块s102:
[0102]
获取数据模块s100:获取每个待分类工程管理文件的树状目录,包括节点和节点所在级别;获取每个节点对应的关键词集合,将相同关键词归为一类得到关键词种类个数;
[0103]
计算模块s101:
[0104]
根据每类关键词在每个树状目录上的分布概率和每类关键词在每个节点对应的级别上的分布概率得到每类关键词的置信度;
[0105]
根据每个树状目录上的节点数量和每个节点的目录级别得到每个节点的关注权重;
[0106]
对两两树状目录进行升序同级别目录匹配得到两两树状目录之间的已匹配节点集合;
[0107]
获取已匹配节点集合中两两两节点对应的关键词集合的交集与并集,根据交集和并集中每类关键词的置信度得到两两节点之间的相似性;
[0108]
根据已匹配节点集合中两两节点之间的相似性和每个节点的关注权重两两树状目录的相似性;
[0109]
分类模块s102:
[0110]
根据两两树状目录之间的相似性对待分类工程管理文件进行分类。
[0111]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1