一种基于元强化学习算法的计算卸载方法
1.本发明涉及移动边缘计算技术领域,特别是一种基于元强化学习算法的计算卸载方法。
背景技术:
2.随着物联网设备,如智能手机、传感器和可穿戴设备等的快速增长和应用,大量的计算密集型任务需要从iot设备转移到云服务器上执行。然而,这些密集行任务的转移过程会涉及到大量的数据传输,这将导致物联网应用的高延迟。移动边缘计算(mec)的出现可以有效缓解这一挑战。移动边缘计算可以将复杂任务从物联网设备中的计算密集型任务迁移到边缘服务器中,从而为物联网设备提供计算服务。通过利用边缘服务器以及云服务器的计算和决策能力来减少计算延迟和能源,从而提升用户的体验质量。
3.但是,任务卸载的过程会受到不同因素的影响,如用户习惯、无线信道通信、连接质量、移动设备可用性和云服务器性能等等。因此,做出最优决策是边缘卸载的最关键问题。它需要决定任务是否应该被卸载到边缘服务器或云服务器。如果大量的任务被卸载到云服务器上,带宽将被占用,这将大大增加传输延迟。因此,需要有一个合理的卸载决策方案,使其能够合理地将每个任务分配给处理服务器。一方面,物联网环境中存在大量重复或类似的任务,往往需要从头开始重新训练,导致卸载决策效率低下;另一方面,一些物联网应用场景对任务决策有严格的时间限制,卷积神经网络(cnn)的学习速度慢,不适合满足mec系统中资源异质性和实时性的要求。
4.面对快速变化的物联网应用场景,不能在每次mec环境变化时通过重新计算来重新调整任务卸载决策和无线资源分配,否则会造成更高的服务延迟和成本。虽然,通过引入深度强化学习等智能算法,在mec的卸载决策方面取得了一些良好的效果,但仍然存在学习速度慢、模型环境变化时原始网络参数失效等挑战。在实际应用场景中,mec的环境往往随时随地受到很多因素的影响。传统的智能算法通常是基于神经网络的,当mec环境发生变化时,其原有参数将全部失效,需要大量的训练数据从头开始训练,这使得学习效率很低,重复训练会消耗资源,削弱mec系统的性能。同时,为了提高效率,还需要高配置的设备来适应高强度的训练。考虑到物联网的延迟和能源消耗,可以对具有一系列依赖性任务的工作流进行卸载决策。然而这个问题是np-hard的,传统的优化方法很难有效地取得结果。解决上述问题的一个有希望的方法是将深度学习技术,如深度强化学习(drl)引入边缘云协作的计算范式。由于传统的drl算法存在着学习速度较慢的缺点,导致训练好的模型不能很好的适应变化的环境,从而影响用户的体验质量。
技术实现要素:
5.本发明的目的是针对现有技术的不足而设计的一种基于元强化学习算法的计算卸载方法,采用在物联网设备、边缘服务器和云服务器协作式应用场景下建立任务卸载决策和资源分配模型的方法,获取当前卸载系统的状态,通过元学习获取学习模型,然后通过
模型训练获取任务卸载决策,该方法综合考虑物联网设备中任务流情况以及各个设备的状态能够优化卸载决策,使用元强化学习的算法,大大降低了物联网设备计算任务的时延和功耗,方法简便,效率高,有效解决了边缘卸载系统中的任务卸载决策和资源分配,以及传统的深度强化学习算法对新任务采样效率低的问题,进一步降低物联网设备处理计算任务的时延和能耗,从而能够提升用户的体验质量。
6.本发明的目的是这样实现的:一种基于元强化学习算法的计算卸载方法,其特点是采用构建任务卸载决策和资源分配模型的方法,获取当前卸载系统的状态,将其通过元学习获取学习模型,然后通过模型训练获取任务卸载决策,计算卸载具体包括以下四个步骤:
7.s1、在物联网设备、边缘服务器和云服务器协作式应用场景下建立任务卸载决策和资源分配模型,该模型包括:移动边缘计算卸载环境模型、计算任务模型、计算任务决策模型、计算任务时延模型、计算任务能耗模型和具有马尔可夫决策过程的计算任务卸载模型。
8.s2、获取当前卸载系统的状态,具体包括以下步骤:
9.s201:获取当前卸载系统中物联网设备、边缘服务器和云服务器的状态,包括物联网设备的任务状况,以及各设备的计算能力和各个设备之间的传输带宽。
10.s3:获取学习模型,具体包括以下步骤:
11.s301:获取物联网设备任务状态;
12.s302:采样k个学习任务,初始化元策略参数φ0;
13.s303:采样获得状态和行为的集合,并采取相应的动作,评估获得的奖励;
14.s304:判断奖励是否收敛或者是否达到迭代次数上限。当奖励收敛或已达到迭代次数上限时,即可获取参数,否则继续执行训练;
15.s305:更新元策略参数;
16.s306:判断是否收敛或者是否达到迭代次数上限。当奖励收敛或已达到迭代次数上限时,即可获取学习模型,否则继续执行训练。
17.s4、获取卸载决策,具体包括以下步骤:
18.s401:采样获得状态和行为的集合,并采取相应的动作,评估获得的奖励;
19.s402:判断奖励是否收敛或者是否达到迭代次数上限。当奖励收敛或已达到迭代次数上限时,即可获取卸载决策,否则继续执行训练。
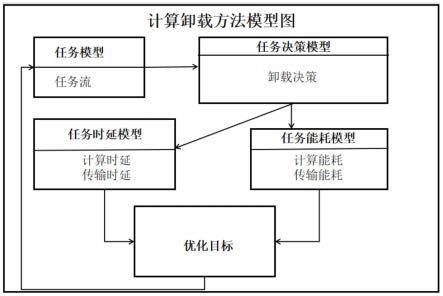
20.所述步骤s1中计算卸载环境模型的建立方法为:在物联网设备、边缘服务器和云服务器协作式应用场景下,该场景包括一个云服务器,多个边缘服务器和多个物联网设备,边缘服务器用m={1,2,...,m}来表示。并且由物联网设备、边缘服务器建立任务计算协作集群,由物联网设备和云服务器建立任务决策集群。
21.所述步骤s1中的计算任务模型的建立方法为:将每个物联网设备中的计算程序分为连续的工作流,假设第x个工作流的定义如下述(a)式:
22.t
x
={v1,e
1,2
,v2,
…
,vi,e
i,j
,vj,
…
,e
n-1,n
,vn}
ꢀꢀꢀ
(a);
23.其中,t
x
表示物联网设备中第x个工作程序,vi表示工作程序中第i个工作流;e
i,j
表示工作流vi和工作流vj之间需要传输的数据量。
24.所述步骤s1中的计算任务决策模型建立方法为:为工作程序中每个工作流分别制
定不同的卸载策略,并且用矩阵变量来表示不同的的卸载决策。如工作流vi的卸载决策可由下述(b)式表示为:
25.d
x,i
∈(d0,d1,d2,...,dm)
ꢀꢀꢀ
(b);
26.其中,d
x,i
表示物联网设备中第x个工作程序中第i个工作流的卸载决策,更具体地,d0=[1,0,...,0]
t
,d1=[0,1,...,0]
t
,d0=[0,1,...,1]
t
。d0表示第i个工作流在本地运行,dk(k∈[1,m])表示第i个工作流卸载到边缘服务器k上执行。
[0027]
所述步骤s1的计算任务时延模型建立方法为:当工作程序中第i个工作流在物联网设备本地运行或者卸载到边缘服务器上执行时,首先需要经过一段时间的计算时延,然后不同工作流传输数据需要经过一段时间的传输时延。因此,任务vi的计算延迟由以下述(c)式计算:
[0028][0029]
其中,f0和fk(k∈[1,m])分别表示物联网设备和服务器k的计算能力。
[0030]
任务vi和vi之间的传输延迟则由下述(d)式表示为:
[0031][0032]
其中,w
k1,k2
表示不同设备之间的传输带宽。
[0033]
因此,总的传输时延则由下述(e)式表示为:
[0034][0035]
所述步骤s1的计算任务能耗模型建立方法为:当工作程序中第i个工作流在物联网设备本地运行或者卸载到边缘服务器上执行时,首先在物联网设备和边缘服务器上进行计算需要消耗一定的能量,然后不同工作流传输数据需要消耗一定的能量。因此,任务vi的计算能量消耗由下述(f)式计算:
[0036][0037]
其中,δ0和δ1分别表示物联网设备和服务器为处理数据每个cpu计算周期需要消耗的能量。因此,任务vi和vj之间传输数据所消耗的能量由下述(g)式计算:
[0038][0039]
其中,en单位时间传输数据所消耗的能量。因此,总的能量消耗则由下述(h)式计算:
[0040][0041]
本发明总的优化目标为最小化时延和能量消耗,可以将优化目标由下述(k)表示为:
[0042][0043]
其中,w1和w2分别是关于时延和能量的目标系数。
[0044]
所述步骤s1中具有马尔可夫决策过程的计算任务卸载模型建立方法由下述(j)式表示为:
[0045]
tn=(s,a,r,π)
ꢀꢀꢀ
(j);
[0046]
式中,元素从左到右依次表示问题的状态空间、动作空间状态转移矩阵、奖励函数和策略;为了求解上述马尔可夫决策过程,本发明通过使用神经网络来拟合策略函数和价值函数。首先对策略网络输入当前马尔可夫决策过程的状态si,并逐步输出策略函数与价值函数的拟合结果,以确定下一步动作ai,直到获得最后一个动作为止。本发明的任务协作卸载算法的训练过程包括深度强化学习和元学习两部分,其中深度强化学习部分基于ppo算法对网络进行训练;元学习部分采用maml(model-agnostic meta-learning)算法进行训练。
[0047]
本发明与现有技术相比具有以下显著的技术进步和有益效果:
[0048]
1)本发明能够根据卸载系统的状态分别制定不同的决策策略,取得更有效的优化效果。
[0049]
2)采用元强化学习算法能够有效解决计算卸载与资源分配问题,并且还能解决传统深度强化学习算法对新任务的采样效率低的问题,从而实现在动态环境中的快速计算卸载决策。
[0050]
3)有效解决了传统的深度强化学习算法对新任务采样效率低的问题,大大降低了物联网设备计算任务的时延和功耗,从而提升用户体验质量。
附图说明
[0051]
图1为本发明的模型图;
[0052]
图2为本发明流程图。
具体实施方式
[0053]
为了更好地理解本技术方案,下面结合附图对本发明作进一步详细描述。
[0054]
实施例1
[0055]
参阅图1,本发明在物联网设备、边缘服务器和云服务器协作式应用场景下建立任务卸载决策和资源分配模型,模型构建的具体步骤如下:
[0056]
1)计算环境:根据云服务器、边缘服务器和物联网设备的地理位置将边缘服务器和云服务器分组为不同的协作集群共同完成物联网设备中任务的。
[0057]
假设该集群中有一个云服务器、多个边缘服务器以及多个物联网设备。边缘服务器用m={1,2,...,m}来表示。
[0058]
2)计算任务:假设物联网设备上会产生不同的计算密集型任务,每个计算任务可以分成不同的工作流,每个计算密集型任务可以由下述(a)式表示为:
[0059]
t
x
={v1,e
1,2
,v2,
…
,vi,e
i,j
,vj,
…
,e
k-1,k
,vk}
ꢀꢀꢀ
(a)。
[0060]
其中,t
x
表示物联网设备中第x个工作程序;vi表示工作程序中第i个工作流;e
i,j
表
示工作流vi和工作流vj之间需要传输的数据量。
[0061]
3)计算任务执行方式:采用任务本地执行和卸载到边缘服务器上执行的两种执行方式计算密集型任务中不同的工作流,本发明将工作流vi的卸载决策由下述(b)式表示为:
[0062]dx,i
∈(d0,d1,d2,...,dm)
ꢀꢀꢀ
(b)。
[0063]
其中,d
x,i
表示物联网设备中第x个工作程序中第i个工作流的卸载决策,更具体地,d0=[1,0,...,0]
t
,d1=[0,1,...,0]
t
,d0=[0,1,...,0]
t
。d0表示第i个工作流在本地运行,dk(k∈[1,m])表示第i个工作流卸载到边缘服务器k上执行。
[0064]
4)时延模型:本发明在计算密集型任务中不同的工作流会有不同的执行方式,当工作程序中第i个工作流在物联网设备本地运行或者卸载到边缘服务器上执行时,首先要经过一段时间的计算时延,然后不同工作流传输数据需要经过一段时间的传输时延。因此,任务υi的计算延迟由下述(c)式计算:
[0065][0066]
其中,f0和fk(k∈[1,m])分别表示物联网设备和服务器k的计算能力。
[0067]
任务υi和vj之间的传输延迟由下述(d)式计算:
[0068][0069]
其中,w
k1,k2
表示不同设备之间的传输带宽。因此,总的传输时延由下述(e)式计算:
[0070][0071]
5)本发明计算密集型任务中不同的工作流会有不同的执行方式,当工作程序中第i个工作流在物联网设备本地运行或者卸载到边缘服务器上执行时,首先在物联网设备和边缘服务器上进行计算需要消耗一定的能量,然后不同工作流传输数据需要消耗一定的能量。因此,任务vi的计算能量消耗通过下述(f)式计算:
[0072][0073]
其中,δ0和δ1分别表示物联网设备和服务器为处理数据每个cpu计算周期需要消耗的能量。因此,任务υi和υj之间传输数据所消耗的能量由下述(g)式计算:
[0074][0075]
其中,en单位时间传输数据所消耗的能量。因此,总的能量消耗为下述(h)式计算:
[0076][0077]
本发明总的优化目标为最小化时延和能量消耗,可以将优化目标表示为下述(k)式:
[0078][0079]
其中,w1和w2分别是关于时延和能量的目标系数。
[0080]
6)具有马尔可夫决策过程卸载模型:根据整个边缘卸载系统中的任务卸载协作集群的任务情况和各个设备的资源状况,将整个边缘卸载系统的卸载决策和卸载过程建模为具有马尔可夫决策过程卸载模型,并将该过程参数化为下述(j)式:
[0081]
tn=(s,a,r,π)
ꢀꢀꢀ
(j);
[0082]
式中,元素从左到右依次表示问题的状态空间、动作空间状态转移矩阵、奖励函数和策略。
[0083]
所述状态空间由下述(m)式定义示为:
[0084]st
={t
x
,f0,f1,f2,...,fm,w
k1,k2
}
ꢀꢀꢀ
(m);
[0085]
其中,t
x
={υ1,e
1,2
,υ2,
…
,υi,e
i,j
,υj,
…
,e
n-1,n
,υn}表示物联网设备中工作程序不同的工作流;f0,f1,f2,...,fm分别表示物理网设备和边缘服务器的计算能力;w
k1,k2
表示不同设备之间的带宽,例如w
0,1
表示物联网设备和边缘服务器1之间的带宽。
[0086]
所述动作空间由下述(n)式定义为:
[0087]at
={d
x,0
,d
x,1
,...,d
x,n
}
ꢀꢀꢀ
(n)。
[0088]
其中,d
x,i
(i∈[1,n])表示不同工作流的卸载决策,更具体地,每个工作流的卸载决策又可以由下述(p)式定义为:
[0089]dx,i
∈(d0,d1,d2,...,dm)
ꢀꢀꢀ
(p)。
[0090]
其中,d0=[1,0,...,0]
t
,d1=[0,1,...,0]
t
,d0=[0,1,...,0]
t
;d0表示第i个工作流在本地运行;dk(k∈[1,m])表示第i个工作流卸载到边缘服务器k上执行。
[0091]
所述奖励,由于系统目标是最小化边缘卸载系统的任务处理延迟和能量消耗,所以本发明将马尔可夫决策过程的奖励分为两部分,第一部分与处理任务的时间延迟相关,第二部分与为了完成任务所消耗的能量有关。
[0092]
与处理任务的时间延迟相关的奖励由下述(q)式定义为:
[0093][0094]
其中,l
local
表示工作程序完全在本地执行所花费的时间;l
x
表示工作程序通过边缘卸载系统进行计算所消耗的时间。
[0095]
与完成任务所消耗的能量部分的奖励由下述(r)式定义为:
[0096][0097]
其中,e
local
表示工作程序完全在本地执行所消耗的能量;e
x
表示工作程序通过边缘卸载系统进行计算所消耗的能量。
[0098]
因此,可以将奖励定义为下述(s)式:
[0099][0100]
其中,w
l
和we分别是关于时延和能量的奖励系数。
[0101]
所述策略为当任务t
x
到达时整个系统的策略为π(ai|si),从初始状态s0开始,根据
策略π(ai|si),每执行一个动作,系统即进入一个新的状态并得到一个奖励,直到物联网设备中最后一个任务决策完成。
[0102]
为了求解上述马尔可夫决策过程,本发明通过使用神经网络来拟合策略函数和价值函数,首先对策略网络输入当前马尔可夫决策过程的状态si,并逐步输出策略函数与价值函数的拟合结果,以确定下一步动作ai,直到获得最后一个动作为止。
[0103]
本发明的任务协作卸载算法的训练过程包括深度强化学习和元学习两部分,下面会分别对这两部分进行详细阐述。
[0104]
1)算法训练的深度强化学习部分
[0105]
本发明基于ppo(proximal policy optimization)算法对上述网络进行训练,ppo算法是目前openai基线集强化学习基准算法的默认算法,它通过简单的clip机制选择目标函数的保守下限,不需要计算trpo算法约束,从而提高算法的数据采样效率,以及算法的鲁棒性,降低超参数选择的复杂性。ppo算法的具体过程是为待优化的策略维护两个策略网络。第一个策略网络是优化的策略网络,第二个策略网络是以前用来收集样本的策略网络,现在还没有被更新。然后根据收集的样本,计算出优势估计值最后,通过最大化的目标函数来更新网络参数,从而优化策略πθ。
[0106]
所述ppo算法的目标函数如下述(t)式定义为:
[0107][0108]
其中,clip函数用来限制的πθ的范围;r
t
(θ)为采样策略与目标策略的比值,且由下述(u)式定义为:
[0109][0110]
其中,πθ
old
(a
t
|s
t
)固定用来采样数据;πθ(a
t
|s
t
)不断更新用来训练网络;为下述(v)式定义的优势估计值:
[0111][0112]
综上所述,策略网络参数优化的更新规则为下述(w)式定义为:
[0113][0114]
其中,α为inner loop训练的学习率。在经过一定数量的样本学习之后,目标策略网络会将该网络的参数赋给采样策略网络,即θ
old
←
θ。
[0115]
2)算法训练的元学习部分
[0116]
本发明基于maml(model-agnostic meta-learning)算法按下述步骤进行训练:
[0117]
a、首先准备多个个训练任务(train task),再准备几个测试任务(test task),测试任务用于评估meta learning学习到的参数的效果,训练任务和测试任务均从采样中产生。
[0118]
b、初始化一个meta网络的参数为φ0,meta网络是最终要用来应用到新的测试任务中的网络,该网络中存储了“先验知识”。
[0119]
c、开始执行迭代预训练并得到meta网络的参数。
[0120]
d、使用测试任务对meta learning的效果进行评估。
[0121]
参阅图2,本发明提出了基于元强化学习算法的计算卸载方法,该方法主要分为三个主要阶段:(1)获取当前卸载系统的状态、(2)获得学习模型、(3)获取卸载决策。
[0122]
(1)获取当前卸载系统的状态
[0123]
获取当前卸载系统中物联网设备、边缘服务器和云服务器的状态,包括物联网设备的任务状况,以及各设备的计算能力和各个设备之间的传输带宽。
[0124]
(2)获取学习模型
[0125]
步骤一:获取物联网设备任务状态;
[0126]
步骤二:采样k个学习任务,初始化元策略参数φ0;
[0127]
步骤三:采样获得状态和行为的集合,并采取相应的动作,评估获得的奖励;
[0128]
步骤四:判断奖励是否收敛或者是否达到迭代次数上限,当奖励收敛或已达到迭代次数上限时,即可获取参数,否则继续执行训练;
[0129]
步骤五:更新元策略参数;
[0130]
步骤六:判断是否收敛或者是否达到迭代次数上限,当奖励收敛或已达到迭代次数上限时,即可获取学习模型,否则继续执行训练。
[0131]
(3)获取卸载决策
[0132]
步骤一:采样获得状态和行为的集合,并采取相应的动作,评估获得的奖励;
[0133]
步骤二:判断奖励是否收敛或者是否达到迭代次数上限,当奖励收敛或已达到迭代次数上限时,即可获取卸载决策,否则继续执行训练。
[0134]
综上,本发明中的计算卸载方法旨在解决边缘卸载系统中的任务卸载决策和资源分配问题,进一步降低物联网设备处理计算任务的时延和能耗。该计算卸载方法首先在物联网设备、边缘服务器和云服务器协作式应用场景下建立任务卸载决策和资源分配模型,接着获取当前卸载系统的状态,然后通过元学习获取学习模型,最后通过训练获取任务卸载决策。本发明综合考虑物联网设备中任务流情况以及各个设备的状态能够优化卸载决策,最后基于元强化学习的算法能够解决传统的深度强化学习算法对新任务采样效率低的问题。
[0135]
以上只是本发明的较佳实现而已,并非对本发明做任何形式上的限制,故凡未脱离本发明技术方案的内容,依据本发明的技术实质对以上实现方法所做的任何的简单修改、等同变化与修饰,凡为本发明等效实施,均应包含于本专利的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1