一种跨项目软件缺陷预测数据选择方法
1.本发明涉及软件缺陷预测技术领域,更具体的说是涉及一种跨项目软件缺陷预测数据选择方法。
背景技术:
2.软件缺陷预测技术是目前提高软件测试效率的重要手段之一。其主要流程如下。首先通过分析软件的历史数据库,并从中选择程序模块,对其进行标记,之后构建缺陷预测数据,随后根据软件代码在编写过程中固有的特征以及代码的复杂程度,为程序设计出特征空间,特征空间的特征要求与软件缺陷紧密相关,并测量已提取的程序模块的特征值,在得到测量的结果后,这些程序模块便可作为训练数据,基于机器学习的方法,得到训练模型。同样将需要预测的程序模块进行按设计的特征进行测量,得到测试集,最后用机器学习得到的训练模型进行缺陷预测,其预测的输出可以是模块内是否含有缺陷、缺陷的数量以及缺陷的密度等。但在现实软件开发的情况下,需要进行缺陷预测的项目(目标项目)很可能并没有历史数据库,或者说仅有少量历史数据而不足以进行模型训练,这时可以借助其他具有充足历史数据的项目(源项目)数据,此方法称为跨项目软件缺陷预测。
3.针对跨项目软件缺陷数据匮乏的问题,采用其他软件缺陷数据进行数据补充,然而不同项目之间因其使用场景、软件开发人员的开发模式、设计方案、编程的方法等并不相同,所以这就导致两个不同项目数据会不可避免地存在差异性,这也是最终的预测效果并不好的原因。为了能够让预测效果更理想,采用其他软件缺陷数据进行数据补充时,其选择条件为选取与目标软件信息量更加相似的其他软件的缺陷数据。基于这一目的,计算项目间软件缺陷样本数据之间的相似性是十分重要的。
4.目前比较常见的方法是基于实例的样本相似性选择方法,例如bruak过滤法和peter过滤法,其主要目的是通过欧氏距离度量个体样本与目标样本之间的相似度,从而筛选出适合目标项目的源项目数据进行数据补充,之后再进行模型训练。但是这会存在一个问题,在多个源项目同时存在时,如何挑选源项目,也就是说需要先从项目的层面上解决问题,而不是直接选择样本数据,即使选择样本数据也需要尽可能寻找与目标项目分布相似的源项目数据。
5.因此,如何度量多源跨项目软件缺陷数据的相似性,为跨项目软件缺陷预测提供数据支持是本领域技术人员亟需解决的问题。
技术实现要素:
6.有鉴于此,本发明提供了一种跨项目软件缺陷预测数据选择方法,首先度量源项目数据与目标项目数据的概率分布,通过计算源项目数据和目标项目数据之间的wasserstein距离,从项目的角度选取与目标项目数据更为相似的源项目数据,然后同时结合机器学习方法,提出对相似性度量验证,验证本发明提出方法的有效性,从而为从事软件缺陷预测相关工作人员提供项目数据选择依据,并证明其可靠性。
7.为了实现上述目的,本发明采用如下技术方案:
8.一种跨项目软件缺陷预测数据选择方法,包括以下步骤:
9.步骤1:对多个干源项目数据和目标项目数据进行数据预处理;
10.步骤2:计算预处理后的每个源项目数据和目标项目数据之间的wasserstein距离;
11.步骤3:根据wasserstein距离判断每个源项目数据与目标项目数据的相似性,选定源项目数据。
12.优选的,所述数据预处理包括剔除冗余样本、剔除含缺失值的样本和数据标准化;采用主成分分析方法,把原始样本数据线性映射到低维空间中,使得投影后的数据在新的低维空间中具有各特征线性无关的特性,通过投影后,高维的数据可以映射为低维的数据,从而实现数据的简约,即降维;利用z-score方法对源项目数据和目标项目数据进行标准化。
13.优选的,计算wasserstein距离的具体过程为:
14.步骤21:源项目数据为xs,目标项目数据为x
t
,源项目数据中样本数量为ns,目标项目数据中样本个数为n
t
,则源项目数据与目标项目数据的概率分布公式为:
[0015][0016]
其中p(x
s,i
)和p(x
t,i
)分别是源项目数据xs和目标项目数据x
t
中第的i个样本的概率分布;源项目数据和目标项目数据均为均匀分布,即p(x
s,i
)=1/ns,p(x
t,i
)=1/n
t
;
[0017]
步骤22:最优运输就是将源项目数据xs移动到目标项目数据x
t
的最小工作量,也即找到从p(xs)到p(x
t
)的最优运输方案;
[0018]
计算p(xs)和p(x
t
)两个分布之间的概率耦合矩阵,
[0019][0020]
其中,p为两个分布之间的概率耦合矩阵;其中,p为两个分布之间的概率耦合矩阵;而p是所有运输方案的集合;r表示特征空间;
[0021]
步骤23:根据概率耦合矩阵计算wasserstin距离,公式为:
[0022][0023]
其中《
·
,
·
》f代表矩阵内积,c为代价矩阵;
[0024][0025]
c(i,j)代表样本x
s,i
与样本x
t,j
的平方欧式距离。
[0026]
优选的,所述步骤3中按照所述wasserstein距离从小到大进行排序,选定所述wasserstein距离最小的源项目数据作为跨项目软件缺陷数据。
[0027]
优选的,所述步骤3中根据所述wasserstein距离为所有所述源项目数据分配权重,所述wasserstein距离越小权重越大,根据所述权重对所有所述源项目数据进行加权,获得选定源项目数据。
[0028]
优选的,所述步骤3的具体实现过程为:
[0029]
步骤31:根据wasserstein距离d计算e值;
[0030][0031]
其中是第i个源项目数据与目标项目数据的欧式距离的平方,ω是用来控制wasseerstein距离范围的参数;
[0032]
步骤32:根据e值计算出k个源项目数据的权重;
[0033][0034]
其中αi是第i个源项目数据的权重,用权重控制不同源域的重要性;
[0035]
步骤33:将所有源项目数据的数据合并在一起,即将加权后的k个源项目数据以及其标签连接起来,形成训练集为:
[0036]
x=[α1x
s,1
,...,αkx
s,k
],y=[y
s,1
,...,y
s,k
]
ꢀꢀ
(6)
[0037]
其中x
s,i
是第i个源项目数据的样本数据;y
s,i
是第i个源项目数据的标签;[x,y]则是训练集,作为软件缺陷预测过程训练软件缺陷预测模型的训练集。
[0038]
优选的,步骤4:对选定源项目数据进行验证,证明相似性判断准确性。
[0039]
优选的,步骤4的具体实现过程为:
[0040]
步骤41:将每个源项目数据分别作为一组训练集;
[0041]
步骤42:分别利用每组所述训练集进行模型训练,构建缺陷预测模型;
[0042]
步骤43:将目标项目数据分别输入到每组源项目数据对应的所述缺陷预测模型中,获得缺陷结果;
[0043]
步骤44:根据每组缺陷结果计算每个缺陷预测模型的性能评价指标;
[0044]
步骤45:分别对比每组源项目数据与目标项目数据之间的wasseerstein距离,以及性能评价指标,获得相似性适合度。根据相似性适合度证明选定的源项目数据与目标项目数据是最合适的。
[0045]
优选的,采用logistic回归对所述训练集进行模型训练,构建缺陷预测模型。
[0046]
优选的,步骤45中对所述源项目数据进行两两对比,采用一般规律进行对比,如果距离小且性能评价指标高则符合一般规律,否则不符合,根据符合一般规律的次数和总对比次数计算相似性适合度。
[0047]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种跨项目软件缺陷预测数据选择方法及验证方法,针对跨项目软件缺陷预测,从多个源项目中选择合适的进行后续的模型训练,利用相似性度量方法从多个源项目中确定合适的源项目数据,为软件缺陷预测提供数据支撑,提高软件预测的准确性。
附图说明
[0048]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0049]
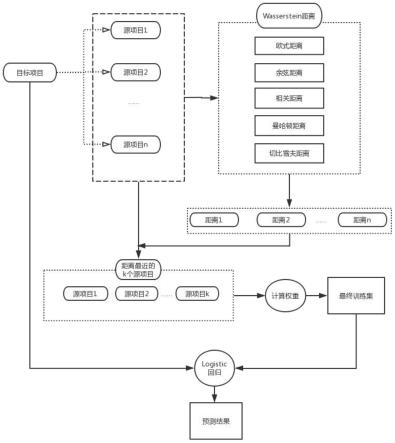
图1附图为本发明提供的基于wasserstein距离的多源项目预测选择流程图;
[0050]
图2附图为本发明提供的验证流程图;
[0051]
图3附图为本发明提供的验证方案流程图。
具体实施方式
[0052]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0053]
本发明实施例公开了一种跨项目软件缺陷预测数据选择方法,流程如图1所示。
[0054]
s1:对源项目数据和目标项目数据进行数据预处理;包括:
[0055]
(1)剔除冗余样本
[0056]
在软件模块度量时,若考虑了大量与代码或开发过程相关的度量元,会使得一些数据集产生维度爆炸问题,因此,需要使用有效方法来重点识别出数据集中的冗余特征和无关特征;通过采用主成分分析方法,把原始样本数据线性映射到低维空间中,使得投影后的数据在新的低维空间中具有各特征线性无关的特性,通过投影后,高维的数据可以映射为低维的数据,从而实现数据的简约,即降维;
[0057]
(2)剔除含缺失值的样本
[0058]
一些样本数据存在缺失值,采用删除缺失值样本的方法确保数据的完整性;对于数据噪声问题,采用聚类分析的方法,将超出距离范围的样本剔除,确保分类器的预测准确度;
[0059]
(3)数据标准化
[0060]
考虑到不同度量元的量级可能有很大差异这一问题,利用z-score方法对源数据和目标数据进行标准化,即使得每个特征的均值为0,方差为1;z-score方法的公式如下:
[0061][0062]
其中,x为原始数据的均值,σ为原始数据的标准差;
[0063]
s2:计算两个项目数据之间的wasserstein距离,存在多个源项目数据时,计算每个源项目数据与目标项目数据的wasserstein距离;
[0064]
s21:针对两个项目数据之间的wasserstein,首先给定源项目数据为xs,给定目标项目数据为x
t
,源项目数据中样本数量为ns,目标项目数据中样本个数为n
t
,于是,给出源项目数据与目标项目数据的概率分布公式:
[0065][0066]
其中p(x
s,i
)和p(x
s,i
)分别是源项目数据xs和目标项目数据x
t
中的i个样本的概率分布;源项目数据和目标项目数据均为均匀分布,即p(x
s,i
)=1/ns,p(x
t,i
)=1/n
t
;
[0067]
s22:最优运输就是将源项目数据xs移动到目标项目数据x
t
的最小工作量,也即找到从p(xs)到p(x
t
)的最优运输方案;
[0068]
定义p为为两个分布之间的概率耦合矩阵。
[0069][0070]
其中而p是所有运输方案的集合;r表示特征空间;
[0071]
s23:根据概率耦合矩阵和计算wasserstin距离,公式为:
[0072][0073]
其中《
·
,
·
》f代表矩阵内积,c为代价矩阵;
[0074][0075]
c(i,j)代表样本x
s,i
与样本x
t,j
的平方欧式距离;
[0076]
s3:根据wasserstein距离判断每个源项目数据与目标项目数据的相似性,选定源项目数据;wasserstein距离表述源项目数据与目标项目数据之间的相似性,根据wasserstein距离选定源项目数据作为跨项目软件缺陷预测数据包括两种方法,第一种按照wasserstein距离从小到大进行排序,选定wasserstein距离最小的源项目数据作为跨项目软件缺陷数据;第二种根据wasserstein距离为所有源项目数据分配权重,wasserstein距离越小权重越大,根据权重对所有源项目数据进行加权,获得选定源项目数据;
[0077]
其中第二种的具体实现过程为:
[0078]
s31:根据wasserstein距离d计算e值;
[0079][0080]
其中是第i个源项目数据与目标项目数据的欧式距离的平方,ω是用来控制wasseerstein距离范围的参数;
[0081]
s32:根据e值计算出k个源项目数据的权重;
[0082][0083]
其中αi是第i个源项目数据的权重,用权重控制不同源域的重要性;
[0084]
s33:将所有源项目数据的数据合并在一起,即将加权后的k个源项目数据以及其标签连接起来,形成训练集为:
[0085]
x=[α1x
s,1
,...,αkx
s,k
],y=[y
s,1
,...,y
s,k
]
ꢀꢀ
(6)
[0086]
其中x
s,i
是第i个源项目数据的样本数据;y
s,i
是第i个源项目数据的标签;[x,y]则是训练集,作为软件缺陷预测过程训练软件缺陷预测模型的训练集;
[0087]
s4:对选定源项目数据进行验证,证明相似性判断准确性;
[0088]
s41:将每个源项目数据分别作为一组训练集;
[0089]
根据已经算出的的wasseerstein距离,为k个源项目数据计算权重,从而可以区分不同源项目数据的重要性,以获得更好的预测效果;
[0090]
s411:根据wasserstein距离d计算e值。
[0091][0092]
其中是第i个源项目数据与目标项目数据的欧式距离的平方,ω是用来控制
wasseerstein距离范围的参数;
[0093]
s412:根据e值计算出k个源项目数据的权重;
[0094][0095]
其中,αi是第i个源项目数据的权重,用权重控制不同源域的重要性;
[0096]
s413:并将所有源项目数据的数据合并在一起,即将加权后的k个源项目以及其标签y连接起来,形成新的训练数据,构成的训练集为:
[0097]
x=[α1x
s,1
,...,αkx
s,k
],y=[y
s,1
,...,y
s,k
]
ꢀꢀ
(6)
[0098]
其中x
s,i
是第i个源项目数据的样本数据,y
s,i
是第i个源项目数据的标签,[x,y]则是训练集;源项目数据自带标签;
[0099]
s42:模型训练;分别利用每组训练集进行模型训练,构建缺陷预测模型;
[0100]
logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归”一词源于最佳拟合,表示要找到最佳拟合参数集,训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化算法,logistic回归的原理是根据训练集现有数据,进行拟合,根据最佳拟合参数得到分隔超平面,通过分隔超平面,将测试集的样本分为两类,logistic回归实现简单,计算量小、速度快;利用相似性度量选择的源项目数据用作模型训练数据,再利用目标项目数据输入训练后的模型进行测试,获得有无缺陷的预测结果;
[0101]
s43:将目标项目数据分别输入到每组源项目数据对应的缺陷预测模型中,获得缺陷结果;
[0102]
s44:模型测试;根据每组缺陷结果计算每个缺陷预测模型的性能评价指标;
[0103]
为了评价预测的效果,需要计算其性能评价指标,根据预测结果和实际结果的不同,共有四种情况,算法预测为有缺陷,模块实际也是有缺陷(true positive,tp);算法预测为有缺陷,模块实际为无缺陷(false positive,fp);算法预测为无缺陷,模块实际为有缺陷(false negative,fn);算法预测为无缺陷,模块实际也为无缺陷(true negative,tn),如下表1所示:
[0104]
表1混淆矩阵
[0105][0106]
选用f-measure作预测的性能评价指标,f-measure是信息检索领域常用的一种评价标准,常用的是f1-measure,它表示准确率(precision)和查全率(recall,pd)的调和平均数,在大数据中准确率与查全率这两个指标相互制约,使用f-measure能很好地描述预测效果,f-measure可定义为:
[0107][0108]
其中,precision和recall分别为准确率和查全率,其公式如下:
[0109][0110][0111]
s45:验证;分别对比每组源项目数据与目标项目数据之间的wasseerstein距离,以及性能评价指标,获得相似性适合度。根据相似性适合度证明选定的源项目数据与目标项目数据是最合适的。
[0112]
如图3所示验证方案:
[0113]
首先,选定目标项目数据,计算其与各个源项目数据的距离,并分别用各个源项目数据对目标项目数据进行预测,得到性能评价指标f-measure;为了验证所选的上述s1-s3的相似性度量方法是否适合用来计算特定数据集之间的距离,验证方案基于一个一般规律:在进行缺陷预测时,所用源项目数据与目标项目数据相似度越高(距离越近),预测效果越好;如图中,将源项目数据1得到的距离和f-measure与源项目数据2得到的距离和f-measure比较,看其是否符合一般规律,若比较时两个源项目数据中与目标项目数据距离较小的源项目预测效果更好,那么它就符合这个一般规律,反之,若比较时两个源项目数据中与目标项目数据距离较小的源项目数据预测效果法反而更差,那么这次比较并不符合一般规律,也就是说,用此种距离度量方法得到的项目数据间距离存在一定问题,并不能完全准确地描述它们之间的相似性,于是,设计一个评价指标,衡量所选距离度量方法用来描述特定数据集之间的相似性的适合程度;
[0114][0115]
此公式的含义为,将n个源项目数据得到的距离和f-measure结果两两比较,总比较次数为n(n-1)/2,而比较中遇到的符合上述一般规律的次数为m,a为两者的比值,用来可以用来衡量所选距离度量方法用来描述特定数据集之间的相似性的适合程度。
[0116]
实施例
[0117]
本发明采用nasa项目中cm1,mw1,pc1,pc3和pc4五个数据集作为实例,如下表2所示。这些数据集的度量元数量均为37,且这5个数据集拥有完全一致的度量元,依次选用这五个数据集中的一个作为目标项目,其余数据集作为源项目,进行同构的跨项目缺陷预测,根据预测效果来选择最佳的机器学习算法。
[0118]
表2原始数据
[0119][0120]
在进行数据预处理之后,计算wasserstein距离,结果如下表3所示。
[0121]
表3 wasserstein距离
[0122][0123]
根据前面内容,选择logistic回归算法,选择nasa项目中的数据集进行实验,将cm1作为测试集,其余四个数据集mw1、pc1、pc3、pc4分别作为训练集,之后按照同样的方法将mw1、pc1、pc3、pc4依次作为测试集,其余数据集作为训练集,进行实验,得到的f-measure结果如下表。
[0124]
表4 f-measure结果
[0125][0126]
[0127]
接下来计算a值,它能够衡量所选距离度量方法用来描述特定数据集之间的相似性的适合程度。例如对于数据集cm1,如表5所示,它与mw1、pc1的wasserstein距离分别为29.5、5119694.8,而利用这两个数据集预测的结果为0.257、0.301,这显然不符合规律,将测试结果结合距离两两比较,总比较次数为6,得到其中符合规律的次数为3,则比值a为0.5。
[0128]
表5 a值计算示例
[0129][0130]
随后使用同样的方法针对数据集mw1、pc1、pc3、pc4算出作为评价指标的a值,最后求得平均值结果就是wasserstein距离(平方欧式距离矩阵)的评价指标。
[0131]
表6 wasserstein(平方欧式距离矩阵)评价指标
[0132][0133][0134]
根据上表,可以得出如下结论,在以cm1为目标项目时,通过wasserstein距离可以
得出mw1更加适合选为源项目,但是通过lr测试结果与a值可以看出,有0.5的概率认为选取mw1是最优解,同理以pc4为例,认为有1的概率选取pc1为最优的源项目。上述验证方法验证了采用本发明的相似性度量方法所挑选项目的有效性,在进行模型训练和预测时,应用本发明的方法可以得到较理想的效果。
[0135]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0136]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1