基于频繁项集算法的电力文本知识发现方法及设备
1.本发明涉及基于频繁项集算法的电力文本知识发现方法及设备,属于电力设备运维技术领域。
背景技术:
2.由于核心电力设备和输电重要线路,其安全运行对整个电力系统的安全至关重要,尤其是运维管理要求高、安全运维责任重大,检修作业的专业化程度高,数据采集工作量也很大。目前针对输变电设备和线路运行数据的采集分析应用还处于初级阶段,前期梳理的设备故障知识库主要以非结构化的形式管理存储,应用较为困难,且尚未结合设备线路的相关规程和案例处置信息,无法实现智能信息检索和推荐,难以有效帮助设备和线路异常监测,以及故障诊断。
技术实现要素:
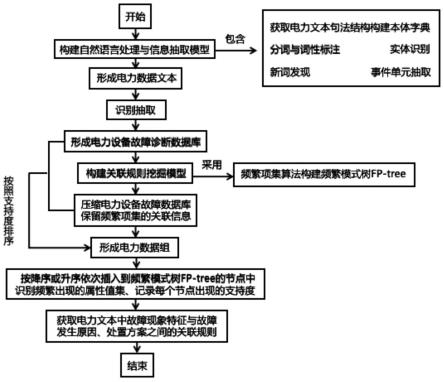
3.针对现有技术的缺陷,本发明的目的一在于提供一种构建自然语言处理与信息抽取模型,获取电力文本句法结构知识并构建本体字典,对电力文本进行实体识别、分词与词性标注、新词发现以及事件单元抽取处理,使得电力文本分布规律、形式统一,形成电力数据文本,进而能够整合提取出电力设备故障/缺陷文本中的有效数据,形成了电力设备故障诊断数据库;同时,构建关联规则挖掘模型,利用频繁项集算法构建频繁模式树fp-tree,对电力设备故障诊断数据库进行压缩,并保留频繁项集的关联信息,进而识别出频繁出现的属性值集以及每个节点处的支持度;从而获取电力文本中故障现象特征与故障发生原因、处置方案之间的关联规则,发现电力文本中蕴含的知识,为电力设备故障诊断提供更精准的辅助决策的电力文本知识发现方法。
4.本发明的目的二在于提供一种通过自然语言处理与信息抽取模块进行文本数据进行归集整合,从而提取出电力设备故障/缺陷文本中的有效数据,形成了电力设备故障诊断数据库;同时利用关联规则挖掘模块利用关联规则挖掘知识发现技术实现对电力文本数据中文本信息进行有效归类,建立映射关系;进而利用fp-growth频繁项集挖掘的技术,解决了传统关联规则挖掘过程中连接较多、占用空间大、运算量大等问题的电力文本知识发现设备。
5.为实现上述目的之一,本发明的第一种技术方案为:
6.基于频繁项集算法的电力文本知识发现方法,
7.包括以下步骤:
8.步骤一,构建自然语言处理与信息抽取模型;
9.所述自然语言处理与信息抽取模型,用于获取电力文本句法结构知识并构建本体字典,对电力文本进行实体识别、分词与词性标注、新词发现以及事件单元抽取处理;
10.步骤二,对步骤一中的电力数据文本进行识别抽取,形成电力设备故障诊断数据库;
11.步骤三,构建关联规则挖掘模型;关联规则挖掘模型采用频繁项集算法构建频繁模式树fp-tree,对步骤二中的电力设备故障诊断数据库进行压缩,并保留频繁项集的关联信息;
12.步骤四,根据步骤三中的关联信息,将电力设备故障诊断数据库中的各数据项按照支持度排序,形成电力数据组;
13.步骤五,将步骤四中电力数据组中的每个数据项按降序或升序依次插入到频繁模式树fp-tree的节点中,识别出频繁出现的属性值集,同时每个节点处均记录该节点出现的支持度;
14.步骤六,根据步骤五中的属性值集以及支持度,获取电力文本中故障现象特征与故障发生原因、处置方案之间的关联规则。
15.本发明经过不断探索以及试验,构建自然语言处理与信息抽取模型,获取电力文本句法结构知识并构建本体字典,对电力文本进行实体识别、分词与词性标注、新词发现以及事件单元抽取处理,使得电力文本分布规律、形式统一,形成电力数据文本,进而能够整合提取出电力设备故障/缺陷文本中的有效数据,形成了电力设备故障诊断数据库。
16.同时,本发明构建关联规则挖掘模型,利用频繁项集算法构建频繁模式树fp-tree,对电力设备故障诊断数据库进行压缩,并保留频繁项集的关联信息,进而识别出频繁出现的属性值集以及每个节点处的支持度;从而获取电力文本中故障现象特征与故障发生原因、处置方案之间的关联规则,发现电力文本中蕴含的知识,为电力设备故障诊断提供更精准的辅助决策。
17.进一步,本发明利用关联规则挖掘知识发现技术实现对电力文本数据中文本信息进行有效归类,并建立映射关系,将原有的知识结构从非结构化电力文本形式升级为以知识元组的形式进行结构化存储;同时基于fp-growth频繁项集挖掘的技术,解决了传统关联规则挖掘过程中连接较多、占用空间大、运算量大的问题。
18.更进一步,本发明特别适用于变电现场,用于辅助运检人员对电力设备运行状态进行辅助诊断与决策的系统,能够快速准确地判断出故障部位及原因,加快站内设备故障处理进度,有效提高基层人员作业效率;进一步本发明能有效结合设备线路的相关规程和案例处置信息,实现智能信息检索和推荐,可以有效的进行设备和线路的异常监测,以及故障诊断,方案科学、合理,切实可行。
19.作为优选技术措施:
20.所述实体识别包括以下内容:
21.步骤11,基于深度学习模型,构建神经网络模型并利用神经网络模型将文字符号特征表示为分布式特征信息;
22.步骤12,利用步骤11中的分布式特征信息,优化网络参数,训练网络模型;
23.步骤13,利用步骤12中的网络模型对电力文本中的语句实体进行识别。
24.作为优选技术措施:
25.所述深度学习模型基于双向长短时记忆网络bi-lstm以及条件随机场crf进行构建;
26.所述双向长短时记忆网络bi-lstm包括输入门、遗忘门、输出门,其基于上一时刻的隐藏层信息和本时刻的输入信息计算三个门机制的值,再与上一时刻存储单元中的信息
进行整合得到本时刻的单元输出,同时对隐藏层信息和存储单元信息进行更新作为下一时刻双向长短时记忆网络bi-lstm的输入;
27.双向长短时记忆网络bi-lstm的计算公式如下:
28.i=σ(x
t
ui+s
t-1
wi)
29.f=σ(x
t
uf+s
t-1
wf)
30.o=σ(x
t
uo+s
t-1
wo)
31.g=tanh(x
t
ug+s
t-1
wg)
32.c
t
=c
t-1
*f+g*i
33.s
t
=tanh(c
t
)*o
34.其中x
t
表示t时刻网络输入值,s
t-1
表示t-1时刻隐藏层神经元的激活值,c表示记忆单元,u、w分别表示模型参数,σ表示sigmoid激活函数,s
t
表示t时刻lstm隐藏层的激活值,i、f、o分别表示输入门、遗忘门、输出门。
35.作为优选技术措施:
36.所述条件随机场crf基于隐马尔可夫模型和最大熵模型进行构建,其计算公式如下:
[0037][0038][0039]
其中,x为输入电力文本序列,y为实体标注序列,p(y/x)为给定x条件下输出序列y的条件概率分布,s
l
(yi,x,i)为状态特征函数,tk(y
i-1
,yi,x,i),z(x)为规范因子。
[0040]
作为优选技术措施:
[0041]
所述分词与词性标注,包括以下内容;
[0042]
步骤21,根据收集整理好的若干份电力文本整理,得到的电力分词语料库;
[0043]
步骤22,采用空格的方式,通过深度学习模型,将步骤21中的电力分词语料库的词一一分割出来,并对词进行词性标注;
[0044]
所述词性为名词或动词或形容词或副词或量词;
[0045]
所述新词发现基于序列标注方法与基于信息熵进行词挖掘。
[0046]
作为优选技术措施:
[0047]
所述事件单元抽取包括以下内容;
[0048]
通过对电力文本进行离线挖掘,找出词与词的相近、同义关系,进行词的标准化;
[0049]
通过分析语言单位内成分之间的依存关系,得到其句法结构;
[0050]
建立实体/属性/值的链接模型,将电力文本中出现的术语或别名与知识库节点/词典中标准词建立对应关系;
[0051]
建立属性值抽取模型、属性值推理模型,对给定输入设备的电力文本,识别出电力文本中目标命名实体对应的属性与对应值,抽取出标准化的实体、属性、值三元组,并作为输入信息输入至关联规则挖掘模型。
[0052]
作为优选技术措施:
[0053]
所述频繁项集算法的具体实现过程如下:
1]};
[0079]
由于候选项集并不是所有的项集都是频繁的,因此需要利用剪枝步减小搜索空间。
[0080]
剪枝步利用apriori算法从集合ck中去掉候选k项集的(k-1)项子集,其具体包括以下内容;
[0081]
通过扫描数据库得到频繁1项集的集合,用频繁1项集生成候选2项集,再次扫描数据库,找出频繁2项集;按照该步骤进行,直至频繁k项集不能再被找到。
[0082]
为实现上述目的之一,本发明的第二种技术方案为:
[0083]
基于频繁项集算法的电力文本知识发现设备,
[0084]
应用上述的基于频繁项集算法的电力文本知识发现方法;
[0085]
包括电容式触摸屏、键盘、处理器、电源模块、设备内存、自然语言处理与信息抽取模块、关联规则挖掘模块,所述自然语言处理与信息抽取模块、关联规则挖掘模块存储在设备内存里;
[0086]
所述自然语言处理与信息抽取模块,用于对文本数据进行归集整合,从而提取出电力设备故障/缺陷文本中的有效数据,形成了电力设备故障诊断数据库;
[0087]
所述关联规则挖掘模块,用于利用关联规则挖掘知识发现技术实现对电力文本数据中文本信息进行有效归类,并建立映射关系;同时利用频繁项集算法构建频繁模式树fp-tree,识别出频繁出现的属性值集以及每个节点处的支持度,获取电力文本中故障现象特征与故障发生原因、处置方案之间的关联规则。
[0088]
本发明针对根据电力文本内容进行电力设备故障自动诊断问题,提供了一种基于频繁项集算法的电力文本知识发现系统,通过自然语言处理与信息抽取模块进行文本数据进行归集整合,从而提取出电力设备故障/缺陷文本中的有效数据,形成了电力设备故障诊断数据库。
[0089]
进一步,本发明关联规则挖掘模块利用关联规则挖掘知识发现技术实现对电力文本数据中文本信息进行有效归类,并建立映射关系;进而利用fp-growth频繁项集挖掘的技术,解决了传统关联规则挖掘过程中连接较多、占用空间大、运算量大的问题。
[0090]
更进一步,本发明特别适用于变电现场,用于辅助运检人员对电力设备运行状态进行辅助诊断与决策的系统,能够快速准确地判断出故障部位及原因,加快站内设备故障处理进度,有效提高基层人员作业效率;进一步本发明能有效结合设备线路的相关规程和案例处置信息,实现智能信息检索和推荐,可以有效的进行设备和线路的异常监测,以及故障诊断,方案科学、合理,切实可行。
[0091]
与现有技术相比,本发明具有以下有益效果:
[0092]
本发明经过不断探索以及试验,构建自然语言处理与信息抽取模型,获取电力文本句法结构知识并构建本体字典,对电力文本进行实体识别、分词与词性标注、新词发现以及事件单元抽取处理,使得电力文本分布规律、形式统一,形成电力数据文本,进而能够整合提取出电力设备故障/缺陷文本中的有效数据,形成了电力设备故障诊断数据库。
[0093]
同时,本发明构建关联规则挖掘模型,利用频繁项集算法构建频繁模式树fp-tree,对电力设备故障诊断数据库进行压缩,并保留频繁项集的关联信息,进而识别出频繁出现的属性值集以及每个节点处的支持度;从而获取电力文本中故障现象特征与故障发生
原因、处置方案之间的关联规则,发现电力文本中蕴含的知识,为电力设备故障诊断提供更精准的辅助决策。
[0094]
进一步,本发明利用关联规则挖掘知识发现技术实现对电力文本数据中文本信息进行有效归类,并建立映射关系,将原有的知识结构从非结构化电力文本形式升级为以知识元组的形式进行结构化存储;同时基于fp-growth频繁项集挖掘的技术,解决了传统关联规则挖掘过程中连接较多、占用空间大、进而本发明能有效结合设备线路的相关规程和案例处置信息,实现智能信息检索和推荐,可以有效的进行设备和线路的异常监测,以及故障诊断,方案科学、合理,切实可行。
[0095]
更进一步,本发明特别适用于变电现场,用于辅助运检人员对电力设备运行状态进行辅助诊断与决策的系统,能够快速准确地判断出故障部位及原因,加快站内设备故障处理进度,有效提高基层人员作业效率。
附图说明
[0096]
图1为本发明关联规则挖掘模型运行流程图;
[0097]
图2为本发明基于频繁项集算法的电力文本知识发现设备框图。
具体实施方式
[0098]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0099]
相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。进一步,为了使公众对本发明有更好的了解,在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。
[0100]
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文所使用的术语只是为了描述具体的实施例的目的,不是旨在限制本发明。
[0101]
如图1所示,本发明基于频繁项集算法的电力文本知识发现方法的一种具体实施例:
[0102]
基于频繁项集算法的电力文本知识发现方法,
[0103]
步骤一,根据电力文件分布杂散、形式不统一的特点,构建自然语言处理与信息抽取模型;
[0104]
所述自然语言处理与信息抽取模型,获取电力文本句法结构知识并构建本体字典,对电力文本进行分词与词性标注、实体识别、新词发现以及事件单元抽取处理,使得电力文本分布规律、形式统一,形成电力数据文本;
[0105]
步骤二,对步骤一中的电力数据文本进行识别抽取,形成电力设备故障诊断数据库;
[0106]
步骤三,构建关联规则挖掘模型;关联规则挖掘模型采用频繁项集算法构建频繁模式树fp-tree,对步骤二中的电力设备故障诊断数据库进行压缩,并保留频繁项集的关联
信息;
[0107]
步骤四,根据步骤三中的关联信息,将电力设备故障诊断数据库中的各数据项按照支持度排序,形成电力数据组;
[0108]
步骤五,将步骤四中电力数据组中的每个数据项按降序或升序依次插入到频繁模式树fp-tree的节点中,识别出频繁出现的属性值集,同时每个节点处均记录该节点出现的支持度;
[0109]
步骤六,根据步骤五中的属性值集以及支持度,获取电力文本中故障现象特征与故障发生原因、处置方案之间的关联规则,发现电力文本中蕴含的知识,为电力设备故障诊断提供的辅助决策。
[0110]
本发明自然语言处理与信息抽取模型的一种具体实施例:
[0111]
电力文本中信息具有数据量巨大且数据类型众多的特点,但受限于数据分布杂散、形式不统一的问题,难以直接对电力文本信息开展机器学习,高效发现其中蕴含的丰富知识。因此收集整合数据对知识发现的开展具有重要意义。
[0112]
自然语言处理与信息抽取模型首先对经过键盘、触屏或是usb录入的电力文本进行处理,获取文本句法结构知识并构建本体字典。这是电力文本知识发现的基础,自然语言处理与信息抽取模型处理电力文本主要分为四个步骤:实体识别、分词与词性标注、新词发现以及事件单元抽取。
[0113]
实体识别包括以下内容:
[0114]
首先,本发明设备基于深度学习的方法,设计和搭建神经网络模型并利用其将文字符号特征表示为分布式特征信息。接着,利用标注数据,优化网络参数,训练网络模型。最后利用训练好的模型对句子中的实体进行识别。本发明设备采用业界比较主流的bi-lstm+crf的模型进行深度学习,lstm单元包括输入门、遗忘门、输出门,是基于上一时刻的隐藏层信息和本时刻的输入信息计算三个门机制的值,再与上一时刻存储单元中的信息进行整合得到本时刻的单元输出,同时对隐藏层信息和存储单元信息进行更新作为下一时刻lstm单元的输入。lstm的计算过程如下:
[0115]
i=σ(x
t
ui+s
t-1
wi)
[0116]
f=σ(x
t
uf+s
t-1
wf)
[0117]
o=σ(x
t
uo+s
t-1
wo)
[0118]
g=tanh(x
t
ug+s
t-1
wg)
[0119]ct
=c
t-1
*f+g*i
[0120]st
=tanh(c
t
)*o
[0121]
其中x
t
表示t时刻网络输入值,s
t-1
表示t-1时刻隐藏层神经元的激活值,c表示记忆单元,u、w都是模型参数,σ表示sigmoid激活函数,s
t
是t时刻lstm隐藏层的激活值,i、f、o分别表示输入门、遗忘门、输出门。
[0122]
crf结合了隐马尔可夫模型和最大熵模型的特点,同时考虑了词语本身及上下文特征还加入了词典等外部特征,提升了模型的实体识别效果,一般采用线性链条件随机场,计算过程如下:
[0123]
[0124][0125]
其中x为输入文本序列,y为实体标注序列,p(y|x)为给定x条件下输出序列y的条件概率分布,s
l
(yi,x,i)为状态特征函数,tk(y
i-1
,yi,x,i),z(x)为规范因子。
[0126]
分词与词性标注包括以下内容:
[0127]
借助收集整理好的788份电力文本整理得到的电力分词语料库,采用空格的方式,借助深度学习算法,将短句中的词一个一个的分割出来,并对词进行词性标注,如:名词、动词、形容词、副词、量词等。
[0128]
新词发现包括以下内容:
[0129]
新词发现是词挖掘结果中去除已知的、不关心的词后,未能通过已有分词方法成功切分出来的词。比如:"烧坏选择器静触头"的分词结果为"烧坏选择器静触头"。其中,"静触头"应该被作为一个词,却被切成了多个词,失去了原有的语义。本发明设备采用基于序列标注方法与基于信息熵的新词发现算法解决此问题。
[0130]
事件单元抽取包括以下内容:
[0131]
首先,通过对大量文本进行离线挖掘,找出词与词的相近、同义关系,为词的标准化打下基础。其次,通过分析语言单位内成分之间的依存关系,揭示其句法结构。再次,建立实体/属性/值的链接模型,将文档中出现的术语或别名与知识库节点/词典中标准词建立对应关系。最后,建立属性值抽取模型、属性值推理模型,对给定输入设备的文本,识别出文本中目标命名实体对应的属性与对应值,抽取出标准化的实体、属性、值三元组,并作为输入信息输入至关联规则挖掘模块。
[0132]
通过上述流程的处理,可以有效解决数据分布杂散、形式不统一的问题,实现电力文本信息的识别抽取,形成电力设备故障诊断数据库,存储于设备的主存储单元中。
[0133]
本发明关联规则挖掘模型的一种具体实施例:
[0134]
关联规则挖掘模型采用fp-growth算法进行构建,其实现流程为:将提供频繁项集的数据库压缩到一棵频繁模式树(fp-tree)中,但保留频繁项集的关联信息。fp-tree将数据库中的各数据项按照支持度排序,把每个数据项按降序依次插入到树的节点中,同时每个结点处均记录有该结点出现的支持度。
[0135]
fp-growth算法具体实现过程如下:
[0136]
s1:对主存储单元中的电力文本数据集进行扫描并设定最小支持度(min
sup
),统计所有单个元素的支持度,删除不满足给定的最小支持度的元素,将1项频繁集放入项头表,并按照支持度降序排列,构造频繁1项集。
[0137]
s2:将读到的原始数据剔除非频繁1项集,并按照支持度降序排列,实现数据的扫描。
[0138]
s3:继续读入排序后的数据集,插入fp树,插入时按照排序后的顺序,插入fp树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到fp树后,fp树在模型中建立完成,完成fp-tree的构造。
[0139]
s4:对频繁项集进行挖掘,其具体包括以下内容:
[0140]
首先,对fp-tree由叶子节点到根节点的顺序进行遍历,生成每个频繁元素节点的
条件模式基(以所查找项为终点的路径集合,表示所查找项与树根节点间的所有路径)。
[0141]
接着,在设备中生成其对应的条件模式树,生成所有的从根节点到叶子节点的路径,挖掘得到频繁模式与频繁项集并将结果反馈回设备显示屏。
[0142]
通过上述流程的处理,挖掘获取电力文本中故障现象特征与故障发生原因、处置方案之间的关联规则,发现电力文本中蕴含的知识,为电力设备故障诊断提供更精准的辅助决策。
[0143]
如图2所示,本发明基于频繁项集算法的电力文本知识发现设备的一种具体实施例:
[0144]
基于频繁项集算法的电力文本知识发现设备
[0145]
应用上述的基于频繁项集算法的电力文本知识发现方法;
[0146]
包括触屏、键盘、usb输入、处理器、电源模块、主存储单元、自然语言处理与信息抽取模块、关联规则挖掘模块,所述自然语言处理与信息抽取模块、关联规则挖掘模块存储在设备内存里;
[0147]
所述自然语言处理与信息抽取模块,用于对文本数据进行实体识别、分词与词性标注、新词发现以及事件单元抽取处理,从而提取出电力设备故障/缺陷文本中的有效数据,并将有效数据存储至主存储单元,形成了电力设备故障诊断数据库;
[0148]
所述关联规则挖掘模块,用于利用关联规则挖掘知识发现技术实现对电力文本数据中文本信息进行有效归类,并建立映射关系;同时利用频繁项集算法构造频繁1项集,然后扫描数据,构造fp-tree,再挖掘频繁项集,并将挖掘结果输送到显示屏上进行显示。
[0149]
所述触屏为10.95英寸2560x1600分辨率的ips电容式触摸屏;处理器为amd ryzen 94900hs处理器;主存储单元的内存容量为6g,存储容量为256gb。
[0150]
本发明提出一种对自然语言自动进行处理与关键信息抽取,最终频繁模式树增长算法的电力文本知识发现设备,方案科学合理、切实可行。
[0151]
应用本发明方法的一种装置实施例:
[0152]
一种计算机设备,其包括:
[0153]
一个或多个处理器;
[0154]
存储装置,用于存储一个或多个程序;
[0155]
当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述的基于频繁项集算法的电力文本知识发现方法。
[0156]
本技术术语解释:
[0157]
电力文本
[0158]
指完整记录了电力设备故障现象、处理过程、解决措施等不同阶段设备故障信息的文本,蕴含了丰富的设备隐含质量问题信息及专家处理经验,在同类设备故障处理时具有较高参考价值。主要包含有:故障案例、处置方案、规范、导则、标准、科研论文等形式。
[0159]
知识发现
[0160]
指从数据库中提取出有用的信息,这些信息可能是有用的、容易被理解的、潜在的,并且剔除没有规律的、冗余的数据。其核心是将一个低级别的数据映射成其他形式,这些形式可能是更紧凑的、更有用的、更容易被人理解的。
[0161]
频繁项集
[0162]
指在数据集中识别出频繁出现的属性值集,可以为可能的决策提供支持。
[0163]
关联规则
[0164]
指是一种基于规则的机器学习方法,用于从某特定数据集中发现其中不同事件之间的隐含对应关系。
[0165]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0166]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0167]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1