一种面向卷积神经网络的分布式学习方法与流程
1.本发明涉及深度神经网络技术领域,更具体的说是涉及一种面向卷积神经网络的分布式学习方法。
背景技术:
2.卷积神经网络在高维数据的分类中取得了巨大成功,例如图像识别和目标检测,被广泛应用于大量应用中。但是,训练卷积神经网络是数据密集型的任务,往往需要从多个数据源收集大规模的数据。一个卷积神经网络模型通常包含百万级参数,需要大量数据和算力来训练这些参数。
3.现有联邦学习方法允许多个数据源在数据不出本地的情况下,通过模型参数的局部更新和全局共享机制,分布式地共同训练卷积神经网络。在这种方法下,数据源端(代理端)和云中心服务器间需要传输整个卷积神经网络的模型参数,通信代价巨大。
4.因此,如何减少训练过程中的通信代价是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种面向卷积神经网络的分布式学习方法,解决基于多源数据分布式共同训练深度神经网络过程中面临的通信代价问题,减少训练过程中的通信代价。
6.为了实现上述目的,本发明采用如下技术方案:
7.一种面向卷积神经网络的分布式学习方法,包括:
8.将卷积神经网络切割为前层网络和后层网络,并将前层网络部署至n个代理端,n≥2,将后层网络部署至1个中心服务器;
9.初始化代理端前层网络和中心服务器后层网络;
10.基于一个代理端对一个中心服务器的模式分布式共同训练卷积神经网络;
11.基于多个代理端对一个中心服务器的模式分布式共同训练卷积神经网络。
12.优选的,将卷积神经网络切割为前层网络和后层网络,并将前层网络部署至n个代理端,将后层网络部署至1个中心服务器的具体步骤如下:
13.拟训练卷积神经网络标记为函数f,卷积神经网络的拓扑结构记为(l1,l2,l3,
…
,ln);
14.获取卷积神经网络的配置文件,得到卷积神经网络每层结构,结构类型具体包括卷积层、池化层、激活函数层、dropout层和全连接层;
15.将卷积神经网络从输入层向输出层遍历,切割点选择在第一个全连接层的前面;
16.根据切割点将卷积神经网络切割为前层网络和后层网络,前层网络记为fa,由输入层到切割点前的层组成,其拓扑结构标记为(l1,l2,l3,
…
,ln),后层网络记为fc,由切割点后的层到输出层组成,其拓扑结构标记为(l
n+1
,l
n+2
,
…
,ln);
17.将前层网络fa部署至n个代理端,将后层网络fc部署至中心服务器。
18.优选的,基于一个代理端对一个中心服务器的模式分布式共同训练卷积神经网络具体包括以下步骤:
19.设置卷积神经网络训练参数,至少包括批量大小、学习率和最大轮数;
20.随机选择一个代理端作为第一个代理端a1,基于前向传播的逐层计算原理,通过第一个代理端a1的训练数据d1在前层网络上计算前向传播过程,输出张量fa(d1):fa(d1)
←
ln(l
n-1
...l1(d1));此步可以确保代理端a1在自有数据d1不出本地的情况下,与中心服务间共同训练卷积神经网络;
21.第一个代理端a1通过网络向中心服务器传输张量fa(d1)和训练数据d1对应的标记label;具体而言,网络可以无线网络、有线网络、4g或5g。
22.基于前向传播的正向逐层计算原理,中心服务器接收张量fa(d1)和标记label后,以张量fa(d1)作为输入,在后层网络上计算前向传播过程,输出张量output:output
←
fc(fa(d1));此步确保了代理端a1和中心服务器共同完成了卷积神经网络的前向传播过程。
23.中心服务器计算张量output和标记label间的梯度g,记为:g
←
g(output,lable),其中g表示卷积神经网络的代价函数;
24.中心服务器以梯度g为输入,在后层网络上计算反向传播过程,输出张量g':表示后层网络中第n层网络至第n+1层网络依次输出的张量;
25.中心服务器通过网络向第一个代理端a1传输张量g';
26.第一个代理端a1接收张量g'后,以张量g'作为输入,在前层网络上计算反向传播过程,输出梯度g”:表示前层网络中第n层网络至第一层网络依次输出的梯度;
27.中心服务器将第一个代理端a1记为最后一次训练的代理。
28.优选的,基于多个代理端对一个中心服务器的模式分布式共同训练卷积神经网络具体包括以下步骤:
29.步骤a:随机选择代理端a
x
,代理端a
x
通过网络向中心服务器请求最后一次训练的代理,其中,x是从{2,3,...n}中随机选择;
30.步骤b:中心服务器通过网络向代理端a
x
发送上次一对一模式中最后一次训练的代理端ay;
31.步骤c:代理端a
x
通过网络向代理端ay请求前层网络的参数;
32.步骤d:代理端ay通过网络向代理端a
x
发送前层网络的参数φy;
33.步骤e:代理端a
x
基于前层网络的φy更新自身前层网络的参数;
34.步骤f:代理端a
x
和中心服务器c基于一对一模式训练卷积神经网络;
35.步骤g:再次循环上述步骤a~步骤f,直至所有代理端训练完毕。
36.优选的,通过python编程语言的标准随机函数初始化代理端前层网络fa的参数,所述准随机函数为xavier和gaussian。
37.通过python编程语言的标准随机函数初始化中心服务器端后层网络fc的参数。所述准随机函数为xavier和gaussian。
38.经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种面向卷积神
经网络的分布式学习方法,在减少训练过程代理和中心服务器间通信代价的情况下,基于多个数据源分布式地共同训练卷积神经网络。
附图说明
39.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
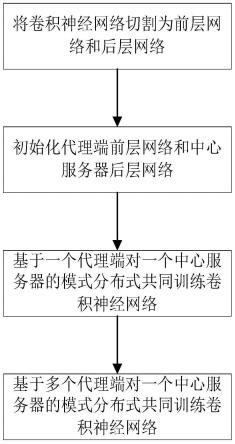
40.图1附图为本发明提供的一种面向卷积神经网络的分布式学习方法流程图。
41.图2是本发明实施例中卷积神经网络的拓扑结构。
42.图3是本发明实施例中代理端和中心服务器间的分布式学习架构。
具体实施方式
43.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
44.以图2所示卷积神经网络vgg-16为例,采用mnist数据集,描述100个代理和1个云中心服务器间分布式共同训练卷积神经网络,如图3所示。其中,mnist共有70000张灰度图像,10个类别;每个代理均匀分配7000张图像,每张图像对应0-9间的某个数字。在每个代理的7000张图像中,5000张用于训练,2000张用于测试。如图1所示,一种面向卷积神经网络的分布式学习方法,具体为:
45.s1:将卷积神经网络切割为前层网络和后层网络;
46.s1具体为:
47.s1.1:拟训练卷积神经网络标记为函数f,卷积神经网络的拓扑结构记为(l1,l2,l3,
…
,l
16
);
48.s1.2:获取卷积神经网络的配置文件,得到每层的类型。具体而言,每层的类型可以分为:卷积层、池化层、dropout层和全连接层;
49.s1.3:从输入层向输出层遍历,切割点为第13层和第14层间;
50.s1.4:根据切割点,将卷积神经网络切割为两部分:前层网络和后层网络,前层网络记为fa,由输入层到切割点前的层组成,其拓扑结构标记为(l1,l2,l3,
…
,l
13
);后层网络记为fc,由切割点后的层到输出层组成,其拓扑结构标记为(l
14
,l
15
,l
16
);
51.s1.5:将前层网络fa部署到100个代理端;将后层网络fc部署到1个云中心服务器端。
52.s2:初始化代理端前层网络和云中心服务器端后层网络;
53.s2具体为:
54.s2.1:使用python编程语言的标准随机函数xavier初始化α,各代理使用α更新前层网络fa的参数。
55.s2.2:使用python编程语言的标准随机函数xavier初始化β,云中心服务器使用β
更新后层网络fc的参数。
56.s3:采用1对1模式分布式共同训练卷积神经网络;
57.s3具体为:
58.s3.1:设置卷积神经网络训练参数,其中批量大小为32,学习率为0.001,最大轮数为500。
59.s3.2:基于前向传播的逐层计算原理,代理端a1使用自有训练数据d1在前层网络上计算前向传播过程,输出张量:fa(d1)
←
l
13
(l
12
...l1(d1)),其中d1的大小为5000张灰度图像,共有10个类别。
60.s3.3:代理端a1通过有线网络向云中心服务器c传输fa(d1)和数据d1对应的标记label(共10个类别)。
61.s3.4:基于前向传播的正向逐层计算原理,云中心服务器c接收fa(d1)和label后,以fa(d1)作为输入,在后层网络上计算前向传播过程,输出张量:output
←
fc(fa(d1))。
62.s3.5:云中心服务器c计算上述步骤输出的张量output和标记label间的梯度g,记为:g
←
g(output,lable),其中g表示卷积神经网络的代价函数。
63.s3.6:云中心服务器c以上述步骤输出的梯度g为输入,在后层网络上计算反向传播过程,输出张量:
64.s3.7:云中心服务器c通过网络向代理端a1传输g'。
65.s3.8:代理端a1接收g'后,以g'作为输入,在前层网络上计算反向传播过程,输出梯度:
66.s3.9:云中心服务器c将代理端a1记为最后一次训练的代理。
67.s4:采用多对1模式分布式共同训练卷积神经网络。
68.s4具体为:
69.s4.1:随机选择代理端a
x
,代理端a
x
通过有线网络向云中心服务器c请求最后一次训练的代理。这里,x随机选择为5。
70.s4.2:云中心服务器c通过有线网络向代理端a5发送最后一次训练的代理a1。
71.s4.3:代理端a5通过有线网络向代理端a1请求前层网络的参数。
72.s4.4:代理端a1通过有线网络向代理端a5发送参数φ1。
73.s4.5:代理端a5使用φ1更新自身前层网络的参数。
74.s4.6:代理端a5和云中心服务器c使用s3的1对1模式训练卷积神经网络;
75.s4.7:再次循环上述s4.1~s4.6,直至所有代理端训练完毕
76.以图2所示卷积神经网络vgg-16为例子,对联邦学习和本发明方法训练过程中的一次通信轮回需要传输的通信代价进行比较。
77.首先,表1给出vgg 16中每层的参数和张量大小,其中conv3-64表示卷积核的大小为3
×
3,64个;fc-4096表示全连接神经元的个数为4096。
78.其次,联邦学习需要代理和中心服务间传输的参数大小为138,357,544,即对16个层参数的求和。由于每个参数在python语言中占据4个byte,故参数占据的内存大小为138,357,544
×4÷
1024
÷
1024=527.79mb。
79.然后,本发明方法在13层和14层对vgg16进行切割,需要代理和中心服务间传输的
张量大小为512
×
14
×
14=100,352,即第13层的张量大小。同样地,由于每个参数在python语言中占据4个byte,故张量占据的内存大小为100,352
×4÷
1024
÷
1024=0.38mb。
80.最后,基于上述计算,可知:本发明方法在一次通信轮回中需要传输的数据量为0.38mb,而联邦学习需要传输的数据量为=527.79mb。本发明方法所传输的数据量为联邦学习方法的0.07%,极大地减少了通信低价。
81.表1 vgg 16中每层的参数和张量大小
82.层数类型参数张量第1层conv3-641,79264
×
224
×
224第2层conv3-6436,92864
×
224
×
224第3层conv3-12873,856128
×
112
×
112第4层conv3-128147,584128
×
112
×
112第5层conv3-256295,168256
×
56
×
56第6层conv3-256590,080256
×
56
×
56第7层conv1-256590,080256
×
56
×
56第8层conv3-5121,180,160512
×
28
×
28第9层conv3-1522,359,808512
×
28
×
28第10层conv1-5122,359,808512
×
28
×
28第11层conv3-5122,359,808512
×
14
×
14第12层conv3-1522,359,808512
×
14
×
14第13层conv1-5122,359,808512
×
14
×
14第14层fc-4096102,764,5444096第15层fc-409616,781,3124096第16层fc-10004,097,0004096
83.本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
84.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1