基于深度元学习和生成对抗网络的字体修复方法及系统
1.本发明主要涉及到计算机视觉图像处理领域、图片文字修复技术领域,特别是涉及一种基于字体笔画、结构、轮廓的深度元学习和循环生成对抗网络的书法字体修复方法、系统。
背景技术:
2.随着深度学习技术的快速发展和人工智能应用的普及,相关新型技术已为人们的生产生活带来了巨大的便捷。在如今,中华传统文化正在被大家所重视,字体书法正式传统文化中的一部分。而在获得中国古今的汉字书法字体时,时常会因为年代久远或者其他因素导致书法字体缺失破损,如何对于这些书法字体进行修复是现在的一个热点研究。
3.近年来,各种针对破损残缺的书法字体进行修复的方法层出不穷,主要分为传统方法和深度学习的方法。传统方法如专利cn105069766a一种基于汉字图像轮廓特征描述的碑文修复方法,通过对已有书法数据集进行字体结构和笔画的分割,得到一个部件笔画模板集合。然后在修复过程中,查找笔画模板中的相似匹配度最高的笔画进行填充修复,这种类型的方法虽能对字体有个很好的结构还原,但对风格较为潦草的字体(例如草书、行书等)补全的笔画风格差异较大。
4.如今深度学习的技术快速发展背景下,最新的一些工作引入深度神经网络和生成对抗网络的思路对缺损书法字体进行修复。cn110765339a一种基于生成对抗网络的残缺中文书法修复补全方法和cn110335212a基于条件对抗网络的缺损古籍汉字修复方法中提出利用生成对抗网络或者条件生成对抗网络来进行字体修复,均为将待修复字体直接放入神经网络模型中进行训练得到修复后的字体图片,在全局范围上进行的调整修改,并没有考虑到字体结构等特征。专利cn110570481a基于风格迁移的书法字体库自动修复方法及系统中均提出使用风格迁移的方法进行书法字体的修复,该方法虽然大大减少了传统字体分割等工作量,生成的效果也较好,但是所使用的风格迁移模型需要配对的数据集,这种数据集在实际应用场景下是很难获得的,我们难以获得该汉字在该书法类别中所对应的字体图像。
5.专利cn112435196基于深度学习的文字修复方法及系统中提出使用深度学习的方法进行修复,该方法首先通过文字完整性检测模块输出缺失笔画,然后利用缺失笔画匹配模块针对缺失笔画匹配相似风格笔画。该方法结合笔画信息和生成对抗网络的方法进行修复,但并未考虑汉字字体结构和局部关系等特征。并且在实际场景下,我们能获得的待修复书法字体的数据集较少,该方法无法解决小样本场景下的书法字体修复问题。
6.因此,亟需一种多维度字体特征考虑下,利用小样本书法字体数据进行缺失修复的方法。
技术实现要素:
7.本发明的目的在于提供一种基于深度元学习和生成对抗网络的字体修复方法及
系统,利用深度元学习的方法学习汉字字体笔画、轮廓、结构和局部关系等多维度字体特征,通过小样本书法字体数据进行缺损字体修复的方法。
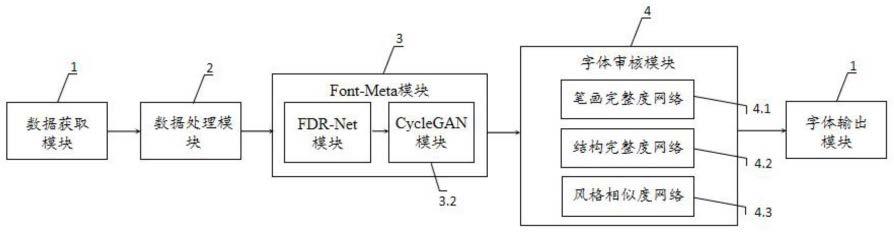
8.为了达到上述目的,在本发明的第一个方面,提供一种基于深度元学习和生成对抗网络的字体修复方法,其特征在于,其包括如下步骤:
9.s1、使用数据获取模块获取已有的书法字体数据集dataset-1以及字体的笔画和结构数据;
10.s2、使用数据处理模块将数据针对不同任务进行不同方式的处理;
11.s3、使用font-meta模块对残缺的书法字体进行补全;
12.s4、使用字体审核模块寻找最好的补全字体;
13.s5、使用字体输出模块输出修复字体。
14.进一步地,所述s1中所述数据集dataset-1构建的步骤为:
15.s11、获取待修复的书法作品;
16.s12、利用覆盖矩阵对原始整幅书法作品图像进行书法字体裁剪,将裁剪后的获得的图像进行扩充或者压缩至大小为256
×
256的图片;
17.s13、对统一尺寸后的图片转为单通道,进行二值化处理,得到字的二值化图片;
18.s14、二值化图片集构建所述数据集dataset-1。
19.进一步地,将所述数据集dataset-1进一步处理为dataset-11,具体步骤为:
20.s21、获得完整书法字体和艺术字体;
21.s22、选择图像熵最大的图片作为数据;
22.s23、随机生成不同大小的不规则形状作为字体掩码,模拟书法字体的缺损情况;
23.s24、字体掩码分别加入数据集dataset-11中,得到类缺失图片集合;
24.s25、将类缺失图片集合进行配对,构建数据集dataset-11。
25.进一步地,所述s3包括:
26.s31、构造字体补全网络fdr-net,循环生成对抗网络和字体结构审核模型;
27.s32、利用maml的方法对字体补全网络fdr-net进行预训练;
28.s33、将字体补全网络fdr-net修复后的字体放入循环生成对抗网络进行局部风格调整,输出风格转换后的字体图像。
29.进一步地,将所述数据集dataset-11放入所述font-meta模块中进行学习,初始化并预训练字体补全网络fdr-net,步骤为:
30.s321、获取字体笔画数据;
31.s322、获取字体结构数据;
32.s323、构造模拟书法字体残缺的数据集,进行残缺数据和原始数据配对;
33.s324、构造字体补全网络fdr-net模型;
34.s325、训练字体补全网络fdr-net。
35.进一步地,所述s33包括:
36.s331、初始并预训练循环生成对抗网络;
37.s332、得到待修复的书法字体数据,并对字体补全网络fdr-net精调,进行风格和字体内容结构学习;
38.s333、预训练和精调后得到精调后的字体补全网络fdr-net;
39.s334、对缺失部分进行补全,得到初步修复后的图片;
40.s335、将初步修复后的图片输入循环生成对抗网络中进行局部风格迁移,得到迁移后的图像。
41.进一步地,所述预训练字体补全网络fdr-net,能够补全缺失部分的笔画结构,得到补全后的书法字体m1。
42.进一步地,所述s4包括:
43.s41、预训练笔画完整度网络、结构完整度网络和风格相似度网络;
44.s42、将风格转换后的图像输入笔画完整度网络进行打分,得到score1;
45.s43、将风格转换后的图像输入结构完整度网络进行打分,得到score2;
46.s44、将风格转换后的图像输入风格相似度网络进行打分,得到score3;
47.s45、通过分别计算笔画完整度网络、结构完整度网络和风格相似度网络三个网络打分结果的加权平均值,能得到最终的分值序列,选择得分最高的修复后的书法字体图片进行输出。
48.进一步地,font-meta模块包括fdr-net模块和cyclegan模块;
49.fdr-net模块,用于生成网络和深度元学习的方法学习如何进行字体补全;
50.yclegan模块,用于补全字体的局部风格转换。
51.在本发明的第二个方面,提供一种基于深度元学习和生成对抗网络的字体修复系统,其特征在于,其包括如下模块:
52.数据获取模块,用于获取已有的书法字体数据集dataset-1以及字体的笔画和结构数据;数据处理模块,用于将数据针对不同任务进行不同方式的处理;
53.font-meta模块,用于对残缺的书法字体进行补全;
54.字体审核模块,用于寻找最好的补全字体;
55.字体输出模块,用于输出修复字体。
56.本发明的有益技术效果至少在于以下几点:
57.(1)与现有技术相比,本发明提出的基于深度元学习的方法能够基于现有的数据样本学到汉字的字体笔画、结构和风格等特征,在对汉字字体缺失部位进行补全时考虑的因素比现有技术更加全面;
58.(2)由于待修复的书法字体数据较少,现有技术都是基于已知大量数据的前提下进行学习,本发明利用元学习的机制,只需要少量新数据样本就能够从已有的知识池中推断出该种类型数据特征,大大减少对新数据的数量需求。
59.(3)现有技术均需要配对的数据集进行风格转换,采用循环生成对抗网络可以不需要配对数据集完成字体风格转换。同时加入字体审核模块,进一步提高了书法字体修复的质量。在书法字体修复领域上,该发明能大大较少人工成本,并且提升字体修复的精度和完整程度。
附图说明
60.利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
61.图1是本发明实施例字体修复系统的结构示意图。
62.图2是本发明实施例汉字字体结构示意图。
63.图3是本发明实施例maml算法流程图。
64.图4是本发明实施例循环生成对抗网络的算法流程示意图。
具体实施方式
65.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
66.本发明提供的基于深度元学习认知字体的结构、笔画、轮廓等特征并结合循环生成对抗网络进行风格转换的书法字体修复方法。利用现有的书法字体数据集进行元训练数据集s1,通过对现有字体库中的字体笔画、字体结构和字体内容等特征进行学习以及学习缺失笔画的字体补全过程,得到各字体不同维度特征的先验知识以及元模型font-meta和字体结构审核模型fsr-net。然后将待修复的数据进行处理后得到数据集s2,放入font-meta中进行该种类型的书法字体笔画,结构,内容,风格的学习,并通过将font-meta的字体补全网络fdr-net 修复的字体放入循环生成对抗网络中进行风格再迁移,得到与原始字体风格一致的完整书法字体图片。
67.在一个实施例中,如图1所示,提供的基于深度元学习和循环生成对抗网络的书法字体修复系统,其包括以下模块:
68.数据获取模块,用于获取已有的书法字体数据集dataset-1以及字体的笔画和结构数据;
69.数据处理模块,用于将数据针对不同任务进行不同方式的处理;
70.font-meta模块,用于对残缺的书法字体进行补全;
71.字体审核模块,用于寻找最好的补全字体;
72.字体输出模块,用于输出修复字体。
73.本实施例提供的基于深度元学习和循环生成对抗网络的书法字体修复方法,其包括如下步骤:
74.s1中所述数据集dataset-1构建的步骤为:
75.s11、获取待修复的书法作品;
76.s12、原始整幅书法作品图像,利用覆盖矩阵进行书法字体裁剪,将裁剪后的获得的图像进行扩充或者压缩至大小为256
×
256的图片;
77.s13、对统一尺寸后的图片转为单通道,进行二值化处理,得到字的二值化图片;
78.s14、处理好的二值化图片集为所述数据集dataset-1。
79.构建现有汉字字体的数据集dataset-1具体步骤为:
80.首先需要获取已有的所有标准字体和艺术字体数据集,并利用k-means的方法进行数据聚类处理,随机提取每一类中重点数据样本10个。然后将dataset-1根据不同处理方法和不同目的分割为dataset-11,dataset-12,dataset-13,dataset-14。处理方法和不同使用目的如s1101-s1104所示:
81.s1101、dataset-11是字体补全网络使用的数据集。该数据集的特点在于,随机生
成像素值为0的不同大小的不规则形状作为字体掩码,模拟书法字体的缺损情况。掩码分别加入新数据集中,得到类缺失图片集合。将类缺失图片集合和原始图片进行配对,构建数据集。最后对于数据集dataset-11进行分割为支持集和查询集(支持集和查询集在s13中会进行介绍);
82.s1102、dataset-12是字体审核模块中笔画完整度网络使用的数据集。获取笔画数据集,根据新华字典总共分为101个笔画种类,设计笔画分离网络a,将dataset-1数据集中的汉字图片进行笔画分离;
83.s1103、dataset-13是字体审核模块中结构完整度网络使用的数据集。根据维基百科可知,汉字字体主要有12种不同的结构,如上下、左右、包围等,12种结构如图2所示;
84.s1104、dataset-14是字体审核模块中风格相似度网络使用的数据集。是对dataset-1 数据进行二值化处理后得到的数据集。
85.将所述数据集dataset-1进一步处理为dataset-11,具体步骤为:
86.s21、获得正常书法和艺术字体;
87.s22、利用字体信息熵选择最好的数据;
88.s23、随机生成不同大小的不规则形状作为字体掩码,模拟书法字体的缺损情况;
89.s24、字体掩码分别加入数据集dataset-11中,得到类缺失图片集合;
90.s25、将类缺失图片集合进行配对,构建数据集dataset-11。
91.所述s3包括:
92.s31、构造字体补全网络fdr-net,循环生成对抗网络和字体结构审核模型,初始化并预训练字体补全网络fdr-net,该网络是一个简单的变分自动编码器结构,主要包括编码器模块和解码器模块。编码器和解码器均由卷积层、归一化层、池化层等构成,编码器和解码器的网络大小和层数可以任意设置。详细的,在本实例中,采用的是5
×
5的卷积核和2
×
2的池化,步长stride为1,6层卷积层,卷积核数量分别为32、32、64、128、256、256。
93.初始化并预训练循环生成对抗网络,该网络主要由两个生成器g和f以及两个判别器d1 和d2所构成。
94.生成器g:学习映射g:x
→
y,其中x是原始字体风格;y是生成器g生成的字体风格。生成器g的主要目的在于学习能使g(x)和y相似的映射。
95.生成器f:学习映射f:y
→
x,接收目标字体风格,将其转换成和原字体风格相似的风格。生成器f的主要目的是学习能使f(g(x))和x相似的映射。
96.生成器g和f网络结构由3个卷积块、2个残差块和2个上采样块构成。每个卷积块包含一个2d卷积层和1个batchnorm层,使用relu作为激活函数。每个残差块中包含两个2d 卷积层,每个卷积层后面都有一个批归一化层,设置的momentum值为0.8。每个上采样块包含一个2d转置卷积层,使用relu作为激活函数。
97.判别器d1:主要负责区分生成器f生成的图像(用f(y)表示)和目标领域中的真实图像 (表示为x)。
98.判别器d2:主要负责区分生成器g生成的图像(用g(x)表示)和目标领域中的真实图像 (表示为y)。
99.判别器d1和d2的架构类似patchgan中的判别网络架构,包含5个卷积层,5个batchnorm 层。
100.s32、利用maml的方法对字体补全网络fdr-net进行预训练;
101.利用maml的方法对字体补全网络fdr-net进行预训练,dataset1的数据集说明:dataset1 称为d-meta-train数据集。设dataset1数据集中有φ种类型的字体,font1~font
φ
,其中m为每种字体所含有的样本数。该数据集中分为了n个task,每个task是对不同风格字体添加掩码后的残缺字体和完整字体的20组配对集合,如同时每个任务分为支持集和查询集,在本专利任务中,将配对好的5组数据集称为支持集,另外15组数据集作为查询集。每一个task相当于普通深度学习模型训练过程的一个数据,因此我们需要反复在训练数据分布中抽取若干个task组成batch,然后使用adam优化器进行优化。
102.首先对任务进行定义,我们将待修复书法数据的设为f,补全网络进行修复后的数据设为o,那么每一个任务就是其中r表示补全网络。本实施例使用r
θ
来表示参数为θ的字体生成器。当模型学习第i个任务ti时,参数θ变成θ
′i,适应当前任务ti的参数θ
′i使用支持集通过m步梯度下降更新模型参数获得,对于其中的一步梯度下降,计算公式为
[0103][0104][0105]
查询集loss函数为:
[0106][0107]
对于整个所有n个任务进行损失求和,元学习目标函数为:
[0108][0109]
整个预训练过程如算法1所示,目的是得到字体补全网络fdr-net:
[0110]
fdr-net模块,用生成网络和深度元学习的方法学习如何进行字体补全,具体元训练过程为:
[0111]
首先是前两个require。第一个require指的是dmeta-train中task的分布,我们可以反复随机抽取task,形成一个由若干个t组成的task池,作为maml的训练集,如图3所示。第二个require就是学习率,maml是基于二重梯度的,每次迭代包含两次参数更新的过程,所以有两个学习率可以调整。
[0112]
步骤1:随机初始化模型参数;
[0113]
步骤2:是一个循环,可以理解为一轮迭代过程或一个epoch,当然,预训练过程也可以有多个epoch,相当于设置epoch;
[0114]
步骤3:随机对若干个(例如5个)task进行采样,形成一个batch;
[0115]
步骤4-步骤7:第一次梯度更新过程。
[0116]
复制一个原模型,计算出新的参数,用在第二轮梯度的计算过程中。利用batch中的每一个task,分别对模型的参数进行更新(5个task即更新5次)。注意这个过程在算法中是可以反复执行多次的,但是伪代码没有体现这一层循环。
[0117]
步骤5:利用batch中的某一个task中的支持集,计算每个参数的梯度。
[0118]
步骤6:第一次梯度的更新。
[0119]
步骤4-步骤7:结束后,maml完成了第一次梯度更新。接下来根据第一次梯度更新得到的参数,通过gradient by gradient,计算第二次梯度更新。第二次梯度更新时计算出的梯度,直接通过adam作用于原模型上,也就是模型真正用于更新其参数的梯度。
[0120]
步骤8:这里对应第二次梯度更新的过程。这里的loss计算方法,大致与步骤5相同,但是不同点有两处:第一处是我们不再分别利用每个task的loss更新梯度,而是像常见的模型训练过程一样,计算一个batch的loss总和,对梯度进行随机梯度下降adam;第一处是这里参与计算的样本,是task中的查询集,在我们的例子中,即5-way*15=75个样本,目的是增强模型task上的泛化能力,避免过拟合支持集。
[0121]
步骤8结束后,模型结束在该batch中的训练,开始回到步骤3,继续采样下一个batch。
[0122]
以上便是maml预训练得到fdr-net的全部过程。
[0123]
接下来,在面对字体补全数据以及新的字体补全task时,我们将在fdr-net的基础上,精调(fine-tune)得到m-fine-tune。
[0124]
精调过程于预训练过程大致相同,不同之处有以下几点:
[0125]
步骤1中,精调不用再随机初始化参数,而是利用训练好的fdr-net初始化参数;
[0126]
步骤3中,精调只需要抽取一个task进行学习,自然也不用形成batch。精调利用这个 task的支持集训练模型,利用查询集测试模型;
[0127]
精调没有步骤8,因为task的查询集是用来测试模型的,目标图像对模型是未知的。因此精调过程没有第二次梯度更新,而是直接利用第一次梯度计算的结果更新参数。
[0128]
s33、将补全网络fdr-net修复后的字体放入循环生成对抗网络进行局部风格调整,输出风格转换后的字体图像,具体的,只需要获取少量目标风格书法字体(可以是完整也可是局部字体)且更具循环生成对抗网络的特性——不需要配对好的风格数据集,就能够完成原目标字体的风格转换,该模型训练中涉及对抗损失和循环一致损失:
[0129]
对抗损失和生成字体图像的分布以及目标域的分布相匹配:
[0130][0131]
公式5中的x是原字体风格,y是目标字体风格。判断器dy试图区分映射g生成的风格 (即g(x))和目标字体风格y。判断器d
x
试图区分映射f生成的风格(即f(y))和原始字体风格。
[0132]
循环一致性损失用来避免学习中的转换器g和f相互矛盾。如果仅使用对抗损失,网络将同样一组输入字体图像映射到目标字体的任一组随机组合的图像上。因此,获得的任何映射都可以学到一种类似于目标概率分布的输出。概率xi和yi之间就会由很多中映射的方式。循环一致性损失通过减少可能映射的数量来解决这一问题。那么循环一致性的损失函数公式如
[0133]
式6所示。
[0134][0135]
如果使用循环一致性损失,那么通过f(g(x))和g(f(y))进行重构的图像会分别和x,y相似。
[0136]
完整的目标函数是对抗损失和循环一致性损失的加权和,如公式3所示。
[0137]
l(f,g,d
x
,dy)=l
gan
(g,x,y,dy)+l
gan
(f,y,x,d
x
)+φl
cyc
(f,g)
ꢀꢀꢀ
(7)
[0138]
公式7中l
gan
(g,dy,x,y)是第一个对抗损失,l
gan
(f,d
x
,y,x)是第二个对抗损失。第一个对抗损失是基于生成器a和判别网络b计算的,第二个对抗损失是基于生成网络b和判别网络a计算的。目标函数需优化公式8的函数,来训练cyclegan。
[0139][0140]
cyclegan的训练步骤如图4所示。
[0141]
将所述数据集dataset-11放入所述font-meta模块中进行学习,初始化并预训练字体补全网络fdr-net,步骤为:
[0142]
s321、获取字体笔画数据;
[0143]
s322、获取字体结构数据;
[0144]
s323、构造模拟书法字体残缺的数据集,进行残缺数据和原始数据配对;
[0145]
s324、构造字体补全网络fdr-net模型;
[0146]
s325、训练字体补全网络fdr-net。
[0147]
所述s33包括:
[0148]
s331、初始并预训练循环生成对抗网络;
[0149]
s332、得到待修复的书法字体数据,并对字体补全网络fdr-net精调,进行风格和字体内容结构学习;
[0150]
s333、预训练和精调后得到精调后的字体补全网络fdr-net;
[0151]
s334、对缺失部分进行补全,得到初步修复后的图片;
[0152]
s335、将初步修复后的图片输入循环生成对抗网络中进行局部风格迁移,得到迁移后的图像。
[0153]
预训练字体补全网络fdr-net,能够补全缺失部分的笔画结构,得到补全后的书法字体 m1。
[0154]
s4包括:
[0155]
s41、预训练笔画完整度网络、结构完整度网络和风格相似度网络;
[0156]
s42、将风格转换后的图像输入笔画完整度网络进行打分,笔画完整度打分。笔画完整度网络是一个浅层的全连接神经网络,网络层数、神经元个数以及优化器可以任意设置,在本实例中采用5层全连接层,使用relu激活函数和sgd优化器进行模型训练,得到score1;
[0157]
s43、将风格转换后的图像输入结构完整度网络进行打分,结构完整网络是一个卷积神经网络,卷积核的卷积层数同样可以任意设置。在本实例中采用4层卷积层,4层池化层和2 层全连接层,使用relu激活函数和adam优化器进行模型训练,得到score2;
[0158]
s44、将风格转换后的图像输入风格相似度网络进行打分,风格相似度网络和结构完整度网络类似,采用4层卷积层,4层池化层和2层全连接层,使用relu激活函数和adam优化器进行模型训练,得到score3;
[0159]
s45、通过分别计算笔画完整度网络、结构完整度网络和风格相似度网络三个网络打分结果的加权平均值,能得到最终的分值序列,选择得分最高的修复后的书法字体图片进行输出:
[0160]
score=α
·
score1+β
·
score2+γ
·
score3
ꢀꢀꢀ
(9)
[0161]
其中α、β、γ分别为三个网络得分占整体得分的权重。
[0162]
一种基于深度元学习和生成对抗网络的字体修复系统,其特征在于,所述系统包括:
[0163]
数据获取模块,用于获取已有的书法字体数据集dataset-1以及字体的笔画和结构数据;
[0164]
数据处理模块,用于将数据针对不同任务进行不同方式的处理;
[0165]
font-meta模块,用于对残缺的书法字体进行补全;
[0166]
字体审核模块,用于寻找最好的补全字体;
[0167]
字体输出模块,用于输出修复字体。
[0168]
综上所述,本专利提出了基于深度元学习和生成对抗网络的字体修复方法及系统,基于深度元学习和生成对抗网络的字体修复方法及系统。利用现有的书法字体数据集进行元训练数据集s1,通过对现有字体库中的字体笔画、字体结构和字体内容等特征进行学习以及学习缺失笔画的字体补全过程,得到各字体不同维度特征的先验知识以及元模型font-meta和字体结构审核模型fsr-net。然后将待修复的数据进行处理后得到数据集s2,放入font-meta 中进行该种类型的书法字体笔画,结构,内容,风格的学习,并通过将font-meta的字体补全网络fdr-net修复的字体放入循环生成对抗网络中进行风格再迁移,得到与原始字体风格一致的完整书法字体图片。
[0169]
本发明上述实施例提出的字体修复方法及系统,能够基于现有的数据样本学到汉字的字体笔画、结构和风格等特征,在对汉字字体缺失部位进行补全时比现有技术更加全面;本发明应用在书法字体修复领域中,能减少人工成本,提升字体修复的精度和完整程度。
[0170]
尽管已经示出和描述了本发明的实施例,本领域技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变形,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1