一种具有知识迁移判别能力的数据分类方法
1.本发明涉及图像、文本数据分类技术领域,尤其涉及一种具有知识迁移判别能力的数据分类方法。
背景技术:
2.近来,机器学习在自动驾驶、语音识别、计算机视觉、目标检测等领域取得很大成功,但是,对于某些真实场景,它仍然有一些限制,构建精确的机器学习模型需要大量不同类型的训练样本,然而在现实中,获取的数据通常是未分类的;
3.现有的分类模型如:softmax回归适用于多分类,具有应用简单、易于训练、结果直观的优点,因此,受到研究人员的更多关注,传统softmax采用交叉熵损失函数进行优化,但并不能保证得到优化后的特征分布,softmax分类器理想的应用场景是训练样本与测试样本具有相同的特征分布,然而,在许多情况下,收集满足要求的训练样本通常是耗时的、昂贵的,这使得softmax模型的分类结果并不令人满意;
4.针对训练样本与测试样本不满足相同分布的情况,训练迁移学习是解决上述问题的一种比较有效的方法,然而,现有的迁移学习方法只关注源域(训练样本)和目标域(测试样本)的整体分布信息和全局结构信息,忽略单个样本对全局度量贡献的差异性,从而影响了分类器性能;
5.鉴于以上我们提供一种具有知识迁移判别能力的数据分类方法用于解决以上问题。
技术实现要素:
6.针对上述情况,本发明提供一种具有知识迁移判别能力的数据分类方法,本方案通过设计权重系数以及加权wmmd,提升了系统跨越知识迁移能力,为了区分不同类型数据,引入lda,对源域样本和目标域样本进行降维,使降维后的数据具有类内方差最小,类间方差最大,相对于已有的分类模型,提高了分类精度。
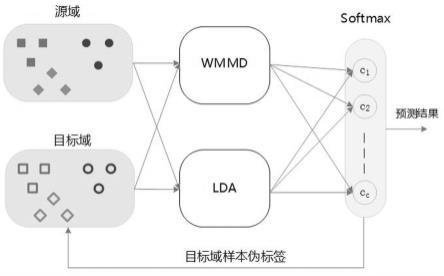
7.一种具有知识迁移判别能力的数据分类方法,其特征在于,包括源域、目标域、特征空间、softmax分类器、预测结果,其过程包括以下步骤:
8.s1:源域样本和目标域样本经特征映射后,在特征空间中可找到它们近似的相同分布;
9.s2:在特征空间中进行wmmd和linear discriminant analysis(lda)运算,wmmd单元计算源域样本与目标域样本间边沿分布和条件分布差异,尽量消除源域与目标域之间的差异,linear discriminant analysis(lda)单元,目的是尽量缩小同类样本之间距离,最大化不同样本之间的距离;
10.s3:softmax分类器分别计算目标域中每个样本所对应的每个标签下的概率,选择概率值最大值对应的标签,即为该样本的标签,完成样本分类;
11.s4:预测结果保存目标域样本分类结果,即每个样本对应的标签。
12.上述技术方案有益效果在于:
13.(1)在源域(训练样本)与目标域(测试样本)数据分布不同的情况下,把在源域中学习到的分类模型,利用知识迁移方法应用于目标域分类任务;
14.(2)本方案通过设计加权mmd(称为wmmd,mmd是一种度量方法,度量源域样本与目标域样本不同类型数据之间的距离,wmmd在mmd的基础上考虑了不同类型样本在度量时贡献不同,通过度量时增加权重系数w实现),提升了系统跨越知识迁移能力,从而实现了把在源域中学习到的分类模型,利用知识迁移方法应用于目标域分类任务,相对于已有的分类模型,提高了分类精度;
15.(3)为了区分不同类型数据,引入lda,对源域样本和目标域样本进行降维,使降维后的数据具有类内方差最小,类间方差最大,使得该分类模型的分类性能得到进一步提升。
附图说明
16.图1为本发明softmax-lwmmd系统框图;
17.图2为本发明wmmd内部结构框图;
18.图3为本发明linear discriminant analysis(lda)计算原理示意图;
19.图4为本发明参数α、β取值与准确率的关系示意图;
20.图5为本发明参数λ、μ取值与准确率的关系示意图;
21.图6为本发明迭代次数与准确率的关系示意图。
具体实施方式
22.有关本发明的前述及其他技术内容、特点与功效,在以下配合参考附图1至6对实施例的详细说明中,可清楚的呈现,以下实施例中所提到的结构内容,均是以说明书附图为参考。
23.实施例1,本实施例提供一种具有知识迁移判别能力的数据分类方法,其特征在于,包括源域(源域由两部分组成,样本x和样本标签y
x
,源域用表示)、目标域(目标域中只有样本,用表示)、特征空间、softmax分类器、预测结果;
24.其分类过程包括以下步骤:
25.s1:源域样本和目标域样本经特征映射后,在特征空间中可找到它们近似的相同分布;
26.s2:在特征空间中进行wmmd和linear discriminant analysis(lda)运算,wmmd单元计算源域样本与目标域样本间边沿分布和条件分布差异,尽量消除源域与目标域之间的差异;
27.如附图3所示,为lda计算原理示意图,linear discriminant analysis(lda)单元,目的是尽量缩小同类样本之间距离(使得同类数据尽可能的靠近),最大化不同样本之间的距离(使得不同类的数据尽可能的远离);
28.附图1中,伪标签表示在训练过程中,配给目标样本的标签,不一定是真的标签,会在每次训练后更新伪标签,训练结束的条件是:有伪标签不再更新或者达到最大训练次数(tmax);
29.s3:softmax分类器分别计算目标域中每个样本所对应的每个标签下的概率,选择
概率值最大值对应的标签,即为该样本的标签,完成样本分类;
30.s4:预测结果保存目标域样本分类结果,即每个样本对应的标签。
31.一、为了实施上述分类步骤过程,首先构造系统目标函数:(1)
32.其中,
[0033][0034][0035][0036][0037][0038]
上述函数中θ是系统所有项参数,即系统需要通过训练确定的参数;
[0039]
j1(θ)是softmax回归的代价函数;
[0040]
j2(θ)是基于wmmd计算结果;
[0041]
j3(θ)用于通过条件分布和边沿分布减少softmax回归概率输出层中,域间的分布差异;
[0042]
j4(θ)是模型参数的稀疏控制项,防止模型出现过拟合现象;
[0043]
j5(θ)是系统中lda计算项;
[0044]
α,β,λ,μ分别是j2(θ),j3(θ),j4(θ),j5(θ)的平衡参数;
[0045]
l0和w0分别是边沿分布矩阵和边沿分布权重系数矩阵;
[0046]
lc和wc分别是条件分布矩阵和条件分布权重系数矩阵;
[0047]
gb是类间矩阵,gu是类内矩阵,gv是总散度矩阵,gv=gb+gu。
[0048]
l0矩阵由下式计算得:
[0049][0050]
其中,是源域,是目标域,x是相应域中的样本,n是相应域中的样本数量;
[0051]
权重系数w0定义如下:
[0052]
[0053]
其中,是第i个样本的权重系数,是源域或目标域样本的均值;
[0054]
lc矩阵根据下式计算:
[0055][0056]
其中,是属于类c的源域样本集,是源域样本xi的正确标签,相应的,是属于类c的目标域样本集;
[0057]
类权重系数wc的定义如下:
[0058][0059]
其中,是第i个属于类c的样本的权重系数,是源域或目标域属于类c的样本的均值。
[0060]
上述公式(3)的得出过程如下:
[0061]
wmmd边沿分布计算和条件分布计算公式过程如下:
[0062]
边沿分布距离计算如下:
[0063][0064]
其中矩阵l0,及权重系数w0计算公式为公式(7)和公式(8),我们的创新之处是在公式(10-1)中增加了ωixi和ωjxj项,分别表示源域和目标域;
[0065]
条件分布距离目标函数表达式加入权重系数后如下:
[0066][0067]
其中矩阵lc,及权重系数wc计算公式为公式(9)和公式(10),我们的创新之处是在公式(10-2)中增加了ωix
ic
和ωjx
jc
项,分别表示源域和目标域中不同类型数据;
[0068]
基于公式(10-1)和公式(10-2)最终得出基于wmmd计算结构的公式,如下:
[0069][0070]
如附图2所示,为wmmd内部结构图,传统的mmd(maximum meandivergence)在计算边缘分布和条件分布时只考虑了样本的整体信息,未考虑单个样本信息对数据分布的影响(没有考虑单个样本在迁移中的贡献),mmd只考虑了l矩阵,wmmd不仅考虑样本的整体信息,同时考虑了单个样本的贡献,针对每个样本增加权重系数w(为区分每个样本贡献度大小,给每个样本增加权重系数,贡献多的样本所占的权重大,反之,贡献小的样本所占权重小),从而使得分类精度更高。
[0071]
类间矩阵计算如下:
[0072][0073]
这里表示所有样本的均值;
[0074]
类内矩阵计算如下:
[0075][0076]
这里表示第i类样本的均值,表示总样本中是i类样本的数据子集;
[0077]
由式(11)和式(12)得总散度矩阵:
[0078][0079]
二、将上述系统目标函数进行优化
[0080]
最小化目标函数j(θ)得到参数θ的最优解,由于方程(1)没有封闭解,利用梯度下降法可求得其解,目标函数j(θ)针对属于第j类参数θ求偏导,结果为:
[0081][0082]
其中,
[0083][0084]
[0085][0086][0087][0088]
模型参数由下式更新,
[0089][0090]
取得模型参数θ后,对目标域进行分类,每一个测试样本x属于类别j的概率为:
[0091][0092]
通过式(21)计算出x属于所有类别的概率,取最大概率所对应的类别即为x的分类类别。
[0093]
三、以下演示上述系统运算过程:
[0094]
首先输入:源域样本目标域样本参数α,β,λ,μ,最大迭代次数t
max
.
[0095]
1.模型参数θ初始化。
[0096]
2.根据公式(7)构造边沿分布差异矩阵l0,设l0=0,同时,根据公式(8)构造边沿分布权重矩阵w0,设w0=0。
[0097]
3.根据公式(11)、(12)、(13)分别计算gb、gu和gv矩阵。
[0098]
4.根据公式(1)计算目标函数j(θ),然后根据公式(14)求偏导的值。
[0099]
5.利用梯度下降法优化得参数θ值。
[0100]
6.参数θ值带入softmax回归模型分类目标样本并预测其标签
[0101]
7.根据公式(9)计算条件分布差异矩阵lc,同时,根据公式(10)计算条件分布权重矩阵wc。
[0102]
8.跳转到3继续执行直到预测标签不再变化,或达到最大迭代次数t
max
。
[0103]
9.程序终止(输出:模型参数θ和目标域样本分类预测标签)。
[0104]
四、以下通过具体实验数据验证本方案的分类性能
[0105]
1、数据集的描述
[0106]
实验在五个数据集上完成,数据集分为三组,分别是两组图像数据集:office-31+caltech-256和msrc+voc2007,一组文本数据集:reuters-21578,表2给出图像数据集基本信息。
[0107][0108]
表2 图像数据集信息
[0109]
office-31+caltech-256:office-31是一个常用的跨域图像识别数据集,有4,652幅图像和31个类别组成,其图像来自三个不同的领域,分别是amazon(简称a,图片下载于amazon网站)、webcam(简称w,低分辨率图像来自网络摄像头拍摄)、dslr(简称d,高分辨率图像来自数码单反像机拍摄的);
[0110]
caltech-256也是一个标准的图像识别数据集,包含256个类的30607张图像,office-31+caltech-256联合数据集,包含4个域,a、w、d和c(caltech-256),实验时任意选取两个不同的域组成源域和目标域,可构建12组不同的跨域任务,分别是(1)a
→
c、(2)a
→
d、(3)a
→
w、
…
、(11)w
→
c、(12)w
→
d;
[0111]
msrc+voc2007:msrc数据集含有18个类别,共计4323张图像,voc2007数据集含有20个类别,共计5011张图像,分别从msrc中选取1296张图像、voc2007中选择1530张图像组成两组实验数据,一组msrc作为源数据,voc2007作为目标数据,记作msrc
→
voc,另一组两者互换源域和目标域,记作voc
→
msrc,选取的图像转换为256像素的黑白图像,特征维度为240维;
[0112]
reuters-21578:是一个文本分类常用数据集,包含5个顶级类别,分别是orgs,people,places,topics,exchanges,我们选取3个大类orgs、people和places,构造6组跨领域文本分类任务,分别是orgs vs people、people vs orgs、orgs vs places、places vs orgs、people vs places和places vs people,每组数据第一个类是源数据,第二个类是目标数据;
[0113]
2、分类模型的选取
[0114]
我们选取有代表性的分类模型在上述三组数据集上进行比较实验,以评价其分类性能;
[0115]
选取的模型分为两大类,一类是标准的分类器,包括svm和softmaxregression,另一类是迁移学习分类器,包括tca+svm(tca1)、tca+softmaxregression(tca2)、jda+svm(jda1)、jda+softmax regression(jda2)、utsr及本方案提出的softmax-wmmd、softmax-lwmmd;
[0116]
对比实验中,所有算法的参数都设置为默认值或原文中提到的推荐值,典型超参
数设置,svm惩罚项参数c取值{0.1,0.5,1,5,10,50,100},softmax回归中稀疏约束项平衡参数λ取值[10-4
,10-3
],特征迁移算法中,特征子空间的维度k取值[20,100],参照附图4、5、6所示,为softmax-lwmmd模型参数α、β、λ、μ和最大迭代次数与准确率关系示意图;
[0117]
首先进行灵敏度实验和分析,验证softmax-lwmmd模型在平衡参数α、β、λ、μ和最大迭代次数下都能实现最佳性能,在三组数据集中选取4组分类任务分别是(5)c
→
d、(7)d
→
a、msrc
→
voc和people vs place,结果如附图4、5、6所示:
[0118]
(1)图4中,在任务people vs place上,α取值小于等于1时,模型分类精度始终保持最佳,当α取值小于1时,wmmd项所占比重增加,模型分类精度下降,在另外3个任务上,α取值在特定区间上,模型分类性能达到最优。
[0119]
(2)当β取值较小时,模型在4个任务上分类精度变化较小,但未达到最佳,β取得合适值时,模型分类精度达到最佳,随着β增加,当达到临界点后,模型性能下降较快,说明jda引入项所占比重需在合理范围,如图4所示。
[0120]
(3)图5中,参数λ、μ与β相似,softmax正则项和lda项所占比重太大或太小都会影响模型分类精度。
[0121]
(4)随着迭代次数的增加,在分类任务中,模型精度会不断提高。当迭代次数超过14次后,模型性能达到最佳并趋于稳定,体现其具有较好的收敛性。如图6所示。
[0122]
综上所述,选取最大迭代次数t
max
=50,其他参数α,β,λ,μ根据分类数据集的不同,所选取的值也不同,在实验过程中根据不同分类的数据集而相应的选择参数α,β,λ,μ的取值情况。
[0123]
3、实验结果分析
[0124]
[0125][0126]
表3 不同分类算法在图像数据集上的准确率
[0127][0128]
表4 不同分类算法在文本数据集上的准确率根据实验结果,我们可以得到以下3点结论:
[0129]
首先,我们观察到,在三个实验数据集上,softmax-lwmmd模型相比于其他分类模型取得更好的效果,softmax-lwmmd平均分类精度在两组图像数据集上分别为53.24%和51.11%、文本数据集上为76.11%,相较于参考模型utsr分别提高了1.7%、1.42%和
2.28%,这验证了softmax-lwmmd能够为跨域分类任务构建更有效的表现;
[0130]
其次,softmax-lwmmd模型分类效果优于softmax-wmmd模型,这是因为,softmax-lwmmd模型增加了lda算法,lda降维后的数据具有类内方差最小,类间方差最大,进一步提高了softmax-lwmmd模型分类性能;
[0131]
本方案应用于图像分类任务和文本分类任务中针对图像数据和文本数据的分类:
[0132]
在图像分类任务中,选取数据集w
→
d,参数设置为α=10-2
,β=10-3
,λ=10-3
,μ=10-6
,迭代次数大于等于50时,系统分类精度大于等于88.55;
[0133]
在文本分类任务中,选取数据集people vs orgs,参数设置为α=2,β=3,λ=3,μ=1,迭代次数大于等于50时,系统分类精度大于等于85.42;
[0134]
使得本方案在应用于图像分类任务中相比于其他方法具有较高的分类精度。
[0135]
上面只是为了说明本发明,应该理解为本发明并不局限于以上实施例,符合本发明思想的各种变通形式均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1