一种基于电力大数据平台的数字审计疑点提取方法及系统与流程
1.本发明属于电网信息资源与管理方法技术领域,具体涉及一种基于电力大数据平台的数字审计疑点提取方法及系统。
背景技术:
2.数字化审计指的是运用大数据手段提高审计效率和审计准确性的技术,对于项目众多、涉及系统跨度大的审计过程具有较强优势。审计最重要的目的是在于查找可疑项目,挖掘项目实施背后潜在问题,然而传统模式下审计项目的现场实施管理存在审计质量难以把控、审计情况反馈滞后等问题,同时电网公司项目众多、项目背后联系错综复杂,人工审计效率低且难以有效形成强关联,项目实施过程中的疑点难以发掘。
3.而随着国网电力公司的管理和经营信息化程度越来越高,电力大数据平台的形成,一定程度上解决了该问题;但仍多采用人工审计为主、信息化手段为辅的审计方式,即通过人为经验确定常见项目审计疑点、通过信息化技术查找上述疑点是否规范,难以发掘出某些隐蔽风险和新型风险;与此同时,现有的信息化技术在进行数据挖掘过程中,各审计项目包括多个业务子系统,业务子系统产生的业务数据数量大、表项多、数据间相似度大、数据间相互管理,利用电力大数据平台进行审计工作时,采用apriori关联算法,大量扫描原始数据库,采用穷举方式各项集,且多次扫描不断产生海量子集,对设备内存具有较大考验,不适用于现有电力大数据平台。
技术实现要素:
4.本发明在于提供一种基于电力大数据平台的数字审计疑点提取方法,采用鲨鱼智能算法优化apriori关联规则,将apriori迭代寻找强关联频繁k-项集过程,转变为一个多维空间寻优过程,即通过迭代寻优解决了apriori穷举对内存的影响,使得其适用于现有电力大数据平台的内存。
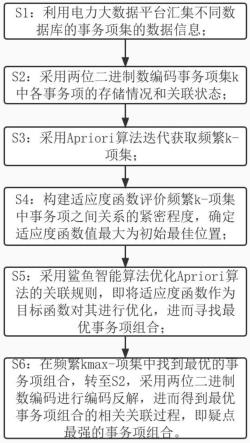
5.一种基于电力大数据平台的数字审计疑点提取方法,包括如下步骤:
6.s1:利用电力大数据平台汇集不同数据库的事务项集的数据信息;
7.s2:采用两位二进制数编码事务项集k中各事务项的存储情况和关联状态;
8.s3:采用apriori算法迭代获取频繁k-项集;
9.s4:构建适应度函数以评价频繁k-项集中事务项之间关系的紧密程度,确定适应度函数值最大即为初始最佳位置;
10.s5:采用鲨鱼智能算法优化apriori算法的关联规则,即将适应度函数作为目标函数对其进行优化,进而寻找最优事务项组合;
11.s51:设定频繁k-项集的项为m,对事务项组合的位置、寻优初始速度进行初始化;
12.s52:结合适应度函数,采用鲨鱼智能算法寻找得到频繁k-项集中的最优事务项组合,转至s3,直至找到频繁k-项集中的最优事务项组合;
13.s6:在频繁k
max-项集中找到最优的事务项组合,转至s2,采用两位二进制数编码进
行编码反解,进而得到最优事务项组合的相关关联过程,即疑点最强的事务项组合。
14.进一步的,所述s2中,两位二进制数包括:
15.第一位二进制数,所述第一位二进制数表示该事务项是否存在;其中,1表示存在,0 表示不存在;
16.第二位二进制数,所述第二位二进制数表示该事务项的关联状态;其中,1表示该事务项为规则前件,0表示该事务项为规则后件。
17.进一步的,所述s3中,采用apriori算法获取频繁k-项集的具体过程包括如下步骤:
18.s31:设定支持度阈值和置信度阈值;
19.s32:遍历频繁k-项集中事务项的数据信息,统计k个事务项的支持度,得到候选k-项集;
20.s33:计算k个事务项的支持度,剔除支持度不大于支持度阈值的事务项,得到频繁k
‑ꢀ
项集;
21.s34:转至s32,直至k=k
max
,没有新的频繁项集产生,即不存在支持度不大于支持度阈值的,迭代结束。
22.进一步的,所述s31中,支持度表示事务项集k中事务项x和事务项y出现的频繁程度,用于反映事务项间关联的普遍性,其计算表达式为:
23.support(x
→
y)=p(x∩y);
24.置信度表示事务项y在包含事务x中出现的频繁程度,用于反映事务项间关联的可靠性,其计算表达式为:
25.confidence(x
→
y)=p(x∩y)/p(x);
26.其中,当support(x
→
y)和confidence(x
→
y)均满足支持度阈值和置信度阈值,认为x
→ꢀ
y为强关联规则。
27.进一步的,所述s4中,适应度函数f(x
→
y)的计算表达式为:
28.f(x
→
y)=support(x
→
y)
·
confidence(x
→
y)
29.其中,support(x
→
y)为关联规则x
→
y的支持度,confidence(x
→
y)为关联规则x
→
y 的置信度。
30.进一步的,所述s51中,初始化的过程包括:
31.位置初始化,频繁k-项集中的事务项组合的初始位置为:
[0032][0033]
式中,m为频繁k-项集中的事务项集总数;
[0034]
其中,其为第i个频繁k-项集中的事务项组合的位置向量;n 为第i个事务项集中事务项的总数,为频繁k-项集中的事务项组合的初始位置;
[0035]
寻优速度初始化,系统初始化寻找频繁k-项集中的事务项组合的寻找速度矢量为:
[0036][0037]
其中,其为寻找频繁k-项集中的第i个事务项组合的速度
向量; n为第i个事务项集中事务项的总数,为寻找频繁k-项集中第j个事务项集中第i个事务项组合的速度。
[0038]
进一步的,所述s52中,鲨鱼智能优化算法寻找频繁k-项集中的最优事务项组合的过程包括:
[0039]
s521:采用鲨鱼智能优化算法对适应度函数极值点的事务项进行局部寻优,并对寻找到的新位置进行适应度函数值大小排序,保留前一半数据的位置为最佳位置;
[0040]
s522:当前后两次迭代间的适应度函数小于设定阈值时,采用混沌映射跳出局部最优,转至所述s3进行迭代,直至完成设定迭代次数,即k=k
max
。
[0041]
进一步的,所述s521中,采用鲨鱼智能算法进行寻优过程中,系统在寻找频繁k-项集中最优事务项组合过程中,寻找速度更新的计算表达式为:
[0042][0043]
式中,表示频繁k-项集中第j个事务项集中第 i个事务项组合的速度;f(x)为适应度函数;αk、γ1、γ2是均匀分布在[0,1]之间的随机数;
[0044]
其中,鲨鱼寻优过程中的运动方式包括:
[0045]
前进运动,模拟鲨鱼向适应度函数极值点的位置前进,即是系统向适应度函数极值点处的事务项组合的位置前进,其因前进运动产生的新位置y
ik+1
的计算表达式为:
[0046][0047]
式中,为第k次迭代过程中事务项组合物的位置,为第k次迭代过程中系统寻找事务项组合物的速度,δt为第k次迭代的时间;
[0048]
旋转搜索,用于避免前进运动搜寻到的适应度函数极值点位置局部最优,进而旋转搜索实现局部寻优,其在第k+1次迭代中因旋转搜索产生的新位置的计算表达式为:
[0049][0050]
式中,p=(1,2,...,p),p为位置搜索中每个阶段的事务项组合的数量,p点的位置搜索在y
ik+1
附近;γ3为均匀分布在[-1,1]之间的随机数;
[0051]
当系统在模拟鲨鱼进行旋转搜索过程中找到一个更优的点,会去掉该点,并继续搜索。
[0052]
进一步的,所述s522中,混沌映射是采用logstic混沌映射,通过产生新的随机解,进而跳出局部最优,其表达式为:
[0053]
x
n+1
=xn×
μ
×
(1-xn)
[0054]
其中:μ∈(0,4]。
[0055]
一种用于如上所述的一种基于电力大数据平台的数字审计疑点提取方法的系统,包括:
[0056]
数据模块,用于汇集电力大平台的数据信息,并进行两位二进制数编码;
[0057]
模型模块,用于获取频繁k-项集以及构建适应度函数;
[0058]
优化模块,用于鲨鱼智能算法优化适应度函数,获取最优事务项组合;
[0059]
输出模块,用于将获取最优事务项组合的编码进行反解码,输出最优事务项组合的相关关联过程,即疑点最强的事务项组合。
[0060]
本发明的有益效果为:
[0061]
本发明通过查找、挖掘各电力信息间的关联关系,找寻看似不相关的审计数据间的相关关系和异常,分析该异常出现的深层次原因,将正常关系的对应规则与其他相关数据比对,发现和分析审计疑点;采用鲨鱼智能算法优化apriori关联规则,将apriori迭代寻找强关联频繁k-项集过程,转变为一个多维空间寻优过程,即通过迭代寻优解决了apriori穷举对内存的影响;同时通过鲨鱼智能算法优化apriori算法适应度函数的计算,增强了模型的拟合能力,提高了查找最优事务项组合的精确度。
附图说明
[0062]
图1为本发明的流程示意图;
[0063]
图2为获取频繁k-项集的流程示意图;
[0064]
图3为鲨鱼智能优化算法寻找频繁k-项集中的最优事务项组合的流程示意图;
[0065]
图4为本发明系统的示意图。
具体实施方式
[0066]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0067]
需要说明的是,下述实施方案中所述实验方法,如无特殊说明,均为常规方法,所述试剂和材料,如无特殊说明,均可从商业途径获得;在本发明的描述中,术语“横向”、“纵向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,并不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
[0068]
此外,术语“水平”、“竖直”、“悬垂”等术语并不表示要求部件绝对水平或悬垂,而是可以稍微倾斜。如“水平”仅仅是指其方向相对“竖直”而言更加水平,并不是表示该结构一定要完全水平,而是可以稍微倾斜。
[0069]
在本技术的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本技术中的具体含义。
[0070]
图1所示的是一种基于电力大数据平台的数字审计疑点提取方法,包括如下步骤:
[0071]
s1:利用电力大数据平台汇集不同数据库的事务项集的数据信息;
[0072]
s2:采用两位二进制数编码事务项集k中各事务项的存储情况和关联状态;
[0073]
两位二进制数具体包括:
[0074]
第一位二进制数,第一位二进制数表示该事务项是否存在;其中,1表示存在,0表示不存在;
[0075]
第二位二进制数,第二位二进制数表示该事务项的关联状态;其中,1表示该事务项为规则前件,0表示该事务项为规则后件。
[0076]
s3:采用apriori算法迭代获取频繁k-项集,构建适应度函数以评价频繁k-项集中事务项之间关系的紧密程度,确定适应度函数值最大即为初始最佳位置;
[0077]
如图2所示,具体过程包括如下步骤:
[0078]
s31:设定支持度阈值和置信度阈值;
[0079]
s32:遍历频繁k-项集中事务项的数据信息,统计k个事务项的支持度,得到候选k-项集;
[0080]
s33:计算k个事务项的支持度,剔除支持度不大于支持度阈值的事务项,得到频繁k
‑ꢀ
项集;
[0081]
s34:转至s32,直至k=k
max
,没有新的频繁项集产生,即不存在支持度不大于支持度阈值的,迭代结束。
[0082]
其中,关联规则x
→
y的支持度表示事务项集k中事务项x和事务项y出现的频繁程度,用于反映事务项间关联的普遍性,其计算表达式为:
[0083]
support(x
→
y)=p(x∩y);
[0084]
关联规则x
→
y的置信度表示事务项y在包含事务x中出现的频繁程度,用于反映事务项间关联的可靠性,其计算表达式为:
[0085]
confidence(x
→
y)=p(x∩y)/p(x);
[0086]
当support(x
→
y)和confidence(x
→
y)均满足支持度阈值和置信度阈值,认为x
→
y为强关联规则。
[0087]
其中,频繁k-项集中各事务项的编码个数取决于频繁1-项集中剩余事务项个数,通过采用两位二进制数编码,频繁k-项集中各事务项的编码个数为频繁1-项集中剩余事务项个数的两倍。
[0088]
s4:构建适应度函数以评价频繁k-项集中每k个事务项之间关系的紧密程度,确定适应度函数值最大即为初始最佳位置;
[0089]
其中,适应度函数采用每k个事务项的置信度和支持度表示,其计算表达式为:
[0090]
f(x
→
y)=support(x
→
y)
·
confidence(x
→
y)
[0091]
其中,support(x
→
y)为关联规则x
→
y的支持度,confidence(x
→
y)为关联规则x
→
y 的置信度。
[0092]
s5:采用鲨鱼智能算法优化apriori算法的关联规则,即将适应度函数作为目标函数对其进行优化,进而寻找最优事务项组合;
[0093]
其中,鲨鱼智能算法是通过模拟鲨鱼觅食行为进行寻优;通过在搜索域内生成一组初始气味粒子模拟猎物;假设鲨鱼进行搜索时的初始位置为任意气味粒子的位置,气味粒子的浓度表示鲨鱼与猎物的距离,气味越浓则鲨鱼与猎物的距离越近,即通过适应度函数表示;鲨鱼优先靠近气味浓度较高的气味粒子,即寻优过程为向气味粒子浓度更高的气
味粒子移动的过程。
[0094]
s51:设定频繁k-项集的项为m,对事务项组合的位置、寻找最优事务项组合的初始速度进行初始化;
[0095]
在本实施例中,鲨鱼智能算法中的气味粒子即为频繁k-项集中的事务项组合,鲨鱼智能算法中的鲨鱼即为寻找频繁k-项集中的事务项组合的系统。
[0096]
位置初始化,频繁k-项集中的事务项组合的初始位置为:
[0097][0098]
式中,m为频繁k-项集中的事务项集总数;
[0099]
其中,其为第i个频繁k-项集中的事务项组合的位置向量;n 为第i个事务项集中事务项的总数,为频繁k-项集中的事务项组合的初始位置;
[0100]
寻优速度初始化,系统初始化寻找频繁k-项集中的事务项组合的寻找速度矢量为:
[0101][0102]
其中,其为寻找频繁k-项集中的第i个事务项组合的速度向量; n为第i个事务项集中事务项的总数,为寻找频繁k-项集中第j个事务项集中第i个事务项组合的速度。
[0103]
以频繁1-项集为例,即初始化过程包括:
[0104]
位置初始化,频繁1-项集中的事务项组合的初始位置为:
[0105][0106]
式中,m为频繁1-项集中的事务项集总数;
[0107]
其中,其为第i个频繁1-项集中的事务项组合的位置向量;n 为第i个事务项集中事务项的总数,为频繁1-项集中的事务项组合的初始位置;
[0108]
寻优速度初始化,系统初始化寻找频繁1-项集中的事务项组合的寻找速度矢量为:
[0109][0110]
其中,其为寻找频繁1-项集中的第i个事务项组合的速度向量; n为第i个事务项集中事务项的总数,为寻找频繁1-项集中第j个事务项集中第i个事务项组合的速度。
[0111]
s52:采用鲨鱼智能算法寻找得到频繁k-项集中的最优事务项组合,转至s3;其具体步骤如图3所示;
[0112]
s521:采用鲨鱼智能优化算法对适应度函数极值点的事务项进行局部寻优,并对寻找到的新位置进行适应度函数值大小排序,保留前一半数据的位置为最佳位置;
[0113]
采用鲨鱼智能算法进行寻优过程中,当鲨鱼跟踪气味时,速度会随气味浓度的增加而增大,获取鲨鱼在每个维度的速度,即系统在寻找频繁k-项集中最优事务项组合过程
中,寻找速度更新的计算表达式为:
[0114][0115]
式中,表示频繁k-项集中第j个事务项集中第i个事务项组合的速度;f(x)为适应度函数;αk、γ1、γ2是均匀分布在[0,1]之间的随机数。
[0116]
其中,鲨鱼寻优过程中的运动方式包括:
[0117]
前进运动,使得鲨鱼向适应度函数极值点的位置前进,即是系统向适应度函数极值点处的事务项组合的位置前进,其因前进运动产生的新位置y
ik+1
的计算表达式为:
[0118][0119]
式中,为第k次迭代过程中事务项组合物的位置,为第k次迭代过程中系统寻找事务项组合物的速度,δt为第k次迭代的时间;
[0120]
旋转搜索,用于避免前进运动搜寻到的适应度函数极值点位置局部最优,进而旋转搜索实现局部寻优,其在第k+1次迭代中因旋转搜索产生的新位置的计算表达式为:
[0121][0122]
式中,p=(1,2,...,p),p为位置搜索中每个阶段的事务项组合的数量,p点的位置搜索在y
ik+1
附近;γ3为均匀分布在[-1,1]之间的随机数。
[0123]
当系统在模拟鲨鱼进行旋转搜索过程中找到一个气味更强的点,会去掉该点,并继续搜索。
[0124]
考虑适应度函数应最大化,保留当前在频繁k-项集中找到的所有事务项组合的前 50%,各事务项组合所对应的位置作为下一搜索过程中的起始点,前进运动和旋转搜索的过程一直循环,直至迭代次数达到最大迭代次数,即k=k
max
。
[0125]
s522:为了避免采用鲨鱼智能算法,即系统在寻找最优事务项组合的过程中陷入局部最优解,而难以收敛,当前后两次迭代间的适应度函数值小于设定阈值时,采用混沌映射,产生新的随机解以跳出局部最优,转至s3进行迭代,进行下一频繁项集的搜索,直至完成设定迭代次数,即k=k
max
。
[0126]
其中,混沌映射采用logstic混沌映射,其的表达式为:
[0127]
x
k+1
=xk×
μ
×
(1-xk)
[0128]
其中,μ∈(0,4]。
[0129]
s6:在频繁k
max-项集中找到最优的事务项组合,转至s2,采用两位二进制数编码进行编码反解,进而得到最优事务项组合的相关关联过程,即疑点最强的事务项组合。
[0130]
如图4所示,一种用于如上所述的一种基于电力大数据平台的数字审计疑点提取方法的系统,包括:
[0131]
数据模块,用于汇集电力大平台的数据信息,并进行两位二进制数编码;
[0132]
模型模块,用于获取频繁k-项集以及构建适应度函数;
[0133]
优化模块,用于鲨鱼智能算法优化适应度函数,获取最优事务项组合;
[0134]
输出模块,用于将获取最优事务项组合的编码进行反解码,输出最优事务项组合的相关关联过程,即疑点最强的事务项组合。
[0135]
实施例2
[0136]
在本实施例中,采用数字审计疑点提取方法的过程包括:
[0137]
t1:通过电力大数据平台汇集事件名字、负责人和厂家的信息,如表1所示:
[0138]
表1电力大数据平台部分信息
[0139]
事件id事件名字负责人厂家1维保1甲厂家12维保2乙厂家23维保3丙厂家34维保4丁厂家45维保5张三厂家46维保6甲厂家47维保2乙厂家48维保1甲厂家49维保2乙厂家410维保1乙厂家411维保2乙厂家412维保1张三厂家413维保6甲厂家3
[0140]
其中,事件名字中的维保1~维保6分别采用t1~t6表示,负责人中的甲、乙、丙、丁、张三分别采用f1~f5表示,厂家中的厂家1~厂家4分别采用d1~d4表示。
[0141]
t2:即表1中各事务项的第一位二进制数如表2所示:
[0142]
表2第一位二进制数示表
[0143]
idt1t2t3t4tst6f1f2f3f4f5d1d2d3d411000001000010002010000010000100300100000000001040001000001000015000010000010001600000110000000170100000100000018100000100000001901000001000000110100000010000001110100000100000011210000000001000113000001100000010
[0144]
对表1中各事务项进行两位二进制数编码,如:
[0145]
事件名字中维保1即t1的两位二进制编码数为11,表示该事务项存在且为规则前件;
[0146]
负责人中的甲即f1的两位二进制编码数为10,表示该事务项存在且为规则后件;
[0147]
厂家中的厂家1即d1的两位二进制编码数为01,表示该事务项不存在。
[0148]
即111001编码表示t1→
f1关联。
[0149]
以此类推,对各事务项进行两位二进制数编码。
[0150]
t3:采用apriori算法获取频繁1-项集,
[0151]
设定支持度阈值为1/13,剔除支持度不大于支持度阈值的事务项,得到频繁1-项集;
[0152]
其中,事务项t3、事务项t4、事务项t5、事务项f3、事务项f4、事务项d1、事务项d2的支持度不大于支持度阈值,进行剔除;
[0153]
其中,频繁1-项集中含有:事务项t1、事务项t2、事务项t6、事务项f1、事务项f2、事务项f5、事务项d3、事务项d4;即如事务项t1的编码为[1101010101010101];
[0154]
此时,事务项的维度从15
×
2=30减小为8
×
2=16。
[0155]
t4:构建适应度函数,即:
[0156]
f(x)=support(x)
·
confidence(x)
[0157]
对频繁1-项集中的各事务项进行计算,得到各事务项的适应度值。
[0158]
t5:采用鲨鱼算法在频繁1-项集中进行寻找最优事务项;其中设定阈值为10-3
;将适应度值依照大小排序,保留适应度值位于前一半的事务项进行迭代;直至在频繁3-项集中找到最优事务项组合,即得到最优解为[0111011001010110];
[0159]
其中,最优解[0111011001010110]中各编码含义依次为:01表示事务项t1不存在;11表示事务项t2存在且为规则前项件;01表示事务项t6不存在;10表示事务项f1存在且为规则后件;01表示事务项f2不存在;01表示事务项d3不存在;10表示事务项d4存在且为规则后件。
[0160]
t6:对最优解进行反解,得到事务项t2、事务项f2、事务项d4强关联,即维保2-人员乙-厂家4强关联。
[0161]
因此,在后续审计工作过程中,可对维保2-人员乙-厂家4的相关审计流程进行加强管理和审计。
[0162]
需要说明的是,本发明中支持度阈值、置信度阈值、设定阈值的值的选取依照实际情况进行选择。
[0163]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1