一种目标检测交叉数据集的混合训练方法与流程
1.本发明涉及数据集训练技术领域,具体涉及一种目标检测交叉数据集的混合训练方法。
背景技术:
2.在目标检测任务中,已经在数据集a中训练完成了检测模型,需要增加新的类别检测,现有的做法一般有4种分别为,1、直接混合a、b数据集进行训练,会导致a数据集中b的类别没有标注,同时b数据集中a的类别没有标注,直接混合训练会降低模型的精度;2、对a、b数据集进行交叉标注,对a数据集标注所有b数据集中的类别,同时对数据集b标注所有a中的类别。该方法需要进行大量的数据标注工作;3、对a、b数据集分别训练模型,训练好的模型记为ma、mb,使用ma模型对数据集b推理生成a类别的标签,使用mb模型对数据集a推理生成b类别的标签,该方法依赖ma、mb模型的精度,生成的标签会有大量的错误标签和漏检,实际应用效果不佳;4、对于数据集a中的每一个样本,计算分类损失时,添加一个mask屏蔽b类别的损失,对于数据集b中的每一个样本,计算分类损失时,添加一个mask屏蔽a类别的损失,该方法将a、b数据集计算分类损失时相互进行屏蔽,没有考虑b数据集中潜在的a类负样本和a数据集中潜在的b类负样本,导致对最终模型的精度提升有限。
技术实现要素:
3.本发明的目的在于,提供一种目标检测交叉数据集的混合训练方法,在目标检测任务训练中,针对已有的数据已经训练好了一个模型,需要增加新类别的数据集训练时,能够直接混合多个数据集,而不需要对混合后的数据集进行交叉标注,也能达到较高的模型精度,可以大大节省数据标注的时间和成本。
4.为解决上述技术问题,本发明采用如下的技术方案:一种目标检测交叉数据集的混合训练方法,包括以下步骤:
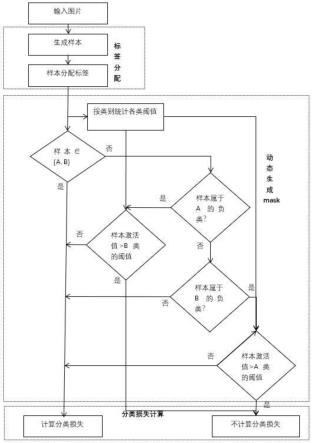
5.步骤1、样本标签分配:输入的图片经过常规方法处理后生成特征图featuremap,特征图featuremap上的点即为样本,样本在经过匹配之后,分配样本标签为正样本或负样本;
6.步骤2、动态生成mask矩阵:根据特征图featuremap动态生成mask矩阵,对特征图featuremap的样本分别进行阀值计算,同时判断其中样本标签,将标签为正样本的进行分类损失计算并给mask矩阵赋值;标签为负样本的需要根据样本阀值判断是否进行分类损失计算并给mask矩阵赋值;
7.步骤3、分类损失计算:用常规方法进行分类损失计算,决定分类loss是否继续参与训练。
8.前述步骤1中输入的图片经过骨干网络和特征金字塔网络后生成特征图featuremap,特征图featuremap的每一个点对应一个预先定义尺寸的样本,一个样本对应于输入图片上的一个矩形区域,特征图featuremap上每个样本的激活值代表该样本属于对
应类别的概率,样本经过匹配之后得出正样本和负样本;样本的匹配过程为:每个样本通过最大iou或者最近中心点的距离与真实的gt进行匹配,样本与gt匹配成功后被分配到该gt对应的类别标签,对于匹配成功的样本称之为正样本,未匹配任何gt的样本称之为负样本。
9.前述样本类别标签具体可以为:设a数据集中包含的类别数为c1,类别标签为{1,...,c1},b数据集中包含的类别数为c2,类别标签为{c1+1,...,c1+c2},数据集a的负样本标签为c1+c2+1,数据集b的负样本标签为c1+c2+2。
10.前述步骤2中根据特征图featuremap生成的样本标签,动态的生成mask矩阵:设一张图片的特征图featuremap生成的样本数为n,a和b数据集的总类别数为c1+c2,则特征图featuremap包含c1+c2个通道,每个通道表示在该位置存在对应类别的概率,全部激活值输出为n*(c1+c2),同时动态的生成n*(c1+c2)的一个mask矩阵,样本和mask矩阵一一对应,mask矩阵中满足条件的置1,不满足条件的置0,将mask乘到最后的分类loss中,动态的决定是否忽略某个样本的某个类别的loss。
11.前述mask矩阵中置为1或0的判断过程为:特征图featuremap的每一个样本,判断是否为正样本,如果是正样本则将mask中对应的第i行置1,对于i∈[0,n),mask[i,:]=1,如果不是正样本,则判断样本的标签是c1+c2+1或c1+c2+2,若样本标签为c1+c2+1,则循环判断样本的激活值是否大于b数据集中每一类的最优阈值t,大于最优阈值t,将样本对应的类别mask位置置0,对于样本编号为i,类别为ci,那么mask[i,ci]=0,不大于最优阈值t则将样本对应的类别mask位置置1,对于样本编号为i,类别为ci,那么mask[i,ci]=1;若样本标签为c1+c2+2,则循环判断样本的激活值是否大于a数据集中每一类的最优阈值t,大于最优阈值t,将样本对应的类别mask位置置0,对于样本编号为i,类别为ci,那么mask[i,ci]=0,不大于最优阈值t则将样本对应的类别mask位置置1,对于样本编号为i,类别为ci,那么mask[i,ci]=1。
[0012]
前述最优阈值t的选取过程:在一种实现中,可以将阈值区间从0-1均匀分成k个区间,设置参数k=100,则每个区间的分割为{0.01,0.02,.....,0.99,1},正负样本分别统计,记为p_bin和n_bin,p_bin和n_bin的维度为(c1+c2)*100,每一个类别单独统计激活值落在bin区间的总数,对于正样本的样本激活值,对应类别的p_bin的计数加一,样本的类别为i,激活值为j,那么p_bin[i,j]+=1,对于负样本的样本激活值,对应类别的n_bin的计数加一,样本的类别为i,激活值为j,那么n_bin[i,j]+=1。训练完一轮迭代后,可以统计得到训练集中所有类别的正负样本在100个不同的bin的计数,对正负样本的计数bin计算f1分数,取f1分数最高的bin值作为动态mask的生成阈值t;
[0013]
f1分数的计算公式(1)为:
[0014][0015]
计算公式(1)中precision的计算公式(2)为
[0016]
计算公式(1)中recall的计算公式(3)为
[0017]
计算公式(2)和计算公式(3)中:tp表示预测为正样本,标签也是正样本,fp表示预测为正样本,标签是负样本,fn表示预测为负样本,标签是正样本;对于一个epoch中统计得
到的p_bin和n_bin,那么对于类别为ci的第i个bin,其tp为fp为fn为将tp、fp、fn带入公式(1)、(2)、(3)中可以得到每个类别在每个bin下的f1分数,对于每一个类别取f1分数最大值对应的bin值作为该类的mask阈值,记为最优阈值t,维度为(c1+c2)。
[0018]
前述步骤3分类损失计算过程:目标检测的分类损失可以用交叉熵或focalloss,直接将mask矩阵和分类loss相乘,即可决定分类loss是否继续参与训练;
[0019]
对于交叉熵或focalloss损失,所有样本的损失可以表述为如下表达式(4):
[0020]
l={l1,l2,...,ln}
t
[0021]
表达式(4)中l的维度为n*(c1+c2),n为样本总数,每一个样本的损失ln:
[0022]
交叉熵ln的计算公式(5)如下:
[0023]
ln=-y
n log(xn)-(1-yn)log(1-xn)
[0024]
focalloss中ln的计算公式(6)如下:
[0025]
ln=-α(1-xn)
βyn log(xn)-(1-α)(xn)
β
(1-yn)log(1-xn)
[0026]
计算公式(5)和计算公式(6)中yn为每个样本的标签,维度为(c1+c2),xn为每个样本的激活值,维度为(c1+c2);公式(6)中的α、β为超参数,一般设置为0.25和2;
[0027]
对于交叉熵或focalloss修改后的l_mask形式如下式(7):
[0028]
l_mask=l*mask={l1,l2,...,ln}
t
*mask。
[0029]
与现有技术相比,本发明高明的地方在于,目标检测任务训练中,能够动态生成mask矩阵,通过本发明中算法选取mask矩阵中的最优阈值,以最优阀值为依据给mask矩阵赋值,同时可以决定哪些分类loss需要损失计算,最后对这些分类loss进行分类损失计算,并判断是否需要继续训练;进而能够直接混合多个数据集,而不需要对混合后的数据集进行交叉标注,也能达到较高的模型精度,可以大大节省数据标注的时间和成本。
附图说明
[0030]
图1是本发明的整体流程框图。
[0031]
下面结合附图和具体实施方式对本发明作进一步的说明。
具体实施方式
[0032]
本发明的实施例1:一种目标检测交叉数据集的混合训练方法,包括以下步骤:
[0033]
步骤1、样本标签分配:输入的图片经过常规方法处理后生成特征图featuremap,特征图featuremap上的点即为样本,样本在经过匹配之后,分配样本标签为正样本或负样本;
[0034]
步骤2、动态生成mask矩阵:根据特征图featuremap动态生成mask矩阵,对特征图featuremap的样本分别进行阀值计算,同时判断其中样本标签,将标签为正样本的进行分类损失计算并给mask矩阵赋值;标签为负样本的需要根据样本阀值判断是否进行分类损失计算并给mask矩阵赋值;
[0035]
步骤3、分类损失计算:用常规方法进行分类损失计算,决定分类loss是否继续参与训练。
[0036]
本发明的实施例2:一种目标检测交叉数据集的混合训练方法,包括以下步骤:
[0037]
步骤1、样本标签分配:输入的图片经过骨干网络和特征金字塔网络后生成特征图featuremap,特征图featuremap的每一个点对应一个预先定义尺寸的样本,一个样本对应于输入图片上的一个矩形区域,特征图featuremap上每个样本的激活值代表该样本属于对应类别的概率,样本经过匹配之后得出正样本和负样本;样本的匹配过程为:每个样本通过最大iou或者最近中心点的距离与真实的gt进行匹配,样本与gt匹配成功后被分配到该gt对应的类别标签,对于匹配成功的样本称之为正样本,未匹配任何gt的样本称之为负样本;
[0038]
样本类别标签具体可以为:设a数据集中包含的类别数为c1,类别标签为{1,...,c1},b数据集中包含的类别数为c2,类别标签为{c1+1,...,c1+c2},数据集a的负样本标签为c1+c2+1,数据集b的负样本标签为c1+c2+2;
[0039]
步骤2、动态生成mask矩阵:根据特征图featuremap动态生成mask矩阵,对特征图featuremap的样本分别进行阀值计算,同时判断其中样本标签,将标签为正样本的进行分类损失计算并给mask矩阵赋值;标签为负样本的需要根据样本阀值判断是否进行分类损失计算并给mask矩阵赋值;
[0040]
步骤3、分类损失计算:用常规方法进行分类损失计算,决定分类loss是否继续参与训练。
[0041]
本发明的实施例3:一种目标检测交叉数据集的混合训练方法,包括以下步骤:
[0042]
步骤1、样本标签分配:输入的图片经过骨干网络和特征金字塔网络后生成特征图featuremap,特征图featuremap的每一个点对应一个预先定义尺寸的样本,一个样本对应于输入图片上的一个矩形区域,特征图featuremap上每个样本的激活值代表该样本属于对应类别的概率,样本经过匹配之后得出正样本和负样本;样本的匹配过程为:每个样本通过最大iou或者最近中心点的距离与真实的gt进行匹配,样本与gt匹配成功后被分配到该gt对应的类别标签,对于匹配成功的样本称之为正样本,未匹配任何gt的样本称之为负样本;
[0043]
样本类别标签具体可以为:设a数据集中包含的类别数为c1,类别标签为{1,...,c1},b数据集中包含的类别数为c2,类别标签为{c1+1,...,c1+c2},数据集a的负样本标签为c1+c2+1,数据集b的负样本标签为c1+c2+2;
[0044]
步骤2、动态生成mask矩阵:根据特征图featuremap生成的样本标签,动态的生成mask矩阵:设一张图片的特征图featuremap生成的样本数为n,a和b数据集的总类别数为c1+c2,则特征图featuremap包含c1+c2个通道,每个通道表示在该位置存在对应类别的概率,全部激活值输出为n*(c1+c2),同时动态的生成n*(c1+c2)的一个mask矩阵,样本和mask矩阵一一对应,mask矩阵中满足条件的置1,不满足条件的置0,将mask乘到最后的分类loss中,动态的决定是否忽略某个样本的某个类别的loss;
[0045]
mask矩阵中置为1或0的判断过程为:特征图featuremap的每一个样本,判断是否为正样本,如果是正样本则将mask中对应的第i行置1,对于i∈[0,n),mask[i,:]=1,如果不是正样本,则判断样本的标签是c1+c2+1或c1+c2+2,若样本标签为c1+c2+1,则循环判断样本的激活值是否大于b数据集中每一类的最优阈值t,大于最优阈值t,将样本对应的类别mask位置置0,对于样本编号为i,类别为ci,那么mask[i,ci]=0,不大于最优阈值t则将样本对应的类别mask位置置1,对于样本编号为i,类别为ci,那么mask[i,ci]=1;若样本标签为c1+c2+2,则循环判断样本的激活值是否大于a数据集中每一类的最优阈值t,大于最优阈
值t,将样本对应的类别mask位置置0,对于样本编号为i,类别为ci,那么mask[i,ci]=0,不大于最优阈值t则将样本对应的类别mask位置置1,对于样本编号为i,类别为ci,那么mask[i,ci]=1;
[0046]
最优阈值t的选取过程:在一种实现中,可以将阈值区间从0-1均匀分成k个区间,设置参数k=100,则每个区间的分割为{0.01,0.02,.....,0.99,1},正负样本分别统计,记为p_bin和n_bin,p_bin和n_bin的维度为(c1+c2)*100,每一个类别单独统计激活值落在bin区间的总数,对于正样本的样本激活值,对应类别的p_bin的计数加一,样本的类别为i,激活值为j,那么p_bin[i,j]+=1,对于负样本的样本激活值,对应类别的n_bin的计数加一,样本的类别为i,激活值为j,那么n_bin[i,j]+=1;训练完一轮迭代后,可以统计得到训练集中所有类别的正负样本在100个不同的bin的计数,对正负样本的计数bin计算f1分数,取f1分数最高的bin值作为动态mask的生成阈值t;
[0047]
f1分数的计算公式(1)为:
[0048][0049]
计算公式(1)中precision的计算公式(2)为
[0050]
计算公式(1)中recall的计算公式(3)为
[0051]
计算公式(2)和计算公式(3)中:tp表示预测为正样本,标签也是正样本,fp表示预测为正样本,标签是负样本,fn表示预测为负样本,标签是正样本;对于一个epoch中统计得到的p_bin和n_bin,那么对于类别为ci的第i个bin,其tp为fp为fn为将tp、fp、fn带入公式(1)、(2)、(3)中可以得到每个类别在每个bin下的f1分数,对于每一个类别取f1分数最大值对应的bin值作为该类的mask阈值,记为最优阈值t,维度为(c1+c2);
[0052]
步骤3、分类损失计算:用常规方法进行分类损失计算,决定分类loss是否继续参与训练。
[0053]
本发明的实施例4:一种目标检测交叉数据集的混合训练方法,包括以下步骤:
[0054]
步骤1、样本标签分配:输入的图片经过骨干网络和特征金字塔网络后生成特征图featuremap,特征图featuremap的每一个点对应一个预先定义尺寸的样本,一个样本对应于输入图片上的一个矩形区域,特征图featuremap上每个样本的激活值代表该样本属于对应类别的概率,样本经过匹配之后得出正样本和负样本;样本的匹配过程为:每个样本通过最大iou或者最近中心点的距离与真实的gt进行匹配,样本与gt匹配成功后被分配到该gt对应的类别标签,对于匹配成功的样本称之为正样本,未匹配任何gt的样本称之为负样本;
[0055]
样本类别标签具体可以为:设a数据集中包含的类别数为c1,类别标签为{1,...,c1},b数据集中包含的类别数为c2,类别标签为{c1+1,...,c1+c2},数据集a的负样本标签为c1+c2+1,数据集b的负样本标签为c1+c2+2;
[0056]
步骤2、动态生成mask矩阵:根据特征图featuremap生成的样本标签,动态的生成mask矩阵:设一张图片的特征图featuremap生成的样本数为n,a和b数据集的总类别数为c1
+c2,则特征图featuremap包含c1+c2个通道,每个通道表示在该位置存在对应类别的概率,全部激活值输出为n*(c1+c2),同时动态的生成n*(c1+c2)的一个mask矩阵,样本和mask矩阵一一对应,mask矩阵中满足条件的置1,不满足条件的置0,将mask乘到最后的分类loss中,动态的决定是否忽略某个样本的某个类别的loss;
[0057]
mask矩阵中置为1或0的判断过程为:特征图featuremap的每一个样本,判断是否为正样本,如果是正样本则将mask中对应的第i行置1,对于i∈[0,n),mask[i,:]=1,如果不是正样本,则判断样本的标签是c1+c2+1或c1+c2+2,若样本标签为c1+c2+1,则循环判断样本的激活值是否大于b数据集中每一类的最优阈值t,大于最优阈值t,将样本对应的类别mask位置置0,对于样本编号为i,类别为ci,那么mask[i,ci]=0,不大于最优阈值t则将样本对应的类别mask位置置1,对于样本编号为i,类别为ci,那么mask[i,ci]=1;若样本标签为c1+c2+2,则循环判断样本的激活值是否大于a数据集中每一类的最优阈值t,大于最优阈值t,将样本对应的类别mask位置置0,对于样本编号为i,类别为ci,那么mask[i,ci]=0,不大于最优阈值t则将样本对应的类别mask位置置1,对于样本编号为i,类别为ci,那么mask[i,ci]=1;
[0058]
最优阈值t的选取过程:在一种实现中,可以将阈值区间从0-1均匀分成k个区间,设置参数k=100,则每个区间的分割为{0.01,0.02,.....,0.99,1},正负样本分别统计,记为p_bin和n_bin,p_bin和n_bin的维度为(c1+c2)*100,每一个类别单独统计激活值落在bin区间的总数,对于正样本的样本激活值,对应类别的p_bin的计数加一,样本的类别为i,激活值为j,那么p_bin[i,j]+=1,对于负样本的样本激活值,对应类别的n_bin的计数加一,样本的类别为i,激活值为j,那么n_bin[i,j]+=1;训练完一轮迭代后,可以统计得到训练集中所有类别的正负样本在100个不同的bin的计数,对正负样本的计数bin计算f1分数,取f1分数最高的bin值作为动态mask的生成阈值t;
[0059]
f1分数的计算公式(1)为:
[0060][0061]
计算公式(1)中precision的计算公式(2)为
[0062]
计算公式(1)中recall的计算公式(3)为
[0063]
计算公式(2)和计算公式(3)中:tp表示预测为正样本,标签也是正样本,fp表示预测为正样本,标签是负样本,fn表示预测为负样本,标签是正样本;对于一个epoch中统计得到的p_bin和n_bin,那么对于类别为ci的第i个bin,其tp为fp为fn为将tp、fp、fn带入公式(1)、(2)、(3)中可以得到每个类别在每个bin下的f1分数,对于每一个类别取f1分数最大值对应的bin值作为该类的mask阈值,记为最优阈值t,维度为(c1+c2);
[0064]
步骤3、分类损失计算:目标检测的分类损失可以用交叉熵或focalloss,直接将mask矩阵和分类loss相乘,即可决定分类loss是否继续参与训练;
[0065]
对于交叉熵或focalloss损失,所有样本的损失可以表述为如下表达式(4):
[0066]
l={l1,l2,...,ln}
t
[0067]
表达式(4)中l的维度为n*(c1+c2),n为样本总数,每一个样本的损失ln:
[0068]
交叉熵ln的计算公式(5)如下:
[0069]
ln=-y
n log(xn)-(1-yn)log(1-xn)
[0070]
focalloss中ln的计算公式(6)如下:
[0071]
ln=-α(1-xn)
βyn log(xn)-(1-α)(xn)
β
(1-yn)log(1-xn)
[0072]
计算公式(5)和计算公式(6)中yn为每个样本的标签,维度为(c1+c2),xn为每个样本的激活值,维度为(c1+c2);公式(6)中的α、β为超参数,一般设置为0.25和2;
[0073]
对于交叉熵或focalloss修改后的l_mask形式如下式(7):
[0074]
l_mask=l*mask={l1,l2,...,ln}
t
*mask。
[0075]
本发明的一种实施例的工作原理:输入的图片经过骨干网络和特征金字塔网络后生成特征图featuremap,特征图featuremap的每一个点对应一个预先定义尺寸的样本,一个样本对应于输入图片上的一个矩形区域,每个样本通过最大iou或者最近中心点的距离与真实的gt进行匹配,样本与gt匹配成功后被分配到该gt对应的类别标签,对于匹配成功的样本称之为正样本,未匹配任何gt的样本称之为负样本;同时动态生成mask矩阵,判断特征图featuremap的每一个样本是否为正样本,如果是正样本则将mask矩阵中对应的点置1,如果不是正样本,则判断样本的标签是c1+c2+1或c1+c2+2,若样本标签为c1+c2+1,则循环判断样本的激活值是否大于b数据集中每一类的最优阈值t,大于最优阈值t,将样本对应mask矩阵的点置0,不大于最优阈值t则将样本对应mask矩阵的点置1;若样本标签为c1+c2+2,则循环判断样本的激活值是否大于a数据集中每一类的最优阈值t,大于最优阈值t,将样本对应mask矩阵的点置0,不大于最优阈值t则将样本对应mask矩阵的点置1;最后用交叉熵或focalloss进行分类损失计算,将mask矩阵和分类loss相乘,决定分类loss是否继续参与训练。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1