一种性格加强的对话情感预测模型及其构建方法
1.本发明涉及对话系统中情感预测技术领域,尤其是一种基于对话者性格加强的对话情感预测模型及其构建方法。
背景技术:
2.情感计算(affective computing)是自然语言处理领域中的一项基础任务,其目的是推断用户语句中的情感信息。随着互联网技术的蓬勃发展,如今已经进入信息爆炸的时代,如何从用户的海量数据中提取出用户的情感信息变得尤为重要。特别是在对话系统中,情感计算能够帮助机器理解用户的情感,选择适当的反应情感并在对话中表达出来。在早期研究中,研究者们专注于在相应中呈现特定的情感,或者以同理心回应用户的情感,这样的对话系统忽略了情感表现的个体差异,可能会导致情感交互不一致,让用户感觉他们在与死板的机器交谈。
3.为了解决先前的方法所带来的问题,研究者们采用基于深度学习的方法来处理情感预测任务。由于深度神经网络能够自动地从原始数据中提取特征,从而在很大程度上避免了耗时耗力的特征工程。现有的研究往往使用循环神经网络进行情感预测,因为循环神经网络能够抓取序列信息,从而能够更好地抓取文本中的有效信息。另外,用户和物品作为评论的发出者和接受者,它们的信息也相当重要。因此,研究者引入自注意力机制,帮助循环神经网络更好地抓取对话系统中语句中的有效信息,以更好地进行情感预测。
4.现有技术的情感预测方法只进行一次分类即得出结果,对于类别较多的任务,显得有些力不从心,尤其是对话系统中情感预测的个体差异问题更是无能为力。其主要问题在于,如果只进行一次分类,那么在这一次分类的过程中,需要均衡的考虑所有的情感类别。而实际上,有些类别的正确性更高,需要赋予更多的关注,有些类别的正确性更低,可以适当减少关注。通过一些先验知识,例如用户和物品的交互信息,可以提前判断哪些类别的正确性更高,哪些类别的正确性更低,在这个基础上再进行分类会更有针对性,效果也会更好。
技术实现要素:
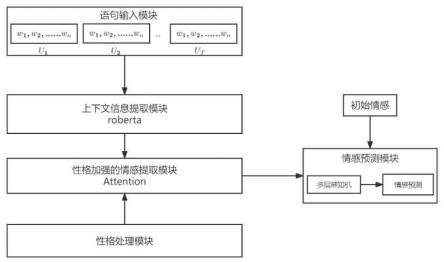
5.本发明的目的是针对现有技术的不足而提供的一种性格加强的对话情感预测模型及其构建方法,采用语句输入模块、上下文特征提取模块、性格加强的情感抽取模块、性格处理模块和情感预测模块组成的对话情感预测模型,预测对话者的情感,利用用户的初始情感和性格信息,以及对话的上下文信息,通过性格影响的情感转换,最终得到最终预测结果。对话情感预测模型的构建包括:获取对话者性格信息、用户初始情感表示、词级别信息提取、句子表征生成、性格加强的情感提取和情感预测等步骤。本发明提升了深度学习模型在对话中进行情感预测的准确性,在meld和emorynlp两个真实数据集上进行实验,结果表明较高的准确率和更强的可解释性,方法简便,实用性强,效果好,具有很好的应用前景。
6.实现本发明目的具体技术方案是:一种性格加强的对话情感预测模型,其特点是
采用语句输入模块、上下文特征提取模块、性格加强的情感抽取模块、性格处理模块和情感预测模块组成的对话情感预测模型,预测对话者的情感,所述语句输入模块将输入的对话语句进行分句处理后输入上下文特征提取模块;所述上下文特征提取模块使用预训练模型roberta从对话语句中,将得到上下文信息的向量表示输入性格加强的情感抽取模块;所述性格加强的情感抽取模块协同性格处理模块采用注意力机制以及从对话语句中学习用户情感,将得到情感变化的向量表示输入情感预测模块;所述情感预测模块将对话者的初始情感向量和性格影响的情感向量连接起来,从而预测对话者的情感。
7.所述情感预测模块由多层感知机和softmax函数组成,将对话者初始情感向量和性格影响的情感转换向量相加后输入多层感知机和softmax函数中进行情感预测。
8.一种性格加强的对话情感预测模型的构建方法,其特特点是对话情感预测模型的构建具体包括下述步骤:
9.步骤1:获取对话者性格信息
10.1-1:采用性格大五结构模型来表示对话者的性格,用5维向量表示对话者的性格信息,性格向量的维度分别表示大五模型中的ocean(openness,conscientiousness,extraversion,agreeableness,neuroticism),将ocean映射到情感模型pad中(pleasure,arousal,dominance),得到下述(a)式表示的对话者性格信息pn:
11.pn=(p
α
,p
β
,p
γ
)
ꢀꢀꢀ
(a)。
12.其中,p
α
、p
β
、p
γ
分别为pad空间中的权重,且由下述(b)~(d)计算:
13.p
α
=0.21e+0.59a+0.19n
ꢀꢀꢀ
(b);
14.p
β
=0.15o+0.30a-0.57n
ꢀꢀꢀ
(c);
15.p
γ
=0.25o+0.17c+0.60e-0.32a
ꢀꢀꢀ
(d)。
16.1-2:获得对话者性格信息后,通过多层感知机提取对话者的性格表示向量r
p
,具体计算如下述(e)式计算:
17.r
p
=dropout(relu(w
p
*pn+b
p
))
ꢀꢀꢀ
(e)。
18.其中,pn=(p
α
,p
β
,p
γ
)表示心理学中将性格映射到pad空间的性格表示;dropout是正则化手段;relu(x)=max(0,x)是激活函数;w
p
是权重矩阵;b
p
是偏置项;r
p
表示经过深度神经网络学习后的性格向量表示。
19.步骤2:用户初始情感表示
20.2-1:将情感分为七类(即中性、生气、厌烦、恐惧、开心、悲伤和惊讶),将七种情感映射到pad(pleasure-arousal-dominance)空间中,pad空间在三个不同维度上表示了情感意向,详见下表1心理学中的七种情感表示向量e
pad
:
21.表1七种情感表示向量
[0022][0023]
表中,p体现对话者情感中的积极性(正值)和消极性(负值);a体现对话者神经(生理层面)的激活水平及兴奋程度(高兴奋为正值,低兴奋为负值);d体现对话者与外部环境相互主导的强弱情况(对话者主导为正值,外界主导为负值)。
[0024]
根据表1得到心理学中的情感表示向量e
pad
,通过多层感知机提取对话者初始情感的表示向量ei,具体计算如下述(f)式:
[0025]ei
=relu(w
ei
*e
pad
+b
ei
)
ꢀꢀꢀ
(f)。
[0026]
其中,ei表示对话者的初始情感表示向量;relu(x)=max(0,x)是激活函数;w
ei
是权重矩阵;b
ei
是偏置项。
[0027]
步骤3:词级别信息提取
[0028]
将对话语句进行分句,对每个句子中的词所对应的向量按序送入双向lstm中进行处理,使用双向lstm对应位置的输出表示该位置的词所包含的信息。
[0029]
步骤4:句子表征生成
[0030]
使用预训练模型roberta提取对话语句的语义信息,输入对话语句ui,ui语句的长度为120,对长度小于120的语句进行padding处理,使用k维向量表示语句的语义信息,k的取值为768,i表示对话中的第i个语句,获得语句的语义信息后,通过多层感知机获得语句的情感信息具体计算如下述(g)~(h)式:
[0031][0032][0033]
其中,ui表示对话中的第i个句子;ai表示第i个句子的attention-mask信息;dropout是正则化手段;relu(x)=max(0,x)是激活函数;w
u1
是权重矩阵;b
u1
是偏置项;是对话中第i个语句的roberta的输出;是对话中第i个语句的深度神经网络的输出;;eu是表示句子的语义信息;ru表示语句的情感信息。
[0034]
步骤5:性格加强的情感提取
[0035]
5-1:使用k维向量表示对话中第i个语句的情感信息,使用k维向量r
p
表示对话者的性格向量,其中k的取值为128。
[0036]
5-2:采用基于余弦和正弦的位置编码方案,且由下述(i)~(j)式在语句情感信息和性格信息表示中加入位置编码:
[0037][0038][0039]
其中,p表示对应的位置编码矩阵;i表示行;j表示列;p
i,2j
为第i个位置在2j
[0040]
维的位置编码。
[0041]
5-3:根据对话中语句的位置,把语句情感信息向量和位置编码向量相加作为新的语句向量表示具体计算如下述(k)式;
[0042][0043]
其中,p表示对应的位置编码矩阵;表示加入位置编码的语句k维向量表示。
[0044]
5-4:使用性格信息向量r
p
作为attention层的查询(query)向量q,使用语句的向量表示作为attention层的键k(key)和值v(value)向量。
[0045]
5-5:将查询向量q和每个键k由下述(m)式计算权重;
[0046]
f(q,ki)=q
t
wakiꢀꢀꢀ
(m)。
[0047]
其中,q
t
为性格查询向量;wa为注意力矩阵;ki为语句情感向量。
[0048]
5-6:使用softmax函数将上述权重由下述(n)式进行归一化处理:
[0049][0050]
其中,ai为第i个语句的权重;softmax(f(q,ki))为激活函数;
[0051]
exp(f(q,k))为指数函数。
[0052]
5-7:对权重和相应的值v进行加权求和,得到attention值作为情感转换向量ea,具体计算如下式(p);
[0053]
ea=attention(q,k,v)=∑
iaivi
ꢀꢀꢀ
(p)。
[0054]
其中,q、k和v分别是查询、键、值向量;ea表示性格影响的情感转换向量;ai为vi向量的权重。
[0055]
步骤6:情感预测
[0056]
情感预测模块由多层感知机和softmax函数组成,将对话者初始情感向量和性格影响的情感转换向量相加后输入多层感知机和softmax函数中进行情感预测,具体计算如下述(q)式;
[0057]er
=softmax(relu(w
er
*(ei+ea)+b
er
))
ꢀꢀꢀ
(q)。
[0058]
其中,ei和ea分别是对话者初始情感和性格加强的情感转换向量表示;relu(x)=max(0,x)为激活函数。
[0059]
本发明与现有技术相比具有准确率更高,可解释性更强,大大提升了深度学习模型在对话中进行情感预测的准确性,方法简便,实用性强,效果好,利用用户和物品的交互信息以及评论信息进行对评论的情感倾向进行二次分类,从而充分使用用户信息、物品信息和文本信息,提高了情感分类的准确率,具有很好的应用前景。
附图说明
[0060]
图1为本发明的流程图。
具体实施方式
[0061]
参阅图1,本发明采用语句输入模块、上下文特征提取模块、性格加强的情感抽取模块、性格处理模块和情感预测模块组成的对话情感预测模型,预测对话者的情感,所述语句输入模块将输入的对话语句进行分句处理后输入上下文特征提取模块;所述上下文特征提取模块使用预训练模型roberta从对话语句中,将得到上下文信息的向量表示输入性格加强的情感抽取模块;所述性格加强的情感抽取模块协同性格处理模块采用注意力机制以及从对话语句中学习用户情感,将得到情感变化的向量表示输入情感预测模块;所述情感预测模块将对话者的初始情感向量和性格影响的情感向量连接起来,从而预测对话者的情感。
[0062]
结合以下具体实施例和附图,对本发明作进一步的详细说明。实施本发明的过程、条件、实验方法等,除以下专门提及的内容之外,均为本领域的普遍知识和公识常识,本发明没有特别限制内容。
[0063]
实施例1
[0064]
采用meld数据集中的一个对话例子,对话者1是chandler,对话者2为jade,对话者1的ocean性格向量为[0.648,0.375,0.386,0.58,0.477](以下简称性格向量p),对话语句1为“um,absolutely.uh,how'bout tomorrow afternoon?do you know uh,central perk in the village,say,five-ish?”(以下简称为语句u1),对话语句2为“great,i'll see you then.”(以下简称为语句u2),对话者的初始情感为“neutral”(以下简称初始情感ei),对对话者1(chandler)的下一语句的情感进行预测,其具体操作按下述步骤进行:
[0065]
步骤1:获取对话者1(chandler)的性格信息
[0066]
1-1:使用64维向量r
p
表示对话者1的性格信息;把ocean性格向量p映射到情感pad空间,得到pad空间性格向量表示:p
pad
=[0.514,0.00,0.272],具体计算如下述(1)-(3)式:
[0067]
p
α
=0.21e+0.59a+0.19n
ꢀꢀꢀ
(1);
[0068]
p
β
=0.15o+0.30a-0.57n
ꢀꢀꢀ
(2);
[0069]
p
γ
=0.25o+0.17c+0.60e-0.32a
ꢀꢀꢀ
(3)。
[0070]
1-2:将pad空间中的性格向量p
pad
送入深度神经网络得到对话者1的性格表示向量r
p
,具体计算如式(4);
[0071]rp
=dropout(relu(w
p
*pn+b
p
))
ꢀꢀꢀ
(4)。
[0072]
其中,p
pad
=(p
α
,p
β
,p
γ
)表示pad空间计算得出;dropout是正则化手段;relu(x)=max(0,x)是激活函数;w
p
是权重矩阵;b
p
是偏置项;r
p
表示经过深度神经网络的输出。
[0073]
步骤2:用户初始情感表示
[0074]
2-1:使用64维向量ei表示对话者1的初始情感;将对话者1的初始情感映射到情感pad空间中得到e
pad
=[0.00,0.00,0.00],具体映射如下表1所示:
[0075]
表1七种情感表示向量
[0076][0077]
2-2:将pad空间中的情感向量e
pad
送入深度神经网络得到对话者1的初始情感表示向量ei,具体计算如述(5)式:
[0078]ei
=relu(w
ei
*e
pad
+b
ei
)
ꢀꢀꢀ
(5)。
[0079]
其中,ei表示经过深度神经网络的输出;relu(x)=max(0,x)是激活函数;w
ei
是权重矩阵;b
ei
是偏置项。
[0080]
步骤3:词级别信息提取
[0081]
将对话语句u1、u2进行分,对每个句子进行如下处理:将句子中的词所对应的向量按序送入双向lstm中,使用双向lstm对应位置的输出表示该位置的词所包含的信息。
[0082]
步骤4:句子表征生成
[0083]
将对话语句u1和u2进行padding处理,长度统一为120,将u1和u2送入roberta得到对话语句u1和u2的语义信息向量的语义信息向量的维度为768,将语义信息向量送入深度神经网络得到语句情感表示re;具体计算如下述(6)~(7)式;
[0084][0085][0086]
其中,ui表示对话中的第i个句子;ai表示第i个句子的attention-mask信息;dropout是正则化手段;relu(x)=max(0,x)是激活函数;w
u1
是权重矩阵;b
u1
是偏置项;是对话中第i个语句的roberta的输出;是对话中第i个语句的深度神经网络的输出。
[0087]
步骤5:性格加强的情感提取
[0088]
5-1:使用64维向量表示对话中第i个语句的情感信息,使用64维向量r
p
表示对话者的性格向量:。
[0089]
5-2:在语句情感信息和性格信息表示中加入位置编码,采用基于余弦和正弦的位置编码方案,根据对话中语句的位置,把语句情感信息向量和位置编码向量相加作为新的语句向量表示具体计算如下述(8)~(10)式;
[0090][0091]
[0092][0093]
其中,p表示对应的位置编码矩阵;i表示行;j表示列;k维向量表示加入位置编码的语句向量了表示。
[0094]
5-3:使用性格信息向量r
p
作为attention层的查询(query)向量q,使用语句的向量表示作为attention层的键k(key)和值v(value)向量。
[0095]
5-4:将查询向量(query)和每个键(key)计算得到权重,使用softmax函数对这些权重进行归一化处理,对权重和相应的键值(value)进行加权求和得到最后attention值作为情感转换向量ea,具体计算如下述(11)~(13)式:
[0096]
f(q,ki)=q
t
wakiꢀꢀꢀ
(11);
[0097][0098]
ea=attention(q,k,v)=∑
iaivi
ꢀꢀꢀ
(13)。
[0099]
其中,q、k、v分别是查询、键、值向量;ea表示性格影响的情感转换。
[0100]
步骤6:情感预测
[0101]
情感预测模块由多层感知机和softmax函数组成,将对话者初始情感向量ei和性格影响的情感转换向量ea相加后输入多层感知机和softmax函数中进行情感预测,具体计算如下述(14)式:
[0102]er
=softmax(relu(w
er
*(ei+ea)+b
er
))
ꢀꢀꢀ
(14)。
[0103]
其中,ei和ea分别是对话者初始情感和性格加强的情感转换向量表示;relu(x)=max(0,x)为激活函数。
[0104]
本发明提升了深度学习模型在对话中进行情感预测的准确性,在meld和emorynlp两个真实数据集上进行实验,实验结果表明,本发明与现有技术相比,准确率更高,可解释性更强。
[0105]
以上只是本发明的较佳实现而已,并非对本发明做任何形式上的限制,故凡未脱离本发明技术方案的内容,依据本发明的技术实质对以上实现方法所做的任何的简单修改、等同变化与修饰,凡为本发明等效实施,均应包含于本专利的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1