一种基于知识驱动的非合作式人格预测方法及系统
1.本发明涉及信息检索与推荐领域,特别是指一种基于知识驱动的非合作式人格预测方法及系统。
背景技术:
[0002][0003]
传统的人格分析方法主要包括以下两类:基于自我报告型量表的人格分析方法和基于社交网络数据的人格分析方法。基于自我报告型量表的人格分析方法主要是通过用户填写自我报告型量表,从而实现对用户人格特质的测量,需要在个体积极配合的情况下获取个体的人格信息,属于合作式方法。然而,由于用户在填写量表时难免具有主观性,并且需要施策人员的辅助,因此该方法丧失了易推广的优点。随着大数据时代的到来,相关研究人员将人格理论与人们在微博等社交平台产生的海量社交数据结合起来,实现基于社交网络数据的人格分析方法。主流做法如下:以人工填写的自我报告型量表为前提,对用户产生的社交数据进行特征提取,基于特征提取的结果建立机器学习预测模型,然后面向用户进行施测。
[0004]
主流社交网络用户人格预测方法主要存在以下四个方面的问题:(1)量表的主观性以及数量质量限制,要求用户具有合作性;(2)不同社交网络的跨范围通用性不强;(3)人格预测模型的持久稳定性不足;(4)监督学习的黑盒方式使得预测模型不具有可解释性。其根本原因是:主流方法属于数据驱动方法,采用合作式(量表填写)、黑盒式(机器学习)人格预测,难以适用精准画像所需的非合作式与可解释性社交网络用户人格预测。基于知识驱动的非合作式与可解释性人格分析方法,如词典法,有望解决上述四个问题,实现大规模非合作式社交网络用户人格分析。
技术实现要素:
[0005]
本发明的主要目的在于克服现有技术中的上述缺陷,提出一种基于知识驱动的非合作式人格预测方法及系统,能够有效地避免传统方法中传统方法中用户合作式的弊端,提高人格预测方法的可解释性和可推广性,适用于大规模的社交网络用户人格预测。
[0006]
本发明采用如下技术方案:
[0007]
一方面,一种基于知识驱动的非合作式人格预测方法,包括:
[0008]
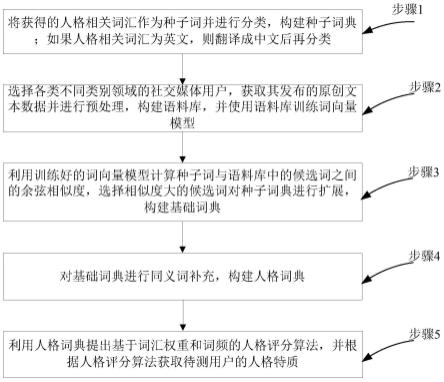
步骤1,将获得的人格相关词汇作为种子词并进行分类,构建种子词典;如果人格相关词汇为英文,则翻译成中文后再分类;
[0009]
步骤2,选择各类不同类别领域的社交媒体用户,获取其发布的原创文本数据并进行预处理,构建语料库,并使用语料库训练词向量模型;
[0010]
步骤3,利用训练好的词向量模型计算种子词与语料库中的候选词之间的余弦相似度,选择相似度大的候选词对种子词典进行扩展,构建基础词典;
[0011]
步骤4,对基础词典进行同义词补充,构建人格词典;
[0012]
步骤5,利用人格词典提出基于词汇权重和词频的人格评分算法,并根据人格评分算法获取待测用户的人格特质。
[0013]
优选的,所述步骤1中,获得的人格相关词汇来自国际上在大五人格研究中总结得到的人格相关英文词汇。
[0014]
优选的,所述步骤2,具体包括:
[0015]
步骤2.1,针对社交媒体的预设各类别,每个类别分别选取发言超过预设条的预设位社交媒体用户,获取预设年内发表的文本数据;
[0016]
步骤2.2,对获取的文本数据进行预处理:删除图片和表情;删除已发布的广告;去掉标点符号并使用jieba软件进行分词,预处理完成后形成语料库;
[0017]
步骤2.3,利用word2vec方法对预处理完成的语料库训练词向量模型,获得每个词语的词向量表示。
[0018]
优选的,所述步骤3,具体包括:
[0019]
步骤3.1,利用训练好的词向量模型,将种子词典中的词汇导入进行余弦相似度计算,选择出扩展词,扩展词的定义为:
[0020]
w=(sim
seed
,kw)
[0021]
式中,sim
seed
为种子词seed与扩展词在向量空间中的词向量余弦相似度,kw是扩展词的词语词频,基础词典构建遵守的原则如下:
[0022]
(1)设置词语相似度sim
seed
阈值,当sim
seed
》0.75的词语才进行收录;
[0023]
(2)设置词语词频阈值,将词频kw《100的词语舍去;
[0024]
(3)若多个种子词同时与一个扩展词拥有高相似度,则仅保留一个扩展词,并对其他种子词进行标记,记录其相似度;
[0025]
步骤3.2,根据上述词典构建规则进行得到结合语料库的基础词典。
[0026]
优选的,所述步骤4,具体包括:
[0027]
从同义词词林中,查找基础词典词汇的多个同义词并扩充到基础词典,构建人格词典,同义词的规则如下:
[0028]
(1)基础词典词汇的同义词若有多个,则全部进行收录;
[0029]
(2)若基础词典词汇没有同义词,则跳过;
[0030]
(3)若基础词典词汇的同义词出现重复,则仅保留一个同义词,在重复的其他基础词典词汇中进行标记。
[0031]
优选的,所述步骤5,具体包括:
[0032]
步骤5.1,将人格词典中种子词的权重设置为1,针对分别由语料库与同义词词林知识库得到的扩展词汇与补充词汇,通过word2vec方法计算其与种子词的相似度以确定其词汇权重,上述构建的人格词典中包含高维度和低维度人格词汇,人格词典中第i维高水平人格维度的高维度扩展词w
hsim
的权重计算方式如下:
[0033][0034]
式中,p
hsim
(i)指高维度扩展词w
hsim
在第i维高水平人格所占有的权重,sim
hseed
表示高维度扩展词w
hsim
与其对应的第j个高维度种子词w
hseed
的word2vec相似度,n
hseed
表示的
是高维度扩展词w
hsim
对应高维度种子词的个数;对各个高维度扩展词来说,将其所对应高维度种子词的word2vec相似度求和并平均,即为高维度扩展词的权重;
[0035]
在人格词典中,第i维高水平人格维度的高维度补充词w
hsyn
的权重计算方式如下:
[0036][0037]
式中,p
hsyn
(i)表示的是高维度补充词w
hsyn
在第i维高水平人格所占有的人格权重,p
hori(j)
(i)表示高维度补充词w
hsyn
的第j个高维度原词w
hori
在第i维人格的权重,n
hori
表示的是与高维度补充词w
hsyn
的高维度原词的个数;
[0038]
人格词典中第i维低水平人格维度的低维度扩展词w
lsim
的权重计算方式如下:
[0039][0040]
式中,p
lsim
(i)指低维度扩展词w
lsim
在第i维低水平人格所占有的权重,sim
lseed
表示低维度扩展词w
lsim
与其对应的第j个低维度种子词w
lseed
的word2vec相似度,n
lseed
表示的是低维度扩展词w
lsim
对应低维度种子词的个数;对各个低维度扩展词来说,将其所对应低维度种子词的word2vec相似度求和并平均,即为低维度扩展词的权重;
[0041]
在人格词典中,第i维低水平人格维度的低维度补充词w
lsyn
的权重计算方式如下:
[0042][0043]
式中,p
lsyn
(i)表示的是低维度补充词w
lsyn
在第i维低水平人格所占有的人格权重, p
lori(j)
(i)表示低维度补充词w
lsyn
的第j个低维度原词w
lori
在第i维低水平人格的权重,n
lori
表示的是与低维度补充词w
lsyn
的低维度原词的个数;
[0044]
步骤5.2,分析待测用户在社交媒体上发布的文本数据,根据人格词典统计文本数据中各个词汇的词频;
[0045]
步骤5.3,基于上述步骤得到的词汇权重和词频,分别计算待测用户在每个人格维度上高水平和低水平的人格特质得分,高水平人格特质得分的计算方式如下:
[0046][0047]
式中,score
hu
(i)表示用户u在第i维人格高水平下的得分,k
hw(j)
表示第j个人格高维度词汇w在用户文本中出现的词频数,p
hw(j)
(i)表示的是第j个高维度人格词汇w在第i维人格高水平下的权重,n
hi
表示用户文本中与高维度人格词汇匹配的个数;
[0048]
低水平人格特质得分的计算方式如下:
[0049]
[0050]
式中,score
lu
(i)表示用户u在第i维人格低水平下的得分,k
lw(j)
表示第j个低维度人格词汇w在用户文本中出现的词频数,p
lw(j)
(i)表示的是第j个低维度人格词汇w在第i维人格低水平下的权重,n
li
表示用户文本中与低维度人格词汇匹配的个数;
[0051]
对于用户u而言,其在第i维人格特质下的得分为高水平得分减去低水平得分,即:
[0052]
scoreu(i)=score
hu
(i)-score
lu(i)[0053]
式中,scoreu(i)表示用户u在第i维人格的得分,score
hu
(i)表示用户u在第i维人格高水平下的得分,score
lu
(i)表示用户u在第i维人格低水平下的得分。
[0054]
另一方面,一种基于知识驱动的非合作式人格预测系统,包括:
[0055]
种子词典构建模块,用于将获得的人格相关词汇作为种子词进行翻译和分类,构建种子词典;
[0056]
语料库构建模块,用于选择各类不同类别领域的社交媒体用户,获取其发布的原创文本数据并进行预处理,构建语料库,并使用语料库训练词向量模型;
[0057]
基础词典构建模块,用于利用训练好的词向量模型计算种子词与语料库中的候选词之间的余弦相似度,选择相似度大的候选词对种子词典进行扩展,构建基础词典;
[0058]
人格词典构建模块,用于对基础词典进行同义词补充,构建人格词典;
[0059]
人格特质获取模块,用于利用人格词典提出基于词汇权重和词频的人格评分算法,并根据人格评分算法获取待测用户的人格特质。
[0060]
由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
[0061]
本发明通过知识库和语料库结合的方式构建人格词典,有效缓解领域词典时效性和全面性不足的问题,并且利用人格词典提出基于词汇权重和词频的人格评分算法,进而获取待测用户的人格特质,避免了传统方法中用户合作式的弊端,提高人格预测方法的可解释性和可推广性,适用于大规模的社交网络用户人格预测。
附图说明
[0062]
图1为本发明实施例的基于知识驱动的非合作式人格预测方法的流程图;
[0063]
图2为本发明实施例的基于知识驱动的非合作式人格预测方法的详细流程图;
[0064]
图3为本发明实施例的人格词典构建流程图;
[0065]
图4为本发明实施例的基于词汇权重和词频的人格评分算法流程图;
[0066]
图5为本发明实施例的100名用户间接实验得分相似度图;
[0067]
图6为本发明实施例的基于知识驱动的非合作式人格预测系统的结构框图。
具体实施方式
[0068]
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
[0069]
参见图1所示,本发明一种基于知识驱动的非合作式人格预测方法,包括:
[0070]
步骤1,将获得的人格相关词汇作为种子词并进行分类,构建种子词典;如果人格相关词汇为英文,则翻译成中文后再分类;
[0071]
步骤2,选择各类不同类别领域的社交媒体用户,获取其发布的原创文本数据并进行预处理,构建语料库,并使用语料库训练词向量模型;
[0072]
步骤3,利用训练好的词向量模型计算种子词与语料库中的候选词之间的余弦相似度,选择相似度大的候选词对种子词典进行扩展,构建基础词典;
[0073]
步骤4,对基础词典进行同义词补充,构建人格词典;
[0074]
步骤5,利用人格词典提出基于词汇权重和词频的人格评分算法,并根据人格评分算法获取待测用户的人格特质。
[0075]
进一步的,参见图2所示,本发明的模型分为5个部分:种子词典构建、词向量模型训练、基础词典构建、人格词典构建、人格评分算法设计。具体实施步骤如下:
[0076]
(1)种子词典构建
[0077]
参见图3种子词典构建部分流程图所示,本实施例利用schwartz等人通过分析75000个具有人格真值的facebook用户的语言特点得到的与大五人格高相关的词语,对其进行翻译和分类并对结果进行校正,得到种子词典。校正原则为:(1)删除不符合中文特点的词语;(2) 删除中文不常使用的外国文字;(3)对于国外使用的部分缩写进行直译加意译;(4)合并相同语义的词语。最终得到的种子词典规模如表1所示:
[0078]
表1种子词典规模
[0079][0080]
(2)词向量模型训练
[0081]
本实施例利用选择各类不同类别领域的微博用户,爬取其发布的原创文本信息作为语料库,具体包括:
[0082]
首先,针对微博的31个类别,从每个类别分别选取发言超过1000条的3位微博用户,获取其三年(2018-2021)内发表的原微博;对获取的微博文本信息进行预处理:删除发言中的图片、表情等信息;删除已发布的广告微博;去掉标点符号并使用jieba软件进行分词,预处理完成后形成语料库。
[0083]
然后,利用word2vec方法对预处理完成的语料库训练词向量模型,获得每个词语的词向量表示。
[0084]
(3)基础词典构建
[0085]
参见图3基础词典构建部分流程图所示,基础词典构建是利用语料库对种子词典扩展而得到的:利用词向量模型计算种子词与语料库中候选词之间的余弦相似度,选择相似度大的候选词对种子词典进行扩展,形成基础词典。具体包括:
[0086]
首先,训练完成后,将种子词典中的词汇导入进行余弦相似度计算,选择出扩展词。扩展词的定义为:
[0087]
w=(sim
seed
,kw)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0088]
式中,sim
seed
为种子词seed与扩展词在向量空间中的词向量余弦相似度,kw是扩展
词的词语词频。基础词典构建遵循的原则如下:
[0089]
(a)设置词语相似度sim
seed
阈值,当sim
seed
》0.75的词语才进行收录。
[0090]
(b)设置词语词频阈值,将词频kw《100的词语舍去。
[0091]
(c)若多个种子词同时与一个扩展词拥有高相似度,则仅保留一个扩展词,并对其他种子词进行标记,记录其相似度。
[0092]
其次,根据上述词典构建规则进行得到结合语料库的基础词典,共计3115个词语,基础词典的规模如表2所示:
[0093]
表2基础词典规模
[0094][0095]
(4)人格词典构建
[0096]
由于word2vec对于同义词并不敏感,因此较难通过训练得到具有同义词关系的词语。然而对于基础词典而言,每个词仍然存在一些意思相同的同义词。因此,需要通过外部知识库对基础词典进行同义词扩充,本发明利用哈工大同义词词林对基础词典进行补充得到人格词典,进一步提高人格词典的全面性。参见图3人格词典构建部分流程图所示,基于哈工大同义词词林的同义词收录规则如下:
[0097]
(a)基础词典词汇的同义词若有多个,则全部进行收录;
[0098]
(b)若基础词典词汇没有同义词,则跳过;
[0099]
(c)若基础词典词汇的同义词出现重复,则仅保留一个同义词,在重复的其他基础词典词汇中进行标记。
[0100]
经过同义词扩展后得到人格词典,共计10354个词语,人格词典的规模如表3所示:
[0101]
表3人格词典规模
[0102][0103]
本实施例所得到的基于知识库和语料库结合的人格词典,满足以下两个特点:(a)包含许多领域词典不会收录的网络用语,具有时效性;(b)使用了外部知识库哈工大同义词词林进行同义词扩充,具有全面性。
[0104]
(5)基于词汇权重和词频的人格评分算法
[0105]
针对传统人格预测方法存在的用户合作式与不可解释性的问题,本发明利用人格词典提出一种基于词汇权重和词频的人格评分算法,进而利用该评分算法获取待测用户人
格特质。该算法基本原理为:使用词频加权检索的思想,对人格词典中的词汇赋予权重,使词汇可以表示在各个人格维度中的代表程度;同时,使用词频来代表词汇在用户文本中的重要性,进行加权计算,得到人格信息结果,实现待测用户人格特质的获取。参见图4所示,具体包括:
[0106]
1)人格词汇权重计算
[0107]
在大五人格理论中,人格由五种特质组成,并且在每种不同的特质中词语所表达出的人格权重并不相同,每种特质在不同个体中所占的比例也不尽相同,因此用户的人格可以定义为:
[0108]
personality=(score(exrt),score(neur),score(agree),score(cons),score(open))
ꢀꢀꢀꢀꢀꢀꢀ
(2)
[0109]
式中,personality表示用户的人格,score(exrt)表示用户在外倾性上的得分,score(neur) 表示用户在神经质性上的得分,score(agree)表示用户在宜人性上的得分,score(cons)表示用户在尽责性上的得分,score(open)表示用户在外向性上的得分。在每个人格维度中,将人格维度分为高水平和低水平,使用scoreh表示人格维度得分为高水平,score
l
表示人格维度得分为低水平。人格词汇权重计算方式如下所示:
[0110]
首先,将人格词典中种子词的权重设置为1。针对分别由语料库与同义词词林知识库得到的扩展词汇与补充词汇,通过word2vec方法计算其与种子词的相似度确定其词汇权重。上述构建的人格词典中包含高维度和低维度人格词汇,人格词典中第i维高水平人格维度的高维度扩展词w
hsim
的权重计算方式如下:
[0111][0112]
式中,p
hsim
(i)指高维度扩展词w
hsim
在第i维高水平人格所占有的权重,sim
hseed
表示高维度扩展词w
hsim
与其对应的第j个高维度种子词w
hseed
的word2vec相似度,n
hseed
表示的是高维度扩展词w
hsim
对应高维度种子词的个数;对各个高维度扩展词来说,将其所对应高维度种子词的word2vec相似度求和并平均,即为高维度扩展词的权重;
[0113]
在人格词典中,第i维高水平人格维度的高维度补充词w
hsyn
的权重计算方式如下:
[0114][0115]
式中,p
hsyn
(i)表示的是高维度补充词w
hsyn
在第i维高水平人格所占有的人格权重, p
hori(j)
(i)表示高维度补充词w
hsyn
的第j个高维度原词w
hori
在第i维人格的权重,n
hori
表示的是与高维度补充词w
hsyn
的高维度原词的个数;
[0116]
人格词典中第i维低水平人格维度的低维度扩展词w
lsim
的权重计算方式如下:
[0117][0118]
式中,p
lsim
(i)指低维度扩展词w
lsim
在第i维低水平人格所占有的权重,sim
lseed
表
示低维度扩展词w
lsim
与其对应的第j个低维度种子词w
lseed
的word2vec相似度,n
lseed
表示的是低维度扩展词w
lsim
对应低维度种子词的个数;对各个低维度扩展词来说,将其所对应低维度种子词的word2vec相似度求和并平均,即为低维度扩展词的权重;
[0119]
在人格词典中,第i维低水平人格维度的低维度补充词w
lsyn
的权重计算方式如下:
[0120][0121]
式中,p
lsyn
(i)表示的是低维度补充词w
lsyn
在第i维低水平人格所占有的人格权重, p
lori(j)
(i)表示低维度补充词w
lsyn
的第j个低维度原词w
lori
在第i维低水平人格的权重,n
lori
表示的是与低维度补充词w
lsyn
的低维度原词的个数;
[0122]
2)人格特质计算
[0123]
文本与人格之间存在密切关系,因此,本实施例根据用户在微博平台发布的文本数据,根据人格词典统计文本数据中各个词汇的词频。若某一人格维度词汇在用户发布消息时被多次使用,则说明用户在该人格维度下占据的比例更高。此外,不同词汇在每个人格维度中表现出来的人格维度特征程度并不相同,需要计算人格词汇在每个维度中表现出的权重。
[0124]
本实施例采取如下方式进行人格特质计算:首先对高水平和低水平都进行一次计算,得到两种不同水平的人格特质数值;然后将高水平的人格特质分数减去低水平的人格特质分数,得到其对应人格维度分数。高水平人格特质得分的计算方式如下:
[0125][0126]
式中,score
hu
(i)表示用户u在第i维人格高水平下的得分,k
hw(j)
表示第j个人格高维度词汇w在用户文本中出现的词频数,p
hw(j)
(i)表示的是第j个高维度人格词汇w在第i维人格高水平下的权重,n
hi
表示用户文本中与高维度人格词汇匹配的个数;
[0127]
低水平人格特质得分的计算方式如下:
[0128][0129]
式中,score
lu
(i)表示用户u在第i维人格低水平下的得分,k
lw(j)
表示第j个低维度人格词汇w在用户文本中出现的词频数,p
lw(j)
(i)表示的是第j个低维度人格词汇w在第i维人格低水平下的权重,n
li
表示用户文本中与低维度人格词汇匹配的个数;
[0130]
对于用户u而言,其在第i维人格特质下的得分为高水平得分减去低水平得分,即:
[0131]
scoreu(i)=score
hu
(i)-score
lu(i)ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0132]
式中,scoreu(i)表示用户u在第i维人格的得分,score
hu
(i)表示用户u在第i维人格高水平下的得分,score
lu
(i)表示用户u在第i维人格低水平下的得分。
[0133]
当scoreu(i)》0时,表示用户u在第i维人格维度下处于高水平;当scoreu(i)《0时,表示用户u在第i维人格维度下处于低水平;当scoreu(i)=0时,表示用户u在第i维人格维
度下处于平衡水平,对于高水平和低水平人格维度中会表现出的人格特质概率相同。
[0134]
(6)效果评估
[0135]
为了验证本发明方法的效果,通过发放量表的形式获取微博用户在各个维度的人格得分及其发布的文本数据,利用本发明方法对用户发布的文本数据进行分析,得到用户人格特质,并将人格分析的结果与量表的结果进行比对,验证本发明方法的有效性;然后,再将本发明方法结果与目前研究中的优秀方法进行比对,验证该方法的先进性;最后,在大量数据集上,将本发明方法与其他研究算法结果进行间接实验,进一步评估该方法的效果。在先进性实验和间接实验中,对比的算法为bfm算法。bfm算法为中科院心理所计算机网络心理实验室研发的“文心”(textmind)中文心理分析系统中的bfm评分表,该算法可以根据bfm表中功能词所对应的不同人格维度进行评分。
[0136]
首先,本发明方法实验数据的来源为:在有效性实验中,实验数据来源于发布原创微博数量大于100条的微博用户所填写的量表结果及通过爬虫软件获取到的其发布的文本数据;在间接实验中,实验数据来源于微博中不同的32个兴趣分类中粉丝数最高的200名且不是营销号的用户,爬取其微博文本数据,清洗数据后得到的间接实验用户文本数据集。
[0137]
其次,以量表法的人格特质得分为基准,利用余弦相似度评价指标评估本发明方法得到的用户人格特质分数的有效性。由于量表法和本发明方法的刻度级别并不相同,因此,需要对量表得分和本发明方法得分进行标准化。余弦相似度具体计算公式如下:
[0138][0139]
式中,psim
cos
(a,b)为量表数据a与用户数据b之间的人格相似度,i为第i维人格特质, p(a)i和p(b)i分别为量表数据a与用户数据b的第i维人格特质得分。
[0140]
1)算法有效性分析
[0141]
根据量表数据的微博id,爬取用户的文本,舍去用户文本不足100条原创微博的用户,最终得到7位符合要求用户的微博文本。对文本进行预处理后,使用本发明方法得到用户人格分数与量表法得分进行得分相似度计算并取平均值,得到得分相似度计算表如表4所示:
[0142]
表4各用户量表法与本发明方法得分相似度计算表
[0143]
[0144][0145]
从表4中可以看出,量表法与本发明方法的得分相似度达到61.98%,说明本发明方法可以一定程度地反映量表得到的大五人格结果。与量表法相比,本发明方法无需与与社交网络用户接触,只需获取用户的可公开文本信息,就可以做到大规模对用户无感的非合作式且可解释性强的人格分析,不会对被测人员产生影响,也同时不会触犯用户隐私。
[0146]
2)算法先进性分析
[0147]
使用bfm算法对用户文本进行人格分析,并将bfm算法的人格得分结果与量表法得分进行相似度计算,得到得分相似度计算表如表5所示:
[0148]
表5量表法与bfm算法得分相似度计算表
[0149][0150]
从表5可以看出,本发明方法的得分结果平均相似度接近bfm算法的结果63.8%。此外,本发明方法的相似度区间在42.98%到82.17%之间,而bfm算法得分的相似度区间在13.59%到91.70%之间,因此本发明方法的稳定性更佳。相比bfm算法,本发明方法的主要优势体现在如下3个方面:(1)收录了更多现代社会中的新词汇和外来词汇,在社交网络语言快速发展的环境下有更好的适应能力;(2)更新简单,不需要领域专家对新词汇进行标注,就可以实现对领域词典的不断更新;(3)本发明方法可以分别得出各个人格维度中高水平和低水平的得分,可以更加针对的分析用户个体的人格特质信息,对下游应用更加有益。
[0151]
3)间接性实验分析
[0152]
间接实验通过本发明方法与bfm算法的得到的人格得分进行余弦相似度计算,进一步检验本发明方法的有效性。具体做法为:首先,对100名用户文本,分别使用本发明方法与bfm 算法进行人格分析,分别得到人格特质得分;然后,计算两种人格特质得分的余弦相似度;最后,计算平均余弦相似度。
[0153]
100名用户的间接实验得分相似度如图5所示:本发明方法与bfm算法的平均余弦相似度为91.72%,因此可以说明本发明方法的结果与现有优秀方法bfm算法的结果相似度高,从而进一步验证了词典法的有效性。
[0154]
综上所述,本发明提出一种基于知识驱动的非合作式人格预测方法,通过知识库和语料库结合的方式构建人格词典,有效缓解领域词典时效性和全面性不足的问题,并且利用人格词典提出基于词汇权重和词频的人格评分算法,进而获取待测用户的人格特质,避免了传统方法中用户合作式的弊端,提高人格预测方法的可解释性和可推广性,适用于
大规模的非合作式社交网络用户人格预测。与目前研究中表现优秀的bfm算法进行先进性和有效性实验对比结果表明,本发明方法具有良好的性能。
[0155]
参见图6所示,本发明一种基于知识驱动的非合作式人格预测系统,包括:
[0156]
种子词典构建模块601,用于将获得的人格相关词汇作为种子词进行翻译和分类,构建种子词典;
[0157]
语料库构建模块602,用于选择各类不同类别领域的社交媒体用户,获取其发布的原创文本数据并进行预处理,构建语料库,并使用语料库训练词向量模型;
[0158]
基础词典构建模块603,用于利用训练好的词向量模型计算种子词与语料库中的候选词之间的余弦相似度,选择相似度大的候选词对种子词典进行扩展,构建基础词典;
[0159]
人格词典构建模块604,用于对基础词典进行同义词补充,构建人格词典;
[0160]
人格特质获取模块605,用于利用人格词典提出基于词汇权重和词频的人格评分算法,并根据人格评分算法获取待测用户的人格特质。
[0161]
一种基于知识驱动的非合作式人格预测系统的具体实现同一种基于知识驱动的非合作式人格预测方法,本实施例不再重复说明。
[0162]
上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1