基于YOLOX的植物气孔多功能实时智能识别系统
基于yolox的植物气孔多功能实时智能识别系统
技术领域
1.本发明涉及智慧农业技术领域,具体涉及基于yolox的植物气孔多功能实时智能识别系统。
背景技术:
2.植物的气孔主要位于叶片表面,是植物与外界环境之间进行气体交换的通道,气孔的分布状况和数量与植物种类有关,同时也受环境等因素的影响。通过了解气孔的数量,可以反映出周围环境和气候的变化以及植物生长的状况。植物叶片上的气孔的开闭情况也对植物的生命活动有重要作用,例如植物的光合作用、离子转运、呼吸作用以及水的转运等都与植物的气孔开闭有着密切的联系。同时植物叶面细胞气孔表型性状具有重要的研究和应用价值,可为提高作物产量和增强作物逆境的耐受性提供理论依据。
3.目前气孔性状的检测主要依靠人工或半自动化的方式,无论从实验时间、实验方式还是检测精度方便都有待改善,近年来随着深度学习与神经网络的高速发展,人们也开始不断用人工智能的方式对此进行改善,但检测效率与识别效果仍有待提高。
4.另一方面,根据实验室使用的显微镜,目前获取植物气孔的方法大多是破坏性的,因为气孔印痕是从植物叶片表面剥离出来并安装在玻璃玻片上进行观察的,因此迫切需要高通量和无损的叶片气孔性状表型。
技术实现要素:
5.为了解决上述技术问题,本发明的目的在于提供一种基于yolox的植物气孔多功能实时智能识别系统,所采用的技术方案具体如下:
6.本发明一个实施例提供了一种基于yolox的植物气孔多功能实时智能识别系统,该系统包括以下模块:
7.数据采集模块,用于采集植物叶表皮图像,将所述叶表皮图像分为单目标检测数据集和双目标检测数据集;
8.迁移学习模块,用于在coco数据集上获取源领域,以采集的叶表皮图像作为目标领域,提取所述源领域和所述目标领域的共同特征,输出多张特征图;
9.标签分类模块,用于对每张所述特征图采用预测分支解耦结构,得到预测框信息,通过标签分配在预测框中挑选出每个标注框对应的正样本锚框;
10.网络模型训练模块,用于分别以单目标检测数据集和双目标检测数据集中一定比例的图像作为训练集,通过整合ciou loss和focal loss,得到focal-ciou loss作为标注框和正样本锚框之间的第一损失函数,将focal-ciou loss与标注框和正样本锚框之间的分类损失加权求和作为训练集的第二损失函数,直至第二损失函数收敛分别完成单目标网络模型和双目标网络的训练;
11.气孔识别模块,用于接收用户上传的图像数据;基于用户选择的识别模式,利用对应的训练完成的网络模型识别所述图像数据中的气孔特征并反馈给用户。
12.优选的,所述数据采集模块还包括:
13.图像预处理单元,用于分别对单目标检测数据集和双目标检测数据集的所有图像去模糊,得到去模糊图像。
14.优选的,所述迁移学习模块包括:
15.共同特征提取单元,用于利用yolox将源领域与单目标检测数据集对应的目标领域进行特征混合,提取两个领域的共同特征;利用yolox将双目标检测数据集对应的目标领域与源领域进行特征混合,提取混合后的共同特征。
16.优选的,所述标签分类模块包括:
17.预测框信息获取单元,用于对于每张特征图,对yolox的解耦头解耦形成三个预测分支,利用每个预测分支对特征图进行预测,将预测结果连接起来作为输出的预测框信息。
18.优选的,所述标签分类模块包括:
19.正样本锚框挑选单元,用于通过判断所述预测框的中心点是否包含于标注框内进行初步筛选,挑选出候选检测框,通过计算候选检测框和标注框之间的坐标损失以及类别损失选取每个标注框的正样本锚框。
20.优选的,所述正样本锚框挑选单元包括:
21.初步筛选单元,用于获取所述预测框的中心点坐标,以及所述标注框的角点坐标,根据角点坐标获取标注框的横坐标范围和纵坐标范围,当中心点坐标的横坐标包含于所述横坐标范围,并且中心点的纵坐标包含于纵坐标范围时,对应的预测框为所述标注框的候选检测框。
22.优选的,所述正样本锚框挑选单元还包括:
23.成本函数获取单元,用于通过计算候选检测框和标注框的交并比获取坐标损失,根据类别的条件概率和每个候选检测框的先验概率获取类别损失,以坐标损失和类别损失的加权求和作为候选检测框和标注框之间的成本函数。
24.优选的,所述正样本锚框挑选单元还包括:
25.正样本锚框获取单元,用于获取每个标注框对应的n个最大的交并比的和,对该和取整作为正样本锚框的选取数量s,以成本函数最低的s个候选检测框作为正样本锚框。
26.优选的,所述网络模型训练模块还包括:
27.测试单元,用于将所述单目标检测数据集和双目标检测数据集中除验证集以外剩余的图像作为对应的测试集,利用测试集对训练完成的网络模型进行检测,评估网络模型的输出结果。
28.优选的,所述气孔识别模块包括:
29.人机交互单元,用于将评估结果发送给用户,若用户不满意,则根据用户需求调整参数直至用户满意。
30.本发明实施例至少具有如下有益效果:
31.1、使用改进的ciou替代iou,加速预测框的收敛、提高预测框的回归精度的基础上,依托于yolox的高性能和高速度,取得了对同类竞品的优势,率先开发出以yolox为检测模型的多功能气孔识别检测系统,具有广阔的应用前景。
32.2、本系统可以实现对植物气孔视频的实时检测和识别,因此可以研究植物叶片在整个生长阶段的气孔性状,可以探索植物对环境变化的反应机制,对植物气孔性状的研究
具有重要意义,对智慧农业的发展起到积极的推动作用。
33.3、本系统采用改进的yolox模型进行气孔识别,在取得最佳性能的同时,具有极具竞争力的推理速度。
附图说明
34.为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
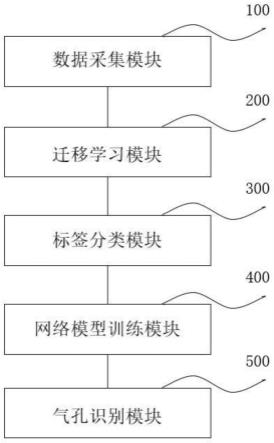
35.图1为本发明一个实施例提供的基于yolox的植物气孔多功能实时智能识别系统的系统框图;
36.图2为本发明系统的主界面;
37.图3为本发明系统设置检测类型界面;
38.图4为本发明系统设置参数调整界面;
39.图5为单图检测展示界面;
40.图6为本发明单图检测结果形成的气孔数据信息表格;
41.图7本发明单图检测结果形成的所有气孔数据信息展示页面;
42.图8为本发明批量检测效果图;
43.图9为本发明批量处理结果详细信息文件;
44.图10为本发明视频检测效果图;
45.图11为图2的英文界面;
46.图12为图5的英文界面。
具体实施方式
47.为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的基于yolox的植物气孔多功能实时智能识别系统,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构、或特点可由任何合适形式组合。
48.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
49.下面结合附图具体的说明本发明所提供的基于yolox的植物气孔多功能实时智能识别系统的具体方案。
50.请参阅图1,其示出了本发明一个实施例提供的基于yolox的植物气孔多功能实时智能识别系统的系统框图,该系统包括以下模块:
51.数据采集模块100、迁移学习模块200、标签分类模块300、网络模型训练模块400以及气孔识别模块500。
52.数据采集模块100,用于采集植物叶表皮图像,将叶表皮图像分为单目标检测数据集和双目标检测数据集。
53.具体的,数据采集模块100包括叶表皮图像采集单元110、数据集区分单元120以及图像预处理单元130。
54.叶表皮图像采集单元110,用于使用便携式手机显微镜或便携式显微镜采集植物叶表皮图像。
55.采集的叶表皮图像是由两种便携式和高通量显微镜装置直接从活叶中获取的图像,进行后续的气孔性状测量,避免了气孔的破坏性成像。
56.数据集区分单元120,用于区分单目标检测植物叶表皮图像和双目标检测植物叶表皮图像。
57.根据需要分别选取单目标检测植物叶表皮数据和双目标检测植物叶表皮数据,即根据拍摄照片的设备来区分单目标图像和双目标图像。若设备放大倍数达到可以进行双目标检测的要求为双目标检测数据;若放大倍数较低肉眼无法区分开闭状态为单目标检测图像。
58.单目标检测植物叶表皮数据为:jpg格式;图像分辨率为:4608
×
3456pixels,~6μm/pixel;双目标检测植物叶表皮数据为:jpg格式;图像分辨率为:640
×
480pixels,~1.5μm/pixel。
59.需要说明的是,单目标检测植物叶表皮图像在后续气孔识别中的识别结果为气孔,双目标检测植物叶表皮图像在后续气孔识别中的识别结果为开气孔和闭气孔两种类别。
60.图像预处理单元130,用于分别对单目标检测数据集和双目标检测数据集的所有图像去模糊,得到去模糊图像。
61.由于植物的叶子是不平坦的,设备拍摄的视野有限且手机的晃动和聚焦都对照片或视频的清晰度有影响,因此选择lucy-richardson算法进行去模糊。
62.具体的计算公式为:
[0063][0064]
其中,表示k次迭代后的去模糊图像,(x,y)表示像素的坐标,g(x,y)表示手机拍摄的原始图像,h(x,y)表示便携式显微成像仪系统的点扩散函数(psf),*表示进行卷积操作。
[0065]
使用lucy-richardson加速算法多次迭代对采集的图像中每个像素点进行去模糊操作,完成图像的去模糊,作为一个示例,本发明实施例通过10次迭代得到最终的去模糊图像。
[0066]
迁移学习模块200,用于在coco数据集上获取源领域,以采集的叶表皮图像作为目标领域,提取源领域和目标领域的共同特征,输出多张特征图。
[0067]
具体的,迁移学习模块200包括源领域和目标领域获取单元210和共同特征提取单元220。
[0068]
源领域和目标领域获取单元210,用于将在coco数据集上的yolox_s预训练模型作为源领域rs,以采集的叶表皮图像作为目标领域,其中单目标检测数据集中的图像作为第一目标领域r
d1
、双目标检测数据集中的图像作为第二目标领域r
d2
。
[0069]
coco数据集是一个可用于图像检测(image detection),语义分割(semantic segmentation)和图像标题生成(image captioning)的大规模数据集,包含大量有标注的图像。
[0070]
共同特征提取单元220,用于利用yolox将源领域与单目标检测数据集对应的目标领域进行特征混合,提取两个领域的共同特征;利用yolox将双目标检测数据集对应的目标领域与源领域进行特征混合,提取混合后的共同特征。
[0071]
yolox在提取特征时采用了spp net来减少卷积运算和防止图像变形,使得任意大小的特征图都能够转换成固定大小的特征向量。采用yolox的backbone和fpn neck网络结构,使rs分别与r
d1
和r
d2
进行特征数据混合并分别提取混合后的共同特征,输出3个不同尺度的特征图。
[0072]
采用类似fpn(feature pyramid networks)的上采样和融合做法加强了对小目标检测的精确度。
[0073]
需要说明的是,在利用yolox进行提取特征之前,由于神经网络输入的限制,输入尺寸大小只能为32的倍数,所以需要将输入的图像重新调整大小,便于特征的提取。
[0074]
标签分类模块300,用于对每张特征图采用预测分支解耦结构,得到预测框信息,通过标签分配在预测框中挑选出每个标注框对应的正样本锚框。
[0075]
具体的,标签分类模块300包括预测框信息获取单元310和正样本锚框挑选单元320。
[0076]
预测框信息获取单元310,用于对于每张特征图,对yolox的解耦头解耦形成三个预测分支,利用每个预测分支对特征图进行预测,将预测结果连接起来作为输出的预测框信息。
[0077]
将每一个尺度的特征图采用预测分支解耦结构,即将yolo head解耦形成三个预测分支:目标框的类别、预测分数分支,目标框为前景还是背景预测分支,目标框的坐标信息预测分支。将这三个分支分别进行预测,再将三个分支的预测结果在连接在一起,作为预测框的输出信息。
[0078]
输出信息为预测框的信息(reg,obj,cls),其中reg为预测框的坐标;obj为预测框属于前景还是背景,属于前景obj的值为0,属于背景obj的值为1;cls为预测框的类别,对于单目标检测cls为1,对于多目标检测cls为2,代表开气孔、闭气孔两种目标类别。
[0079]
耦合检测头可能会损害检测性能,yolox采用预测分支解耦,能够极大改善收敛速度。
[0080]
进一步的,在将三个分支的预测结果在连接在一起之前,加入自适应层,建立领域自适应,使rs分别和r
d1
、r
d2
的特征分布更加接近,并计算rs和r
d1
的距离为d1,rs和r
d2
的距离为d2。
[0081]
正样本锚框挑选单元320,用于通过判断预测框的中心点是否包含于标注框内进行初步筛选,挑选出候选检测框,通过计算候选检测框和标注框之间的坐标损失以及类别损失选取每个标注框的正样本锚框。
[0082]
正样本锚框挑选单元320包括初步筛选单元321、成本函数获取单元322以及正样本锚框获取单元323。
[0083]
初步筛选单元321,用于获取预测框的中心点坐标,以及标注框的角点坐标,根据
角点坐标获取标注框的横坐标范围和纵坐标范围,当中心点坐标的横坐标包含于横坐标范围,并且中心点的纵坐标包含于纵坐标范围时,对应的预测框为标注框的候选检测框。
[0084]
获取预测框的中心点坐标(x
center
,y
center
),根据标注框的坐标[x
center
,y
center
,w,h]]计算标注框的左上角坐标(gt
l
,gt
t
),和右下角坐标(gtr,gtb),然后计算:b
l
=x
center-gt
l
,br=gt
r-x
center
,b
t
=y
center-gt
t
,bb=gt
b-y
center
。
[0085]
当b
l
和br大于0,说明预测框的中心点坐标的横坐标包含于横坐标范围,b
t
和bb大于0说明预测框的中心点坐标的横坐标包含于纵坐标范围,即预测框的中心点坐标在标注框内,此时提取该预测框作为候选检测框。
[0086]
成本函数获取单元322,用于通过计算候选检测框和标注框的交并比获取坐标损失,根据类别的条件概率和每个候选检测框的先验概率获取类别损失,以坐标损失和类别损失的加权求和作为候选检测框和标注框之间的成本函数。
[0087]
经过初步筛查,得到n个候选检测框,并记录每个候选检测框的信息(reg,obj,cls),通过计算候选检测框和标注框的交并比获取坐标损失reg_loss,具体的,通过iou算法得到选检测框和标注框的交并比iou,再进行torch.log计算得到坐标损失reg_loss。
[0088]
根据类别的条件概率和每个候选检测框的先验概率获取类别损失:令类别的条件概率和候选检测框的先验概率做乘积,得到候选检测框的类别分数,通过计算可得到标注框和候选检测框之间的类别损失cls_loss。
[0089]
将两个损失函数加权相加,计算cost成本函数,如下:
[0090][0091]
其中,i表示标注框的序号,j表示候选检测框的序号,c
ij
表示第j个候选检测框对第i个标注框的损失值,表示第j个候选检测框对第i个标注框的类别损失,表示第j个候选检测框对第i个标注框的坐标损失,λ表示平衡系数。
[0092]
作为一个示例,本发明实施例中平衡系数λ取3。
[0093]
正样本锚框获取单元323,用于获取每个标注框对应的n个最大的交并比的和,对该和取整作为正样本锚框的选取数量s,以成本函数最低的s个候选检测框作为正样本锚框。
[0094]
对于每个标注框,选取n个交并比最大的候选检测框,对选取的n个交并比求和并取整为s,在n个候选检测框中挑选成本函数最低的s个候选检测框作为正样本锚框。
[0095]
若两个标注框选择了同一个正样本锚框,则令cost成本函数值更低的标注框选择该正样本锚框。
[0096]
网络模型训练模块400,用于分别以单目标检测数据集和双目标检测数据集中一定比例的图像作为训练集,通过整合ciou loss和focal loss,得到focal-ciou loss作为标注框和正样本锚框之间的第一损失函数,将focal-ciou loss与标注框和正样本锚框之间的分类损失加权求和作为训练集的第二损失函数,直至第二损失函数收敛分别完成单目标网络模型和双目标网络的训练。
[0097]
具体的,网络模型训练模块400包括第二损失函数获取单元410和测试单元420。
[0098]
第二损失函数获取单元410,用于分别以单目标检测数据集和双目标检测数据集中一定比例的图像作为训练集,获取第二损失函数,直至第二损失函数收敛分别完成单目
标网络模型和双目标网络的训练。
[0099]
基于将正样本锚框纵横比拟合标注框的纵横比的影响考虑进入损失函数,同时为了实现把高质量的锚框和低质量的锚框分开从而尽可能地提升模型精度,本发明实施例在ciou的基础上,提出并使用一种新的iou损失公式:
[0100][0101]
其中,sa表示标注框的面积,sb表示正样本锚框的面积,γ表示可调参数,ρ表示欧氏距离,b表示正样本锚框的中心点,b
gt
表示标注框的中心点,c表示能够同时覆盖正样本锚框和标注框的最小矩形的对角线距离,α是用于做trade-off的参数,v是用来衡量长宽比一致性的参数。
[0102]
α的定义如下:
[0103][0104]
v定义如下:
[0105][0106]
其中,ω
gt
表示标注框的宽,h
gt
表示标注框的高,ω表示正样本锚框的宽,h表示正样本锚框的高。
[0107]
需要说明的是,经过实验表示γ=0.5时结果最好,因此本发明实施例中γ=0.5。
[0108]
获取前景和背景的第一分类损失obj_loss,以及进行开气孔、闭气孔的目标分类的第二分类损失cls_loss,在本发明实施例中两个分类损失都是采用bce_loss的方式获取的。
[0109]
将三个损失加权相加得到单目标loss1损失函数和双目标loss2损失函数,其中权重为超参数。再将rs和r
d1
的距离d1加入到loss1函数中,rs和r
d2
的距离d2加入到loss2函数中,计算每轮迭代的网络模型的loss1函数值和loss2函数值。
[0110]
作为一个示例,本发明实施例中focal-ciou loss的权重为0.5,前景和背景的第一分类损失obj_loss的权重为0.25,目标分类的第二分类损失cls_loss的权重为0.25。
[0111]
重复上述训练过程,本发明实施例设置迭代轮数(epoch)为300次,一次读入的光学显微镜图像量(batch-size)为8张,直至第二损失函数收敛分别完成单目标网络模型和双目标网络的训练。
[0112]
测试单元420,用于将单目标检测数据集和双目标检测数据集中除验证集以外剩余的图像作为对应的测试集,利用测试集对训练完成的网络模型进行检测,评估网络模型的输出结果。
[0113]
将单目标检测数据集和双目标检测数据集中除验证集以外剩余的图像作为对应的测试集,载入训练后的网络模型,对测试集中的图像进行气孔识别,获取气孔表型性状标注的实际情况。
[0114]
单目标检测数据集训练后的最佳模型对应的气孔表型性状标注的实际情况有:在模型检测过程中图像中的所有气孔是否均被框住、一个气孔周围是否被多个框框住、气孔
表型性状是否被完整且精确地框住。
[0115]
双目标数据集训练后的最佳模型对应的气孔表型性状标注的实际情况有:在模型检测的过程中气孔的分类是否正确、气孔是否均被完整框住、图像中的所有气孔是否都被框住且分类。
[0116]
气孔识别模块500,用于接收用户上传的图像数据;基于用户选择的识别模式,利用对应的训练完成的网络模型识别图像数据中的气孔特征并反馈给用户。
[0117]
具体的,包括图像接收单元510、气孔识别单元520以及人机交互单元530。
[0118]
图像接收单元510,用于接收用户上传的图像数据;图像数据为单张待检测图像,或者多张待检测图像,或者待检测视频。
[0119]
气孔识别单元520,用于基于用户选择的识别模式,利用对应的训练完成的网络模型识别图像数据中的气孔特征并反馈给用户,单目标网络识别的气孔特征至少包括气孔数量、气孔大小以及孔隙率;所述双目标网络识别的气孔特征至少包括气孔的开闭分类、开气孔率以及闭气孔率。
[0120]
基于用户选择的识别模式,选择使用单目标检测网络还是双目标检测网络进行气孔识别。
[0121]
当接收的图像数据为单张待检测图像时,对导入图片进行自动检测和识别,识别结果数据会显示在界面,点击保存按钮即可保存相应数据。
[0122]
当接收的图像数据为多张待检测图像时,导入检测图片所在的文件夹即可完成对文件夹中气孔图片的检测,以及气孔表型性状形态学处理计算,并显示批量处理后的全部植物气孔识别图像;保存处理后的气孔检测详细信息结果为excel格式文件。
[0123]
当接收的图像数据为待检测视频时,对视频中气孔状况进行实时识别与检测,完成后自动保存检测完成的视频结果,查看保存结果时检测效果实时显示。
[0124]
用户也可以自主选择保存的内容,例如保存检测结果图,保存气孔切割图,保存气孔excel数据。
[0125]
将检测识别后的各个气孔的详细信息以图像、excel文件的形式保存到相应位置,方便用户对植物图像中气孔性状的分析。
[0126]
人机交互单元530,用于将评估结果发送给用户,若用户不满意,则根据用户需求调整参数直至用户满意。
[0127]
若用户对气孔表型性状的检测与识别结果满意,则停止调整参数,保存数据;若不满意,则用户可以根据需要,调整气孔目标最小存在可能性(confidence),以及非极大值抑制的大小(nms),直至用户对识别结果满意。
[0128]
通过自定义参数功能最大限度地提高气孔自动检测与识别准确性和可扩展性,极大地提高了相关方向研究人员的气孔观测以及各方面表型数据的统计效率与准确度。
[0129]
进一步的,本发明实施例支持中英文切换。
[0130]
通过仿真实验对本发明实施例的系统进行进一步的展示,在如图2所示的界面中,包括设置参数、检测类型、语言以及关于系统,如图3所示,通过检测类型按钮选取识别模式,即进行单目标检测还是双目标检测,如图4所示通过设置参数实现人机交互,参数调整。
[0131]
在本次仿真实验中,将2000张双目标检测玉米气孔图形库的第二十五张图像000025.jpg作为用户选择并导入的待检测图像1,000001.jpg到000011.jpg作批量检测导
入的多张待检测图像组成的图像集2,双目标检测玉米气孔视频video.mp4作为视频检测功能中导入的待检测视频3。
[0132]
如图5所示的气孔检测界面中,点击右上侧“导入图片”按钮,选择待检测图像1,图像将导入并显示在最左侧,设置气孔置信度为0.5,点击“开始检测”,即可得到此图像检测与识别结果,识别结果图显示在导入图像的右侧,详细数据显示在右下方,包括气孔总数、孔隙率、开孔数量、开孔率、闭孔数量、闭孔率,显示和保存检测与识别后气孔性状的详细数据如图6、图7所示。
[0133]
在如图2所示的界面中,点击“批量检测”按钮,导入图像集2,检测过程如图8所示,保存处理后的气孔检测详细信息结果为excel文件如图9所示。
[0134]
在如图2所示的界面中,点击“视频检测”按钮,导入待检测视频3,实时检测过程如图10所示。
[0135]
在如图2所示的界面中,通过菜单栏的语言按钮对系统语言进行中英文切换,切换为英文的页面如图11和图12所示。
[0136]
综上所述,本发明实施例包括以下模块:
[0137]
数据采集模块100、迁移学习模块200、标签分类模块300、网络模型训练模块400以及气孔识别模块500。
[0138]
具体的,通过数据采集模块采集植物叶表皮图像,将叶表皮图像分为单目标检测数据集和双目标检测数据集;通过迁移学习模块在coco数据集上获取源领域,以采集的叶表皮图像作为目标领域,提取源领域和目标领域的共同特征,输出多张特征图;通过标签分类模块对每张特征图采用预测分支解耦结构,得到预测框信息,通过标签分配在预测框中挑选出每个标注框对应的正样本锚框;通过网络模型训练模块分别以单目标检测数据集和双目标检测数据集中一定比例的图像作为训练集,通过整合ciou loss和focal loss,得到focal-ciou loss作为标注框和正样本锚框之间的第一损失函数,将focal-ciou loss与标注框和正样本锚框之间的分类损失加权求和作为训练集的第二损失函数,直至第二损失函数收敛分别完成单目标网络模型和双目标网络的训练;通过气孔识别模块接收用户上传的图像数据;基于用户选择的识别模式,利用对应的训练完成的网络模型识别图像数据中的气孔特征并反馈给用户。本发明实施例能够确识别出植物叶表皮图像中的气孔,实现对植物气孔视频的实时检测和识别,因此可以研究植物叶片在整个生长阶段的气孔性状,可以探索植物对环境变化的反应机制,对植物气孔性状的研究具有重要意义,对智慧农业的发展起到积极的推动作用。
[0139]
需要说明的是:上述本发明实施例先后顺序仅仅为了描述,不代表实施例的优劣。且上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
[0140]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
[0141]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实
施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1