一种用于状态异常诊断的竞争聚类方法
1.本技术涉及数据挖掘技术领域,具体涉及大数据处理技术,尤其涉及一种用于状态异常诊断的竞争聚类方法。
背景技术:
2.聚类分析是数据挖掘领域最为常见的技术之一,用于发现数据集中未知的对象类。聚类分析在客户细分、模式识别、医疗决策、异常检测等诸多领域有着广泛的应用前景。传统的聚类算法能够很好地处理均衡数据的聚类问题,但是现实生活中存在许多不均衡数据,例如医疗诊断、故障诊断等领域的数据中表现正常的数据量要远远大于表现异常的数据量。这类不均衡数据集的特点是同一数据集中归属于某一类别的数据对象的数量和密度与其他类别数据对象的数量和密度有较大差异,通常数据对象数量较多的类称之为大类,数据对象数量较少的类称之为小类。目前的聚类方法主要反映均衡样本类的聚类特征,而异常(或故障)的小样本类常常被忽略,又或者习惯于将大类中的部分对象划分到小类中,从而使获得的类拥有相对均匀的尺度,这限制了基于数据样本聚类特征的应用。
3.为了解决不均衡数据的聚类问题,学者们从不同角度提出了多种方法,包括数据预处理、多中心点及优化目标函数这三大类方法。第一类方法是数据预处理,此类方法对数据集进行欠采样和过采样处理后再进行聚类,但是欠采样方法仅仅采用了属于大类中的一部分具有代表性的子集,导致大类中大量的有效信息被忽略,影响了聚类效果;过采样方法通过增加小类中对象数量来进行数据分析,使原有数据集达到均衡状态,但这样做一方面可能会导致过拟合,另一方面也可能给数据集带来噪声。
4.第二类方法是多中心点的方法,此类方法基于多中心的角度解决模糊聚类算法的“均匀效应”问题,其思想是用多个类中心代替单个类中心代表一个类,在某些情况下,借助该思想,模糊聚类算法在迭代过程中根据距离“中心”最近的原则,能够让部分被错分到小类中的数据对象校正回大类中,具有一定的有效性和可行性。但此类方法对于一些大类分布极其不均匀的不均衡数据聚类问题,不能全面地反映数据分布特征,导致算法的有效性降低。
5.第三类方法是优化目标函数的方法,此类方法从目标函数优化的角度提出新的算法,通过推导出相应的聚类优化目标函数,以解决“均匀效应”问题。这类方法从目标函数直接切入,相比于之前的聚类算法是一种较为直接的新方法且有一定的实用性,但是此类方法一般涉及目标函数参数的求解,属于非线性函数优化问题,难以得到全局最优解,这决定了该类算法的聚类结果具有相对较大的随机性,影响算法的聚类精度。
6.目前,还没有一种既可以自动计算类簇个数,同时有效保留异常(或故障)的小样本类的有效聚类方法。
技术实现要素:
7.本技术提供了一种用于状态异常诊断的竞争聚类方法,其技术目的是有效保留异
常(或故障)的小样本类,同时实现自动计算类簇个数,提高聚类性能。
8.本技术的上述技术目的是通过以下技术方案得以实现的:
9.一种用于状态异常诊断的竞争聚类方法,包括:
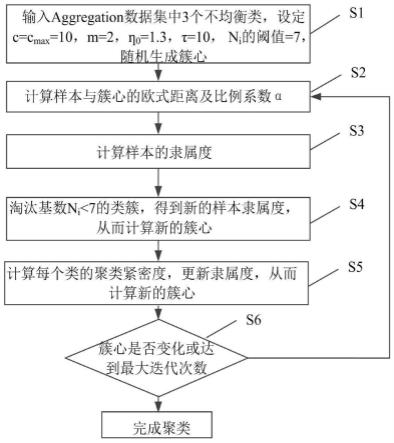
10.s1:输入数据集u,设定初始类簇个数c=c
max
,确定模糊加权指数m、初始值η0、迭代次数常数τ和类簇的基数阈值n,并随机生成第一簇心集合v1,通过模糊c均值聚类算法获取数据集u的初始样本隶属度;其中,u={xj|j=1,...,n},xj表示数据集u中的样本,xj∈u,n表示u的样本总数;v1={vi|i=1,...,c},c表示数据集u的簇心总数,vi表示第i类类簇的簇心;
11.s2:计算样本xj与簇心vi的欧式距离,根据所述欧氏距离和所述初始样本隶属度得到比例系数α,根据欧氏距离和比例系数α构建竞争聚类算法的目标函数;
12.s3:通过所述目标函数计算获得样本隶属度;
13.s4:计算第i类类簇的基数ni,若ni小于基数阈值n,则淘汰该类类簇,得到留下类簇对应的样本隶属度与第二簇心集合v2';
14.s5:根据样本隶属度和第二簇心集合v2'计算每个类簇的聚类紧密度ci,然后根据聚类紧密度ci对样本隶属度和簇心进行更新,得到本轮迭代的最终样本隶属度和第二簇心集合v2。
15.s6:当簇心位置不再发生变化或达到最大迭代次数时,则输出最终结果,完成聚类;否则重复步骤s2至s5。
16.进一步地,所述步骤s2中,根据所述欧式距离和所述初始样本隶属度得到比例系数α,表示为:
[0017][0018]
η(k)=η0exp(-k/τ);
[0019]
其中,表示样本xj到簇心vi的距离,即欧式距离;u
ij
表示第j个样本属于第i个类簇的隶属度;m表示模糊加权指数,取2;k表示迭代次数;
[0020]
则所述目标函数表示为:
[0021][0022][0023]
进一步地,所述步骤s3中,通过所述目标函数使用拉格朗日乘子法对样本隶属度进行计算获得样本隶属度,表示为:
[0024][0025][0026][0027]
进一步地,所述步骤s5中,每个类簇的聚类紧密度ci表示为:
[0028][0029]
其中,
[0030]
中ti={xj|u
ij
>u
lj
;l=1,2,
···
,c;l≠i};
[0031]
ηj=||x
j-vi||;
[0032][0033]
ti表示划分为第i类类簇的样本集合;|ti|表示第i类类簇样本集合的个数;ηj表示样本xj的滤波值;ui表示第i类类簇样本集合与簇心vi距离的平均值。
[0034]
进一步地,所述步骤s5中,根据聚类紧密度ci对样本隶属度和簇心进行更新,表示为:
[0035][0036][0037][0038][0039]
其中,fi表示分配给第i类类簇的系数;si为归一化后第i类类簇的紧密度,s
min
为si中的最小值。
[0040]
本技术的有益效果在于:在已实现了自动计算类簇个数的基础上,通过改进竞争聚类算法的目标函数使得样本容量在聚类代价函数中发挥效用从而弱化了样本容量差异对聚类判决的干扰,得到新的隶属度计算方法,使其能自适应地调整对大类与小类的隶属
度,从而改善算法处理不均衡数据集的聚类效果,有效保留了异常(或故障)的小样本类,同时又同时实现了自动计算类簇个数,提高了聚类的性能,拓展了基于数据样本聚类特征的应用。
附图说明
[0041]
图1为本技术所述方法的流程图;
[0042]
图2为本技术实施例的聚类结果与其他聚类算法的对比示意图。
具体实施方式
[0043]
下面将结合附图对本技术技术方案进行详细说明。
[0044]
图1为本技术所述方法的流程图,一种用于状态异常诊断的竞争聚类方法,选取uci标准数据集的aggregation数据集中3个不均衡类作为本发明验证的数据集u,该方法包括以下步骤:
[0045]
s1:输入数据集u,设定初始类簇个数c=c
max
=10,确定模糊加权指数m=2、初始值η0=1.3、迭代次数常数τ=10和类簇的基数阈值n=7,并随机生成c
max
个簇心,通过模糊c均值聚类算法获取数据集u的初始样本隶属度。
[0046]
s2:计算样本xj与簇心vi的欧式距离,根据欧式距离和初始样本隶属度得到比例系数α,根据欧氏距离和比例系数α构建竞争聚类算法的目标函数。
[0047]
欧式距离d
ij
的计算表示为:
[0048][0049]
其中,表示样本xj到簇心vi的距离,即欧式距离;p表示xj的维度。
[0050]
再根据得到的d
ij
和u
ij
计算比例系数α,表示为:
[0051][0052]
η(k)=η0exp(-k/τ)。
[0053]
最后目标函数表示为:
[0054][0055][0056]
其中,u
ij
表示第j个样本属于第i个聚类的隶属度;m表示模糊加权指数,取2;k表示迭代次数。
[0057]
s3:通过所述目标函数计算样本隶属度。
[0058]
具体地,计算样本隶属度表示为:
[0059][0060]
其中,表示第i类类簇的基数。
[0061]
s4:计算每个类簇的基数ni,若ni小于基数阈值7,则淘汰该类类簇,得到留下类簇对应的样本隶属度与第二簇心集合v2'。
[0062]
s5:在考虑类的大小对目标函数的影响外,还须注意到每一类的样本分布对于聚类结果的影响。本技术给出一种聚类紧密度ci的计算公式用来衡量类别中样本的分布状态,从而得到本轮迭代的最终样本隶属度和第二簇心集合v2,ci的计算公式表示为:
[0063][0064]
其中,
[0065]
中ti={xj|u
ij
>u
lj
;l=1,2,
···
,c;l≠i};
[0066]
ηj=||x
j-vi||;
[0067][0068]
ti表示划分为第i类类簇的样本集合;|ti|表示第i类类簇样本集合的个数;ηj表示样本xj的滤波值;μi表示第i类类簇样本集合与簇心vi距离的平均值。
[0069]
由聚类紧密度公式可以看出:ci的值越小,表明该类越集中,紧密度越高;反之则表明该类越分散,紧密度越低。
[0070]
根据聚类紧密度ci对样本隶属度和簇心进行更新,表示为:
[0071][0072][0073][0074][0075]
其中,fi表示分配给第i类类簇的系数;si为归一化后第i类类簇的紧密度,s
min
为si中的最小值。
[0076]
s6:簇与簇之间竞争,簇心个数逐渐减少达到稳定,当簇心位置不再发生变化或达到迭代次数时,则输出最终结果,完成聚类;否则重复步骤s2至s5。
[0077]
选择模糊c均值聚类算法和竞争聚类算法作为比较算法,其中竞争聚类算法是从模糊c均值聚类算法的基础上演变过来的,其优势在于能够自动计算类簇个数,而模糊c均值聚类算法需要提前设置集群的数量。为了公平起见,我们以可用于状态异常(小样本)诊断的竞争聚类方法获得的簇数作为模糊c均值聚类算法的前提。对于竞争聚类算法,设置η0=4,其它参数设置与可用于状态异常(小样本)诊断的竞争聚类方法相同。
[0078]
图2是此三种聚类算法在同一数据集下的聚类结果比较,中心的位置显示为叠加在数据集上的“+”符号,同时圈出最终的类簇,图2中(a)是本技术所验证的数据集。从图2中(b)可以看到,模糊c均值聚类算法在初始设定3个类簇的基础上,均分了3个类,说明此算法不能有效识别大小类间的差异性;从图2中(c)中看到,竞争聚类算法依旧解决不了模糊c均值聚类算法均分各个类的缺点,并且又由于此算法特有的竞争机制自动忽略了右小角的小类,将3个类错误分成了2个类,而故障点通常类似于这些小类,说明此算法有些情况下不能有效识别故障类。图2中(d)为本技术提出的可用于状态异常(小样本)诊断的竞争聚类方法应用于数据集的聚类结果,可以看到,三个数量密度差异较大的类被正确地分出,说明此算法有能有效识别故障类,同时又可以自动计算类簇个数。
[0079]
本技术通过对传统的隶属度计算方法进行改进,让其能自适应地调整对大类与小类的隶属度,有效保留了异常(或故障)的小样本类,改善了算法处理不均衡数据集的聚类效果。
[0080]
以上所述的实施例仅用以说明本发明的技术方案,而并不是对其限制;本发明属于技本领域的普技术人员依然可以对前述各实施例所记描述的技术方案进行修,或者对其中部分技术特征进行等同替换,只要不偏离本发明的结构或者超越本权利要求书多定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1