一种基于敏感度模型的分组混合精度配置方案搜索方法
1.本发明涉及浮点程序的性能优化技术领域,尤其涉及一种基于敏感度模型的分组混合精度配置方案搜索方法。
背景技术:
2.涉及混合精度的技术中,主要使用基于差异化调试的算法搜索不同的精度配置方案,此类方法暴力搜索可能的精度配置方案,未考虑程序中浮点变量之间存在的关系,所以存在以下问题:
3.1、搜索精度配置方案方法在最坏情况下需要较长的搜索时间,无法快速找到有效的精度配置方案。
4.2、未考虑浮点变量间相互关系,生成的混合精度程序中有较多的精度转换开销,存在进一步的性能提升空间。
技术实现要素:
5.本发明针对搜索精度配置方案方法在最坏情况下需要较长的搜索时间,无法快速找到有效的精度配置方案;未考虑浮点变量间相互关系,生成的混合精度程序中有较多的精度转换开销,存在进一步的性能提升空间的问题,提出一种基于敏感度模型的分组混合精度配置方案搜索方法。
6.为了实现上述目的,本发明采用以下技术方案:
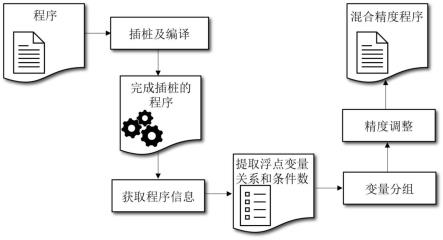
7.一种基于敏感度模型的分组混合精度配置方案搜索方法,包括:
8.步骤1,利用程序插桩完成浮点变量关系提取,量化变量之间的计算次数和计算关系,并将该关系抽象为图表示,得到浮点变量关系图,图中顶点对应各个浮点变量,边代表两个浮点变量有直接的运算关系,边的权值代表两个浮点变量计算了多少次;
9.步骤2,采用社区划分算法对得到的浮点变量关系图进行子图划分,从而将具有强关联的浮点变量分入同一组内;
10.步骤3,计算得出浮点变量的条件数,将其定义为敏感度,并将每一组的敏感度设置为该组中对结果影响最大的浮点变量的敏感度大小,然后采取每一组敏感度从小到大的排序方法进行组间排序;
11.步骤4,进行精度调整,优先降低敏感度最小的变量组内浮点变量的精度,从而在保证精度转换开销尽可能低的同时,获取更高的性能提升。
12.进一步地,所述步骤1包括:
13.步骤1.1,提取浮点计算程序中的函数名称,包括:在提取变量时同时将其所在的函数名称给予标识,对于浮点计算程序中模块m的任一函数,如果该函数不是外部声明函数,则存储该函数名称为后续提取关系使用;
14.步骤1.2,利用基于ssa的def-use链获取浮点计算程序中的数值依赖关系;
15.步骤1.3,提取浮点计算程序中的数值计算关系;
16.步骤1.4,基于步骤1.1至步骤1.3,得到含有函数名称的变量关系表;
17.步骤1.5,将非浮点运算的变量从变量关系表中删除,得到程序中浮点变量之间的运算关系;
18.步骤1.6,采用针对基本块的插桩方法实现对指令执行次数的追踪,得到变量之间的运算次数;
19.步骤1.7,将该关系抽象为图表示,得到浮点变量关系图,图中顶点对应各个浮点变量,边代表两个浮点变量有直接的运算关系,边的权值代表两个浮点变量计算了多少次。
20.进一步地,所述步骤1.2包括:
21.步骤1.2.1,遍历当前函数f的指令,将其中的store指令存储至storequeue队列;
22.步骤1.2.2,若storequeue非空,将队首元素instruction出队列,并将其存储至队列dqueue,进行下一步的指令流分析;若storequeue为空,则流程结束;
23.步骤1.2.3,将dqueue队首元素出队列,并分析该指令对应的def-use链,若对应的指令vi的操作码为load,则vi和instruction对应一组数值关系依赖;若对应的指令vi的操作码不是load,则将vi存储至队列dqueue的队尾;
24.步骤1.2.4,若dqueue不为空,则继续进行步骤1.2.3;若dqueue为空,则进行步骤1.2.2。
25.进一步地,所述步骤1.3包括:
26.限制参与运算的的变量数目不能超过两个,找到store指令中存储的操作数,然后找出对应的运算指令中的虚拟寄存器,最后根据虚拟寄存器找到两条load指令即可得出数值计算关系。
27.进一步地,所述步骤1.5包括:
28.将store指令与load指令成对存储,在进行浮点变量类型判定时,当从load指令和store指令中获取的操作数都属于浮点类型时不过滤该指令对,否则过滤该指令对。
29.进一步地,所述步骤1.6包括:
30.使用llvm ir生成器实现对基本块的指令插桩,通过irbuilder在步骤1.5处理后的每个基本块的第一条load指令前插桩调用函数calculateedge指令,通过插桩调用该函数的指令完成运算次数的记录,重新编译ir为可执行文件,然后执行该文件获取插桩后的程序运行结果,统计程序中数值依赖关系和数值计算关系的变量对数。
31.进一步地,所述步骤2包括:
32.通过louvain算法对浮点变量关系图中节点进行分类。
33.与现有技术相比,本发明具有的有益效果:
34.1、本发明通过计算得出浮点变量的条件数,并将其定义为敏感度,以此来量化程序中浮点变量精度改变后对结果的影响大小,通过降低对结果影响最小的浮点变量精度的方法,使精度搜索空间大大减少,从而快速的找到有效的混合精度配置方案。
35.2、本发明将程序中浮点变量以及变量之间的运算次数抽象为图,而后利用子图划分算法将运算次数较多的浮点变量分入同一组,在精度调整时保证同组内浮点变量精度保持一致,从而减少精度转换开销,提升程序性能。
附图说明
36.图1为本发明实施例一种基于敏感度模型的分组混合精度配置方案搜索方法的流程示意图;
37.图2为本发明实施例以基本块为单位的程序控制流图分析示例图;
38.图3为本发明实施例sin(pi*x)在区间[0,1]的微分计算;
[0039]
图4为本发明实施例浮点变量关系图示例。
具体实施方式
[0040]
下面结合附图和具体的实施例对本发明做进一步的解释说明:
[0041]
如图1所示,一种基于敏感度模型的分组混合精度配置方案搜索方法,包括:
[0042]
步骤1,利用程序插桩完成浮点变量关系提取,量化变量之间的计算次数和计算关系,并将该关系抽象为图表示,得到浮点变量关系图,图中顶点对应各个浮点变量,边代表两个浮点变量有直接的运算关系,边的权值代表两个浮点变量计算了多少次;
[0043]
步骤2,采用社区划分算法对得到的浮点变量关系图进行子图划分,从而将具有强关联的浮点变量分入同一组内;
[0044]
步骤3,计算得出浮点变量的条件数,将其定义为敏感度,并将每一组的敏感度设置为该组中对结果影响最大的浮点变量的敏感度大小,然后采取每一组敏感度从小到大的排序方法进行组间排序;
[0045]
步骤4,进行精度调整,优先降低条件数最小的变量组内浮点变量的精度,从而在保证精度转换开销尽可能低的同时,获取更高的性能提升。
[0046]
进一步地,所述步骤1包括:
[0047]
步骤1.1,提取浮点计算程序中的函数名称,包括:在提取变量时同时将其所在的函数名称给予标识,对于浮点计算程序中模块m的任一函数,如果该函数不是外部声明函数,则存储该函数名称为后续提取关系使用;
[0048]
步骤1.2,利用基于ssa的def-use链获取浮点计算程序中的数值依赖关系;
[0049]
步骤1.3,提取浮点计算程序中的数值计算关系;
[0050]
步骤1.4,基于步骤1.1至步骤1.3,得到含有函数名称的变量关系表;
[0051]
步骤1.5,将非浮点运算的变量从变量关系表中删除,得到程序中浮点变量之间的运算关系;
[0052]
步骤1.6,采用针对基本块的插桩方法实现对指令执行次数的追踪,得到变量之间的运算次数;
[0053]
步骤1.7,将该关系抽象为图表示,得到浮点变量关系图,图中顶点对应各个浮点变量,边代表两个浮点变量有直接的运算关系,边的权值代表两个浮点变量计算了多少次。
[0054]
具体地,所述步骤1.1包括:
[0055]
对于给定浮点计算程序,不同函数之间的变量名称可能出现重复,若忽略函数名称,分析变量间关系时容易产生混淆,无法分辨浮点变量具体属于哪一个函数。因此在提取变量时应同时将其所在的函数名称给予标识,首先设计实现提取程序名称算法,方便联系函数内的浮点变量与函数名称。算法1给出提取程序中函数的具体描述。
[0056][0057]
进一步地,获取函数后,需要分析每个函数中的浮点变量关系,首先利用基于ssa的def-use链获取数值计算依赖关系。
[0058]
[0059][0060]
具体地,所述步骤1.2(即算法2)包括:
[0061]
步骤1.2.1,遍历当前函数f的指令,将其中的store指令存储至storequeue队列;
[0062]
步骤1.2.2,若storequeue非空,将队首元素instruction出队列,并将其存储至队列dqueue,进行下一步的指令流分析;若storequeue为空,则流程结束;
[0063]
步骤1.2.3,将dqueue队首元素出队列,并分析该指令对应的def-use链,若对应的指令vi的操作码为load,则vi和instruction对应一组数值关系依赖;若对应的指令vi的操作码不是load,则将vi存储至队列dqueue的队尾;
[0064]
步骤1.2.4,若dqueue不为空,则继续进行步骤1.2.3;若dqueue为空,则进行步骤1.2.2。
[0065]
进一步地,所述步骤1.3包括:
[0066]
限制参与运算的的变量数目不能超过两个,找到store指令中存储的操作数,然后找出对应的运算指令中的虚拟寄存器,最后根据虚拟寄存器找到两条load指令即可得出数值计算关系。
[0067]
具体地,除数值依赖关系外,程序中还存在着数值计算关系,如double c=a+b,若变量a和变量b精度不一致同样会产生精度转换开销,因此需要分析提取程序中存在的数值计算关系。算法3给出提取计算关系的算法,主要修改算法2中17行if结构内的代码,因此算法3中只给出修改部分的算法示例。
[0068][0069]
算法3限制参与运算的变量数目不能超过两个,即若有a=b+c+d,则需要改写为a0=b+c,a=a0+d。根据指令流分析,只需找到store指令中存储的操作数,然后找出对应的运算指令如add指令中的虚拟寄存器,最后根据虚拟寄存器找到两条load指令即可找出数值计算关系。对于c=a+b,可得出数值计算关系《a,b》。
[0070]
进一步地,所述步骤1.5包括:
[0071]
将store指令与load指令成对存储,在进行浮点变量类型判定时,当从load指令和store指令中获取的操作数都属于浮点类型时不过滤该指令对,否则过滤该指令对。
[0072]
具体地,在完成函数名称提取和浮变量数值分析之后,可以得到含有函数名称的变量关系表,但由于浮点计算程序中不仅仅有浮点变量,还有整型以及其他数据类型的运算,因此需要将非浮点运算的变量如整型数据从变量关系表中删除,因此需要对上述pass收集到的指令中的操作数类型进行分析。由于存在部分浮点计算程序将浮点计算的结果存储为整型数据,因此在计算数值依赖关系时需要将load指令中的操作数和store指令中的操作数类型全部考虑在内。
[0073]
算法4过滤非浮点类型变量的算法示例。数值分析算法中将store指令与load指令成对存储,在进行浮点变量类型判定时load和store中获取的操作数都是浮点类型时不过滤数值关系对,否则过滤该指令对。
[0074][0075]
至此就完成了浮点变量的数值分析全过程,得出程序中存在数值依赖的浮点变量对以及存在数值计算的浮点变量对。
[0076]
进一步地,所述步骤1.6包括:
[0077]
使用llvm ir生成器实现对基本块的指令插桩,通过irbuilder在步骤1.5处理后的每个基本块的第一条load指令前插桩调用函数calculateedge指令,通过插桩调用该函数的指令完成运算次数的记录,重新编译ir为可执行文件,然后执行该文件获取插桩后的程序运行结果,统计程序中数值依赖关系和数值计算关系的变量对数。
[0078]
具体地,程序执行时,发生浮点变量精度不匹配时会产生精度转换开销,当产生精度转换开销的语句多次执行时,会对应用程序的性能产生很大的影响。因此进行变量分组时不仅仅需要考虑程序内浮点变量的数值关系,运算次数也是非常重要的参考量。
[0079]
绝大多数浮点计算程序中循环结构和分支结构是必不可少的部分,因此只计算数值分析提取的指令对数不能够正确的反映变量间的运算次数,因此可以通过插桩实现对指令执行次数的追踪。ir在内存中是以多条顺序执行的指令序列构成的基本块(basicblock)为单位组成的,一个函数则有一个或多个基本块构成。由于基本块中不存在条件结构和循环结构,一次执行过程中基本块内的指令执行次数不大于一次,因此选用针对基本块的插桩方法,图2给出示例程序以及其基本块的划分示意,根据该示例阐述提取变量运算次数流程的实现方法。
[0080]
以示例程序中for循环内z=x+y为例,该语句位于该图2中右图for.body基本块内,该基本块内共有两对浮点依赖关系以及一对浮点计算关系。通过图中可以看出在基本块的末尾出现跳转指令,同一基本块内的指令执行次数是相同的,因此在以基本块为基本
分析单位时可以减少插桩量,每个模块中只需插桩一条计算运行次数的指令即可。本方法使用llvm ir生成器(irbuilder《》)实现对基本块的指令插桩,默认情况下指令插入位置为初始化irbuilder的指令的上方,处理算法如下表所示。通过irbuilder在数值分析pass筛选后的每个基本块的第一条load指令前插桩调用函数calculateedge指令,该基本块每执行一次,函数就同样执行一次,函数内记录该基本块的所有具有依赖关系和计算关系的浮点变量对的运算次数就加1,通过插桩调用该函数的指令完成运算次数的记录。完成插桩pass的执行后需要重新编译ir为可执行文件,然后执行该文件获取插桩后的程序运行结果,统计程序中数值依赖关系和数值计算关系的变量对数。
[0081][0082][0083]
进一步地,得出变量之间的运算关系和运算次数之后,将该关系抽象为图表示,得到浮点变量关系图,图中顶点对应各个浮点变量,边代表两个浮点变量有直接的运算关系,边的权值代表两个浮点变量计算了多少次。图3、图4给出了具体的分组示例程序以及浮点变量关系图。
[0084]
进一步地,所述步骤2包括:
[0085]
通过louvain算法对浮点变量关系图中节点进行分类。
[0086]
具体地,通过louvain算法对图4中节点进行分类,选择顶点s1时,将其划入邻居节点x的社区内,此时δq》0,随后判断将s1分别加入h,b,pi所在的社区内,相比较顶点x而言模块度增长都较小,因此应将浮点变量s1和x分入同一个社区,运算若干次以后,产生了三个稳定的社区,顶点x,s1,h为一个社区,顶点pi,xarg,result一个社区,顶点a,b一个社区,后续的精度调整将在一个社区内的浮点变量统一考虑,从而减少精度搜索空间。
[0087]
具体地,所述步骤3中,条件数通过自动微分(可采用libtorch工具)计算导数后带入条件数公式完成计算,条件数公式具体参见https://damingz.github.io/papers/popl20.pdf。
[0088]
进一步地,本发明方法可描述如下:
[0089][0090][0091]
给定一个源程序,算法6首先判断较低的精度能否满足误差阈值需求,若能够满足误差需求,则后续步骤无需执行,直接输出低精度版本的即可,在降低所有浮点变量精度不能够满足误差阈值需求时,则需要使用分组方法进行精度调整。通过基于llvm的数值分析得出浮点变量关系图g(v,e,w),其中,v表示浮点变量关系图的顶点集合,图中顶点对应各个浮点变量;e表示浮点变量关系图的边集合,边代表两个浮点变量有直接的运算关系;w表示浮点变量关系图的边的权值集合,边的权值代表两个浮点变量计算了多少次。通过调用community包对图g进行社区划分,将分配好的社区方案存入comlist[][]数组中,随后计算得出浮点变量的条件数,将其定义为敏感度,并将每个分组的敏感度设置为当前分组中浮点变量的最大敏感度,并依据该大小对分组进行排序。最后按照条件数(敏感度)从小到大的方式挨个对分组内的变量调整精度,首先降低敏感度最低的分组,而后判断分组方案能否满足误差阈值需求,若能够满足误差阈值需求,则继续修改下一个分组的精度,若不能够满足阈值需求,证明后续再进行调整也不能够满足误差阈值需求,则将本次修改的变量精度复原,结束本次精度调整。
[0092]
若浮点变量精度从长双精度起始,需要长双精度,双精度,单精度三种精度混合,
则需要按照该算法先将部分变长双精度降低至双精度完成一次精度调整过程,而后在此使用该算法调整部分已经是双精度的浮点变量至单精度,共需使用两次该算法进行精度调整。
[0093]
综上,本发明通过计算得出浮点变量的条件数,并将其定义为敏感度,以此来量化程序中浮点变量精度改变后对结果的影响大小,通过降低对结果影响最小的浮点变量精度的方法,使精度搜索空间大大减少,从而快速的找到有效的混合精度配置方案。本发明将程序中浮点变量以及变量之间的运算次数抽象为图,而后利用子图划分算法将运算次数较多的浮点变量分入同一组,在精度调整时保证同组内浮点变量精度保持一致,从而减少精度转换开销,提升程序性能。
[0094]
以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1