一种多智能体强化学习方法及相关装置与流程
本技术涉及人工智能(artificial intelligence,ai),尤其涉及一种多智能体强化学习及相关装置。
背景技术:
1、人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
2、强化学习是近年来人工智能备受关注的方向之一。随着强化学习的快速发展和应用,强化学习已经在机器人控制、游戏博弈、无人驾驶等领域被广泛应用。目前,强化学习算法大都应用于单智能体场景。在单智能体场景中,智能体所在的环境是稳定不变的。但在多智能体场景中,环境是动态且复杂的,且每个智能体的动作都会对其他智能体的动作选择造成影响,因此多智能体强化学习存在环境不稳定以及维度爆炸等问题。由于在多智能体强化学习过程中,每个智能体执行动作前都需要考虑其他智能体的状态,从而使得智能体网络在训练过程中难以实现收敛,进而导致训练效率较低。
3、因此,目前亟需一种能够提高多智能体强化学习的效率的方法。
技术实现思路
1、本技术提供了一种多智能体强化学习方法,能够提高智能体网络的收敛效率,从而提高多智能体强化学习的效率。
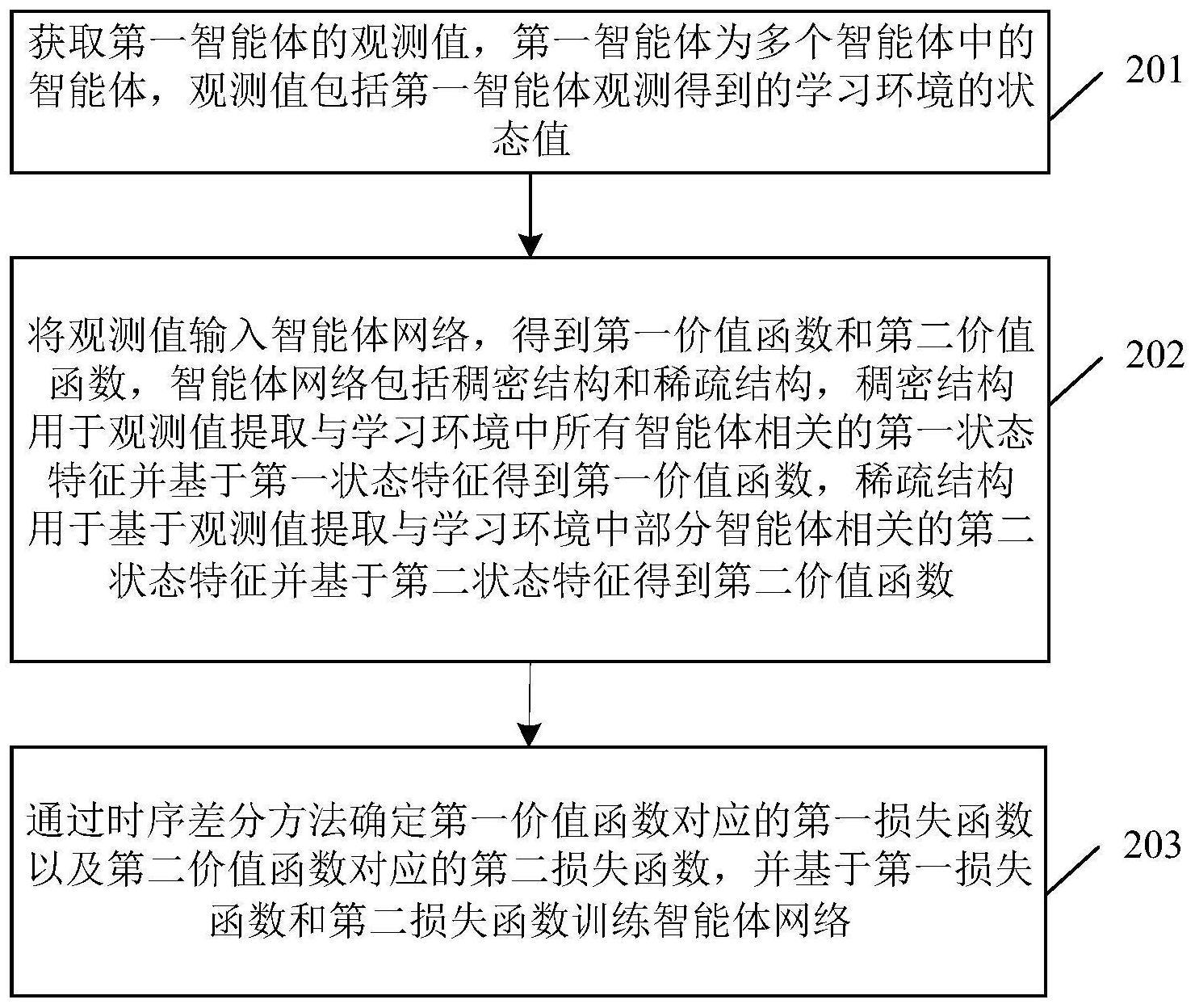
2、本技术第一方面提供一种多智能体强化学习方法,所述方法应用于包括多个智能体的学习环境。具体地,多智能体强化学习方法包括:首先,获取第一智能体的观测值,所述第一智能体为所述多个智能体中的智能体,所述观测值包括所述第一智能体观测得到的所述学习环境的状态值。例如,在第一智能体为智能车辆的情况下,第一智能体的观测值可以为第一智能体观测得到的道路环境中其他智能车辆的运动状态。
3、然后,将所述观测值输入智能体网络,得到第一价值函数和第二价值函数,所述智能体网络包括并行的稠密结构和稀疏结构,所述稠密结构用于基于所述观测值提取与所述学习环境中所有智能体相关的第一状态特征并基于所述第一状态特征得到所述第一价值函数,所述稀疏结构用于基于所述观测值提取与所述学习环境中部分智能体相关的第二状态特征并基于所述第二状态特征得到所述第二价值函数。
4、最后,通过时序差分方法确定所述第一价值函数对应的第一损失函数以及所述第二价值函数对应的第二损失函数,并基于所述第一损失函数和所述第二损失函数训练所述智能体网络。
5、本方案中,通过在智能体网络中引入并行的稠密结构和稀疏结构,基于稀疏结构来使得第一智能体只关注部分智能体,从而忽略部分对第一智能体无关的信息,提高智能体网络的收敛效率;并且,基于稠密结构来使得第一智能体能够有侧重地关注第一智能体之外所有智能体,保证智能体网络能够在训练过程中实现有效收敛。基于并行的稠密结构和稀疏结构,在保证智能体网络能够实现有效收敛的同时,提高智能体网络的收敛效率,从而提高多智能体强化学习的效率。
6、在一种可能的实现方式中,所述稠密结构用于基于稠密注意力机制以及所述观测值提取得到所述第一状态特征,所述稀疏结构用于基于稀疏注意力机制以及所述观测值提取得到所述第二状态特征。
7、在一种可能的实现方式中,所述第一价值函数用于指示所述第一智能体在所述第一状态特征下选择不同动作所带来的价值,所述第二价值函数用于指示所述第一智能体在所述第二状态特征下选择不同动作所带来的价值。
8、本方案中,基于第一价值函数和第二价值函数,能够预测智能体网络分别在第一状态特征和第二状态特征下选择执行各种动作时所带来的价值,从而指导智能体网络后续选择相应的执行动作。
9、在一种可能的实现方式中,所述通过时序差分方法确定所述第一价值函数对应的第一损失函数以及所述第二价值函数对应的第二损失函数,包括:根据所述第一价值函数和预置策略,从所述第一价值函数所指示的多个动作中选择第一动作并确定所述第一动作对应的第一价值;获取执行所述第一动作后的状态所对应的第二价值,并根据所述第一价值和所述第二价值确定所述第一损失函数;根据所述第二价值函数和所述预置策略,从所述第二价值函数所指示的多个动作中选择第二动作并确定所述第二动作对应的第三价值;获取执行所述第二动作后的状态所对应的第四价值,并根据所述第三价值和所述第四价值确定所述第二损失函数。
10、本实施例中,基于时序差分方法来构造用于训练智能体网络的损失函数,能够很好地评价智能体网络的收敛情况,进而有效地实现智能体网络的训练。
11、在一种可能的实现方式中,所述预置策略包括贪心策略或∈-贪心策略,其中所述贪心策略用于选择价值最高的动作,所述∈-贪心策略用于基于第一概率选择价值最高的动作以及基于第二概率选择所述价值最高的动作以外的其他动作。
12、本方案中,基于∈-贪心策略来实现价值函数对应的动作的选择,能够在强化学习过程中实现开发与探索之间的平衡,从而使得智能体网络能够实现快速收敛。
13、在一种可能的实现方式中,所述第一概率与所述智能体网络的训练次数具有正相关关系,所述第二概率与所述智能体网络的训练次数具有负相关关系。
14、在一种可能的实现方式中,所述智能体网络还包括循环神经网络,所述循环神经网络用于对所述观测值以及所述智能体所执行的历史动作进行编码,以得到编码特征;所述第一价值函数是基于所述第一状态特征和所述编码特征得到的,所述第二价值函数是基于所述第二状态特征和所述编码特征得到的。
15、本方案中,通过在智能体网络中引入循环神经网络,能够便于智能体网络记忆历史状态和动作信息,从而指导智能体网络更准确地输出价值函数。
16、在一种可能的实现方式中,所述基于所述第一损失函数和所述第二损失函数训练所述智能体网络,包括:获取所述多个智能体中其他智能体对应的稠密损失函数,并通过第一混合网络对所述第一损失函数和所述稠密损失函数进行混合处理,得到稠密混合损失函数,所述稠密损失函数是基于稠密注意力机制得到的;获取所述多个智能体中其他智能体对应的稀疏损失函数,并通过第二混合网络对所述第二损失函数和所述稀疏损失函数进行混合处理,得到稀疏混合损失函数,所述稀疏损失函数是基于稀疏注意力机制得到的;基于所述稠密混合损失函数和所述稀疏混合损失函数训练所述智能体网络。
17、本方案中,在智能体网络的训练过程中是多个智能体网络混合后的损失函数来进行训练,从而保证每个智能体网络的训练目标是使得多个智能体的总体决策是最优的。
18、在一种可能的实现方式中,在所述智能体网络训练完毕后,所述智能体网络中的所述稠密结构用于执行推理智能体动作的任务,且所述智能体网络中的所述稀疏结构不用于执行所述任务。
19、在一种可能的实现方式中,所述学习环境包括自动驾驶环境、机器人协同作业环境或多角色互动游戏环境。
20、本技术第二方面提供一种多智能体强化学习装置,所述装置应用于包括多个智能体的学习环境,所述装置包括:获取单元,用于获取第一智能体的观测值,所述第一智能体为所述多个智能体中的智能体,所述观测值包括所述第一智能体观测得到的所述学习环境的状态值;处理单元,用于将所述观测值输入智能体网络,得到第一价值函数和第二价值函数,所述智能体网络包括并行的稠密结构和稀疏结构,所述稠密结构用于基于所述观测值提取与所述学习环境中所有智能体相关的第一状态特征并基于所述第一状态特征得到所述第一价值函数,所述稀疏结构用于基于所述观测值提取与所述学习环境中部分智能体相关的第二状态特征并基于所述第二状态特征得到所述第二价值函数;所述处理单元,还用于通过时序差分方法确定所述第一价值函数对应的第一损失函数以及所述第二价值函数对应的第二损失函数,并基于所述第一损失函数和所述第二损失函数训练所述智能体网络。
21、在一种可能的实现方式中,所述稠密结构用于基于稠密注意力机制以及所述观测值提取得到所述第一状态特征,所述稀疏结构用于基于稀疏注意力机制以及所述观测值提取得到所述第二状态特征。
22、在一种可能的实现方式中,所述第一价值函数用于指示所述第一智能体在所述第一状态特征下选择不同动作所带来的价值,所述第二价值函数用于指示所述第一智能体在所述第二状态特征下选择不同动作所带来的价值。
23、在一种可能的实现方式中,所述处理单元,具体用于:根据所述第一价值函数和预置策略,从所述第一价值函数所指示的多个动作中选择第一动作并确定所述第一动作对应的第一价值;获取执行所述第一动作后的状态所对应的第二价值,并根据所述第一价值和所述第二价值确定所述第一损失函数;根据所述第二价值函数和所述预置策略,从所述第二价值函数所指示的多个动作中选择第二动作并确定所述第二动作对应的第三价值;
24、获取执行所述第二动作后的状态所对应的第四价值,并根据所述第三价值和所述第四价值确定所述第二损失函数。
25、在一种可能的实现方式中,所述预置策略包括贪心策略或∈-贪心策略,其中所述贪心策略用于选择价值最高的动作,所述∈-贪心策略用于基于第一概率选择价值最高的动作以及基于第二概率选择所述价值最高的动作以外的其他动作。
26、在一种可能的实现方式中,所述第一概率与所述智能体网络的训练次数具有正相关关系,所述第二概率与所述智能体网络的训练次数具有负相关关系。
27、在一种可能的实现方式中,所述智能体网络还包括循环神经网络,所述循环神经网络用于对所述观测值以及所述智能体所执行的历史动作进行编码,以得到编码特征;所述第一价值函数是基于所述第一状态特征和所述编码特征得到的,所述第二价值函数是基于所述第二状态特征和所述编码特征得到的。
28、在一种可能的实现方式中,所述处理单元,具体用于:获取所述多个智能体中其他智能体对应的稠密损失函数,并通过第一混合网络对所述第一损失函数和所述稠密损失函数进行混合处理,得到稠密混合损失函数,所述稠密损失函数是基于稠密注意力机制得到的;获取所述多个智能体中其他智能体对应的稀疏损失函数,并通过第二混合网络对所述第二损失函数和所述稀疏损失函数进行混合处理,得到稀疏混合损失函数,所述稀疏损失函数是基于稀疏注意力机制得到的;基于所述稠密混合损失函数和所述稀疏混合损失函数训练所述智能体网络。
29、在一种可能的实现方式中,在所述智能体网络训练完毕后,所述智能体网络中的所述稠密结构用于执行推理智能体动作的任务,且所述智能体网络中的所述稀疏结构不用于执行所述任务。
30、在一种可能的实现方式中,所述学习环境包括自动驾驶环境、机器人协同作业环境或多角色互动游戏环境。
31、本技术第三方面提供一种电子设备,可以包括处理器,处理器和存储器耦合,存储器存储有程序指令,当存储器存储的程序指令被处理器执行时实现上述第一方面或第一方面任一实现方式所述的方法。对于处理器执行第一方面的各个可能实现方式中的步骤,具体均可以参阅第一方面,此处不再赘述。
32、本技术第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面任一实现方式所述的方法。
33、本技术第五方面提供了一种电路系统,所述电路系统包括处理电路,所述处理电路配置为执行上述第一方面或第一方面任一实现方式所述的方法。
34、本技术第六方面提供了一种计算机程序产品,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面任一实现方式所述的方法。
35、本技术第七方面提供了一种芯片系统,该芯片系统包括处理器,用于支持服务器或门限值获取装置实现上述第一方面或第一方面任一实现方式中所涉及的功能,例如,发送或处理上述方法中所涉及的数据和/或信息。在一种可能的设计中,所述芯片系统还包括存储器,所述存储器,用于保存服务器或通信设备必要的程序指令和数据。该芯片系统,可以由芯片构成,也可以包括芯片和其他分立器件。
36、上述第二方面至第七方面的有益效果可以参考上述第一方面的介绍,在此不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!