一种基于边缘注意力引导的越南场景文字检测方法
1.本发明涉及文字检测领域,尤其涉及一种基于边缘注意力引导的越南场景文字检测方法。
背景技术:
2.自然场景文本检测是用于自动检测自然场景图像中的文本目标的一项技术,其广泛应用于自动驾驶、招牌识别、场景理解等。并且,自然场景文本检测也吸引了无数研究者的关注和研究。然而,现有的方法大多是基于英语等这些非声调语言的研究,一些声调语言如越南语的场景文字检测却鲜有研究。
3.越南语是一种声调语言,其利用重音符号或变音符号表示元音和声调,其中有三个个符号用来添加元音,五个符号表示越南语的声调,而这五个声调符号决定了每个单词的含义。越南语字符独特的构成,使得自然场景中越南文字的检测相对于现有的针对英语为主的检测技术具有以下困难:
4.1、需要更加丰富和鲁棒的特征信息,以尽可能地检测出越南场景文字目标以及提取到变音符号的特征;
5.2、变音符号的存在以及背景信息的干扰,使得一些类文字目标更易被误检为文字目标,即会出现一些假阳性目标;
6.3、自然场景中越南文字的变音符号与拉丁字母相比形状较小,在检测时易被忽略,进而无法完整地表达越南文字目标(变音符号检测不全,文字目标检测不完整),同时一些字符的上部会出现两个变音符号;
7.4、在自然场景中,越南场景文字目标尺度变化较大。
技术实现要素:
8.本发明的目的在于提供一种基于边缘注意力引导的越南场景文字检测方法,旨在更精准地检测不同尺度的越南场景文字目标,尤其是变音符号信息,并有效剔除非文字目标。
9.为实现上述目的,本发明提供了一种基于边缘注意力引导的越南场景文字检测方法,包括:使用resnet提取目标的特征信息,并在resnet中利用感受野残差块rfrb产生丰富的感受野,以适应不同尺度的越南场景文字目标;
10.使用多路融合特征金字塔网络mf-fpn对特征信息进行融合,得到目标不同层次的特征信息,比如:目标空间位置信息、变音符号细节信息等;
11.将特征信息输入rpn得到一定数量的候选框;
12.将候选框和特征信息经roi align后输入分类分支和掩码分支预测目标的类别信息、边界框信息和掩码信息,并使用re-score机制抑制非文字目标,同时利用边缘注意力机制eam突出目标的边缘。
13.本发明越南场景文字检测方法中,所述利用感受野残差块rfrb产生丰富感受野的
具体方式为:先采用1
×
1卷积调整特征的通道数;然后将膨胀率分别为1、2、3的3个3
×
3膨胀卷积的输出特征进行concat融合;再使用1
×
1的卷积调整通道数进行信息间的交融,进而产生丰富的感受野。
14.本发明越南场景文字检测方法中,所述多路融合特征金字塔网络mf-fpn是一种用于特征融合的网络,以产生含有不同信息的、不同层次的特征图,所述多路融合特征金字塔网络mf-fpn提取目标不同层次特征信息的具体方式为:将resnet得到的当前层次的特征输入通道数为256的1
×
1卷积后得到的输出,由resnet得到的前一层级的特征进行2
×
2平均池化得到的输出,对resnet输出的特征进行自上而下的上采样的输出,三者进行融合后再输入通道数为256的3
×
3卷积,进而得到不同层次的特征信息。
15.本发明越南场景文字检测方法中,所述候选框和特征信息经roi align后输入分类分支和掩码分支,预测目标的类别信息、边界框信息和掩码信息,具体方式是:
16.将候选框和特征信息输入roi align,将该目标的特征图映射到固定尺寸;
17.将固定尺寸的特征图输入分类分支,经由re-score机制得到精确的类别信息,同时利用边缘分支预测目标的边缘轮廓概率图,并将该图和类别与边界框预测分支的中间特征信息相乘形成边缘注意力eam,引导模型预测精确的边界框信息;
18.将固定尺寸的特征图输入掩码分支得到目标的掩码图,同时利用边缘分支预测目标的边缘轮廓概率图,并将该图和掩码预测分支的中间特征信息相乘形成边缘注意力eam,引导模型预测精确的掩码信息。
19.进一步地,所述由re-score机制得到精确的类别信息的具体步骤为:
20.将候选框的特征信息输入卷积网络得到目标的视觉类别置信度;
21.将候选框的特征信息输入序列打分分支得到目标的序列置信度;
22.将两者分别乘0.5后相加得到最终的类别置信度,选取置信度最高的类别作为目标的类别信息。
23.进一步地,所述序列打分分支是由一层通道数为1的1
×
1卷积层、一层bi-lstm层、两层全连接层组成,并且是以特征信息的宽度维度利用bi-lstm进行序列建模。
24.本发明越南场景文字检测方法中,所述re-score机制抑制非文字目标的具体方式为:使用1
×
1卷积调整固定尺寸的候选框特征信息的通道数;使用bi-lstm进行序列特征的提取;使用两层全连接层预测目标的序列得分;使用卷积网络预测目标的视觉分类得分;将两个得分分别与0.5相乘后相加得到最终的类别置信度;以0.7为阈值,将置信度低于阈值的目标剔除。
25.本发明越南场景文字检测方法中,所述利用边缘注意力机制eam突出目标的边缘的具体方式为:利用几层卷积层构成的边缘分支预测目标的边缘轮廓概率图,属于边缘的像素值大于等于0.5,非边缘像素小于0.5;将边缘概率图视为注意力权重与特征信息相乘形成边缘注意力机制eam。
26.本发明的一种基于边缘注意力引导的越南场景文字检测方法,利用感受野残差块rfrb产生不同的感受野,有效适应不同尺度的越南场景文字目标;设计多路融合特征金字塔网络mf-fpn网络,融合丰富的低层特征(相对低层),突出越南场景文字目标的位置以及变音符号的细节信息;re-score机制有效剔除非文字目标;eam增强模型对越南场景文字目标边缘更敏感,进而完整检测到越南场景文字目标,包括变音符号,并剔除一些非文字目
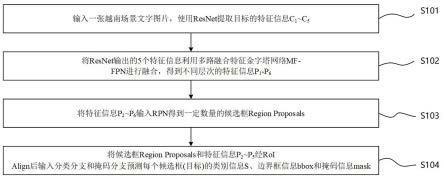
标。
附图说明
27.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
28.图1是实施例越南场景文字检测方法流程图。
29.图2是实施例越南场景文字检测方法的算法结构示意图。
30.图3是实施例提供的感受野残差块rfrb结构图。
31.图4是实施例提供的多路融合特征金字塔网络mf-fpn结构图。
32.图5是实施例提供的改进stage1结构图。
33.图6是实施例提供的re-score机制结构图。
34.图7是实施例提供的分类分支结构图。
35.图8是实施例提供的掩码分支结构图。
36.图9是实施例的越南场景文字检测实验数据示例图;
37.其中,(a)是带有边界框标注的越南场景文字图像样本;(b)是与图像样本(a)对应的二值文本分割图;(c)是与图像样本(a)对应的文本边缘轮廓图。
38.图10是实施例在实验时所需的越南场景文字图片示例。
39.图11是实施例提供的多路融合特征金字塔网络mf-fpn和其他方法所生成的特征图的对比示例。
40.图12是实施例提供的结合边缘注意力机制eam后在不同iou阈值的f-measure比较图。
41.图13是实施例提供的基于边缘注意力引导的越南场景文字检测方法和他人方法的检测结果示例对比图;
42.其中,(a)越南场景文字原始影像;(b)是采用baseline算法对原始影像进行检测的效果图;(c)是采用改进的mask r-cnn对原始影像进行检测的效果图;(d)是采用本发明检测方法对原始影像进行检测的效果图。
具体实施方式
43.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
44.实施例
45.请参阅图1~图13,一种基于边缘注意力引导的越南场景文字检测方法,包括以下步骤,具体参照图1-2:
46.s101输入一张越南场景文字图片,使用resnet提取目标的特征信息c1~c5;
47.其中,所述resnet是本领域一种通用的特征提取网络,该网络包括5个阶段stage,stage2~stage5是由一定数量的残差块组成,resnet在每个stage都会输出一组特征,共计得到5个特征c1~c5。
48.为了使得本发明能有效适应不同尺度的越南场景文字目标,将resnet中所有的残差块替换为实施例提供的感受野残差块rfrb。
49.rfrb的具体结构如图3所示,首先一路分支中将特征输入1
×
1卷积,再同时输入膨胀率分别为1、2、3的膨胀卷积,接着再将三者的输出在通道维度进行融合操作concat(拼接),再利用1
×
1卷积调整通道数和进行信息间的交融进而得到输出信息;另一路为恒等映射shortcut,即将输入信息直接输出或者经过1
×
1卷积调整通道数后输出;最终将两路分支的输出相加add后,经过relu激活函数得到最终的输出。
50.s102将resnet输出的5个特征信息利用多路融合特征金字塔网络mf-fpn进行融合,得到不同层次的特征信息p1~p6;
51.mf-fpn是由fpn所改进得到,fpn是本领域一种通用的特征融合网络。
52.mf-fpn具体结构如图4所示,图4中虚线箭头即为本发明所做改进,即每一层次的特征图pk形成时,不仅会融合ck以及进行上采样upsample的特征,还会融合低一层级的特征c
k-1
。例如得到p3特征图的具体步骤如下:将c2特征进行2
×
2的平均池化avgpool、c3特征进行1
×
1的卷积、自上而下路径的信息进行2倍上采样upsample这三者的输出进行相加add,再经3
×
3卷积得到p3特征。而p6特征图是由p5特征图进行最大池化maxpool得到的。
53.考虑到得到p2特征时需融合c1,而由resnet中stage1提取得到的c1信息有限,本发明对resnet中的stage1进行改进,以便提取到的c1特征信息更丰富。
54.图5所示为改进后的stage1结构图,其含有两路分支,一路分支首先对输入信息用零填充zero padding,接着输入7
×
7、步长为2、通道数为32的深度可分离卷积,再使用最大池化max pooling得到输出信息;另一路分支为先输入1
×
1、步长为1、通道数为32的卷积,再输入两层3
×
3、步长为2、通道数为32的深度可分离卷积得到输出信息;再将两个分支输出的信息进行融合concat;再输入1
×
1、步长为1、通道数为64的卷积得到最终的特征信息c1。
55.s103将特征信息p2~p6输入rpn得到一定数量的候选框region proposals;
56.rpn为领域内知名算法faster r-cnn所提出的一种区域生成网络,该网络会生成一定数量的候选框,代表模型认为在图像中哪些位置可能为文字目标。
57.s104将候选框region proposals和特征信息p2~p5经roi align后输入分类分支和掩码分支预测每个候选框(目标)的类别信息s、边界框信息bbox和掩码信息mask;
58.roi align为领域内算法mask r-cnn中所提,用于根据候选框region proposals的位置信息以及尺寸裁剪出候选框所对应的特征信息,并将其映射到固定尺寸。
59.分类分支的结构图如图7所示,候选框region proposals经过roi align后被映射为7
×
7大小的特征图,并分别输入边缘分支(edge branch)以及类别和边界框预测分支(class and bounding box prediction branch)。其中,边缘分支由一层通道数为256的3
×
3卷积层和一层通道数为1的1
×
1卷积层组成,然后经sigmoid函数激活后得到边缘轮廓概率图edge_map
cls
,并经二值化后得到边缘轮廓二值图。在类别和边界框预测分支中,使用4层卷积层(2层通道数为256的3
×
3卷积、1层通道数为1024的7
×
7卷积、1层通道数为1024的1
×
1卷积)和1层全连接层预测得到边界框bbox和视觉分类置信度sv,并将预测得到的边缘轮廓概率图edge_map
cls
与第一层卷积输出的特征f
cls
进行对应位置元素相乘以形成一种边缘注意力eam,具体计算如式(1)所示。同时将re-score机制融入类别和边界框预测分支,
得到最终的预测类别置信度s;
[0060][0061]
re-score机制融入类别和边界框预测分支,得到最终的预测类别置信度s的具体步骤如下:
[0062]
re-score机制的示意图如图6所示;
[0063]
利用前述类别和边界框预测分支得到第i个候选框的视觉分类得分利用序列打分分支得到候选框的语义序列得分序列打分分支首先利用卷积调整通道数,随后以特征的w(宽度)维度为时间步长,利用bi-lstm进行序列建模,然后经过两层全连接层以及softmax函数后得到目标的序列得分最终预测的第i个候选框类别置信度si经式(2)计算得到;
[0064][0065]
掩码分支的结构图如图8所示,候选框region proposals经roi align后被映射为14
×
14大小的特征图,并分别输入边缘分支(edge branch)和掩码预测分支(mask prediction branch)。边缘分支由4层卷积层(3层通道数为256的3
×
3卷积、1层通道数为1的1
×
1卷积)组成,然后经sigmoid函数激活后得到边缘轮廓概率图edge_map
msk
,并经二值化后得到边缘轮廓二值图。掩码预测分支与mask r-cnn中的掩码分支网络结构相同,由4层通道数为256的3
×
3卷积层、1层通道数为256的2
×
2转置卷积层和1层1
×
1卷积层组成,激活函数为sigmoid,最终得到目标的掩码分割图mask。同时将预测得到的边缘轮廓概率图edge_map
msk
与第一层卷积输出的特征f
msk
进行对应位置元素相乘以形成一种边缘注意力eam,具体计算如式(3)所式;
[0066][0067]
下面,结合实施例,对本发明方法效果作进一步说明。
[0068]
本发明提出的基于边缘注意力引导的越南场景文字检测方法,其测试环境及实验结果为:
[0069]
1)测试环境:
[0070]
系统环境:ubuntu 16.04;
[0071]
硬件环境:内存256gb,gpu:tesla v100
×
4,cpu:1.70ghz intel(r)xeon(r)e5-2609,硬盘:8tb;
[0072]
2)实验数据:
[0073]
为了验证本发明的有效性,使用自然场景多语言文本检测数据集(mlt 2017),只使用了其中7200张只包括拉丁文字类型的图片,以及200张来源于越南真实场景拍摄的图片。
[0074]
数据标注如图9所示,所用标注为越南场景文字目标的边界框位置坐标(图9(a))、越南场景文字目标的二值掩码图(图9(b))、越南场景文字目标的边缘轮廓图(图9(c))。
[0075]
3)实施细节:
[0076]
利用所述数据集对本方法进行训练和测试。在训练模型时,实验首先使用mlt 2017数据集做预训练(80个epoch),然后使用越南文字数据集微调整个模型(20个epoch)。
其中,batch-size设定为8,优化器选择sgd,初始学习率为0.001,动量设定为0.9。
[0077]
所做实验为五折交叉验证实验,越南场景文字数据集采用训练集为160张(在训练过程中,每张图片进行五次数据增广),测试集为40张的分配,并采用precision、recall、f-measure作为评估指标,iou的计算方式为计算mask分支得到的mask分割矩阵与真实目标的mask矩阵(二值掩码分割图)的交并比,而不是传统的方形框的形式计算交并比,iou阈值设置为0.7。
[0078]
在本实验中,对感受野残差块rfrb、多路融合特征金字塔网络mf-fpn、re-score机制、边缘注意力机制eam进行消融研究,对本发明和其他现有方法进行对比。基础算法(baseline)算法为mask r-cnn,本发明是在baseline的基础上改进的。
[0079]
4)实验结果:
[0080]
a)感受野残差块rfrb实验结果
[0081]
如表1所示,加入rfrb模块后,各项评估指标都提升近2%。其性能的提升正是由于rfrb能融合不同感受野,更加灵活地适应不同尺度的越南场景文字目标。
[0082]
为了突显rfrb对不同尺度越南场景文字目标的适应能力,实验按照coco中小、中、大目标的定义,对baseline和结合rfrb进行评测,对比两者分别检测不同尺度的真实越南场景文字目标的数目(真阳性目标)。其中,小目标(s)面积小于322,中目标(m)面积大于322并小于962,大目标(l)面积大于962。实验结果如表2所示,从表中可以看出加入rfrb模块检测出的不同尺度的真阳性目标的数量都比baseline算法所检测出的多,其中检测出小目标的数量相较于baseline算法提升3.6%,中目标提升1.8%,大目标提升5.5%,进一步说明rfrb对不同尺度越南场景文字目标的适应能力。
[0083]
b)多路融合特征金字塔网络mf-fpn实验结果
[0084]
由表1所示,与baseline相比,将baseline中的fpn替换为mf-fpn(+modified stage1)后,在recall指标提升2.8%,precision提升3.8%,f-measure提升3.2%。若再与rfrb结合后,各项指标均小有提升。
[0085]
本实验将图10所示的图像输入至算法中,再分别对fpn和mf-fpn输出的特征图进行可视化,如图11所示,mf-fpn得到的特征图较fpn,目标位置信息更明显,同时包含有更多的细节信息,更有助于检测越南场景文字目标,例如,可以看到mf-fpn提取的p2特征图所包含得变音符号的特征信息(图11箭头所示)。
[0086]
为了进一步验证改进stage1的必要性以及mf-fpn的有效性,做了以下消融实验。实验分别将baseline中resnet的stage1替换为改进后的stage1网络,以及将fpn替换为mf-fpn。实验结果如表3所示,从表中可以看出,仅将baseline中resnet的stage1替换为改进后的stage1,f-measure轻微提升0.4%。而仅将fpn替换为mf-fpn后,precision、recall、f-measure都提升2%左右,进一步表明mf-fpn的有效性。如表3最后一行所示,将改进后的stage1和mf-fpn结合后(mf-fpn+modified stage1),性能进一步提升。
[0087]
c)re-score机制实验结果
[0088]
re-score机制增加对候选框的序列打分,从而使得对候选目标的类别打分更准确,从而有效剔除非文字目标,从表1可以看出,结合re-score后与baseline算法相比,precision值近8%的提升,若同时结合rfrb和mf-fpn后,precision提升5.7%。这足以说明re-score机制抑制假阳性目标的能力。
[0089]
d)边缘注意力机制eam实验结果
[0090]
如表1所示,在iou阈值为0.7的条件下,每一折的交叉验证实验中结合eam较baseline在各项评估指标都有较大的提升,而结合之前所述的模块后,f-measure有4.3%的提升。
[0091]
为了进一步探究eam对变音符号的检测能力,实验采用更高的iou阈值,分别为0.7、0.8、0.9对eam进行测试。如图12所示,在较高的iou阈值下,结合eam后与baseline相比,仍有不错的表现,足以证明其可以有效检测变音符号,进一步准确地分割越南场景文字目标。
[0092]
e)与他人方法的比较
[0093]
从表4中可以看出本发明表现出良好的性能,与他人方法相比,precision提升10.6%,recall提升0.6%,f-measure提升5.8%。图13所示为几种方法检测的结果,从这些结果中可以看出本发明的检测结果边界更精细和更准确,可以有效剔除一些假阳性目标。
[0094]
表1消融研究(表格中mf-fpn的实验结果为结合改进stage1的结果)
[0095]
[0096][0097]
表2检测到不同尺度的真实越南场景文字目标(真阳性目标)的数目
[0098]
[0099][0100]
表3关于改进stage1和mf-fpn的消融研究实验结果
[0101][0102]
表4不同方法的对比结果
[0103][0104][0105]
表4中baseline算法参照:he k,gkioxari g,doll
á
r p,et al.mask r-cnn[c]//
international conference on computer vision(iccv).piscataway,nj:ieee,2017:2961-2969;
[0106]
他人算法参照:俸亚特,文益民.基于改进mask r-cnn的越南场景文字检测[j].计算机应用,2021,41(12):7。
[0107]
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1