一种基于数据建模的难度评估方法与流程
1.本发明涉及一种评估方法,尤其涉及一种基于数据建模的难度评估方法。
背景技术:
2.在当前社会背景下,人员的监管工作是智慧司法工作的重要组成部分,在构建法治社会中起到举足轻重的作用。目前,尚未有方法是通过数据模型量化对象在不同阶段的难度的,无法对当前处理措施进行有效评估,就无法有效的完成相应工作,也无法提高监管改造质量;因此,亟需提供一种基于数据建模的难度评估方法,能够评估对象的监管演化过程,从而实现在特定阶段、特定时期掌握对象的难度与态度,以对当前措施进行有效评估,实时调整阶段性改造方案。
技术实现要素:
3.为了解决上述技术所存在的不足之处,本发明提供了一种基于数据建模的难度评估方法。
4.为了解决以上技术问题,本发明采用的技术方案是:一种基于数据建模的难度评估方法,难度评估方法为:根据全数据域的数据,结合过程动态音频数据建立难度评估模型,将难度分为难、中、易三个区间;难度评估模型根据分值高低将对象划分不同的维度区间。
5.进一步地,全数据域的数据包括基础数据域、会见数据域、亲情电话数据域、生理数据域、心理数据域、惩罚数据域、消费数据域、计分考核数据域、医疗数据域、教育改造数据域。
6.进一步地,难度评估模型的建模步骤如下:
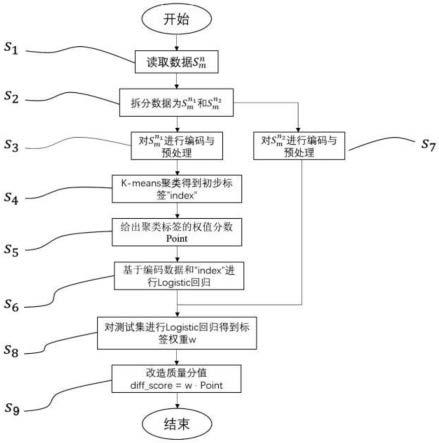
7.s1、获取全数据域的数据,设为
8.s2、将数据分为训练数据和测试数据
9.s3、对训练数据进行编码与预处理:经编码处理得到编码数据,从已编码数据中提取相关性强的特征列作为建模训练数据;
10.s4、采用k-means聚类得到初步标签index;
11.s5、给出聚类标签的权值分数piont;
12.s6、基于编码数据和初步标签index进行logistic回归,得logistic回归模型。
13.进一步地,基于logistic回归模型,获取最终得分diff_score,具体步骤如下:
14.s7、对测试数据进行编码与预处理:获得编码后的测试数据,将与建模训练数据相同的特征列作为测试建模数据,记为data_test;
15.s8、利用训练好的logistic回归模型预测测试数据data_test中的每一样本标签权重w;
16.s9、将权值分数point与标签权重w做内积得到最终得分diff_score,即:
[0017][0018]
其中,w(i)为标签权重w的第i个分量,为权值分数向量的第i个分量, diff_score为最终所得难度得分。
[0019]
进一步地,基于最终所得的难度得分diff_score,对难度进行评估; diff_score分值越高,说明难度越大。
[0020]
进一步地,训练数据测试数据的编码处理均为:对连续型特征进行标签编码;对离散型特征进行独热编码。
[0021]
进一步地,权值分数piont的获取为:将100均分为p份,得到与初步标签向量index维度相同的k维初始权值分数向量p_vec;其中,为初始权重分数向量,对应于p类初步标签;根据k-means聚类结果,将聚类中心的特征权重按照大小排序,将p_vec重新排序给出聚类标签的权值分数piont。
[0022]
本发明公开了一种基于数据建模的难度评估方法,针对特定监管场所的监管人群,基于过程全数据域的数据杨过程评估在不同阶段的难度与态度,根据各个改造阶段数据变化建立不同维度的评估模型与方式方法,并与实际过程中的数据信息进行复合,实现评估对象在不同改造阶段的量化指标,根据量化指标为评估对象在不同阶段提供分类管理、分级处遇、个性化教育矫正方案的实施、教育矫正目标的实现提供科学依据,使过程可评估、可量化,提高监管改造质量。
附图说明
[0023]
图1为本发明的难度评估方法流程图。
具体实施方式
[0024]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0025]
本发明公开了一种基于数据建模的难度评估方法,是针对初期过程时难度的评估方法,根据基础数据域、会见数据域、亲情电话数据域、生理数据域、心理数据域、惩罚数据域、消费数据域、计分考核数据域、医疗数据域、教育改造数据域等结合过程动态音频数据建立难度评估模型,将难度分为难、中、易三个区间;难度评估模型根据分值高低将对象划分不同的维度区间,具体方法如下,如图1所示:
[0026]
首先,设相关全数据域的数据为n=1,2,...,n;m=1,2,...,m;由n 个对象构成,每个对象包含m项特征。这m项特征在一般至少应包括:“人员 id”,“是否成年”“民事赔偿金额”,“以前文化程度”,“现文化程度”,“参加过何党派团体”,“分管等级”,“罚金金额”,“没收财产情况”,“民族”,“性别”,“宗教信仰”,“以前婚姻状况”,“以前面貌”,“分管类型”,“户口类型”,“原始类别”,“当前状态”,“一审 x名名称”,“身高”,“体重”等。
[0027]
将全数据域的数据分为训练数据和测试数据其中, n1=1,2,...,n1;n2=1,2,...,n2;n1+n2=n。
[0028]
具体建模步骤如下:
[0029]
一、训练模型
[0030]
(1)读取训练数据从管理系统获取excel数据,利用python中pandas 包的read_csv函数读取训练数据文件得到pandas.dataframe类型数据
[0031]
(2)训练数据编码。对连续型特征进行标签编码,将特征的取值替换成连续的数值型变量,不会增加模型复杂度,简单易实现,可解释性强。对离散型特征进行独热编码,独热编码是离散特征有多少取值,就用多少维向量来表示该特征,独热编码可以让特征之间距离技术更加合理。训练数据编码记为 coded_data_tr。
[0032]
(3)建模特征提取。通过相关专家及管理人员获取建模过程中与质量相关性强的特征列,从已编码数据coded_data_tr中提取这些相关性强的特征列作为建模训练数据,记为data_train。
[0033]
(4)k-means聚类。利用k-means聚类将建模训练数据data_train分为p类,得到初步标签列“index”。
[0034]
(5)将100均分为p份,得到与初步标签向量“index”维度相同的k维初始权值分数向量p_vec。其中,为初始权重分数向量,对应于p类初步标签;根据k-means聚类结果,将聚类中心的特征权重按照大小排序,将p_vec重新排序给出聚类标签的权值分数piont。其中,piont为p维向量,且每一分量介于0至100之间。
[0035]
(6)logistic回归。基于提取好的建模训练数据data_train和数据标签index 训练logistic回归模型,记为lr。通过调用python中sklearn包的logisticregression.fit函数实现训练,这里,函数的输入dataframe数据为 data_train和数据标签label。
[0036]
二、测试模型
[0037]
(1)读取测试数据与训练数据的读取方式相同,从管理系统获取 excel数据,利用python中pandas包的read_csv函数读取训练数据文件得到 pandas.dataframe类型数据
[0038]
(2)测试数据编码。同理,对连续型特征进行标签编码,将特征的取值替换成连续的数值型变量,不会增加模型复杂度,简单易实现,可解释性强。对离散型特征进行独热编码,独热编码是离散特征有多少取值,就用多少维向量来表示该特征,独热编码可以让特征之间距离技术更加合理。将编码后的测试数据记为coded_data_te。
[0039]
(3)建模特征提取。将与训练数据data_train相同的特征列作为测试建模数据,记为data_test。
[0040]
(4)利用一中第(6)步训练好的logistic回归模型lr预测测试数据 data_test中的每一样本标签权重w。w为p维向量,且每一分量介于0至1之间,分量之和为1。得到标签权重w目的是为了给出样本的预测信息,用于得出最终的质量量化分值。
[0041]
(5)获取最终得分diff_score。将权值分数point与标签权重w做内积得到最终得分。即:
[0042][0043]
其中,w(i)为标签权重w的第i个分量,为权值分数向量的第i个分量, diff_score为最终所得难度得分。
[0044]
三、难度评估
[0045]
基于最终所得的难度得分,对改造难度进行评估。
[0046]
diff_score分值越高,说明难度越大。按照难度得分分为难、中、易三个区间,其中,分值介于0至40为易改造,分值介于40至80为中度改造,分值介于 80至100为难改造。
[0047]
对于本发明所公开的基于数据建模的难度评估方法,与现有技术相比,具有以下技术优势:
[0048]
(1)从原始采集得到的数据出发,利用传统的k-means聚类算法和logistic 回归分类算法,给出了每一改造对象的之前难度量化分值。
[0049]
(2)所使用的k-means聚类算法收敛速度快,聚类效果较优,算法的可解释度强,适用于无监督学习问题。
[0050]
(3)所使用的logistic回归分类算法非常高效,计算量小,很容易调整,最重要的是能输出校准好的预测概率。
[0051]
【实施例】
[0052]
如图1所示,本实施例的基于数据建模的难度评估方法,具体评估过程如下:
[0053]
设相关全数据域的数据为n=1,2,...,n;m=1,2,...,m;由n个对象构成,每个对象包含m项特征。这m项特征在一般至少应包括:“人员id”,“是否成年”“民事赔偿金额”,“以前文化程度”,“现文化程度”,“参加过何党派团体”,“分管等级”,“罚金金额”,“没收财产情况”,“民族”,“性别”,“宗教信仰”,“以前婚姻状况”,“以前面貌”,“分管类型”,“户口类型”,“原始类别”,“当前状态”,“一审x名名称”,“身高”,“体重”等。
[0054]
将全数据域的数据分为训练数据和测试数据其中, n1=1,2,...,n1;n2=1,2,...,n2;n1+n2=n。n,m,n1,m1均为正整数。
[0055]
具体建模步骤如下:
[0056]
一、训练模型
[0057]
(1)读取训练数据
[0058]
(2)数据编码,分别对“以前文化程度”、“现文化程度”、“参加过何党派团体”、“分管等级”、“民族”、“性别”、“宗教信仰”等特征进行标签编码;对“以前婚姻状况”、“以前面貌”、“分管类型”、“户口类型”、“原始类别”、“当前状态”、“一审x名名称”等特征进行独热编码,记为coded_data_tr。
[0059]
(3)建模特征提取。提取已编码数据coded_data_tr中“以前文化程度”、“是否成年”、“民事赔偿金额”、“参加过何党派团体”、“分管等级”、“性别”、“分管类型”、“户口类型”、“原始类别”、“当前状态”、“一审x名名称”、“身高”、“体重”等列作为训练建模数据,记为 oded_train。
[0060]
(4)k-means聚类。利用k-means聚类将建模训练数据data_train分为10 类,得到
初步标签列“index”。
[0061]
(5)将100均分为10份,给出初始权值分数向量 p_vec=[10,20,30,40,50,60,70,80,90,100];根据k-means聚类结果,将聚类中心的特征权重按照大小顺序,由p_vec重新排序给出聚类标签的权值分数 piont=[40,20,30,10,60,90,100,80,70,50]。其中,piont为10为向量,且每一个量介于0至100之间。
[0062]
(6)logistic回归。基于提取好的建模训练数据data_train和数据标签index 训练logistic回归模型,记为lr。
[0063]
二、测试模型
[0064]
(1)读取测试数据
[0065]
(2)数据编码。分别对“以前文化程度”、“现文化程度”、“参加过何党派团体”、“分管等级”、“民族”、“性别”、“宗教信仰”等特征进行标签编码;对“以前婚姻状况”、“以前面貌”、“分管类型”、“户口类型”、“原始类别”、“当前状态”、“一审x名名称”等特征进行独热编码,记为coded_data_te。
[0066]
(3)建模特征提取。提取与训练数据data_train相同的特征列作为测试建模数据,记为data_test。
[0067]
(4)利用一中第(6)步训练好的logistic回归模型lr预测测试数据 data_test中的每一样本标签权重w。w为10维向量,且每一分量介于0至1之间,分量之和为1。
[0068]
(5)获取单个样本最终分值diff_score。将权值分数piont与样板标签权值w 做内积得到最终分值;即:
[0069]
其中,w(i)为标签权重w的第i个分量,为权值分数向量的第i个分量, diff_score为最终所得难度得分。
[0070]
表1出示了测试数据所得的难度分度值;
[0071]
表1
[0072] 人员id难度得分1人员186.556310672人员248.499814713人员322.271995594人员414.271430545人员573.47115185
[0073]
结合难、中、易三个区间进行评价,可知,对于人员1,改造分值取整为 87,由模型判断人员1为难改造对象;对于人员2,改造分值取整为48,由模型判断人员2为中度改造对象;对于人员3,改造分值取整为22,由模型判断人员 3为易改造对象;对于人员4,改造分值取整为14,由模型判断人员4为易改造对象;对于人员5,改造分值取整为73,由模型判断人员3为难改造对象。
[0074]
上述实施方式并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的技术方案范围内所做出的变化、改型、添加或替换,也均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1