一种利用分布式数据库架构提高计算性能的方法和系统与流程
1.本发明属于数据处理技术领域,特别是涉及一种利用分布式数据库架构提高计算性能的方法和系统。
背景技术:
2.企业级数据管理系统,不但需要快速处理大量并发事务(oltp),也需要支持对最近数据的分析(olap),比如复杂查询、综合报表等,但是olap和oltp的优化手段和架构设计是完全不同的,在不使用特殊硬件平台(比如exadata)的前提下,传统的集中式数据存储不能满足要求。
3.构建分布式应用系统,特别是在数据服务层面采用分布式数据库是确保企业级数据管理系统运行效率的有效手段。还如中国专利cn106685835b公开一种在数据中心的计算节点间实现高速分布式路由的方法,在计算节点及网络节点上安装用于对外提供网络服务的ovs虚拟交换机,并仅在计算节点上安装用于监控ovs虚拟交换机流量的fast-dvr控制器,并通过fas-dvr控制器更新通道网桥,各计算节点上所部署的fast-dvr控制器被控制节点集中控制;用户通过api向fast-dvr控制器下发自定义配置,当计算节点之间的不同网络流量超过网络流量阈值后,由fast-dvr控制器动态规划各计算节点间的网络拓扑。实现了对计算节点上网络流量的监控,并通过网络节点和计算节点实现了网络路由功能,既简化了整个数据中心的拓扑结构又能够显著减少网络节点的网络吞吐压力,提高了数据中心整体的网络性能。
4.再有,使用支持分布式数据管理的开源或者商业组件来使用分布式数据库,通常情况下,这些组件,比如:tddl、sharding、cat,均会提供对分库、分表、读写分离等分布式特性的支持。
5.但是,当系统的时效性要求很高,客户不接收、也不允许使用过期的、滞后的“脏”数据来提供数据服务,但又存在大量的、实时请求的在线复杂业务操作的业务场景时,需要采用自定义的分布式数据源管理组件来完成分布式架构下的数据管理。
技术实现要素:
6.本发明的目的在于提供一种基于数据资源目录构建的数据处理系统,通过构建高效、可控的分布式应用系统,在数据服务层面充分利用分布式数据库架构的可扩展性,提高系统的运行效率和均衡运行环境的资源利用,解决以下技术问题:1、不支持数据有效性判断,业务操作获取数据的实效性不能保证;2、不支持按功需定制化的分配数据源;3、不支持按负荷能力自动分配数据源,存在资源使用不均衡的的现象。
7.为解决上述技术问题,本发明是通过以下技术方案实现的:作为本发明提供的第一个方面,本发明为一种利用分布式数据库架构提高计算性能的方法,包括以下步骤:
步骤ss01:在进行数据操作之前,动态数据源管理模块实时扫描注册于高速缓存中的数据源登记信息;步骤ss02:根据数据源登记信息,去除无效数据源;步骤ss03:按照配置项中的数据源模板实例化有效数据源,测试数据源有效性后,实时刷新动态数据源,确保当前数据源包含所有可用、有效的数据源;步骤ss04:按照路由规则,选择合适的数据源作为动态数据源的当前数据源;步骤ss05:使用动态数据源中指定的数据源完成数据操作。
8.进一步地,数据源的配置方法为:采用spring框架作为ioc容器;在spring的配置文件中配置用于分布式数据架构下的主数据库定义,连接到系统环境中的主数据库(集群),作为数据操作的缺省数据源;在spring的配置文件中配置用于分布式数据架构下的从数据库定义,该定义作为从数据库动态注册的数据源模板,适配不同类型的数据源。
9.进一步地,动态数据源包括主数据源和动态注册的从数据库对应的数据源。
10.进一步地,步骤ss02中,去除无效数据源的方法为:s21:在需要监控状态的服务器上部署自定义采集代理客户端;s22:代理客户端定时t1采集服务器状态信息,包括cpu使用情况、数据库繁忙程度(db degree)、内存利用率、io使用率等;s23:将服务器状态信息发送到高速缓存中,并设定生命周期为t1,完成自动注册;s24:以t1=500ms作为心跳检测周期,由高速缓存的ttl机制完成心跳检测,超时未刷新,视为结点失联(无效数据源);s25:动态数据源在工作时监测高速缓存中保存的服务器状态信息,实时判断各服务器状态。
11.进一步地,对于步骤ss04,所有会话均通过jdbc模板注入动态数据源,一个应用有且只有一个单一的数据源。
12.进一步地,所述步骤ss04中,按照路由规则,选择合适的数据源的方法为:s41:从数据库根据定时t1采集当前服务器状态,包含cpu、内存、磁盘等信息,写入高速缓存,同时完成自身的注册;s42:主数据库业务功能处理完成后,把当前内部事务处理编号写入事务登记表,完成主数据库事务处理;s43:应用层或者数据层通过消息发布内部事务处理信息;s44:从数据库通过高级复制软件接收事务登记表中的内部事务编号信息;s45:从数据库通过消息接收内部事务处理信息,与本地事务登记表中的内部事务编号进行比较,确认事务同步状态;s46:从数据库数据同步状态写入高速缓存;s47:应用端动态数据源根据路由规则,在高速缓存中获取已注册的相关服务器信息和数据库信息,选取负荷最低的服务器作为业务处理的节点完成业务处理过程。
13.进一步地,应用层或者数据层通过消息发布内部事务处理信息时,执行以下步骤:创建用于存放会话关联信息的上下文,定义上下文中包含的相关属性;
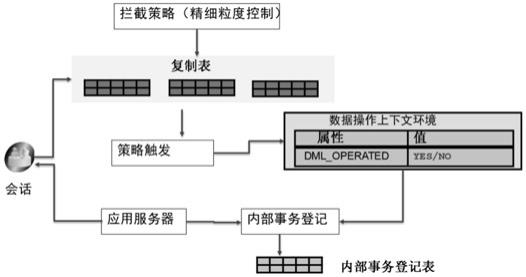
基于oracle精细粒度控制(fgac),在需要复制的数据表上加载拦截策略;在应用层的业务功能处理过程中包含复制监控的后续处理工作。
14.进一步地,步骤s45中:若本地事务编号为0,则没有需要复制的内容;若本地事务编号>0,则需要同步事务编号;即表示发生了需要复制的数据变更,需要记载主数据库本地变更表,应用需要把事务编号通过mq发给从数据库代理;数据插入操作事务包含在应用事务内;为了尽可能对应用透明;只通过(内部)事务编号和外部接口交互;会话上下文和dml审计全部隐藏在系统内部。
15.进一步地,t1为500ms。
16.作为本发明提供的另一个方面,本发明提供一种利用分布式数据库架构提高计算性能的系统,所述的系统包括相互通信连接的主服务器、从服务器、高速缓存,所述的系统用于实现如第一个方面所提供的方法。
17.本发明具有以下有益效果:本发明通过实时采集、判断分布式数据架构下的各个数据服务节点状态,通过动态数据源管理,在确保业务数据真实有效的前提下,均衡的把数据操作过程分配到指定的数据服务节点中去,提高整个系统的性能。
18.当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
19.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
20.图1为本发明服务器状态采集、注册的示意图;图2为本发明中数据库变更监控示意图。
具体实施方式
21.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
22.实施例一:请参阅图1-2所示,本发明为一种利用分布式数据库架构提高计算性能的方法,包括以下步骤:步骤ss01:在进行数据操作之前,动态数据源管理模块实时扫描注册于高速缓存中的数据源登记信息;步骤ss02:根据数据源登记信息,去除无效数据源;步骤ss03:按照配置项中的数据源模板实例化有效数据源,测试数据源有效性后,实时刷新动态数据源,确保当前数据源包含所有可用、有效的数据源;
步骤ss04:按照路由规则,选择合适的数据源作为动态数据源的当前数据源;步骤ss05:使用动态数据源中指定的数据源完成数据操作。
23.本发明实时的把事务消息传播到到高速缓存和从(查询)数据库中,结合通过高级复制软件(如:ogg、spx)或者数据库提供的原生复制功能,传递的事务信息,实时(《20ms)确认数据有效性;在数据服务层部署监控代理,实时(《500ms)采集os和db层面数据写入高速缓存,确保数据源组件能够及时的了解数据服务组件的性能和负荷,按需调度;支持在应用层面包含分布式应用元数据定义,可以在应用层面开启分布式应用,并可设定、支持数据源支持的路由模式。
24.作为本技术提供的一个实施例,优选的,数据源的配置方法为:采用spring框架作为ioc容器;在spring的配置文件中配置用于分布式数据架构下的主数据库定义,连接到系统环境中的主数据库(集群),作为数据操作的缺省数据源;在spring的配置文件中配置用于分布式数据架构下的从数据库定义,该定义作为从数据库动态注册的数据源模板,适配不同类型的数据源。
25.作为本技术提供的一个实施例,优选的,动态数据源包括主数据源和动态注册的从数据库对应的数据源。
26.作为本技术提供的一个实施例,优选的,步骤ss02中,去除无效数据源的方法为:s21:在需要监控状态的服务器上部署自定义采集代理客户端;s22:代理客户端定时t1(t1=500ms)采集服务器状态信息,包括cpu使用情况、数据库繁忙程度(db degree)、内存利用率、io使用率等;s23:将服务器状态信息发送到高速缓存中,并设定生命周期为t1=500ms,完成自动注册;s24:以t1=500ms作为心跳检测周期,由高速缓存的ttl机制完成心跳检测,超时未刷新,视为结点失联(无效数据源);s25:动态数据源在工作时监测高速缓存中保存的服务器状态信息,实时判断各服务器状态。
27.作为本技术提供的一个实施例,优选的,对于步骤ss04,所有会话均通过jdbc模板注入动态数据源,一个应用有且只有一个单一的数据源,具体使用哪个实际的数据源,由路由规则确定。
28.作为本技术提供的一个实施例,优选的,所述步骤ss04中,按照路由规则,选择合适的数据源的方法为:s41:从数据库根据定时t1(t1=500ms)采集当前服务器状态,包含cpu、内存、磁盘等信息,写入高速缓存,同时完成自身的注册;s42:主数据库业务功能处理完成后,把当前内部事务处理编号写入事务登记表,完成主数据库事务处理;s43:应用层或者数据层通过消息发布内部事务处理信息;s44:从数据库通过高级复制软件接收事务登记表中的内部事务编号信息;s45:从数据库通过消息接收内部事务处理信息,与本地事务登记表中的内部事务编号进行比较,确认事务同步状态;
s46:从数据库数据同步状态写入高速缓存;s47:应用端动态数据源根据路由规则,在高速缓存中获取已注册的相关服务器信息和数据库信息,选取负荷最低的服务器作为业务处理的节点完成业务处理过程。
29.在对应用完全透明的前提下,通过在主(写)数据库中部署“钩子”组件或者在应用层面通过aop机制,实时监控数据库中的事务变更,作为本技术提供的一个实施例,优选的,采用oralce数据库,在数据层完成数据变更监控:应用层或者数据层通过消息发布内部事务处理信息时,执行以下步骤:创建用于存放会话关联信息的上下文,定义上下文中包含的相关属性,具体的:
‑‑
用户上下文名称dml_audit_ctx
ꢀꢀꢀꢀꢀ
varchar2(30) default 'dml_audit_context';
‑‑
缺省方案用户default_user_name varchar2(30) default '方案名称';
‑‑‑
dml操作定义dml_operated_key
ꢀꢀ
varchar2(30) default 'dml_operated';
……
create or replace contextdml_audit_context using 方案名称.replicate_audit_pkg;基于oracle精细粒度控制(fgac),在需要复制的数据表上加载拦截策略,通过模板模式确保所有服务均实现透明拦截;在应用层的业务功能处理过程中包含复制监控的后续处理工作。
30.作为本技术提供的一个实施例,优选的,从上下文中获取用户名称、服务名称、操作名称时,注意:数据库刚启动时,dml_audit_ctx中的内容是“null
”ꢀ‑‑
需要复制的表上发生过dml操作;下一个(事务)操作缺省不包括复制表的dml操作。
31.作为本技术提供的一个实施例,优选的,步骤s45中:若本地事务编号为0,则没有需要复制的内容;若本地事务编号>0,则需要同步事务编号;即表示发生了需要复制的数据变更,需要记载主数据库本地变更表,应用需要把事务编号通过mq发给从数据库代理;数据插入操作事务包含在应用事务内;为了尽可能对应用透明;只通过(内部)事务编号和外部接口交互;会话上下文和dml审计全部隐藏在系统内部。
32.具体的:*作者 :王志群创建日期 :20160613
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
修改日期: 20160613
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**功能:判断是否需要在主数据库中记录一致性校验表
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**输入:《留白》**输出 :本地事务编号 0 没有需要复制的内容 》0 需要同步事务编号
ꢀꢀꢀ
**说明 :如果本地事务编号》0,表示发生了需要复制的数据变更,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**需要记载主数据库本地变更表,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**应用需要把事务编号通过mq发给从数据库代理
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**数据插入操作事务包含在应用事务内
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
*
*备注: 为了尽可能对应用透明,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**只通过(内部)事务编号和外部接口交互
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
**会话上下文和dml审计全部隐藏在系统内部
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
*。
33.实施例二:本发明提供一种利用分布式数据库架构提高计算性能的系统,所述的系统包括相互通信连接的主服务器、从服务器、高速缓存,所述的系统用于实现如实施例一所提供的方法。
34.一种利用分布式数据库架构提高计算性能的系统,通过实时采集、判断分布式数据架构下的各个数据服务节点状态,通过动态数据源管理,在确保业务数据真实有效的前提下,均衡的把数据操作过程分配到指定的数据服务节点中去,提高整个系统的性能。
35.在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
36.以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1