一种岩溶含水层连通性判别方法及系统、设备及介质与流程
1.本发明属于水文地质学领域,尤其涉及一种针对岩溶含水层间连通性的判别方法。
背景技术:
2.岩溶水是赋存于可溶性岩层溶蚀裂隙和溶洞中的地下水,其最明显特点是分布极不均匀。受岩溶发育程度、局部地形、构造特征等水文地质条件的影响,岩溶含水层的水流特征与其空间连通性密切相关。复杂岩溶含水层系统的水力连通性研究对岩溶地下水开发与补给、可持续运行、优化布局等具有重要应用价值。
3.岩溶含水层水力连通性的传统研究是通过水头测量(抽水试验)、水化学和环境同位素示踪试验以及数值模拟进行的。然而,水力连通性测量的一般定量方法,如常规实验和同位素示踪试验,工作周期长、投入大,且需要大量的数据支持;数值模拟方法进行含水层系统模拟和连通性研究,则需要大量长期的水文气象数据和详细的参数为前提。上述方法对复杂、不确定的水力连通性研究具有重要意义,但是往往需要大规模和连续的监测,成本高且耗时长。
技术实现要素:
4.本发明针对现有技术存在的问题,公开了一种基于观测井水文地质特征的含水层连通性判别方法,在无需含水层详细信息和复杂参数的情况下,本发明拟基于地下水位观测井的水位监测序列及地形地貌数据,通过距离聚类和属性聚类相结合的混合聚类方法,实现观测井之间岩溶含水层的连通性判别。
5.本发明采用的技术方案如下:
6.第一方面,本发明提出的基于距离-属性混合聚类的岩溶含水层连通性判别方法,如下:
7.步骤1获取各观测井的地下水埋深、水位方差、离断层距离,以及观测井处的地形起伏度、坡度,进行聚类变量计算,并分别存入观测井位置集合和水文地质属性集合;
8.步骤2对水文地质属性集合中的各个因子,分别进行标准化处理,得到标准化处理后的集合;
9.步骤3基于观测井位置集合,进行空间聚类,得到基于观测井位置的空间聚类结果;
10.步骤4基于观测井的水文地质属性集合,进行属性聚类,得到基于观测井水文地质特征的属性聚类结果;
11.步骤5基于得到的空间距离聚类结果和水文地质属性聚类结果,采用交叉合并规则进行聚类结果的综合,得到混合聚类结果;
12.步骤6对混合聚类结果进行评价;
13.步骤7依据混合聚类结果及观测井间连通性强弱生成含水层连通性专题图。
14.第二方面,本发明还提供了一种岩溶含水层连通性判别系统,如下:
15.集合构建模块,用于获取各观测井的地下水埋深、水位方差、离断层距离,以及观测井处的地形起伏度、坡度,进行聚类变量计算,并分别存入观测井位置集合和水文地质属性集合;
16.标准化处理模块,对水文地质属性集合中的各个因子,分别进行标准化处理,得到标准化处理后的集合;
17.空间聚类模块,基于观测井位置集合,进行空间聚类,得到基于观测井位置的空间聚类结果;
18.属性聚类模块,基于观测井的水文地质属性集合,进行属性聚类,得到基于观测井水文地质特征的属性聚类结果;
19.综合处理模块,基于得到的空间距离聚类结果和水文地质属性聚类结果,采用交叉合并规则进行聚类结果的综合,得到混合聚类结果;
20.评价模块,对混合聚类结果进行评价;
21.连通性判断模块,依据混合聚类结果及观测井间连通性强弱生成含水层连通性专题图。
22.第三方面,本发明还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述方法。
23.第四方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现权利要求任一所述方法。
24.本发明的有益效果如下:
25.本发明基于观测井空间距离和水文地质特征属性特征的混合聚类算法,发明了一种基于距离-属性混合聚类的岩溶含水层连通性判别方法,并基于此方法提供了一种岩溶含水层连通性判别系统,以一种高效而低成本的方式实现了岩溶含水层的连通性判别,提高了岩溶含水层岩溶发育的空间异质性研究成本和效率。
附图说明
26.图1是本实施例中研究区范围和观测井位置;
27.图2是本实施例中采用的地表dem数据;
28.图3是本实施例中采用的地表断裂数据;
29.图4是观测井位置和水文地质属性表;
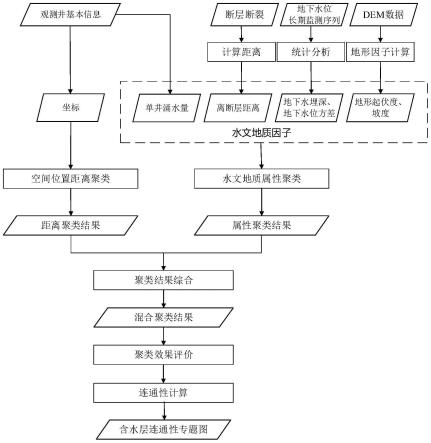
30.图5是本发明方法总流程图;
31.图6是混合聚类方法计算流程图;
32.图7是空间位置距离聚类结果;
33.图8是水文地质属性聚类结果;
34.图9是混合聚类结果;
35.图10是岩溶含水层观测井连通性专题图。
具体实施方式
36.下面对本发明技术方案作进一步详细的说明,本实例选取了山东省济南市马山断
裂与港沟断裂之间的碳酸盐岩岩溶含水层(图1)。数据源包括该区域内布设的16口观测井及其长期地下水位监测序列、30m分辨率dem数据(图2)和断层断裂数据(图3)。结合下面附图,并通过描述一个具体的实施例,来进一步说明。
37.实施例1
38.本实施例提供了一种基于距离-属性混合聚类的岩溶含水层连通性判别方法,具体包括如下步骤:
39.(1)读取和计算各观测井的地下水埋深、水位方差、离断层距离,以及观测井处的地形起伏度、坡度等聚类变量,并分别存入观测井位置集合wellp={wpi(xi,yi)|i=0,...,nw}(nw为观测井数量)和水文地质属性集合hydro={hdi(gdi,gvi,wydi,wtri,wsi,wfi)|i=0,...,nw}。在本实例中观测井总数为16。该步骤具体包括:
40.(1-1)创建观测井集合well={wi(wpi,whdi)|i=1,...,nw},其中,wi为第i个观测井要素,wpi为观测井wi的位置属性集,whdi为观测井wi的水文地质属性集;
41.(1-2)读取观测井基本信息表中各观测井的编号、坐标位置,得到观测井位置属性集wellp={wpi(xi,yi)|i=1,...,nw},其中xi为观测井wi的横坐标,yi是观测井wi的纵坐标;
42.(1-3)读取观测井wi的长期地下水位监测时间序列数据,获取和计算观测井wi的地下水埋深因子gdi,地下水位方差因子gvi;
43.(1-4)读取由抽水试验获得的观测井wi的单井涌水量因子wydi;
44.(1-5)读取dem数据,计算观测井wi所处位置的地形起伏度值wtri。
45.(1-6)计算观测井wi所处位置的坡度值,得到坡度因子wsi;
46.(1-7)读取断裂数据文件,计算观测井wi距最近的断裂的距离,得到离断层距离因子wfi;
47.(1-8)循环执行步骤(1-3)至(1-7),得到所有观测井的水文地质属性信息,并存入集合wellhydro={whdi(gdi,gvi,wydi,wtri,wsi,wfi)|i=1,...,nw},其中gdi为地下水埋深、gvi为地下水位方差、wydi为单井涌水量、wtri为地形起伏度、wsi为坡度、wfi为离断层距离;
48.(1-9)基于wellp、wellhydro,更新观测井集合well={wi(wpi,whdi)|i=1,...,nw}(图4);
49.(2)对观测井的水文地质属性集合wellhydro中的各个因子,分别进行z-score标准化处理,得到标准化处理后的集合wellhydro;
50.(3)基于观测井的位置集合,进行k-means空间聚类,得到基于观测井位置的空间聚类结果。该步骤的流程如图6所示,具体步骤包括:
51.(3-1)读取观测井位置属集合wellp={wpi(xi,yi)|i=1,...,nw};
52.(3-2)初始化距离聚类中心。由wellp中随机选取k个观测井作为距离聚类初始中心集合discenterpoint={dcpj(dcpxj,dcpyj)|j=1,...,k},其中dcpj为距离聚类中心点,dcpxj为横坐标,dcpyj为纵坐标;
53.(3-3)创建距离聚类分组集合
54.其中discatj代表距离聚类的第j个分组,代表第j个分组中的第m个观测井,k表示分组数,nj表示第j个分组中
观测井的数目。本实施例中,分组数为3;
55.(3-4)开始k-means空间位置距离聚类;
56.进一步的,步骤(3-4)包括:
57.(3-4-1)读取距离聚类中心点集合
58.discenterpoint={dcpj(dcpxj,dcpyj)|j=1,,..,k};
59.(3-4-2)根据公式(1)计算观测井wi与聚类中心dcpj的欧式距离:
[0060][0061]
(3-4-3)当j=1,...,k时,重复步骤(3-4-2),得到观测井wi与discenterpoint中所有聚类中心点的欧式距离;
[0062]
(3-4-4)计算dis
ij
(wi,dcpj)(j=1,2,...,k)中最小值,获取与观测井wi距离最小的聚类中心点编号j;将观测井wi存入组discatj中;
[0063]
(3-4-5)当i=1,...,nw,重复步骤(3-4-2)至(3-4-4),将所有观测井都分类到距其最近的聚类中心点簇中;
[0064]
(3-5)更新聚类中心;
[0065]
进一步的,步骤(3-5)包括:
[0066]
(3-5-1)计算discatj中包含的所有观测井的质心,将其作为新的聚类中心点,添加至新聚类中心点集合
[0067]
newdiscenterpoint={ndcpj(ndcpxj,ndcpyj)|j=1,...,k}。
[0068]
(3-5-2)对于j=1,2,...,k,重复步骤(3-5-1),完成所有分组的中心点更新。
[0069]
(3-6)判断更新后的聚类中心点集合newdiscenterpoint相比原聚类中心集discenterpoint是否发生改变,如果变化,执行步骤(3-7),如果未发生变化,执行步骤(3-8);
[0070]
(3-7)将更新后的新聚类中心点集newdiscenterpoint赋值给discenterpoint。转到步骤(3-4)并执行;
[0071]
(3-8)聚类中心不再变化,聚类结束,得到观测井的空间距离聚类结果空间距离聚类结果如图7所示;
[0072]
(4)基于观测井的水文地质属性集合,进行k-means属性聚类,得到基于观测井水文地质特征的属性聚类结果。该步骤的详细流程如图6所示,具体步骤包括:
[0073]
(4-1)读取观测井水文地质属性集合
[0074]
hydro={hdi(gdi,gvi,wydi,wtri,wsi,wfi)|i=1,...,nw};
[0075]
(4-2)初始化水文地质属性聚类中心。由hydro中随机选取k个观测井作为属性聚类初始中心集合
[0076]
hydcenterpoint={hcpj(gdj,gvj,wydj,wtrj,wsj,wfj)|j=1,2,...,k},其中hcpj表示第j个属性聚类中心点,gdj、gvj、wydj、wtrj、wsj、wfj分别代表属性聚类中心点hcpj的标准化后的地下水位埋深、地下水位方差、单井涌水量、地形起伏度、坡度和离断层距离;
[0077]
(4-3)创建集合其
中hydcatj代表水文地质属性聚类的第j个分组,代表第j个分组中的第m个观测井,nj表示第j个分组中观测井的数目。本实施例中,属性聚类的分组数为5;
[0078]
(4-4)执行k-means水文地质属性聚类;
[0079]
进一步的,步骤(4-4)包括:
[0080]
(4-4-1)读取属性聚类中心点集合
[0081]
hydcenterpoint={hcpj(gdj,gvj,wydj,wtrj,wsj,wfj)|j=1,2,...,k};
[0082]
(4-4-2)根据公式(2)计算wi到聚类中心hcpj的水文地质属性距离:
[0083][0084]
(4-4-3)当j=1,...,k时,重复步骤(4-4-2),得到wi与hydcenterpoint中所有聚类中心的距离;
[0085]
(4-4-4)计算hyd
ij
(zhdi,hcpj)(j=1,2,...,k)中最小值,并获取与wi距离最近的属性聚类中心点编号j;将观测井wi加入组hydcatj中;
[0086]
(4-4-5)对于i=1,2,3,...,nw,重复步骤(4-4-2)至(4-4-4),将所有观测井都分类到距其最近的属性聚类中心点簇中;
[0087]
(4-5)更新属性聚类中心:
[0088]
进一步的,步骤(4-5)包括:
[0089]
(4-5-1)计算hydcatj中包含的观测井各个水文地质属性均值,将各个变量均值组成的质心作为新的聚类中心点,添加至新属性聚类中心点集合newhydcenterpoint={nhcpj(ngdj,ngvj,nwydj,nwtrj,nwsj,nwfj)|j=1,2,...,k}
[0090]
(4-5-2)对于j=1,2,...,k,重复步骤(4-5-1),完成所有分组的中心点更新。
[0091]
(4-6)判断更新后的属性聚类中心点newhydcenterpoint相比原属性聚类中心hydcenterpoint是否发生改变,如果变化,执行步骤(4-7),如果未发生变化,执行步骤(4-8);
[0092]
(4-7)将更新后的聚类中心点集newhydcenterpoint赋值给hydcenterpoint。转到步骤(4-4)继续执行;
[0093]
(4-8)属性聚类中心不再变化,水文地质属性聚类结束,得到观测井的水文地质属性聚类结果本实施例中,水文地质属性聚类结果如图8所示;
[0094]
(5)基于(3)和(4)中得到的空间距离聚类结果和水文地质属性聚类结果,采用交叉合并规则进行聚类结果的综合,得到混合聚类结果。该步骤具体包括:
[0095]
(5-1)读取观测井集合well={wi(wpi,whdi)|i=1,...,nw};
[0096]
(5-2)读取空间位置距离聚类结果discategory和水文地质属性聚类结果hydcategory;
[0097]
(5-3)进行两种聚类结果的综合,获得混合聚类结果;
[0098]
进一步的,步骤(5-3)包括:
[0099]
(5-3-1)对于任意两个观测井wi和wj(i,j=1,2,3,...,nw;i≠j),如不符合规则(a),则认为观测井wi和wj之间不连通并将其分为不同类;如符合规则(a)而不符合规则(b),则认为观测井wi和wj间存在弱连通性并将其分为不同类;如同时符合规则(a)和(b),则认为观测井wi和wj之间存在强连通性并将其分为同一类;
[0100]
规则(a):wi和wj属于空间位置距离聚类discategory中的同一组;
[0101]
规则(b):wi和wj属于水文地质属性聚类hydcategory中的同一组;
[0102]
(5-3-2)获得混合聚类结果
[0103]
其中mixcatj表示混合聚类的第j个分组,表示第j类中的第m个观测井;
[0104]
(5-4)获得混合聚类结果mixcategory,同一类的观测井之间为强连通,不同类之间的观测井为不连通或弱连通。本实施例中,混合聚类结果如图9所示;
[0105]
(6)使用calinski-harabasz指标对混合聚类结果进行评价;该步骤具体包括:
[0106]
(6-1)进行聚类结果的效果评价,分组有效性通过calinski-harabasz伪f统计量(简称ch指标)来测量,它是一个反映组内相似性和组间差异性的比率;
[0107]
(6-2)依据公式(3)计算ch指标值:
[0108][0109]
其中:
[0110][0111][0112][0113]
sst反映组间差别,sse反映组内相似性;nw为观测井数目,nj为组j中的观测井数目,k为类(组)数目,nv为用于将观测井进行分组的变量数目,为第j组中第i个观测井的第v个变量值,为所有观测井第v个变量值的平均值,为第j组中第v个变量值的平均值;
[0114]
(6-3)使用计算完成的ch指标值对聚类效果进行评估,该值越大表示聚类效果越好,用于评估不同聚类分组数目情况下的聚类效果。本实例中,经过聚类效果评价,距离聚类分为3组,属性聚类分为5组,综合后的混合聚类为7组聚类效果最佳。
[0115]
(7)依据混合聚类结果及观测井间连通性强弱生成含水层连通性专题图。该步骤
具体包括:
[0116]
(7-1)基于观测井点状数据构建不规则三角网;
[0117]
(7-1)基于混合聚类结果,观测井之间不连通、弱连通和强连通关系分别使用不同类型的直线符号进行表示,制作观测井连通性专题图(图10)。
[0118]
实施例2
[0119]
相应于上面的方法实施例,本实施例还提供了一种岩溶含水层连通性判别系统,如下:本实施例中描述的岩溶含水层连通性判别系统与上文描述的外接存储介质检测方法可相互对应参照。
[0120]
具体的,该系统包括以下模块:
[0121]
集合构建模块,用于获取各观测井的地下水埋深、水位方差、离断层距离,以及观测井处的地形起伏度、坡度,进行聚类变量计算,并分别存入观测井位置集合和水文地质属性集合;
[0122]
标准化处理模块,对水文地质属性集合中的各个因子,分别进行标准化处理,得到标准化处理后的集合;
[0123]
空间聚类模块,基于观测井位置集合,进行空间聚类,得到基于观测井位置的空间聚类结果;
[0124]
属性聚类模块,基于观测井的水文地质属性集合,进行属性聚类,得到基于观测井水文地质特征的属性聚类结果;
[0125]
综合处理模块,基于得到的空间距离聚类结果和水文地质属性聚类结果,采用交叉合并规则进行聚类结果的综合,得到混合聚类结果;
[0126]
评价模块,对混合聚类结果进行评价;
[0127]
连通性判断模块,依据混合聚类结果及观测井间连通性强弱生成含水层连通性专题图。
[0128]
上述各个模块具体的实现方法参考实施例1,与实施例1记载的各个步骤依次对应,在此不进行赘述了。
[0129]
实施例3
[0130]
相应于上面的方法实施例,本实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现实施例1中公开的种基于距离-属性混合聚类的岩溶含水层连通性判别方法。
[0131]
实施例4
[0132]
相应于上面的方法实施例,本实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现实施例1中公开的种基于距离-属性混合聚类的岩溶含水层连通性判别方法。
[0133]
以上所揭露的仅为本发明一种较佳实施例而已,不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1