攻击无依赖的可迁移对抗样本检测方法
1.本发明属于人工智能技术领域,更为具体地讲,涉及一种攻击无依赖的可迁移对抗样本检测方法。
背景技术:
2.随着高效深度学习软件库的开放及硬件设备的持续升级,深度学习技术被广泛应用于计算机视觉、人机交互、智能决策等多个领域,正逐渐渗透并改变着人们的日常生活。然而,对抗样本严重阻碍了深度学习技术在安全相关领域中的应用。
3.对抗样本是一类通过在输入数据中添加难以察觉的细微扰动所生成的恶意样本,可以轻而易举地让表现良好的神经网络模型以高置信度输出错误结果。例如,攻击者通过在路标中添加精心设计的涂鸦,可以致使无人驾驶系统错误识别路标,威胁交通参与者的人身安全。
4.对抗样本检测技术作为一种有效的防御方法,因其无需更改输入数据和目标模型而受到了广泛青睐。然而,已有的相关工作通常需要目标模型或者攻击方法的先验知识,可迁移能力和泛化能力不足,难以应对复杂的开放环境。
技术实现要素:
5.本发明的目的在于克服现有技术的不足,提供一种攻击无依赖的可迁移对抗样本检测方法,在不需要任何关于攻击方法和模型先验知识的情况下,实现对抗样本检测,具有强迁移能力和泛化能力,能够应对复杂多变的真实应用场景。
6.为了实现上述发明目的,本发明攻击无依赖的可迁移对抗样本检测方法包括以下步骤:
7.s1:根据实际需要获取若干训练样本图像及其对应的分类标签,构成训练样本图像集;
8.s2:构造自编码网络模型、全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型,其中:
9.自编码网络模型包括编码器和解码器,其中编码器用于对输入样本图像提取特征,解码器用于根据特征进行重构得到重构样本图像;
10.全局互信息估计模型用于估计输入样本图像和其高维特征表示向量间的全局互信息值,具体方法如下:
11.将输入样本图像x输入自编码网络模型,编码器提取得到高维特征表示向量z,然后将编码器最后一层卷积层所输出的特征图f1一维化之后与高维特征表示向量z进行拼接,得到特征向量h1;然后将另一个参考输入样本图像x
′
输入自编码网络模型,将编码器最后一层卷积层所输出的特征图f2一维化后与原输入样本图像的高维特征表示向量z进行拼接,得到另一个特征向量h2;将上述两个特征向量h1和h2分别输入预设的全局互信息判别模型得到判别值t1和t2,采用如下公式估计得到输入样本图像和其高维特征表示向量间的全
局互信息估计值lg:
12.lg=log(t1)+log(1-t2)
13.局部互信息用于估计输入样本图像和其高维特征表示向量间的局部互信息值,具体方法如下:
14.将输入样本图像x输入自编码网络模型,编码器提取得到高维特征表示向量z,在编码器最后一层卷积层所输出的特征图f1的每个位置拼接一个高维特征表示向量z,得到特征图像i1;然后将另一个输入样本图像x
′
输入自编码网络模型,将编码器最后一层卷积层所输出的特征图f2的每个位置拼接一个原输入样本图像的高维特征表示向量z,得到另一个特征图像i2;将上述两个特征向量i1和i2分别输入预设的全局互信息判别模型得到判别矩阵r1和r2,采用如下公式估计得到输入样本图像和其高维特征表示向量间的局部互信息估计值lm:
[0015][0016]
其中,r1(i,j)、r2(i,j)分别表示判别矩阵r1和r2中坐标(i,j)的元素值,i=1,2,
…
,m,j=1,2,
…
,h,m
×
h表示判别矩阵的大小;
[0017]
先验分布匹配判别模型用于对输入样本图像的高维特征表示向量进行判别,得到判别值;
[0018]
s3:采用训练样本图像对步骤s2中所构建的4个模型进行联合训练,具体包括以下步骤:
[0019]
s3.1:初始化自编码网络模型、全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型的参数,设置迭代次数t=1;
[0020]
s3.2:将训练样本图像集随机划分为若干批次,记得到的训练样本图像的批次数量为k,每个批次中训练样本图像的数量为n;
[0021]
s3.3:令批次序号k=1;
[0022]
s3.4:将第k个批次的训练样本图像{x1,x2,
…
,xn,
…
,xn}输入自编码网络模型中,xn表示本批次中第n张训练样本图像,n=1,2,
…
,n,由编码器中获取该批次训练样本图像的高维特征表示向量{z1,z2,
…
,zn,
…
,zn},记编码器中最后一层卷积层输出的特征图为解码器基于图像的高维特征表示向量对图像进行重构,得到第k个批次训练样本图像的重构样本图像{g(z1),g(z2),
…
,g(zn),
…
,g(zn)};对每个训练样本图像的高维特征表示向量进行加噪处理,得到加噪后的高维特征表示向量{z1+ξ,z2+ξ,
…
,zn+ξ,
…
,zn+ξ},其中ξ表示噪声,解码器基于加噪后的高维特征表示向量对图像进行重构,得到第k个批次中训练样本图像的加噪重构样本图像{g(z1+ξ),g(z2+ξ),
…
,g(zn+ξ),
…
,g(zn+ξ)};
[0023]
然后将第k个批次的训练样本图像重新随机排序,记得到的训练样本图像为{x1′
,x
′2,
…
,x
′n,
…
,x
′n},将重新随机排序后的训练样本图像输入自编码网络模型中,记编码器中最后一层卷积层输出的特征图为
[0024]
s3.5:对于第k个批次的每个训练样本图像xn,将重新随机排序后的训练样本图像
x
′n作为参考输入样本图像,将训练样本图像xn的高维特征表示向量zn、特征图以及训练样本图像x
′n的特征图输入全局互信息估计模型中,得到训练样本图像xn和其高维特征表示向量zn的全局互信息估计值l
n,g
;
[0025]
将第k个批次中各个训练样本图像和其高维特征表示向量的全局互信息估计值进行平均,得到该批次的全局互信息估计值lg;
[0026]
s3.6:对于第k个批次的每个训练样本图像xn,将重新随机排序后的训练样本图像x
′n作为参考输入样本图像,将训练样本图像xn的高维特征表示向量zn、特征图以及训练样本图像x
′n的特征图输入局部互信息估计模型中,得到训练样本图像xn和其高维特征表示向量zn的局部互信息估计值l
n,m
;
[0027]
将第k个批次中各个训练样本图像和其高维特征表示向量的局部互信息估计值进行平均,得到当前批次的局部互信息估计值lm;
[0028]
s3.7:计算得到本批次中训练样本图像xn和重构样本图像g(zn)的均方误差,作为训练样本图像xn的重构损失l
n,c
:
[0029]
l
n,c
=||x
n-g(zn)||2[0030]
其中,|| ||2表示求取二范数;
[0031]
将第k个批次中各个训练样本图像的重构损失进行平均,得到当前批次的重构损失lc;
[0032]
s3.8:计算得到本批次中重构样本图像g(zn)和加噪重构样本图像g(zn+ξ)的均方误差,作为训练样本图像xn的相对重构损失l
n,r
:
[0033]
l
n,r
=||g(zn)-g(zn+ξ)||2[0034]
将第k个批次中各个训练样本图像的相对重构损失进行平均,得到当前批次的相对重构损失lr;
[0035]
s3.9:固定先验分布匹配判别模型的参数,将训练样本图像xn的高维特征表示向量zn输入至先验分布匹配判别模型中,得到判别值dn,采用如下公式计算先验分布匹配损失l
n,p
:
[0036]
l
n,p
=-dn[0037]
将第k个批次中各个训练样本图像的先验分布匹配损失进行平均,得到当前批次的先验分布匹配损失l
p
;
[0038]
s3.10:采用如下公式计算得到自编码网络模型、全局互信息判别模型和局部互信息判别模型的总损失l
t
:
[0039]
l
t
=-λg·
l
g-λm·
lm+λ
p
·
l
p
+λc·
lc+λr·
lr[0040]
其中,λg、λm、λ
p
、λc、λr表示预设的权重。
[0041]
根据总损失l
t
对自编码网络模型、全局互信息判别模型和局部互信息判别模型的参数进行更新;
[0042]
s3.11:首先固定自编码器模型的参数,生成当前批次中训练样本图像的高维特征表示向量{z1,z2,
…
,zn,
…
,zn},然后使用高斯分布随机生成与当前批次大小一致的向量{z
′1,z
′2,
…
,z
′n,
…
,z
′n},将各个向量分别输入至先验分布匹配判别模型中,得到判别值dn和d
′n,采用如下公式计算训练样本图像xn的先验分布匹配损失l
n,d
:
[0043]
l
n,d
=-d
n-d
′n[0044]
将第k个批次中各个训练样本图像的先验分布匹配损失进行平均,得到当前批次的先验分布匹配损失ld,然后根据先验分布匹配损失ld对先验分布匹配判别模型的参数进行更新;
[0045]
s3.12:判断是否批次序号k<k,如果是,进入步骤s3.13,否则进入步骤s3.14。
[0046]
s3.13:令批次序号k=k+1,返回步骤s3.4;
[0047]
s3.14:判断是否迭代次数t<t,t表示预设的最大迭代次数,如果是,进入步骤s3.15,否则模型训练结束;
[0048]
s3.15:令迭代次数t<t+1,返回步骤s3.2;
[0049]
s4:提取步骤s3中训练好的自编码器网络模型中的编码器,构建一个分类器,由编码器和分类器构成对抗样本检测模型,其中编码器用接收样本图像得到高维特征分布,分类器根据高维特征分布确定样本图像的分类;
[0050]
s5:将步骤s1中获取的训练样本图像集中的训练样本图像作为对抗样本检测模型的输入,对应分类标签作为对抗样本检测模型的期望输出,固定编码器参数,对对抗样本检测模型进行训练;
[0051]
s6:对于待检测样本图像,将其分别输入至目标模型和对抗样本检测模型,如果得到的分类结果一致,则该样本图像不是对抗样本,不具有对抗性,否则该样本图像是对抗样本。
[0052]
本发明攻击无依赖的可迁移对抗样本检测方法,构造自编码网络模型、全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型,采用训练样本图像集对以上模型进行联合训练,在联合训练时,先固定先验分布匹配判别模型的参数,对其他三个模型进行参数更新,然后固定自编码网络模型的参数,对先验分布匹配判别模型进行参数更新,训练完毕后提取自编码器网络模型中的编码器,将其和另外构建的分类器构成对抗样本检测模型并采用训练样本集进行训练,将待检测样本图像分别输入至目标模型和对抗样本检测模型,如果得到的高层特征分布不一致,则该样本图像是对抗样本。
[0053]
本发明具有以下有益效果:
[0054]
1)本发明采用双自编码结构,在无监督信息的情况下只使用原始干净数据获取编码器作为映射模型,确保相似数据经过映射模型后的高维特征分布同样相似,从而摆脱对于攻击方法的依赖;
[0055]
2)本发明根据对抗扰动会被模型逐步放大的性质,选用目标模型的输出层作为高层特征空间,通过比较输入样本在目标模型和检测模型中的高层特征分布判别样本的对抗性,从而摆脱对于模型知识的依赖;
[0056]
3)本发明无需更改输入样本和目标模型,易于和其他防御方法相结合,从而为目标模型提供更为有效的保护。
附图说明
[0057]
图1是本发明攻击无依赖的可迁移对抗样本检测方法的具体实施方式流程图;
[0058]
图2是本发明中全局互信息估计模型的原理示意图;
[0059]
图3是本发明中局部互信息估计模型的原理示意图;
[0060]
图4是本发明中模型联合训练的流程图;
[0061]
图5是本发明中对抗样本检测的流程图。
具体实施方式
[0062]
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
[0063]
实施例
[0064]
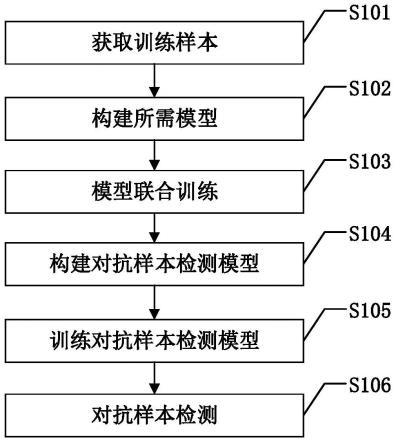
图1是本发明攻击无依赖的可迁移对抗样本检测方法的具体实施方式流程图。如图1所示,本发明攻击无依赖的可迁移对抗样本检测方法的具体步骤包括:
[0065]
s101:获取训练样本:
[0066]
根据实际需要获取若干训练样本图像及其对应的分类标签,构成训练样本图像集。
[0067]
s102:构建所需模型:
[0068]
构造自编码网络模型、全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型,其中:
[0069]
自编码网络模型包括编码器和解码器,其中编码器用于对输入样本图像提取特征,解码器用于根据特征进行重构得到重构样本图像。
[0070]
全局互信息估计模型用于估计输入样本图像和其高维特征表示向量间的全局互信息值。图2是本发明中全局互信息估计模型的原理示意图。如图2所示,本发明中全局互信息估计模型估计输入样本图像和其高维特征表示向量间的全局互信息值的具体方法如下:
[0071]
将输入样本图像x输入自编码网络模型,编码器提取得到高维特征表示向量z,然后将编码器最后一层卷积层所输出的特征图f1一维化(flatten)之后与高维特征表示向量z进行拼接,得到特征向量h1;然后将另一个参考输入样本图像x
′
输入自编码网络模型,将编码器最后一层卷积层所输出的特征图f2一维化后与原输入样本图像的高维特征表示向量z进行拼接,得到另一个特征向量h2;将上述两个特征向量h1和h2分别输入预设的全局互信息判别模型得到判别值t1和t2,采用如下公式估计得到输入样本图像和其高维特征表示向量间的全局互信息估计值lg:
[0072]
lg=log(t1)+log(1-t2)
[0073]
局部互信息估计模型用于估计输入样本图像和其高维特征表示向量间的局部互信息值。图3是本发明中局部互信息估计模型的原理示意图。如图3所示,本发明中局部互信息估计模型估计输入样本图像和其高维特征表示向量间的局部互信息矩阵的具体方法如下:
[0074]
将输入样本图像x输入自编码网络模型,编码器提取得到高维特征表示向量z,在编码器最后一层卷积层所输出的特征图f1的每个位置拼接一个高维特征表示向量z,得到特征图像i1;然后将另一个输入样本图像x
′
输入自编码网络模型,将编码器最后一层卷积层所输出的特征图f2的每个位置拼接一个原输入样本图像的高维特征表示向量z,得到另一个特征图像i2;将上述两个特征向量i1和i2分别输入预设的全局互信息判别模型得到判
别矩阵r1和r2,采用如下公式估计得到输入样本图像和其高维特征表示向量间的局部互信息估计值lm:
[0075][0076]
其中,r1(i,j)、r2(i,j)分别表示判别矩阵r1和r2中坐标(i,j)的元素值,i=1,2,
…
,m,j=1,2,
…
,h,m
×
h表示判别矩阵的大小;
[0077]
先验分布匹配判别模型用于对输入样本图像的高维特征表示向量进行判别,得到判别值。
[0078]
以上4个模型的具体结构可以根据实际需要进行设置。
[0079]
s103:模型联合训练:
[0080]
接下来需要采用训练样本图像对步骤s102中所构建的4个模型进行联合训练。图4是本发明中模型联合训练的流程图。如图4所示,本发明中模型联合训练的具体步骤包括:
[0081]
s401:初始化:
[0082]
初始化自编码网络模型、全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型的参数,设置迭代次数t=1。
[0083]
s402:训练样本图像集批次划分:
[0084]
将训练样本图像集随机划分为若干批次(mini-batch),记得到的训练样本图像的批次数量为k,每个批次中训练样本图像的数量为n。
[0085]
s403:令批次序号k=1。
[0086]
s404:训练样本图像重构:
[0087]
将第k个批次的训练样本图像{x1,x2,
…
,xn,
…
,xn}输入自编码网络模型中,xn表示本批次中第n张训练样本图像,n=1,2,
…
,n,由编码器中获取该批次训练样本图像的高维特征表示向量{z1,z2,
…
,zn,
…
,zn},记编码器中最后一层卷积层输出的特征图为解码器基于图像的高维特征表示向量对图像进行重构,得到第k个批次训练样本图像的重构样本图像{g(z1),g(z2),
…
,g(zn),
…
,g(zn)}。对每个训练样本图像的高维特征表示向量进行加噪处理,得到加噪后的高维特征表示向量{z1+ξ,z2+ξ,
…
,zn+ξ,
…
,zn+ξ},其中ξ表示噪声,解码器基于加噪后的高维特征表示向量对图像进行重构,得到第k个批次中训练样本图像的加噪重构样本图像{g(z1+ξ),g(z2+ξ),
…
,g(zn+ξ),
…
,g(zn+ξ)}。本实施例中添加的噪声为均值为0,方差为0.1的高斯噪声。
[0088]
然后将第k个批次的训练样本图像重新随机排序,记得到的训练样本图像为{x
′1,x
′2,
…
,x
′n,
…
,x
′n},将重新随机排序后的训练样本图像输入自编码网络模型中,记编码器中最后一层卷积层输出的特征图为
[0089]
s405:计算全局互信息损失:
[0090]
对于第k个批次的每个训练样本图像xn,将重新随机排序后的训练样本图像x
′n作为参考输入样本图像,将训练样本图像xn的高维特征表示向量zn、特征图以及训练样本图像x
′n的特征图输入全局互信息估计模型中,得到训练样本图像xn和其高维特征表示
向量zn的全局互信息估计值l
n,g
。
[0091]
将第k个批次中各个训练样本图像和其高维特征表示向量的全局互信息估计值进行平均,得到该批次的全局互信息估计值lg。
[0092]
s406:计算局部互信息损失:
[0093]
对于第k个批次的每个训练样本图像xn,将重新随机排序后的训练样本图像x
′n作为参考输入样本图像,将训练样本图像xn的高维特征表示向量zn、特征图以及训练样本图像x
′n的特征图输入局部互信息估计模型中,得到训练样本图像xn和其高维特征表示向量zn的局部互信息估计值l
n,m
。
[0094]
将第k个批次中各个训练样本图像和其高维特征表示向量的局部互信息估计值进行平均,得到当前批次的局部互信息估计值lm。
[0095]
s407:计算重构损失:
[0096]
计算得到本批次中训练样本图像xn和重构样本图像g(zn)的均方误差,作为训练样本图像xn的重构损失l
n,c
:
[0097]
l
n,c
=||x
n-g(zn)||2[0098]
其中,|| ||2表示求取二范数。
[0099]
将第k个批次中各个训练样本图像的重构损失进行平均,得到当前批次的重构损失lc。
[0100]
s408:计算相对重构损失:
[0101]
计算得到本批次中重构样本图像g(zn)和加噪重构样本图像g(zn+ξ)的均方误差,作为训练样本图像xn的相对重构损失l
n,r
:
[0102]
l
n,r
=||g(zn)-g(zn+ξ)||2[0103]
将第k个批次中各个训练样本图像的相对重构损失进行平均,得到当前批次的相对重构损失lr。
[0104]
s409:计算先验分布匹配损失:
[0105]
固定先验分布匹配判别模型的参数,将训练样本图像xn的高维特征表示向量zn输入至先验分布匹配判别模型中,得到判别值dn,采用如下公式计算先验分布匹配损失l
n,p
:
[0106]
l
n,p
=-dn[0107]
将第k个批次中各个训练样本图像的先验分布匹配损失进行平均,得到当前批次的先验分布匹配损失l
p
。
[0108]
s410:自编码网络模型、全局互信息判别模型和局部互信息判别模型进行参数更新:
[0109]
采用如下公式计算得到自编码网络模型、全局互信息判别模型和局部互信息判别模型的总损失l
t
:
[0110]
l
t
=-λg·
l
g-λm·
lm+λ
p
·
l
p
+λc·
lc+λr·
lr[0111]
其中,λg、λm、λ
p
、λc、λr表示预设的权重。
[0112]
可见,本发明中需要最大化输入样本图像和其高维特征表示向量间的全局互信息估计值和局部互信息估计值,而最小化重构损失、相对重构损失、先验分布匹配损失,因此在总损失计算公式中将全局互信息估计值和局部互信息估计值取反,从而将整体转化为最
小化优化问题。
[0113]
根据总损失l
t
对自编码网络模型、全局互信息判别模型和局部互信息判别模型的参数进行更新。
[0114]
s411:先验分布匹配判别模型进行参数更新:
[0115]
首先固定自编码器模型的参数,生成当前批次中训练样本图像的高维特征表示向量{z1,z2,
…
,zn,
…
,zn},然后使用高斯分布(本实施例中均值为0,方差为5)随机生成与当前批次大小一致的向量{z
′1,z
′2,
…
,z
′n,
…
,z
′n},将各个向量分别输入至先验分布匹配判别模型中,得到判别值dn和dn′
,采用如下公式计算训练样本图像xn的先验分布匹配损失l
n,d
:
[0116]
l
n,d
=-d
n-d
′n[0117]
将第k个批次中各个训练样本图像的先验分布匹配损失进行平均,得到当前批次的先验分布匹配损失ld,然后根据先验分布匹配损失ld对先验分布匹配判别模型的参数进行更新。
[0118]
本实施例中借助wgan-gp的思想,为先验分布匹配判别模型添加梯度惩罚项,梯度惩罚项的系数根据需要设置,本实施例中梯度惩罚项的系数设为10.0,之后再次使用adam优化器完成先验分布匹配判别模型的参数更新。
[0119]
s412:判断是否批次序号k<k,如果是,进入步骤s413,否则进入步骤s414。
[0120]
s413:令批次序号k=k+1,返回步骤s404。
[0121]
s414:判断是否迭代次数t<t,t表示预设的最大迭代次数,如果是,进入步骤s415,否则模型训练结束。
[0122]
s415:令迭代次数t<t+1,返回步骤s402。
[0123]
s104:构建对抗样本检测模型:
[0124]
提取步骤s103中训练好的自编码器网络模型中的编码器,构建一个分类器,由编码器和分类器构成对抗样本检测模型,其中编码器用接收样本图像得到高维特征分布,分类器根据高维特征分布确定样本图像的分类。
[0125]
s105:训练对抗样本检测模型:
[0126]
将步骤s101中获取的训练样本图像集中的训练样本图像作为对抗样本检测模型的输入,对应分类标签作为对抗样本检测模型的期望输出,固定编码器参数,对对抗样本检测模型进行训练。
[0127]
s106:对抗样本检测:
[0128]
图5是本发明中对抗样本检测的流程图。如图5所示,对于待检测样本图像,将其分别输入至目标模型和对抗样本检测模型,如果得到的分类结果(即高层特征分布)一致,则该样本图像不是对抗样本,不具有对抗性,否则该样本图像是对抗样本。
[0129]
为了更好地说明本发明的技术效果,接下来以cifar-10数据集的分类问题为例对本发明进行实验验证。cifar-10数据集包含来自十个类别的50000张训练图像和10000张测试图像,图像大小为32
×
32
×
3。对cifar-10数据集中的训练图像集进行批次划分,每个批次中训练图像数量为256。
[0130]
本实施例选取local、vgg16和resnet50作为分类器对cifar-10数据集实施分类。所有分类器均使用adam优化器(β1=0.9,β2=0.999)训练完成,批次大小为128,学习率为
0.001,最大迭代轮数为50。表1是本实施例中local分类器的结构信息表。
[0131][0132]
表1表2是本实施例中自编码器网络模型的结构信息表。
[0133][0134]
表2
[0135]
表3是本实施例中全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型的结构信息列表。
[0136][0137]
表3
[0138]
训练超参数设置如下:最大迭代轮数为50,学习率为0.0001,总损失函数中各系数值为λg=0.001、λm=0.001、λ
p
=0.0001、λc=10、λr=10。完成自编码网络模型、全局互信息估计模型、局部互信息估计模型和先验分布匹配判别模型的联合训练后,将自编码器网络模型中的编码器提取出来,和预设的分类器一起构成对抗样本检测模型。然后对对抗样本检测模型进行训练。本实施例中分类器采用简单全连接分类器。表4是本实施例中简单全连接分类器的结构信息列表。
[0139]
input 64full connected 1024,bn,reludropout 0.5full connected 512,bn,reludropout 0.5softmax 10
[0140]
表4
[0141]
本实施例中,对抗样本检测模型训练时采用的损失函数为交叉熵损失函数,优化器为adam(β1=0.9,β2=0.999),最大迭代轮数为50,学习率为0.0001,mini-batch大小为256。
[0142]
将本发明对抗样本检测方法简称为miaed,同时保持双自编码网络和简单全连接分类器的结构不变、基本超参数一致,舍去互信息最大化和先验分布匹配,将所得到的对抗样本检测方法记为caed。然后选取现有技术中表现较好的ssd算法(参见文献“gong z,wang w,ku w.adversarial and clean data are not twins[j].arxiv preprint arxiv:1704.04960,2017.)和lid算法(参见文献“ma x,li b,wang y,erfani s,wijewickrema s,schoenebeck g,song d,houle m,bailey j.characterizing adversarial subspaces using local intrinsic dimensionality[c]//international conference on learning representations(iclr).2018;”)作为对比方法,采用对抗样本的召回率(recall)和精确度(accuracy)作为评估指标。对抗样本采用常用的三种算法生成,三种算法分别为pgd算法(参见文献“madry a,makelov a,schmidt l,tsipras,vladu a.towards deep learning models resistant to adversarial attacks[c]//international conference on learning representations(iclr).2018;”)、bim算法(参见文献“kurakin a,goodfellow i,bengio s.adversarial examples in the physical world[c]//international conference on learning representations(iclr).2017;”)和cw2算法(参见文献“carlini n,wagner d.towards evaluating the robustness of neural networks[c]//ieee symposium on security and privacy(s&p).2017:39-57;”)。
[0143]
本次实验中对抗样本由不同攻击方法借助不同分类器生成,借助local分类器与pgd攻击生成的对抗样本用于辅助ssd和lid的训练,local分类器为目标模型。表5是本发明和对比方法在cifar-10数据集的对抗样本检测性能对比表。
[0144][0145]
表5
[0146]
如表5所示,本发明提出的对抗样本检测方法在防御白盒攻击(对抗样本由不同对抗攻击借助local分类器生成)和黑盒攻击(对抗样本由不同对抗攻击借助vgg16和resnet50生成)时,表现出了极为稳定的防御效果,具有较强的泛化能力,可以有效抵御不同攻击,且召回率和精确度均高于caed。
[0147]
表6是本发明针对不同目标模型在cifar-10数据集的对抗样本检测性能对比表。
[0148][0149]
表6
[0150]
如表6所示,本发明提出的对抗样本检测方法具有较强的迁移能力,能够有效保护不同的模型,适应不同应用场景的需要。
[0151]
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1