一种非典型类数据集平衡方法、装置、介质与流程
1.本发明涉及深度学习技术,具体涉及不均衡数据集的深度学习领域,具体使用非典型类数据平衡方法来进行疾病图像分类的处理技术。
背景技术:
2.深度学习技术在医学图像分类领域的应用极大的方便了医生对于疾病的诊断,在深度学习出现之前,基本都是基于机器学习的方法进行研究。机器学习的方法如利用纹理特征,lbp算子以及其他的方法等进行特征提取,然后利用k近邻算法或者svm等传统方法进行图像的分类。许多学者利用上述方法在乳腺癌,甲状腺结节等疾病方面得到了不错的分类结果,并开发出相应的辅助诊断系统。虽然传统的机器学习算法取得了如此多的成就,但是机器学习方法特征选取过程复杂,难以准确提取,且对研究人员要求比较高,现在的医学图像数据集通常都在一万张以上,机器学习方法在大数据集上的分类结果不能令人满意。
3.深度学习在皮肤癌分类任务上的敏感性和特异性以及准确度超过人类专家,为探寻更高的准确率和分类效率,不少研究人员引入了一系列的方法和手段到皮肤镜图像分类领域中来。皮肤癌数据集,大都呈现出数据分布不平衡的特点,是典型的不均衡数据集。对于机器学习,很多学者采取不同的采样方法解决数据不平衡的问题,常用的采样方法有过采样,如smote采样方法,欠采样,如ncl采样方法混合采样,如smote+tomek links方法。
4.现有技术中,对于深度学习,传统解决数据不平衡的方法有对数据进行预处理平衡,或者对损失函数进行优化,或者改进网络的部分结构,使模型在训练时适应不平衡数据集。比如,在处理自然语言不均衡问题时,加入动态的k-means聚类方法进行数据预处理,对文本不平衡数据集的分类准确率有了很好的提升;在心肌梗死信号处理中,使用cnn模型和focal loss损失函数来优化训练,解决了心肌梗死信号不平衡的问题;在皮肤病方面,通过一种辅助解码器来处理原始图像,增加样本数量来平衡数据集,原始图像经过cnn之后,送入解码器网络得到新的图像,新图像与原始图像分别送入对应的cnn分类器,两种图像的训练loss和解码器的loss根据不同权重构成分类模型的总loss。但皮肤癌数据集通常属于不均衡数据集,上述loss平衡方法或者模型集成方法来解决数据集不均衡的问题,目前的效果均不佳,网络或模型的准确性也不够高。因此,如果提出一种皮肤病不均衡数据集的处理方法,可以提高网络或模型的分类效果,同时提高分类的的准确性的方法是非常重要的。
技术实现要素:
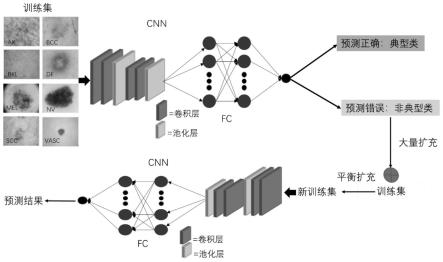
5.鉴于现有技术的缺点,本发明提出一种非典型类数据集平衡方法、装置、介质,本发明结合传统不均衡数据处理方式和非典型类数据集平衡方式,使用皮肤病图像完成不同类型疾病的分类识别,其具体包括对数据集进行预处理,针对不同类别的皮肤病不均衡数据集进行传统扩增得到训练集,实现不同类别的皮肤病数据整体均衡的状态,在此基础上,将训练集送入选定的cnn网络进行训练,得到训练的权重之后,使用此权重对训练集进行分类,得到预测错误和预测正确两个类别,预测错误的类别将之称为非典型类,然后对非典型
类进行大量扩充,得到新训练集—非典型类数据平衡数据集;新的训练集送入网络模型训练,得到最终的训练网络模型,并基于该网络模型进行不同皮肤病疾病的预测分类。
6.第一方面,本发明提出一种非典型类数据集平衡方法,所述方法包括步骤:
7.对数据集进行预处理;
8.针对不同类别的不均衡数据集进行扩增得到平衡数据集;
9.将平衡数据集送入设置好的网络模型进行训练得到非典型类数据集;
10.对非典型类数据集进行非典型类数据扩增,得到非典型类均衡数据集;
11.将典型类数据集和所述非典型类均衡数据集输入网络模型训练,得到训练后的网络模型和训练后的分类结果。
12.进一步地,具体地,对数据集进行预处理具体包括:数据集进行裁剪处理以及随机的图像增强处理。
13.优选地,所述设置好的网络模型具体设置包括:
14.网络模型为efficientnetb0,具体包括mbconvblock,mbconv,sepconv,深度可分离卷积(dwconv),se模块;
15.所述网络模型初始设置使用在自然图像上训练好的权重进行迁移学习训练得到efficientnetb0网络的初始模型权重;
16.优选地,所述网络模型在训练过程中采用focal loss,二分类的交叉熵损失函数:
[0017][0018]
其中,y的取值范围是1或者-1,1代表正样本,-1代表负样本,概率p的取值范围是0到1;
[0019]
用pt代替p,得到公式2:
[0020][0021]
公式1可以重写为公式3:
[0022]
ce(p,y)=ce(pt)=-log(pt)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0023]
为控制正负样本,难分类和容易分类样本权重,focal loss在公式3前面加入调制系数,得到公式4:
[0024]
fl(pt)=-α
t
(1-pt)
γ
log(pt)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0025]
其中α
t
用来降低负样本的权重,当标签等于1的时候,-α
t
等于α,标签等于其他的时候,-α
t
等于1-α,α的取值范围是0到1。
[0026]
具体地,所述数据集扩增具体包括:数据集进行数据扩增包括使用直方图均衡,水平翻转,旋转30度,90度,150度,180度,以及随机檫除中的一种或多种。
[0027]
具体地,在本发明的一种非典型类数据集平衡方法中,还方法步骤还包括:获取目标图像,基于该训练后的网络模型对所述目标图像进行预测分类。
[0028]
第二方面,本发明提出一种非典型类数据集平衡装置,其具体包括:
[0029]
预处理模块,用于对数据集进行预处理;
[0030]
第一扩增模块,用于针对不同类别的不均衡数据集进行扩增得到平衡数据集;
[0031]
第一训练模块,用于将平衡数据集送入设置好的网络模型进行训练得到非典型类数据集;
[0032]
第二扩增模块,用于对非典型类数据集进行非典型类数据扩增,得到非典型类均衡数据集;
[0033]
第二训练模块,用于将典型类数据集和所述非典型类均衡数据集输入网络模型训练,得到训练后的网络模型和训练后的分类结果。
[0034]
第三方面,本发明提出电子设备,其特征在于,包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于执行所述的非典型类数据集平衡方法的步骤。
[0035]
第四方面,本发明提出一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现任一项所述的非典型类数据集平衡方法的步骤。
[0036]
基于本发明的一种非典型类数据集平衡方法、装置、介质,其实现了以下有益的技术效果:
[0037]
(1)本发明实施例中,针对不均衡的数据集,首先对数据集进行预处理;针对不同类别的不均衡数据集进行传统方法的扩增得到平衡数据集;然后将平衡数据集送入设置好的网络模型进行训练得到非典型类数据集;对非典型类数据集进行非典型类数据集扩增,得到非典型类均衡数据集;最后将典型类数据集和所述非典型类均衡数据集输入网络模型训练,得到训练后的网络模型和训练后的分类结果;通过对非典型类的数据集进行扩增的方法,为不均衡数据分类任务领域提供了一个新的思路,其相较于现有的分类方法实现了特异性以及准确率的大幅提升。
[0038]
(2)本发明的实施例中,在网络模型(efficientnetb0)的初始化设置中,使用efficientnetb0在自然图像上训练好的权重进行迁移学习训练,可以避免网络陷入局部最大值,一定程度解决梯度消失和爆炸的问题,同时迁移学习可以帮助网络快速收敛,并提高模型的性能。
[0039]
(3)本发明的实施例中,本发明使用改进的二分类的交叉熵损失函数验证loss平衡策略,在目标检测网络上,解决样本不平衡和样本难分类问题,可以很好的控制难易样本权重,得到较好的训练结果。当其应用于皮肤癌时得到了优良的皮肤癌智能识别分类模型。
附图说明
[0040]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0041]
图1是本发明实施例提供的非典型类数据集平衡方法的总体技术步骤的示意图。
[0042]
图2是本发明实施例提供的isic2019训练集标签示意图。
[0043]
图3是本发明实施例提供的数据集裁剪前后的示意图。
[0044]
图4是本发明实施例提供的传统平衡后数据集分布图。
[0045]
图5是本发明实施例提供的efficientnet网络结构示意图。
[0046]
图6是本发明实施例提供的初始数据集-传统平衡-非典型类数据平衡数据集分布示意图。
具体实施方式
[0047]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0048]
鉴于现有技术的缺点,本发明提出一种非典型类数据集平衡方法、装置、介质,其主要目标是当疾病的自动分类数据集存在不均衡的情况下,本发明结合传统不均衡数据处理方式和非典型类数据集平衡方式,能够实现各类疾病的高效、准确地分类识别,在发明的实施方案中,以皮肤疾病为例,使用不同类别的皮肤病图像完成不同类型疾病的分类识别。相较于现有技术,通过本发明的非典型类数据集平衡方法,实现了皮肤病的准确预测分类,提高了分类效率。
[0049]
具体地,一种非典型类数据集平衡方法,其具体包括对数据集进行预处理,针对不同类别的皮肤病不均衡数据集进行传统扩增得到训练集,实现不同类别的皮肤病数据整体均衡的状态,在此基础上,如图1所示,将训练集送入选定的cnn网络进行训练,得到训练的权重之后,使用此权重对训练集进行分类,得到预测错误和预测正确两个类别,预测错误的类别将之称为非典型类,然后对非典型类进行扩充,得到新训练集—非典型类数据平衡数据集;新的训练集送入网络模型训练,得到最终的训练网络模型和训练后的分类结果,并基于该网络模型进行不同皮肤病疾病的预测分类。
[0050]
示例性地,数据集在本发明中选用isic2019皮肤镜图像分类数据集,其数据来源主要有ham10000,包含训练数据和测试数据两大类,其中训练数据给出了疾病标签,共有25331张皮肤镜图像,以excel文件方式存储,其标签方式类似于one-hot编码,标签方式如图2,其第一行代表疾病类别,第一列是图片名字,数字为1的列类别代表此图片的标签。训练数据集采集均由专业皮肤科医生操作,实验使用的数据集信息如表1,从表格的数量和占比可以看出数据的不均衡性,其中数量最多的黑色素痣,最少的是皮肤纤维瘤,本发明提出的非典型类数据平衡手段就是为了解决这个问题。在使用时削减了部分图片,然后把比赛的训练集一分为二,采集五分之一的图片作为测试集单独存放,避免数据污染,剩下的五分之四作为训练集使用。整个训练数据集中恶性皮肤癌图片共8473张,良性图片16858张,根据疾病良恶性分类,可以看到恶性图片也只有良性疾病的二分之一。在恶性图片中最多的是黑色素瘤,一共4522张,在良性图片中,最多的黑色素痣,一共12875张。
[0051]
表1 isic2019数据集详细示例
[0052][0053]
本发明以下的实施方案中,具体的示例性的技术方案均为举例的需要,其技术方案的实施方式不仅限于此。
[0054]
第一实施例
[0055]
于一实施例中,本发明的一种非典型类数据集平衡方法包括以下步骤:
[0056]
步骤s100、对数据集进行预处理。
[0057]
具体地,对isic2019的数据进行预处理时发现,过对毛发的处理以及先分割后分类的处理,其处理得到边际改善效果很低,不超过1%。为体现本发明提出的非典型类数据平衡的效果,舍弃以上预处理方法,只进行简单的裁剪处理。数据集内部有大量图片有着无关的黑色边缘,如图3的a图和d图所示,示例性地,以皮肤癌为例,皮肤癌分类时只需要关注图片中间的皮肤损伤部位,特对部分图片做裁剪处理。大致步骤为:首先将所有训练数据二值化,二值化图片如图3的b和e图所示,可以看到需要处理图片的黑色边缘,设定阈值,筛选出需要裁剪的图片,对其进行裁剪,并使其宽高比和初始图像相同。裁剪前后图片对比如图3的a图和c图,d图和f图,可以看到裁剪之后的图片很好的保留了皮肤病变部位,而去除了黑色边缘。同时,在输入网络之前,本发明预处理的步骤还包括进行随机的图像增强处理来避免过拟合现象。本发明数据预处理可以很好的提升分类结果的准确度。
[0058]
步骤s200、针对不同类别的不均衡数据集进行扩增得到平衡数据集。
[0059]
具体地,以皮肤病为例,实验数据皮肤病的个别类别数量极少,最多的类别和最少的相差几十倍。为平衡这种差异,采用扩增平衡策略,首先是传统扩充平衡策略,示例性地,对需要扩充的类别图片使用直方图均衡,水平翻转,旋转30度,90度,150度,180度,以及随机檫除(cutout)等方法进行扩充,并且使扩充之后每个类别的图片数量大致接近最多的黑
色素痣数量的二分之一或者三分之一,具体情况视每一个种类的初始图片数量而定。传统平衡后的数据分布如图4,对比初始分布,数据分布较为均衡,小样本数据量的增加也可以避免在训练过程中的过拟合问题。
[0060]
步骤s300、将平衡数据集送入设置好的网络模型进行训练得到非典型类数据集。
[0061]
具体地,将平衡数据集送入设置好的网络模型进行训练分类后,输出结果包括了典型类数据集和非典型类数据集,即通过初步的网路模型得到了分类正确和分类不正确的数据集。
[0062]
具体地,于一个实施例中,所述设置好的网络模型,网络模型可以是efficientnetb0,vgg,resnet以及googlenet。优选地,本发明采用的网络模型为efficientnetb0,平衡数据集中所有输入图片输入大小设置为224
×
224,并做随机的水平翻转和随机旋转的数据增强操作,避免训练时出现过拟合现象;最后对数据进行归一化并转为向量输入到网络模型中。深度学习网络训练时,通过反向传播来修改网络的权重,在深度学习出现之初,训练时随机初始化权重,这会导梯度爆炸和梯度消失问题,所以在进行训练之初应当有一个好的权重初始化,于一个实施例中,可以通过先验知识设置网络模型的初始化权重或是自动随机生成,优选地,本发明的网络模型efficientnetb0使用在自然图像上训练好的权重进行迁移学习训练得到efficientnetb0网络的初始模型权重,已经训练好的模型权重,可以避免网络陷入局部最大值,一定程度解决梯度消失和爆炸的问题,同时迁移学习可以帮助网络快速收敛,并提高模型的性能。
[0063]
具体地,efficientnetb0主要模块有mbconvblock,mbconv,sepconv,使用了深度可分离卷积(dwconv),se模块等结构,具体结构示意图如图5。具体地,网络模型训练中分为迁移学习和使用迁移学习之后的权重训练两个部分,网络模型的设置具体包括:epoch统一设置为100,batch size设置为64,迁移学习的学习率为0.01,迁移学习之后的学习率为0.001,两次训练均使用带动量的sgd优化器,动量设为0.9。根据实际疾病的识别需要,疾病的类别可以设置不同的数量,于一个实施例中,设置分类类别为八类,而基于所用网络模型是从imagenet迁移学习来的,所以修改网络最后的全连接层,使其输出满足当前实验的类别数量。最后本发明对过程中的验证集精度进行监视,当其在10个epoch期间不再有提升,则提前停止训练,并保存模型在验证集准确度最高的权重。
[0064]
步骤s400、对非典型类数据集进行非典型类数据扩增,得到非典型类均衡数据集。
[0065]
具体地,对非典型类数据集进行数据扩增包括使用直方图均衡,水平翻转,旋转30度,90度,150度,180度,以及随机檫除(cutout)等方法进行扩充,扩充后的数据集作为非典型类均衡数据集。于一个实施例中,以皮肤疾病为例,虽然部分类别无非典型类,但是并不影响整体数据的非典型类平衡,并且往往每一个恶性皮肤癌都有非典型类。在得到非典型类之后,使用数据扩增方法,对其进行二十倍五十倍甚至更多的扩增,增加其在数据集中的数量,使得模型能够更好的去关注非典型类样本,降低模型假阴性率。初始数据集-传统平衡数据集-非典型类数据平衡之后的数据集分布如图6,数据分布逐渐趋于平衡。在发明中使用efficientnet进行试验,然后将本发明提出的非典型数据平衡方法应用到分类领域经典的网络,验证非典型类数据平衡方法对训练效果的优化能力。
[0066]
步骤s500、将典型类数据集和所述非典型类均衡数据集输入网络模型训练,得到训练后的网络模型和训练后的分类结果。
[0067]
具体地,基于网络模型训初始练得到了典型类数据集和非典型类数据集,在扩增得到非典型类均衡数据集后,数据分布逐渐趋于平衡,将典型类数据集和所述非典型类均衡数据集得到的新数据训练集输入网络模型中进行训练得到训练后的网络模型,即得到最终训练好的网络模型,同时也得到了训练数据集的分类结果。
[0068]
在步骤s500中,可以理解的是,网络模型中损失函数的使用可以是传统的损失函数,于一个实施例中,优选地,本发明的网络模型在训练过程中采用focal loss解决样本不平衡和样本难分类问题,网络无论是在训练速度上,还是在训练的准确度上都有了较高的提升。focal loss是在基础的二元交叉熵损失函数上面进行修改得到的,二分类的交叉熵损失函数如下公式1所示,
[0069][0070]
其中,y的取值范围是1或者-1,1代表正样本,-1代表负样本,概率p的取值范围是0到1;
[0071]
用pt代替p,得到公式2,
[0072][0073]
公式1可以重写为公式3:
[0074]
ce(p,y)=ce(pt)=-log(pt)
ꢀꢀꢀ
(3)
[0075]
为控制正负样本,难分类和容易分类样本权重,focal loss在公式3前面加入调制系数,得到公式4:
[0076]
fl(pt)=-α
t
(1-pt)
γ
log(pt)
ꢀꢀꢀ
(4)
[0077]
其中α
t
用来降低负样本的权重,当标签等于1的时候,-α
t
等于α,标签等于其他的时候,-α
t
等于1-α,α的取值范围是0到1。因此,可以通过设置α的值来控制正负样本对loss的贡献。其中的(1-pt)
γ
用来控制难分类容易分类样本的权重,如果pt的值越大,也就是说属于某一类的概率越大,1-pt就会越小,反之亦然,因此可以通过设置(1-pt)
γ
来控制难分类和易分类样本对loss的贡献。其中的(1-pt)
γ
称为focal loss的调制系数,而α
t
是在控制正负样本权重时候常用的系数。当γ值为0时,focal loss就是普通的二元交叉熵损失函数,随着值的增大,难分类样本的权重在逐渐增加,因此在使用的时候可以选择适当的α和γ的值,于一个实施例中,本发明根据经验使用的都是0.25,可以很好的控制难易样本权重,得到较好的训练结果。
[0078]
进一步地,在本发明的一种非典型类数据集平衡方法中,该方法步骤还包括:
[0079]
获取目标图像,基于该训练后的网络模型对所述目标图像进行预测分类。
[0080]
具体地,获取测试集的目标图像,将目标图像输入训练后的网络模型中,对测试集的目标图像进行预测分类。本发明的方法可以应用于各种需要进行预测分类的数据集中,特别是不同疾病类型的图像的预测分类,有助于将预测网络模型应用于各类目标图像的分类。在应用于皮肤癌时可以有助于得到优良的皮肤癌智能预测模型以及智能的预测识别分类。
[0081]
本发明通过使用不同分类器模型,在isic2019的20000多张皮肤镜图像数据集上验证非典型类数据平衡效果,使用非典型类数据平衡模型的敏感性,f1分数,准确率,特异
性以及精确率比未使用非典型类数据平衡的模型均有较大提升,其中googlenet的f1分数提升了12.7%,平均准确率的提升约5%。针对黑色素瘤、鳞状细胞癌等八种皮肤损伤的多分类任务中,使用非典型类数据平衡方法和efficientnet模型的准确性达到82.4%,相比最近一次isic2019竞赛的冠军模型准确率提高了约20%。因此,充分说明了本文提出的皮肤病智能识别分类策略的有效性,非典型类数据平衡策略也为不均衡数据分类任务领域提供了一个新的思路。
[0082]
实施例二
[0083]
本发明还提供了另一种实施方式,本发明提出一种非典型类数据集平衡装置,包括:
[0084]
预处理模块,用于对数据集进行预处理;
[0085]
第一扩增模块,用于针对不同类别的不均衡数据集进行扩增得到平衡数据集;
[0086]
第一训练模块,用于将平衡数据集送入设置好的网络模型进行训练得到非典型类数据集;
[0087]
第二扩增模块,用于对非典型类数据集进行非典型类数据扩增,得到非典型类均衡数据集;
[0088]
第二训练模块,用于将典型类数据集和所述非典型类均衡数据集输入网络模型训练,得到训练后的网络模型和训练后的分类结果。
[0089]
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的装置和模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0090]
实施例三
[0091]
本发明还提供了另一种实施方式,本发明提出一种电子设备,包括:处理器1及存储器2。
[0092]
所述存储器2用于存储计算机程序。
[0093]
所述存储器2包括:rom、ram、磁碟、u盘、存储卡或者光盘等各种可以存储程序代码的介质。
[0094]
所述处理器1与所述存储器2相连,用于执行所述存储器2存储的计算机程序,以使所述一种胎儿颅脑结构畸形标准切面生成装置执行上述的非典型类数据集平衡方法。
[0095]
优选地,所述处理器1可以是中央处理器(central processing unit,简称cpu);还可以是专用集成电路(application specific integrated circuit,简称asic)。
[0096]
实施例四
[0097]
本发明还提供了另一种实施方式,即提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序可被至少一个处理器执行,以使所述至少一个处理器执行如上述的非典型类数据集平衡方法的步骤。
[0098]
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述或记载的部分,可以参见其它实施例的相关描述。
[0099]
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各实施例的模块、单元和/或方法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不
应认为超出本发明的范围。
[0100]
在本发明所提供的几个实施例中,应该理解到,所揭露的设备,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块或组件可以结合或者可以集成到另一个设备或系统,或一些特征可以忽略,或不执行。
[0101]
另外,在本发明各个实施例中的各功能模块可以集成在一个处理模块中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个模块中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0102]
以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1