基于支持向量机的滑坡易发性评估方法及工具
1.本发明属于滑坡灾害评估领域,具体涉及一种基于支持向量机的滑坡易发性评估方法及工具。
背景技术:
2.滑坡易发性评价是综合分析研究区内的各种地质环境因素、历史滑坡数据、滑坡的物理规律等要素,确定研究区内未来发生滑坡的概率。近年来,滑坡易发性制图工作已经引起了很多学者的关注,各类基于此的文章被发表。生成滑坡易发性图的方法主要有基于专家经验的经验模型、基于数据驱动的统计模型和机器学习模型。与传统方法相比,机器学习模型不依赖专家经验,降低了评价结果的主观性,准确性高。随着地理信息系统(gis)软件以及开源机器学习库的发展,机器学习方法越来越受欢迎,与其他机器学习算法相比,支持向量机(svm)方法因其在解决小样本、非线性和高维的分类问题上具有一定优势,在计算滑坡易发性方面得到了广泛应用。
3.使用svm开展滑坡易发性评估虽然准确性高,但过程较复杂,涉及数据预处理、影响因子筛选、数据集制作、模型训练及预测等多个步骤,通常使用svm开展滑坡易发性制图工作时,研究人员需要跨多个平台开展工作,如坡度、坡向等基于数字高程模型(dem)制作的地形因子,依靠arcgis或qgis等平台;模型训练及参数优化通常使用python、r或matlab等已经被广泛使用的编程语言;此外,大多数研究中使用excel、spss软件或编程语言进行模型精度评定及统计分析。
4.目前,部分文献提出并应用了几种工具来评估滑坡易发性。osna et al.(2014)等人开发了一个利用mamdani模糊推理系统(fis)绘制滑坡易发性图的独立应用程序(geofis)。sezer et al.(2017)等人为netcad架构软件开发了一个基于专家经验的lsm模块。jebur et al.(2015)等人基于arcgis创建了一个基于双变量统计分析(bsa)的滑坡易发性制图工具箱。zhang et al.(2020)等人提供了一种基于优化的频率比(fr)法的滑坡易发性评估工具,该工具基于arcgis平台。torizin et al.(2022)等人提供了一种python编写的独立滑坡易发性评估应用程序——project manager suite(lsat pm)。bragagnolo et al.(2020)等人了开发了一个基于开源地理信息系统(gis)grass软件的一个免费开源插件r.landslide来基于人工神经网络生成滑坡易发性图。sahin et al.(2020)等人基于r与arcgis软件的集成了一个基于逻辑回归和随机森林的滑坡易发性评价工具包(lsm tool pack)。
5.现有工具箱大多是基于专家经验的模型或统计模型,如证据权法、频率比法等。这种方法原理简单,易于实施,但精度较差。此外,某些工具在使用过程中所需参数量较大,给使用者带来一些不必要的麻烦,且某些因子或机器学习参数的选取需要一定程度的专业知识,因此,这些工具对用户并不友好。
6.此外,大多数滑坡易发性评估工作过程较复杂,涉及数据预处理、影响因子筛选、数据集制作、模型训练及预测等多个步骤,研究人员通常需要跨多个平台开展工作,跨平台
操作较为麻烦。
技术实现要素:
7.为了解决现有技术中存在的上述问题,本发明提供了一种基于支持向量机的滑坡易发性评估方法及工具。本发明要解决的技术问题通过以下技术方案实现:
8.第一方面,本发明提供的一种基于支持向量机的滑坡易发性评估方法包括:
9.获取覆盖待预测区域的历史地形地质数据;
10.其中,所述历史地形地质数据包括滑坡的各项影响因子以及滑坡点数据;
11.对历史地形地质数据以数据转换的形式进行预处理;
12.在预处理之后的历史地形地质数据中裁剪出待预测区域的目标地形地质数据;
13.将同一位置点的目标地形地质数据在通道方向叠加,形成多通道的三维待预测影像;其中,每个通道对应一个影响因子;
14.根据待预测区域的滑坡点数据,在所述待预测影像中确定各个滑坡点所在范围内的第一多通道子影像以及各个非滑坡点所在范围内的第二多通道子影像;
15.按照预设比例从第一多通道子影像和第二多通道子影像中选取样本,组成训练集和测试集;
16.针对每个样本,计算该样本各个通道之间的皮尔逊相关系数以及各个通道因子对滑坡发生的信息增益比;
17.根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子,获得更新后的训练集、测试集以及待预测影像;
18.在不同参数下迭代使用训练集训练svm模型,并使用测试集对svm模型精度进行测试根据评价指标得到训练完成后的最优svm模型;
19.使用训练完成后的最优svm模型对更新后的待预测影像逐窗口进行预测,生成待预测区域的易发性图。
20.第二方面,本发明提供的一种基于支持向量机的滑坡易发性评估工具包括:
21.影响因子制作子工具箱,被配置为:
22.获取覆盖待预测区域的历史地形地质数据;
23.其中,所述历史地形地质数据包括滑坡的各项影响因子以及滑坡点数据;
24.对历史地形地质数据以数据转换的形式进行预处理;
25.在预处理之后的历史地形地质数据中裁剪出待预测区域的目标地形地质数据;
26.模型训练及预测子工具箱,被配置为:
27.将同一位置点的目标地形地质数据在通道方向叠加,形成多通道的三维待预测影像;其中,每个通道对应一个影响因子;
28.数据集制作与因子筛选子工具箱,被配置为:
29.根据待预测区域的滑坡点数据,在所述待预测影像中确定各个滑坡点所在范围内的第一多通道子影像以及各个非滑坡点所在范围内的第二多通道子影像;
30.按照预设比例从第一多通道子影像和第二多通道子影像中选取样本,组成训练集和测试集;
31.针对每个样本,计算该样本各个通道之间的皮尔逊相关系数以及各个通道因子对
滑坡发生的信息增益比;
32.根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子,获得更新后的训练集、测试集以及待预测影像;
33.模型训练及预测子工具箱,被配置为:
34.在不同参数下迭代使用训练集训练svm模型,并使用测试集对svm模型精度进行测试根据评价指标得到训练完成后的最优svm模型;
35.使用训练完成后的最优svm模型对更新后的待预测影像逐窗口进行预测,生成待预测区域的易发性图。
36.本发明提供的一种基于支持向量机的滑坡易发性评估方法及工具,通过数据采集、数据预处理、数据集生成、特征选择、模型训练和易发性图预测这几个过程,预测得到待预测区域的滑坡易发性指数,并生成研究区的滑坡易发性图进行后续分析。本发明包含整个易发性制图的流程,减少了跨平台操作的麻烦;同时相比于现有技术基于滑动窗口的易发性预测过程较耗时的方案,本工具提供一种多进程快速预测的基于支持向量机的滑坡易发性评估工具,充分提高滑坡易发性图的制作效率。以下将结合附图及实施例对本发明做进一步详细说明。
附图说明
37.图1是本发明实施例提供的一种基于支持向量机的滑坡易发性评估方法的流程示意图;
38.图2是本发明实施例提供的一种基于支持向量机的滑坡易发性评估方法的工具示意图;
39.图3是本发明实施例提供的工具箱各子工具界面;
40.图4是本发明实施例提供的待预测区域位置及滑坡点信息示意图;
41.图5是本发明实施例提供的皮尔逊相关系数计算结果示意图;
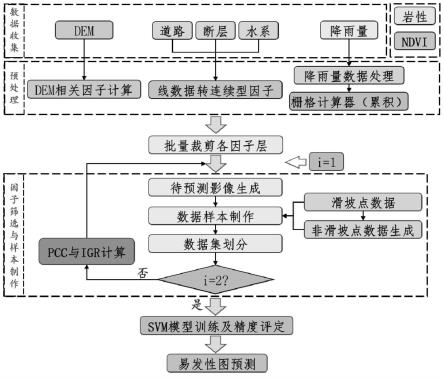
42.图6是本发明实施例提供的信息增益比计算结果示意图;
43.图7是本发明实施例提供的不同参数值下的auc值和精度差异图;
44.图8是本发明实施例提供的roc曲线图;
45.图9是本发明实施例提供的吴起县滑坡易发性分级图。
具体实施方式
46.下面结合具体实施例对本发明做进一步详细的描述,但本发明的实施方式不限于此。
47.如图1所示,本发明提供的一种基于支持向量机的滑坡易发性评估方法包括:
48.步骤1:获取覆盖待预测区域的历史地形地质数据;
49.其中,所述历史地形地质数据包括滑坡的各项影响因子以及滑坡点数据;其中,所述历史地形地质数据包括:历史滑坡点数据、高程(dem)、道路、断层、水系、降雨量、岩性和归一化植被指数(ndvi)数据;所述道路、断层以及水系数据为线矢量数据。
50.步骤2:对历史地形地质数据以数据转换的形式进行预处理;
51.在预处理之后的历史地形地质数据中裁剪出待预测区域的目标地形地质数据;
52.步骤3:将同一位置点的目标地形地质数据在通道方向叠加,形成多通道的三维待预测影像;其中,每个通道对应一个影响因子;
53.步骤4:根据待预测区域的滑坡点数据,在所述待预测影像中确定各个滑坡点所在范围内的第一多通道子影像以及各个非滑坡点所在范围内的第二多通道子影像;
54.步骤5:按照预设比例从第一多通道子影像和第二多通道子影像中选取样本,组成训练集和测试集;
55.步骤6:针对每个样本,计算该样本各个通道之间的皮尔逊相关系数以及各个通道因子对滑坡发生的信息增益比;
56.步骤7:根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子,获得更新后的训练集、测试集以及待预测影像;
57.步骤8:在不同参数下迭代使用训练集训练svm模型,并使用测试集对svm模型精度进行测试根据评价指标得到训练完成后的最优svm模型;
58.其中,所述评价指标包括:训练精度、测试精度、准确度、精确度、召回率、f1值、auc值和roc曲线。
59.步骤9:使用训练完成后的最优svm模型对更新后的待预测影像逐窗口进行预测,生成待预测区域的易发性图。
60.作为本发明一种可选的实施方式,所述对历史地形地质数据以数据转换的形式进行预处理包括:
61.步骤21:利用dem数据,计算待预测区域的地形因子;
62.步骤22:计算待预测区与各个线矢量数据之间的欧式距离,以将矢量数据转化为连续型栅格数据;
63.步骤23:将降雨量数据通过存储格式转化,转化为连续型栅格数据,以完成历史地形地质数据的预处理。
64.作为本发明一种可选的实施方式,所述根据待预测区域的滑坡点数据,在所述待预测影像中确定各个滑坡点所在范围内的第一多通道子影像以及各个非滑坡点所在范围内的第二多通道子影像包括:
65.步骤41:根据待预测区域的滑坡点数据,确定各个滑坡点位置;
66.步骤42:以每个滑坡点为中心点,以预设的半径确定每个滑坡点的圆形缓冲区;
67.步骤43:在每个滑坡点的圆形缓冲区之外且位于待预测区域内,随机选取与滑坡点数量相同的非滑坡点;
68.步骤44:以与滑坡点的圆形缓冲区相同的半径为每个非滑坡点制作圆形缓冲区;
69.步骤45:求取每个圆形缓冲区的最小外接矩形,得到滑坡点的第一外接矩形和非滑坡点的第二外接矩形;
70.步骤46:每个滑坡点的第一外接矩形以及每一个非滑坡点的第二外接矩形在待预测影像对应位置处进行裁剪,得到滑坡点对应的第一多通道子影像以及非滑坡点对应的第二多通道子影像。
71.作为本发明一种可选的实施方式,所述按照预设比例从第一多通道子影像和第二多通道子影像选取样本组成训练集和测试集包括:
72.步骤51:将第一多通道子影像作为正样本,并将第二多通道子影像作为负样本;
73.步骤52:按照预设的正样本与负样本的比例,选择正样本以及负样本组成测试集和训练集;
74.步骤53:将训练集以及测试集进行存储;
75.步骤54:以文本记录训练集以及测试集的存储信息,并进行保存;
76.其中,文本中记载训练集以及测试集中每个样本的存储路径以及区分样本为滑坡点对应的样本还是非滑坡点对应的样本的标签。
77.作为本发明一种可选的实施方式,所述根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子包括:
78.步骤71:确定皮尔逊相关系数超过阈值所对应的两个通道;
79.步骤72:将两个通道中增益值小的通道确定为不符合条件的通道;
80.步骤73:将训练集、测试集以及待预测影像中,不符合条件的通道对应的影响因子去除。
81.本发明提供的基于svm的lsm生成过程包括数据采集、数据预处理、数据集生成、特征选择、模型训练和易发性图预测。数据收集包括研究区历史滑坡数据、矢量数据和滑坡影响因素,如道路、河流、断层、ndvi、dem、岩性和降雨量。数据预处理包括基于dem计算地形因子,如坡度和坡向,将线矢量数据转换为连续栅格因子,以及nc4数据处理。对于具有相同空间分辨率的光栅数据,还需要将其剪裁到相同的范围。然后,根据滑坡点和研究区域范围,随机选取相同数量的非滑坡点构建负样本。同时,训练集和测试集按7:3随机划分。此外,还计算了所有样本的皮尔逊相关系数(pcc)和信息增益比(igr)。根据计算结果选择影响因素;移除高度相关或对滑坡发生不太重要的因素。然后根据特征选择的结果重构训练集和测试集。随后,利用训练集对模型进行训练,通过对准确度、精密度、召回率、f1值、roc曲线和曲线下面积(auc)等参数和评价指标的综合分析,得到最优的svm模型。最后利用最优模型预测研究区的滑坡易发性指数,并生成研究区的滑坡易发性图进行后续分析。
82.本发明提出一种基于支持向量机的滑坡易发性评估工具,根据上述方法流程生成滑坡易发性图。lsm工具箱包括三个子工具箱:“1影响因素制作”、“2数据集制作与因子筛选”和“3模型训练及预测”,如图2所示。该工具箱基于arcpy和python语言开发,可直接集成到arcgis 10.1及以上版本或arcgis pro软件中。高效且对用户友好。各模块界面如图3所示。
83.参考图2,本发明提供的一种基于支持向量机的滑坡易发性评估工具,包括:
84.影响因子制作子工具箱,被配置为:
85.获取覆盖待预测区域的历史地形地质数据;
86.其中,所述历史地形地质数据包括滑坡的各项影响因子以及滑坡点数据;
87.对历史地形地质数据以数据转换的形式进行预处理;
88.在预处理之后的历史地形地质数据中裁剪出待预测区域的目标地形地质数据;
89.值得说明的是:本工具箱在使用时,首先需要准备好研究区的历史滑坡点数据、高程(dem)、道路、断层、水系、降雨量、岩性和ndvi数据,这些将作为原始数据开展滑坡易发性评估工具。
90.预处理过程:首先,使用“1影响因素制作”——“1dem相关因子计算”工具,根据dem计算坡度、坡向、曲率、平面曲率、剖面曲率、地形起伏度、地表粗糙度、地形湿度指数(twi)
等地形因子。使用“1影响因素制作”——“2线数据转连续型因子”工具,将道路、水系、断层等线矢量数据转换为距道路的距离、距水系的距离、距断层的距离等连续型栅格数据,转换方法为欧氏距离。使用“1影响因素制作”——“3降雨量数据处理”工具,将从nasa(https://gpm.nasa.gov/)下载的逐月或逐天降雨量数据(.nc4格式)数据转换为30m的tif栅格数据,然后使用栅格计算器根据需要将所有.tif累加,得到年降雨量。
91.批量裁剪各因子层:对于数据预处理后得到的因子层数据,存在覆盖范围不统一的问题,因此,需要使用“1影响因素制作”——“4批量裁剪各因子层”工具,根据研究区的范围,将所有因子数据(高程、坡度、坡向、曲率、平面曲率、剖面曲率、地形起伏度、地表粗糙度、twi、ndvi、降雨量、距道路的距离、距水系的距离、距断层的距离、岩性)裁剪到相同的范围。
92.模型训练及预测子工具箱,被配置为:
93.将同一位置点的目标地形地质数据在通道方向叠加,形成多通道的三维待预测影像;其中,每个通道对应一个影响因子;
94.值得说明的是:使用“3模型训练及预测”——“1待预测影像生成”工具,将裁剪后的所有因子层栅格数据在通道方向上叠加,生成多通道的待预测影像。
95.数据集制作与因子筛选子工具箱,被配置为:
96.根据待预测区域的滑坡点数据,在所述待预测影像中确定各个滑坡点所在范围内的第一多通道子影像以及各个非滑坡点所在范围内的第二多通道子影像;
97.按照预设比例从第一多通道子影像和第二多通道子影像中选取样本,组成训练集和测试集;
98.针对每个样本,计算该样本各个通道之间的皮尔逊相关系数以及各个通道因子对滑坡发生的信息增益比;
99.根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子,获得更新后的训练集、测试集以及待预测影像;
100.同时,使用“2数据集制作与因子筛选”——“1非滑坡点数据生成”工具,在研究区矢量数据图层范围内生成非滑坡点数据,原则:在给定滑坡样本点一定缓冲区范围外随机选取相同数量的非滑坡样本点。然后,使用“2数据集制作与因子筛选”——“2数据样本制作”工具,根据上一步的滑坡点和非滑坡点数据矢量数据制作缓冲区并逐个要素裁剪待预测影像数据(.tif),生成多通道块样本栅格数据,用于模型训练及精度评定。使用“2数据集制作与因子筛选”——“3数据集划分”工具,按照测试集比例划分训练集和测试集,并以txt保存划分结果。在划分完成后,应用“2数据集制作与因子筛选”——“4pcc与igr计算”工具,基于生成的所有样本路径及标签文件,计算各影响因子层的皮尔逊相关系数与信息增益比。皮尔逊相关系数代表因子层之间的相关性大小,其值位于[-1,1]之间,相关性较大的因子应考虑剔除。信息增益比代表各因子层对滑坡发生的贡献大小,其值大于0说明对滑坡发生有贡献,值越大,贡献越大。根据计算结果,对影响因子进行筛选,移除相关性较大且贡献较小的因子,其余因子用于后续研究。在得到筛选后的因子后,重复“3模型训练及预测”——“1待预测影像生成”、“2数据集制作与因子筛选”——“2数据样本制作”、“2数据集制作与因子筛选”——“3数据集划分”步骤,根据筛选后的因子层,重新更新待预测影像和数据集。因此,在流程图中,以i为判断条件,第一次执行时未进行因子筛选(i《2),第二次执
行时,对因子进行了筛选(i=2)。
[0101]
模型训练及预测子工具箱,被配置为:
[0102]
使用训练集迭代训练svm模型,并使用测试集在每个迭代次对svm模型进行测试直至svm模型符合评价指标,得到训练完成后的svm模型;
[0103]
使用训练完成后的svm模型对更新后的待预测影像逐窗口进行预测,生成待预测区域的易发性图。
[0104]
svm模型训练及精度评定:使用“3模型训练及预测”——“2svm模型训练及精度评定”工具,使用训练集生成各组参数下的svm模型并基于测试集给出模型精度的评定结果。svm核函数为径向基核函数(rbf),需要调节的参数为gamma与惩罚因子c,使用的调参方法为网格搜索算法。模型评价指标包括训练精度、测试精度、准确度、精确度、召回率、f1值、auc值和roc曲线。
[0105]
易发性图预测:使用“3模型训练及预测”——“3易发性图预测”工具,使用上一步得到的最优模型对研究区更新后的待预测影像逐窗口进行预测,生成研究区易发性图。这一步提供单进程或多进程两种方式,多进程效率远高于单进程。
[0106]
可选的:所述影响因子制作子工具箱包括:
[0107]
dem相关因子计算工具,被配置为利用dem数据,计算待预测区域的地形因子;
[0108]
线数据转连续型因子,被配置为计算待预测区与各个线性矢量数据之间的欧式距离,以将矢量数据转化为连续型栅格数据;
[0109]
降雨量数据处理工具,被配置为将降雨量数据通过存储格式转化,转化为连续型栅格数据,以完成历史地形地质数据的预处理;
[0110]
批量裁剪各因子层工具,被配置为在预处理之后的历史地形地质数据中裁剪出待预测区域的目标地形地质数据。
[0111]
可选的,所述模型训练及预测子工具箱包括:
[0112]
待预测影像生成工具被配置为:
[0113]
将同一位置点的目标地形地质数据在通道方向叠加,形成多通道的三维待预测影像;其中,每个通道对应一个影响因子;
[0114]
所述数据集制作与因子筛选子工具箱包括:
[0115]
非滑坡点数据生成工具被配置为:
[0116]
根据待预测区域的滑坡点数据,在所述待预测影像中确定各个滑坡点所在范围内的第一多通道子影像以及各个非滑坡点所在范围内的第二多通道子影像;
[0117]
数据样本制作被配置为:
[0118]
按照预设比例从第一多通道子影像和第二多通道子影像中选取样本,组成训练集和测试集;
[0119]
pcc与igr计算工具,被配置为:
[0120]
针对每个样本,计算该样本各个通道之间的皮尔逊相关系数以及各个通道因子对滑坡发生的信息增益比;
[0121]
数据集划分工具,被配置为:根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子,获得更新后的训练集、测试集以及待预测影像。
[0122]
数据集制作与因子筛选工具包括:
[0123]
非滑坡点数据生成工具,被配置为:
[0124]
从待预测区域的滑坡点数据中确定各个滑坡点位置;
[0125]
以每个滑坡点为中心点,以预设的半径确定每个滑坡点的圆形缓冲区;
[0126]
在每个滑坡点的圆形缓冲区之外且位于待预测区域内,随机选取与滑坡点数量相同的非滑坡点;
[0127]
数据集制作与因子筛选被配置为:
[0128]
以与滑坡点的圆形缓冲区相同的半径为每个非滑坡点制作圆形缓冲区;
[0129]
求取每个圆形缓冲区的最小外接矩形,得到滑坡点的第一外接矩形和非滑坡点的第二外接矩形;
[0130]
每个滑坡点的第一外接矩形以及每一个非滑坡点的第二外接矩形在待预测影像对应位置处进行裁剪,得到滑坡点对应的第一多通道子影像以及非滑坡点对应的第二多通道子影像。
[0131]
数据集划分工具被配置为:
[0132]
将第一多通道子影像作为正样本,并将第二多通道子影像作为负样本;
[0133]
按照预设的正样本与负样本的比例,选择正样本以及负样本组成测试集和训练集;
[0134]
将训练集以及测试集进行存储;
[0135]
以文本记录训练集以及测试集的存储信息,并进行保存;
[0136]
其中,文本中记载训练集以及测试集中每个样本的存储路径以及区分样本为滑坡点对应的样本还是非滑坡点对应的样本的标签。
[0137]
pcc与igr计算工具,被配置为:
[0138]
所述根据皮尔逊相关系数以及信息增益比,去除训练集、测试集以及待预测影像中不符合条件的通道对应的影响因子包括:
[0139]
确定皮尔逊相关系数超过阈值所对应的两个通道;
[0140]
将两个通道中增益值小的通道确定为不符合条件的通道;
[0141]
将训练集、测试集以及待预测影像中,不符合条件的通道对应的影响因子去除。
[0142]
本发明提供的一种基于支持向量机的滑坡易发性评估方法及工具,通过数据采集、数据预处理、数据集生成、特征选择、模型训练和易发性图预测这几个过程,预测得到待预测区域的滑坡易发性指数,并生成研究区的滑坡易发性图进行后续分析。本发明包含整个易发性制图的流程,减少了跨平台操作的麻烦;同时相比于现有技术基于滑动窗口的易发性预测过程较耗时的方案,本工具提供一种多进程快速预测的基于支持向量机的滑坡易发性评估工具,充分提高滑坡易发性图的制作效率。
[0143]
下面利用真实地形地质数据,通过工具箱使用说明本发明生成易发性图的过程以及性能
[0144]
参考图4,以陕西省延安市吴起县为例,使用开发的工具箱进行滑坡易发性评价。首先,收集研究区的历史滑坡数据,并根据研究区滑坡成因等因素选取合适的滑坡影响因子用于后续研究。注意:在使用中应确保所有数据均处于utm投影坐标系下,否则可能会出现某些未知的错误。由于研究区域内基本没有断层分布,且不受断层影响,因此在该案例中
未使用距断层的距离。
[0145]
1、影响因素预处理
[0146]
本例中使用的影响因子数据源有dem,道路,水系,岩性,ndvi和降雨量。岩性和ndvi以预先处理为30m分辨率的栅格数据。对收集到的dem数据使用“dem相关因子计算”工具,根据dem高程数据生成坡度、坡向、曲率、平面曲率、剖面曲率、地面起伏度、地表粗糙度及地形湿度指数等。同时,使用“线数据转连续型因子”工具,基于欧氏距离,根据道路、河流等线矢量数据制作相应的面栅格数据。对于降雨量数据(.nc4),使用“降雨量数据处理”工具,批量将由nasa获取的逐月降雨量数据转换为相应的面栅格数据,并使用栅格计算器对得到的月尺度降雨数据进行累加得到年尺度降雨数据。最后,使用“批量裁剪各因子层”工具,根据研究区矢量文件,批量裁剪生成的影响因子数据。最终共生成14个滑坡影响因子数据,所有因子数据空间分辨率为30m。
[0147]
2、因子选择和样本生成
[0148]
研究区有789处历史滑坡,在本研究中,所有滑坡位置都用于构建滑坡数据集。使用“非滑坡点数据生成”工具随机生成研究区域内距离滑坡点1km以外范围内的相同数量的非滑坡点。
[0149]
首先,利用“待预测影像生成”工具,将研究区域内14个影响因素进行多通道叠加。然后,基于叠加的多通道图像,利用“数据样本制作”工具生成滑坡和非滑坡块数据集。此外,在将样本的路径和标签分别保存到相应的txt文件,使用“数据集划分”工具将训练样本和测试样本按7:3的比例进行划分。最后,所有块数据集都为14个通道、8行和8列。训练集中有1104幅影像,测试集中有474幅影像,其中滑坡数据集标记为1,非滑坡数据集标记为0。
[0150]
使用“pcc和igr计算”工具根据数据样本计算每个因子层的pcc和igr后,图5显示了pcc计算的结果,可以看出,平面曲率与坡度、twi与坡度、起伏幅度与地表粗糙度之间的相关系数均大于0.5,且存在较强的相关性。图6给出了信息增益比的计算结果,14个滑坡影响因素的igr值均大于0,表明这些因素对相应地区滑坡的发生有影响。在本研究区,岩性对滑坡发生的影响最大,其次是ndvi、平面曲率、剖面曲率和twi,而曲率和地形起伏度的影响最小。通过对pcc和igr的综合分析,去除了坡度和地形起伏度这两个影响因素,剩下的12个影响因素用于后续研究。
[0151]
根据评估结果,按信息增益比递减的顺序(即岩性、平面曲率、剖面曲率、ndvi、twi、坡向、表面粗糙度、河流距离、dem、道路距离、降雨量和曲率)重复“待预测图像生成”,“数据样本制作”和“数据集划分”,以获得评估后要预测的最终图像和样本数据。在后续研究中,使用的所有块数据集的通道数为12,行数和列数为8。
[0152]
3、模型训练和精度评估
[0153]
使用“svm模型训练及精度评定”工具根据生成的训练数据训练模型,使用测试集评估性能,并绘制roc曲线。其中,svm模型使用rbf核函数。参数gamma和c的值从0.01、0.02、0.05、0.08、0.1、0.2、0.5、0.8、1、2和5中选择。图7显示了不同gamma和c值的auc值以及训练集和测试集之间的精度差异,使用gamma值作为水平坐标,c值作为垂直坐标。在图中,圆圈的大小表示auc值。圆圈越大,auc值越高,模型的准确性越好。圆形表示训练集和测试集之间的精度差异。如果超过0.5,则表示为0.5。差异越大,模型的过度拟合程度越高,泛化性能越差。因此,综合分析表明,当gamma为0.02,c为2时,auc值较高,差异较小,模型最优。
[0154]
最优模型下的模型性能评价结果如表1所示,roc曲线如图8所示。在474个测试集中,169个滑坡和171个非滑坡被正确预测,68个滑坡和66个非滑坡被错误预测。该模型预测的正确样本占总样本的71.73%,准确率为71.55%,召回率为72.15%。同时,该模型的auc值为0.8029,表明该模型具有良好的预测性能,滑坡易发性图的结果是可靠的。
[0155]
表1模型性能评价指标
[0156][0157]
选择经过训练的最优模型,并使用“易发性图预测”工具,根据最优模型逐单元预测生成的图像。获得每个评估单元被预测为滑坡的概率,以生成研究区域的滑坡易发性图。预测的易发性指数介于0和1之间,易发性指数越大,该地区越容易发生滑坡,相反,易发性指数越低,该地区对滑坡的易发性越低。使用arcgis中的自然间断法,将生成的易发性图分为五个级别:极低、低、中、高和极高。通过svm得到的吴起县滑坡易发性分级图如图9所示。
[0158]
4、工具箱运行效率评估
[0159]
表2分别显示了arcgis和arcgis pro环境下,工具箱各功能模块在吴起县数据的运行时间。所有实验都是在windows pc x64上进行的,该电脑具有2.30ghz gen intel core i7-11800h cpu、4gb geforce rtx 3050ti笔记本电脑图形卡和16gb ram。
[0160]
表2吴起县各工具不同软件运行时间统计
[0161][0162]
如表2示,svm-lsm工具箱在arcgis单进程中运行整个流程的时间为5h 19m 27s,在arcgis pro单进程中运行整个流程的时间为2h 58m 39s,运行效率提高44.08%。同时,svm-lsm工具箱在arcgis多进程中运行整个过程的时间为2h 48m 3s,在arcgis pro多进程中运行整个过程的时间为1h 52m 4s,运行效率提高了33.31%。此外,在arcgis平台下,“易发性图预测(多进程)”工具的运行时间为2h 48m 3s,“易发性图预测(单进程)”工具的运行
时间为5h 19m 27s,将运行时间缩短了近2h 31m 24s,运行效率提高了47.39%。在arcgis pro平台下,“易发性图预测(多进程)”工具的运行时间为20m 12s,“易发性图预测(单进程)”工具的运行时间为1h 26m 47s,将运行时间缩短近1h 6m35s,运行效率提高76.72%。这表明,该工具中的滑动窗口多处理预测工具可以大大提高易发性制图的效率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1